

1.背景
ETA(Estimated Time of Arrival,“预计送达时间”),即用户下单后,配送人员在多长时间内将外卖送达到用户手中。送达时间预测的结果,将会以”预计送达时间”的形式,展现在用户的客户端页面上,是配送系统中非常重要的参数,直接影响了用户的下单意愿、运力调度、骑手考核,进而影响配送系统整体成本和用户体验。
对于整个配送系统而言,ETA 既是配送系统的入口和全局约束,又是系统的调节中枢。具体体现在:
ETA 在用户下单时刻就需要被展现,这个预估时长继而会贯穿整个订单生命周期,首先在用户侧给予准时性的承诺,接着被调度系统用作订单指派的依据及约束,而骑手则会按照这个 ETA 时间执行订单的配送,配送是否准时还会作为骑手的工作考核结果。
ETA 作为系统的调节中枢,需要平衡用户-骑手-商家-配送效率。从用户的诉求出发,尽可能快和准时,从骑手的角度出发,太短会给骑手极大压力。从调度角度出发,太长或太短都会影响配送效率。而从商家角度出发,都希望订单被尽可能派发出去,因为这关系到商家的收入。
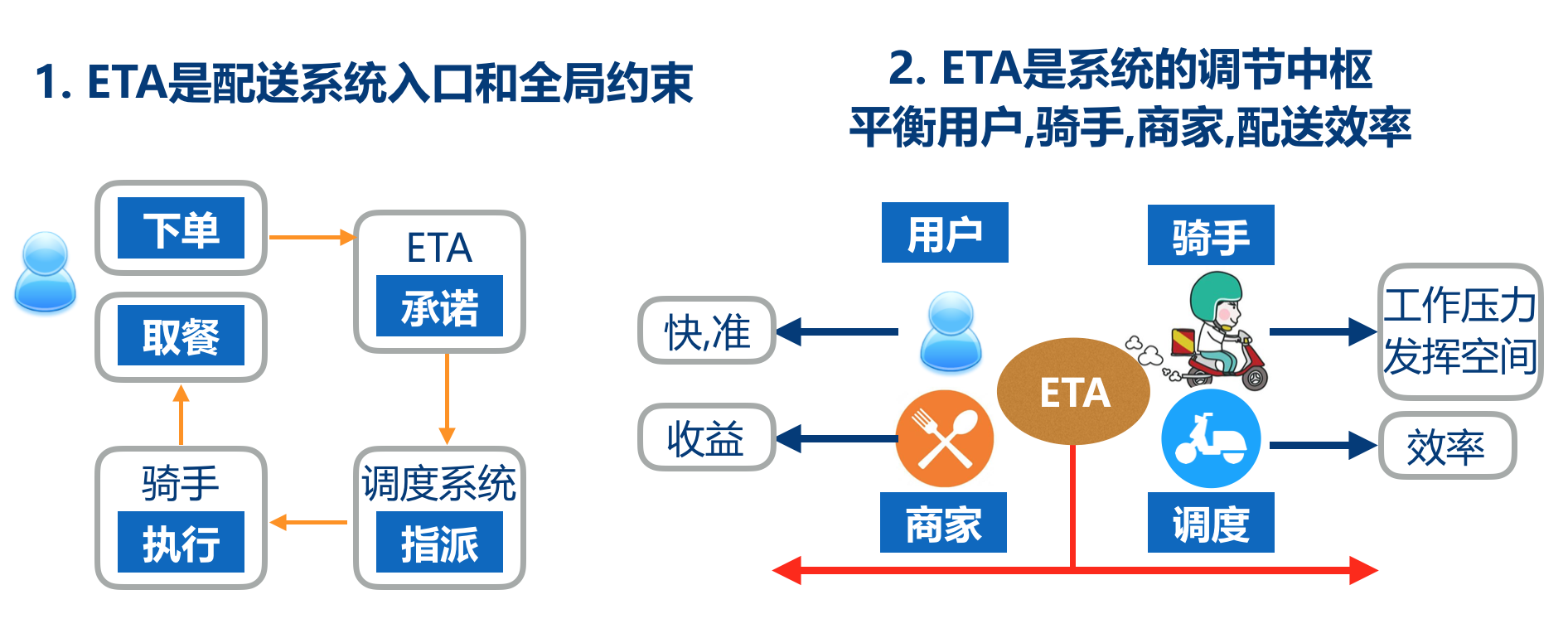
ETA 在配送系统中作用
在这样多维度的约束之下,外卖配送的 ETA 的建模和估计会变得更加复杂。与打车场景中的 ETA 做对比,外卖场景的 ETA 面临如下的挑战:
