
Pika 是一个可持久化的大容量 redis 存储服务,兼容 string、hash、list、zset、set 的绝大部分接口(兼容详情),解决 redis 由于存储数据量巨大而导致内存不够用的容量瓶颈。用户可以不修改任何代码从 redis 迁移到 pika 服务。由于单机 pika 容量受限于单块硬盘容量的大小,360 公司业务和社区对分布式 pika 集群的需求越来越强烈,因此我们推出了原生分布式 pika 集群,发布 pika 版本 v3.4。与 pika+codis 集群方案相比,pika 集群不需要额外部署 codis-proxy 模块,同时由于 codis 对 pika 创建和管理 slot 操作的支持并不友好,需要运维人员大量介入。
集群部署结构
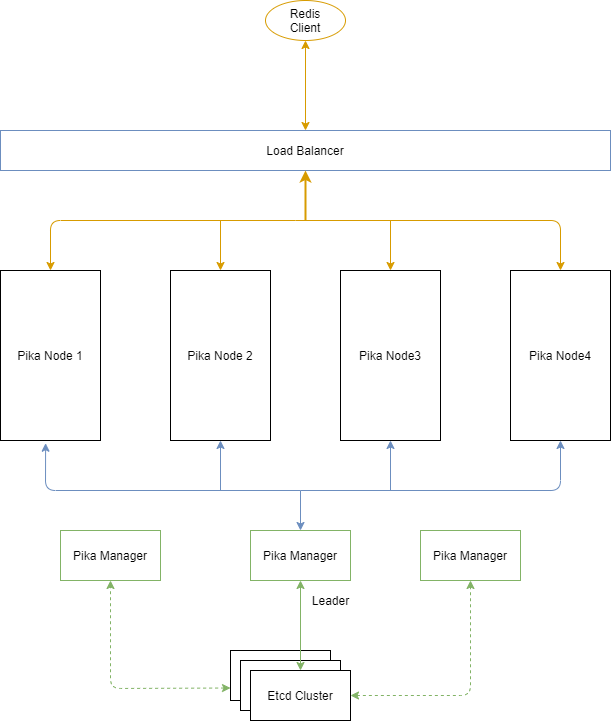
以 3 个 pika 节点的集群为例,集群部署结构如上图所示:
部署 Etcd 集群作为 pika manager 的元信息存储。
3 台物理机上分别部署 pika manager,并配置好 Etcd 的服务端口。Pika manager 会向 etcd 注册,并争抢成为 leader。集群中有且只有一个 pika manager 能够成为 leader 并向 etcd 中写入集群数据。
3 台物理机上分别部署 pika 节点,然后把 pika 节点的信息添加到 pika manager 中。
为了负载均衡,把 pika 的服务端口注册到 LVS 中。
数据分布
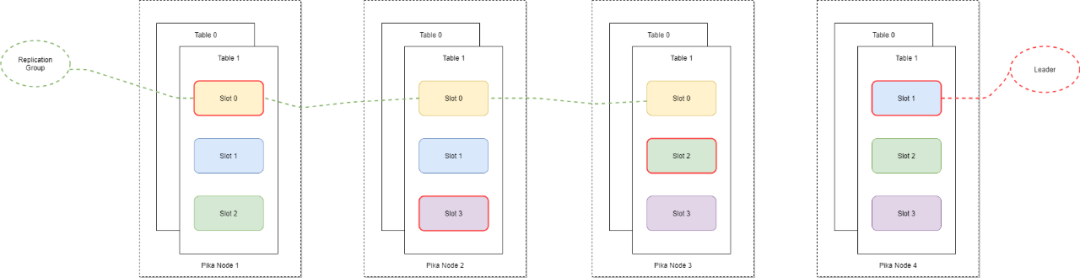
为了对数据按照业务进行隔离,Pika 集群引入 table 的概念,不同的业务数据存储在不同的 table 中。业务数据按照 key 的 hash 值存储到对应的 slot 上面。每一个 slot 会有多个副本,从而形成一个 replication group。replication group 中的所有 slot 副本具有相同的 slot ID,其中一个 slot 副本是 leader,其他副本为 follower。为了保证数据的一致性,只有 leader 提供读写服务。可以使用 pika manager 可以对 slot 进行调度迁移,使数据和读写压力均匀的分散到整个 pika 集群中,从而保证了整个集群资源的充分利用并且可以根据业务压力和存储容量的需要进行水平扩容和缩容。
