

在 DIVE 全球基础软件创新大会 2022 上,阿里云程序语言与编译器团队负责人李三红出品了《DIVE编程语言新风向专场》专题。本文整理自字节跳动高级工程师马春辉在DIVE 全球基础软件创新大会 2022的演讲分享,主题为“字节大规模微服务语言发展之路”。
以下为演讲整理内容。
Golang 现状
Golang(Go 语言)从 09 年开源到现在,短短十多年时间,已经快速成为编程领域非常热门的一门语言,根据 2019 年的 JetBrains 的统计,现在全球有两百多万名开发者,并且还在持续增长。国外很多公司,比如 Google、Uber,国内也有像字节、腾讯等等,都在比较大规模使用 Go 语言,以至于很多人把 Go 称为云原生最佳语言。
在字节内部,微服务使用最多的语言就是 Golang。但字节也不是一开始就使用 Golang。最早期用的是 Python,在 2014 年,我们经历了一场大规模的微服务开发的过程,从Python转向 Golang。据说一个最主要的原因是当时 Python 对 CPU 资源利用率不高,当时负责语言选型的同学经过调研,最终选择了 Golang。现在看来,这位同学眼光非常超前。
当时为什么没有选择Java?Java 有非常多优点,一直到现在都具有统治力。但是站在微服务角度,它有一些固有缺点,比如说资源开销。并行时资源开销越低,意味着部署密度越高,计算成本越低。而 Java 在运行过程中,要花费较多资源进行 JIT 编译。另外,JVM本身要占用大概五六十兆左右的内存,而在微服务中,内存不能超卖超售,所以相对来说,JVM 本身占用的内存比较多。另外,JVM 还要占用大概一两百兆左右的磁盘,对于分布式架构的微服务来说,会影响分发部署速度。此外,Java 的启动速度也一直比较令人诟病,对于需要快速迭代和回滚的微服务来说,启动速度慢会影响交付效率和快速回滚,也有可能让用户感受到访问延迟。当然,Java 也一直在优化。比如说 CDS,还有这几年开始兴起的静态编译。但是很遗憾,字节进行语言选型时,这些项目还不存在。另外可能还有一个没有选择 Java 的原因,就是当时负责语言选型的同学不是特别喜欢 Java。
Golang 优势
中科院的崔慧敏教授说过这么一句话:“设计编程语言一直有两个目标,一个是让编程越来越容易,另外一个就是在新的硬件架构出现以后,可以充分利用硬件特质,发挥更高性能。”
Golang 就是让编程越来越容易的一种语言,它在开发效率和性能之间取得了比较好的平衡。
Golang 有很多优点。首先,它从语言层面上支持高并发。它自带了 Goroutine、也就是协程,可以比较充分地利用多核的性能,让程序员更容易使用并发。其次,它非常简单易学,并且开发效率非常高。Go 的关键字只有 25 个,对比一下 C11,大概有 40 多个关键字。虽然 Go 的关键字数量更少,但是表达能力很强大,几乎支持大多数其他语言里一些比较好用的特性。它的编译速度也非常快。
Golang 存在的问题
Golang 作为一个开源语言,而且 Go team 的核心成员也曾公开表示 Go 完全开源,并且也积极拥抱社区,但是,社区内一直有这样一个说法:“Go 是 Google 的 Go,而不是社区的 Go”。比较典型的一个故事就是 Go 的 module 的发展历史,或者说它的上位史。一般来说,Go 的发展一直被 Google 的 Go Team 核心团队牢牢把控,外界的声音、社区的声音,对 Go 语言的发展来说似乎没那么重要,也就是说,外界很难主导设计一个完整的特性。当然,关于社区的事情,目前我们也在积极筹备,希望能够得到社区的一些良好反馈。
另外一个问题是,随着微服务越来越庞大,包括单个微服务越来越大,以及部署微服务的容器数量也越来越大,达到一定的程度之后,会遇到越来越多性能方面的问题,我们在后续会重点介绍。
此外还有一个问题,微服务数量上来之后,会遇到一些观测问题。
性能问题
