
昨日(11 月 20 日),智源研究院办了一场具身智能 Open Day。 公开其最新研究进展的同时,把大半个具身机器人圈的明星企业 CEO/CTO、联创全都请到了现场,包括银河通用、智元机器人、星海图、加速进化、自变量、原力灵机、星源智、北京人形机器人创新中心、因时机器人、优必选、软通天擎等。
开场前,我们参观了智源的具身智能实验室,并先行看到了其具身大小脑协作框架 RoboOS 和 RoboBrain 的能力展示。

在接下来的现场演讲中,智源研究院系统地公布了其过去一年在具身智能领域的最新科研进展及核心布局。“当前人工智能正处在一个新的拐点,推动机器人从 1.0 专用机器人时代迈向 2.0 通用具身智能时代。”智源研究院院长王仲远表示,但同时他也指出,当下的具身大模型依然面临着“不好用、不通用、不易用”的核心痛点。
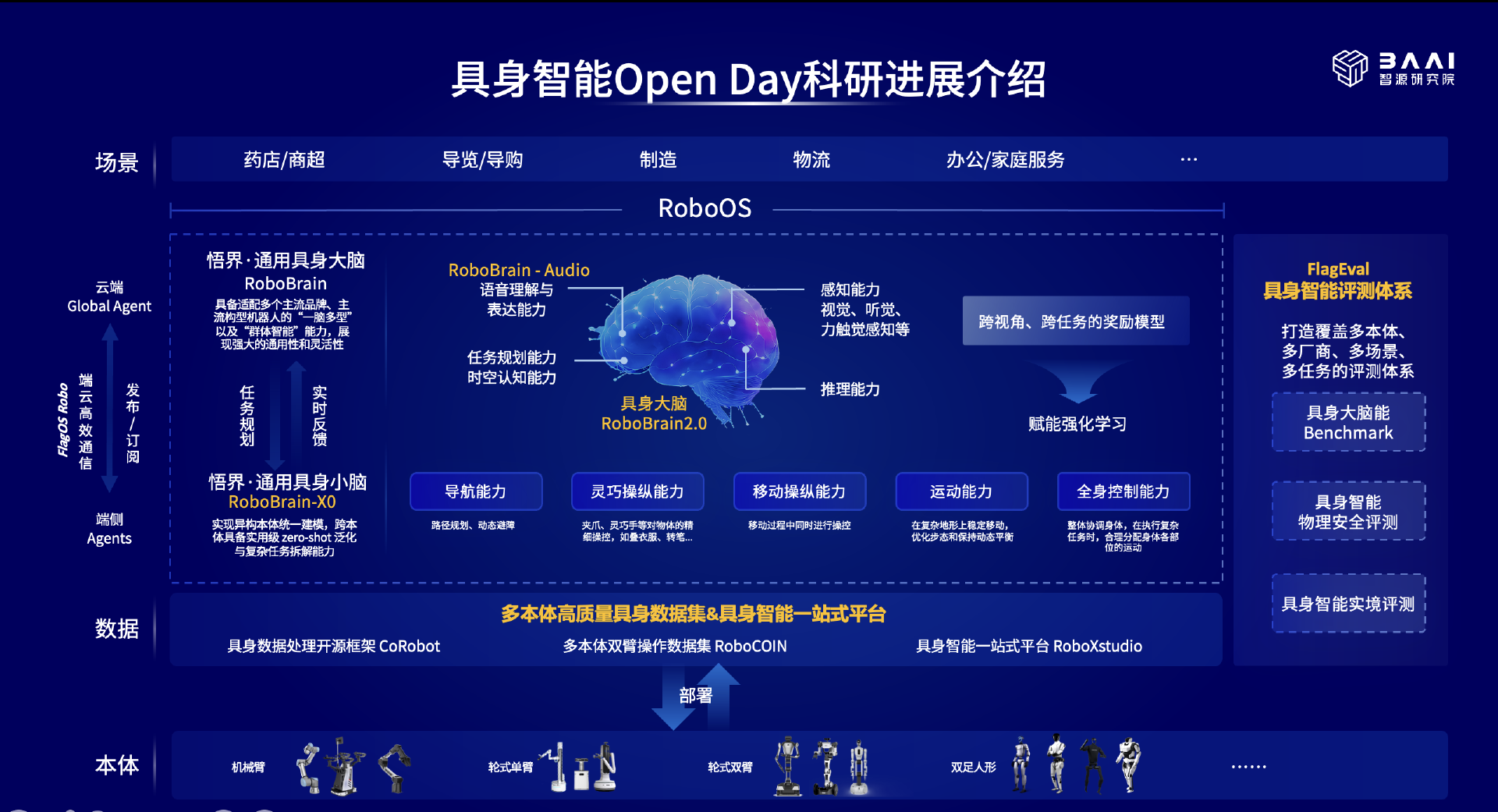
据介绍,智源已经构建出以具身大脑为核心,自底向上全栈具身智能技术体系,包括能够跨异构本体数据采集以及标准化一站式平台、具身大小脑以及 VLA 等具身基座模型,还有具身智能评测等,为具身技术生态提供一套可复现、可对齐的公共基础设施,降低从研究到产业化落地的门槛。