pika 使用 rocksdb 作为存储引擎,每个 slot 会创建对应的 rocksdb。pika 中的每个 slot 都支持读写 redis 5 种数据结构。因此数据迁移的时候会特别方便,只需迁移 pika 中的 slot 即可。但同时也存在资源占用过多的问题。目前的 pika 在创建 slot 的时候会默认创建 5 个 rocksdb,分别来存储 5 种数据结构。在 table 中含有大量 slot 或者创建大量 table 的时候会使单个 pika 节点含有多个 slot,进而创建过多的 rocksdb 实例,占用了过多系统资源。在后续版本中一方面会支持创建 slot 的时候根据业务需要创建一种或几种数据结构,另一方面会持续对 pika 中的 blackwidow 接口层进行优化,减少对 rocksdb 的使用。
数据处理
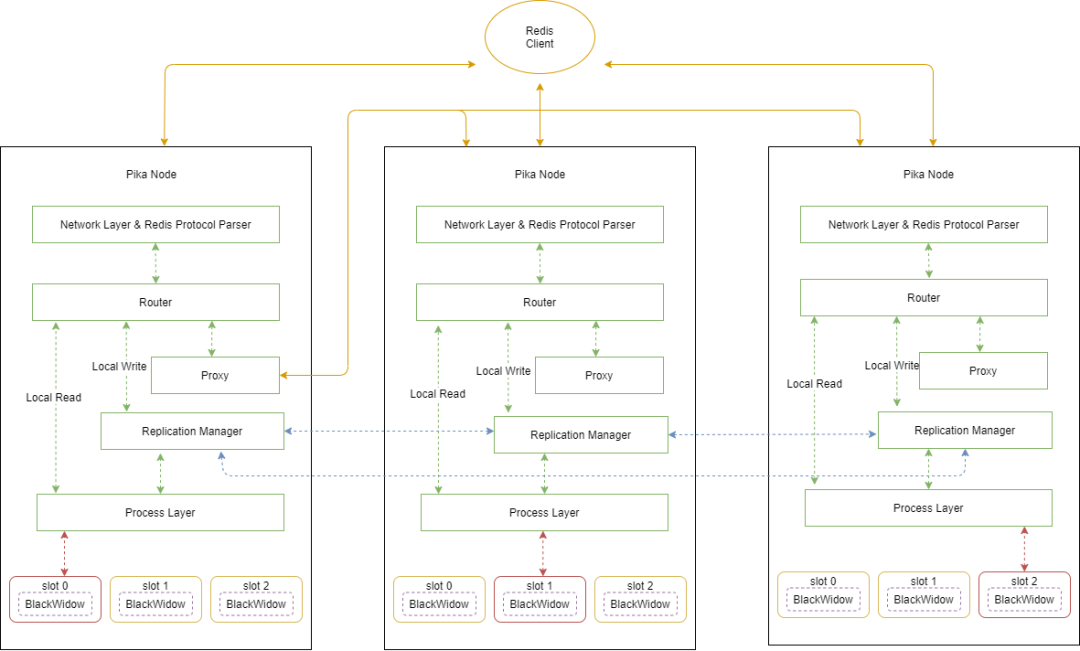
当 pika 节点接收到用户请求时,解析层处理解析 redis 协议,并把解析好的结果交给 router 层进行判断。
router 根据 key 的 hash 结果找到 key 对应的 slot,并判断 slot 是否在本地节点上。
如果 key 所在的 slot 在其他节点,则根据请求创建一个 task 放入队列中,并把请求转发给 peer 节点来处理。当 task 接收到请求的处理结果后把请求返回给客户端。
如果 key 所在的 slot 属于本地节点,就直接本地处理请求并返回给客户端。
对于需要本地处理的写请求,先通过 replication manager 模块写 binlog,异步复制到其他 slot 副本。process layer 根据一致性的要求,写入 leader slot。其中 blackwidow 是对 rocksdb 的接口封装。
我们把 proxy 内嵌的 pika 中,不需要单独部署。与 redis cluster 相比,客户端不需要感知 proxy 的存在,只需像使用单机一样使用集群。可以把 pika 节点的服务端口挂载到 LVS 中,实现压力在整个集群的负载均衡。
日志复制
pika 中 replication manager 模块负责日志的主从同步。为了兼容 redis,pika 支持非一致日志复制,leader slot 直接在 db 中写入数据而无需等待从 follower slot 的 ack 应答。同时也支持 raft 一致性协议方式的日志复制,需要满足收到大多数副本的 ack 才写入 db。