前面提到,随着单个微服务本身大小的增加,以及部署微服务的机器数量越来越多,我们遇到越来越多的性能问题。这些性能问题,可以分为以下两个方面,一个是 GC,这是属于内存管理的一个问题;另外一个是编译生成代码的质量问题。另外在调度(Scheduling)这块,我们也有同事在进行一些优化分析工作。
性能问题之 GC
首先我们谈一下 GC 的问题,或者说内存管理的问题。
内存管理包括了内存分配和垃圾回收两个方面,对于 Go 来说,GC 是一个并发-标记-清除(CMS)算法收集器。但是需要注意一点,Go 在实现 GC 的过程当中,过多地把重心放在了暂停时间——也就是 Stop the World(STW)的时间方面,但是代价是牺牲了 GC 中的其他特性。
我们知道,GC 有很多需要关注的方面,比如吞吐量——GC 肯定会减慢程序,那么它对吞吐量有多大的影响;还有,在一段固定的 CPU 时间里可以回收多少垃圾;另外还有 Stop the World 的时间和频率;以及新申请内存的分配速度;还有在分配内存时,空间的浪费情况;以及在多核机器下,GC 能否充分利用多核等很多方面问题。非常遗憾的是,Golang 在设计和实现时,过度强调了暂停时间有限。但这带来了其他影响:比如在执行的过程当中,堆是不能压缩的,也就是说,对象也是不能移动的;还有它也是一个不分代的 GC。所以体现在性能上,就是内存分配和 GC 通常会占用比较多 CPU 资源。
我们有同事进行过一些统计,很多微服务在晚高峰期,内存分配和 GC 时间甚至会占用超过 30%的 CPU 资源。占用这么高资源的原因大概有两点,一个是 Go 里面比较频繁地进行内存分配操作;另一个是 Go 在分配堆内存时,实现相对比较重,消耗了比较多 CPU 资源。比如它中间有 acquired M 和 GC 互相抢占的锁;它的代码路径也比较长;指令数也比较多;内存分配的局部性也不是特别好。因此我们有同学做优化的第一件事就是尝试降低内存管理,特别是内存分配带来的开销,进而降低 GC 开销。
我们这边同学经过调研发现,很多微服务进行内存分配时,分配的对象大部分都是比较小的对象。基于这个观测,我们设计了 GAB(Goroutine allocation buffer)机制,用来优化小对象内存分配。Go 的内存分配用的是 tcmalloc 算法,传统的 tcmalloc,会为每个分配请求执行一个比较完整的 malloc GC 方法,而我们的 Gab 为每个 Goroutine 预先分配一个比较大的 buffer,然后使用 bump-pointer 的方式,为适合放进 Gab 里的小对象来进行快速分配。我们算法和 tcmalloc 算法完全兼容,而且它的分配操作可以随意被 Stop the world 打断。虽然我们的 Gab 优化可能会造成一些空间浪费,但是在很多微服务上测试后,发现 CPU 性能大概节省了 5%到 12%。
性能问题之生成代码
另外一个问题是 Golang 生成代码的质量问题。Go 的编译器相比传统编译器来说,可以说实现得比较简陋,优化的数量比较少。Go 在编译阶段总共只有 40 多个 Pass,而作为对比,LLVM 在 O2 的时候就有两百多个优化的 Pass。Go 在编译优化时,优化算法的实现也大多选择那些计算精度不高,但是速度比较快的算法。也就是说,Go 非常注重编译时间,导致生成代码的效率不高。
对于我们微服务的一些场景来说,可以不用那么在意编译速度。我们很多微服务,编译一次后会部署到几万个,甚至几十万个核上运行,而且通常会运行比较久。在这种情况下,如果增加一点点编译时间却能够节省 CPU 资源,那么这个开销是可以接受的。
我们在 Golang 编译器的基础上,以编译速度和 binary size 为代价进行了一些优化。当然,我们还是控制了编译速度和 binary size 的代价。比如说我们 binary size 通常的增长大概在 5%到 15%之内,而编译速度也没有降低特别多,大概 50%到 100%左右。
目前我们在编译器上大概有五个优化,我挑两三个重点介绍一下。