同时,智源研究院还公开了在具身智能领域的模型、数据、评测和工具链等核心科研布局。据介绍,智源希望构建面向通用机器人(可跨本体、高泛化性)具身大模型系统,以开源开放夯实具身智能公共底座。目前,智源在具身领域的合作伙伴已超过 30 家。智源研究院表示,未来将持续迭代并同步公布在开源项目、数据集与评测平台上的进展,同时与产业伙伴推进联合试点,加速具身智能从实验室走向生产线。
当具身智能圈的“安卓”,主推视频数据?
“谁家数据贡献得多,将来训练出来的具身大脑在谁家的机器人上就会更好用。”在之后的深度采访中,王仲远直言。
据其透露,对于很多创业公司来讲,训练一个模型的成本非常高。他们自己接到的订单不足以支持他们做有风险的尝试,而这也是他们愿意跟智源合作的一点。总结来说就是,“数据真的很痛,模型能力真的很痛。“
而合作方式就是,硬件他们来造,具身大脑靠智源。“有点类似于他们造手机、我们提供安卓操作系统一样。”王仲远形容道。
他表示,数据、尤其高质量的数据会决定整个模型的能力上限,智源研究院提出的则是以视频数据为主的路径,这遵循了第一性原理,与人类从眼睛观察、学习世界一样。对此,王仲远也作了详细的解释。
“如果我们有一千万台或一亿台机器人,能够天天干活采集很多数据,也许能帮助我们训练出特别有价值的具身大模型,但这是不现实的。我们认为,视频数据包含我们所有需要的时间空间因果,包括文字、声音、图像、一定的三维空间、逻辑以及意图等各种要素,是为数不多乃至唯一可以规模化获得的数据。”
并且,王仲远谈到,只有当机器人公民数量越来越多、产生了海量的机器人专有数据,且这些数据能够被公开且大家广泛用来训练,一个真正专门为具身机器人打造的具身大模型才有可能真正意义上出现。
30+明星 CEO、联创到场,激辩行业分歧
开放日上,30 多位明星具身智能公司的 CEO/CTO、联创齐聚现场,用三场圆桌探讨了世界模型、分层式大模型等不同技术路线的优劣、以及具身硬件发展和产业落地的现状。
“如果世界模型只是视频生成,那不一定能成为具身智能的基座。”王仲远谈到。北京大学助理教授、银河通用创始人及首席技术官王鹤同样认为,让机器人“学人类的视频生成模型”并不成立。机器人真正需要的是能根据自身形态与目标去预测下一步状态的世界模型,而这类模型必须建立在大量属于机器人的数据之上。
另外,嘉宾们普遍认为,短期内,将任务规划、感知与控制解耦的“分层系统”在工程落地和稳定性上更具优势;而中长期,行业需要向“可迁移、可复用”的通用基座模型演进,其关键在于统一的场景表示、高效的数据闭环以及对齐的评测标准。

谈到具身硬件,智元机器人合伙人、具身业务部总裁姚卯青表示,“硬件依然是瓶颈。关节发热、扭矩密度低、电池续航是线性瓶颈,每年都在进步;软件和大模型的泛化能力是非线性瓶颈,突破点不知道在哪一天。”
针对“硬件是否仍在拖累模型”的问题,与会者认为,二者已进入“共同定义”的新阶段。优秀的具身系统需要在模型层面做好规划,也需要在硬件层面通过力控等技术保证执行的可靠性。对于备受关注的人形机器人形态,嘉宾们表现出高度务实,认为其是当前供应链和应用场景下的主流探索方向,但任务需求和成本结构将最终决定商业化形态。

来自能源、制造等领域的场景方代表则明确了落地的核心指标:系统的鲁棒性、部署与维护成本、清晰的安全边界,以及与现有 IT/OT 系统的集成效率。一个共识是,具身智能的商业化应从“可度量的单点任务”切入,以确保投资回报率(ROI)的闭环,避免因追求场景广度而牺牲落地深度。