非一致日志复制
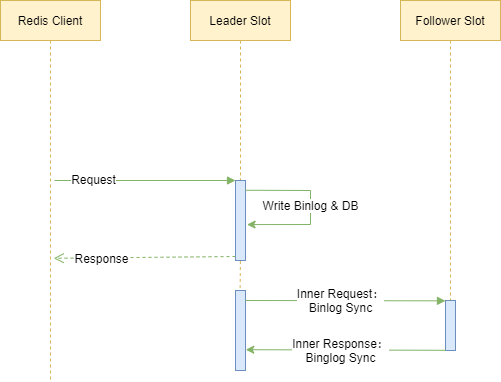
在非一致场景下处理流程如下:
处理线程接收到客户端的请求,直接加锁后写入 binlog 和并操作 db。
处理线程返回客户端 response。
辅助线程发送 BinlogSync 同步请求给 follower slot,同步日志。
follower slot 返回 BinlogSyncAck 报告同步情况。
一致性日志复制
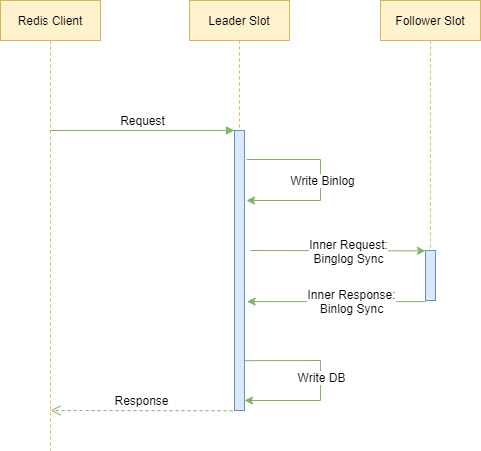
在一致性日志复制场景下:
处理线程把客户端请求写入 binlog 文件
通过发送 BinlogSync 请求向从库同步
从库返回 BinlogSyncAck 报告同步状况
检查从库应答满足大多数后将相应的请求写入 db
将 response 返回客户端
集群元数据处理
我们在 codis-dashboard 的基础上二次开发了 pika manager(简称 PM),作为整个集群的全局控制节点,用来部署和调度管理集群。PM 里保存了整个集群的元数据及路由信息。
增加了集群创建多表的功能,方便业务根据表的不同来实现业务数据隔离。
支持创建表时指定 slot 数目和副本数目,方便运维根据业务的规模和故障容忍度创建 table。
从逻辑上把 group 的概念改为 replication group,使得原来的进程级别的数据和日志复制转变为 slot 级别的复制。
支持创建 table 时创建密码来隔离业务的使用。客户端只需要执行 auth 和 select 语句就可以认证并对指定的 table 进行操作。
支持 slot 迁移,方便根据业务需求进行扩容和缩容。
集成哨兵模块,PM 会不断的向集群中的 pika 节点发送心跳,监测存活状态。当 PM 发现 leader slot down 时,会自动提升 binlog 偏移最大的 slave slot 为 leader。
存储后端支持元数据写入 etcd,保证元数据的高可用。
pika manager 通过不断向 etcd 争抢锁来成为 leader,来实现 pika manager 的高可用。
后记
pika 原生集群的推出解决了单机 pika 受限于磁盘容量的限制,可以按照业务的需求进行水平扩容。但仍然有一些缺陷,如基于 raft 的内部自动选主功能的缺失,基于 range 的数据分布,及监控信息的展板等功能。后续版本我们会一一解决这些问题。