第一个优化就是内联优化。内联优化是其他优化的基础,它的作用就是在编译时,把函数的定义替换到调用的位置。函数调用本身是有开销的,在 Go1.17 之前,Go 的传参是栈上传参,函数入栈出栈是有开销的,做函数调用实际上是执行一次跳转,可能也会有指令 cache 缺失的开销。
Golang 原生的内联优化受到比较多限制。比如一些语言特性会阻止内联,比如说如果一个函数内部含有 defer,如果把这个函数内联到调用的地方,可能会导致 defer 函数执行的时机和原有语义不一致。所以这种情况下,Go 没有办法做内联。此外,如果一个函数是 interface 类型的函数调用,那么这个函数也不会被内联。
另外,Go 的编译器从 1.9 才开始支持非叶子节点的内联,虽然非叶子节点的内联默认是打开的,但是策略却非常保守。举个例子,如果在非叶子节点的函数中存在两个函数调用,那么这个函数在内联评估时就不会被内联。另外,从实现的角度上,内联的策略也做得非常保守。我们在字节的 go 编译器中修改了内联策略,让更多函数可以被内联,这样带来的最直接收益就是可以减少很多函数调用开销。虽然单次函数调用的开销可能并不是特别大,但是积少成多,总量也不少。
另外更重要的是,内联之后增加了其他优化的机会,比如说逃逸分析、公共子表达式删除等等。因为编译器优化大多数都是函数内的局部优化,内联相当于扩大了这些优化的分析范围,可以让后面的分析和优化效果更加明显。
当然,内联虽然好,也不能无限制内联,因为内联也是有开销的。比如我们发现,经过内联优化后,binary size 体积大概增加了 5%到 10%,编译时间也有所增加。同时,它还有另外一个更重要的运行时开销。也就是说,内联增加后会导致栈的长度有所增加,进而导致运行时扩栈会增加不小的开销。为了降低扩栈的开销,我们也针对性地调整了一下 Golang 的初始栈大小。
这里再简单介绍一下栈调整的背景。Golang 通过 goroutine 支持高并发,用户可以创建非常多的 goroutine。为了降低对内存的要求,每个 goroutine 的栈就不能像其他语言的线程的栈那样,设置成两兆到八兆这么大的空间,要不然很容易 OOM。在 Linux 上,Golang 的起始栈大小是 2K。Go 会在函数开头时检查一下当前栈的剩余空间,看看是否满足当前函数正常运行的需求,所以会在开头插入一个栈检查的指令,如果发现不能满足,就会触发扩栈操作:先申请一块内存,把当前栈复制过去,最后再遍历一下栈,逐帧地修改栈上的指针,避免出现指针指向老的栈的情况。这个开销是很大的,内联策略的调整会让更多数据分配到栈上,加剧这种现象出现,所以我们调整了 GO 的起始栈大小。
我们收益最大的一个优化应该就是内联策略的优化调整上。另外我们还进行了一些其他优化,比如说前面提的 Gab 优化,我们会在编译期把 Gab 的快速分配路径直接生成到编译器的代码中,这样可以加快分配到 Gab 上的对象的内存分配速度。
因为 Go 的内存分配的优化开销还是比较大的,所以我们一个优化重点就是想办法降低在堆上的分配。而 Golang 分配对象到堆上还是栈上,这个过程由逃逸分析控制,所以我们也进行了一些逃逸分析的优化。
大家可以看到,我们目前在编译器上实现的优化,大多都是通用优化。理论上,所有微服务都可能享受到这些优化的收益,目前我们实际上线的微服务也证明了这点。
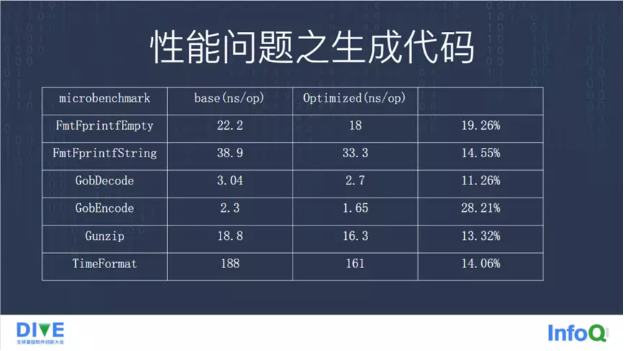
我们看一下这些优化的收益。可以看到,在 Microbenchmark,也就是 Go 自带的那个 Go1 的 benchmark 上,多的有接近 20%的性能提升,少的也有百分之十几。
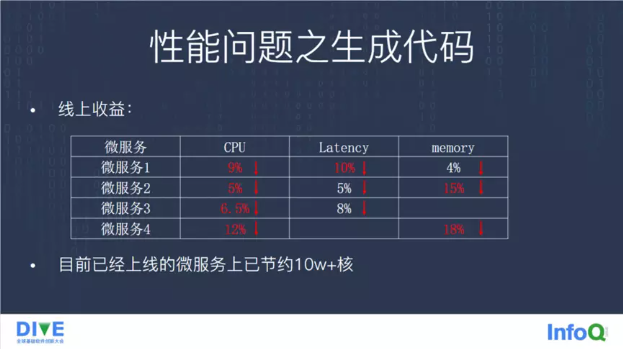
我们发现,基本上线上所有微服务或多或少都会节省一些 CPU 资源。除此之外,延迟也有不同程度的降低,以及内存使用也有不同程度的下降。我们在目前上线的一些微服务上,目前对于高峰期的 CPU,已经节约了大概有十几万核了。
正因为我们在编译器上经过了几个简单的优化,都能得到这么明显的优化效果,所以目前我们有两个策略在走,第一个是继续尝试在 Go 原生编译器里引入更多编译器优化,希望进一步提升 Go 的原生编译器性能;另一个,我们也考虑借助 LLVM 强大的优化能力,把 Go 的源代码编译成 LLVM IR,然后生成可执行代码来进行性能上的优化。
现在社区上已经有这么一个项目,就是 Gollvm,基本可用,但是不支持很多重要的特性。比如说它不支持汇编语言,如果微服务当中或者引用的第三方库里含有 Plan9 的汇编,Gollvm 现在是不支持的。另外,它的 GC 暂时不支持精确栈扫描,采用的是保守栈扫描策略。另外,Gollvm 现在的性能相比 GO 原生编译器还有不小差距。但是我们现在也在调研和研究。
性能问题之观测
另外,在 Go 上线的过程中,我们还发现了一个比较明显的问题,就是性能观测问题,具体来说就是测不准。
它自带的 pprof 工具,结果不是太准确。这在 Go 社区内部也有一些讨论,大概原理是 Go 的 pprof 工具使用 itimer 来发生信号,触发 pprof 采样,但是在 Linux 上,特别是某些版本的 Linux 上,这些信号量可能不是那么准确。根据我们 pprof 的结果来统计,一些容器上大概有 20%甚至 50%的结果被丢掉了。它还有一个问题,在一个线程上触发的信号可能会采样到另外一个 M 上,一个 M 上触发的这个采用信号可能会采到另外一个 M 上的数据。
而 perf 呢,很遗憾,我们很多线上容器内部不支持 perf。出于一些安全策略的考虑,也不允许在线上安装 perf 这样的工具。
可能大家都听说过,Uber 在 Go 上开发了一个 pprof++的工具,类似于 pprof,也是调用 pprof 的一些接口,使用硬件的 PMU 来触发采样。但是 Uber 的 pprof++的一个问题是性能损耗非常大。我们经过一些验证,发现在一些小例子上,在打上 Uber 的 pprof++的 patch 之后,仅仅是打上这个 patch 而不是打开这个 pprof,就有大概 3%左右的性能损耗。我们前面做编译器优化、做内存分配优化,性能提升很多也就提升 5%到 10%,只把这 patch 打上去,性能就损耗了 3%。所以我们不能接受这种性能损耗。
比较幸运的是,Go1.18 之后,它提出了 per-M 这个 pprof,对每个 M 来进行采样,结果相对比较准确。
我们在 Go1.6、1.17 上,也仿照 Uber,采用了 PMU 的 pprof 形式。这种方式实际验证下来,对性能的损耗比较小,我们想办法避免了 Uber 的性能损耗大的问题。此外它还能够提供一些比如 branchmiss/icache 等等更强大的 CPU 采样分析能力。
总结与展望
Golang 还是比较有前景的,而且目前还在迅速发展。
从长期趋势来看,基于更高级编程语言的软件系统会逐步取得竞争优势。因为随着 CPU 等硬件资源的价格进一步下降,而开发成本,开发人力成本,还有项目研发风险以及系统的稳定性、安全性方面,可能会成为更重要的决策和考量。目前来说,Go 不仅拥有非常好的开发效率,也有着可以说媲美 C 的性能,而且它还很好地提供了互联网环境下服务端开发的各种好用特性。所以很多人将 Go 语言称为云原生最佳语言。
当然,未来可能会有一种新语言,有更好的效率、更高的性能,也可能会有更开放的设计开发环境,最终取代 Go。我也非常希望能有这样的新语言出现。
演讲嘉宾:
马春辉,目前在字节跳动从事编程语言相关软件开发支持工作。拥有十余年编译器虚拟机相关软件研发经验,曾参与 HP ACC 编译器、IBMJDK、华为毕昇编译器/虚拟机等项目开发,在编译器、runtime、性能优化等领域有丰富经验。
相关阅读:

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...







评论 2 条评论