外卖场景中 ETA 是对客户履约承诺的重要组成部分,无论是用户还是骑手,对于 ETA 准确性的要求非常高。而在打车场景,用户更加关心是否能打到车,ETA 仅提供一个参考,司机端对其准确性也不是特别在意。
由于外卖 ETA 承担着承诺履约的责任,因此是否能够按照 ETA 准时送达,也是外卖骑手考核的指标、配送系统整体的重要指标;承诺一旦给出,系统调度和骑手都要尽力保证准时送达。因此过短的 ETA 会给骑手带来极大的压力,并降低调度合单能力、增加配送成本;过长的 ETA 又会很大程度影响用户体验。
外卖场景中 ETA 包含更多环节,骑手全程完成履约过程,其中包括到达商家、商家出餐、等待取餐、路径规划、不同楼宇交付等较多的环节,且较高的合单率使得订单间的流程互相耦合,不确定性很大,做出合理的估计也有更高难度。
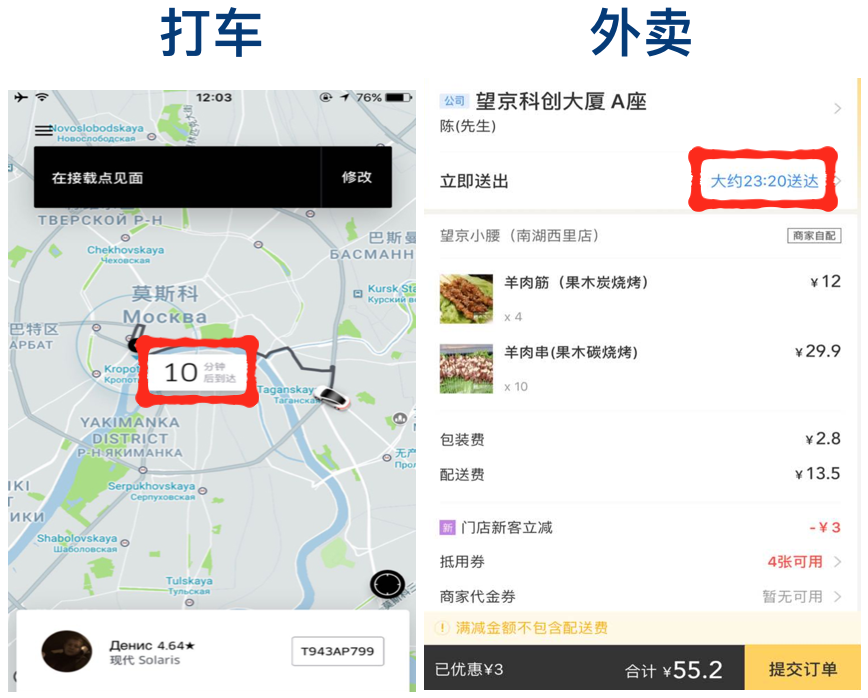
外卖及打车中的 ETA
下图是骑手履约全过程的时间轴,过程中涉及各种时长参数,可以看到有十几个节点,其中关键时长达到七个。这些时长涉及多方,比如骑手(接-到-取-送)、商户(出餐)、用户(交付),要经历室内室外的场景转换,因此挑战性非常高。对于 ETA 建模,不光是简单一个时间的预估,更需要的是全链路的时间预估,同时更需要兼顾”单量-运力-用户转化率”转化率之间的平衡。配送 ETA 的演变包括了数据、特征层面的持续改进,也包括了模型层面一路从 LR-XGB-FM-DeepFM-自定义结构的演变。
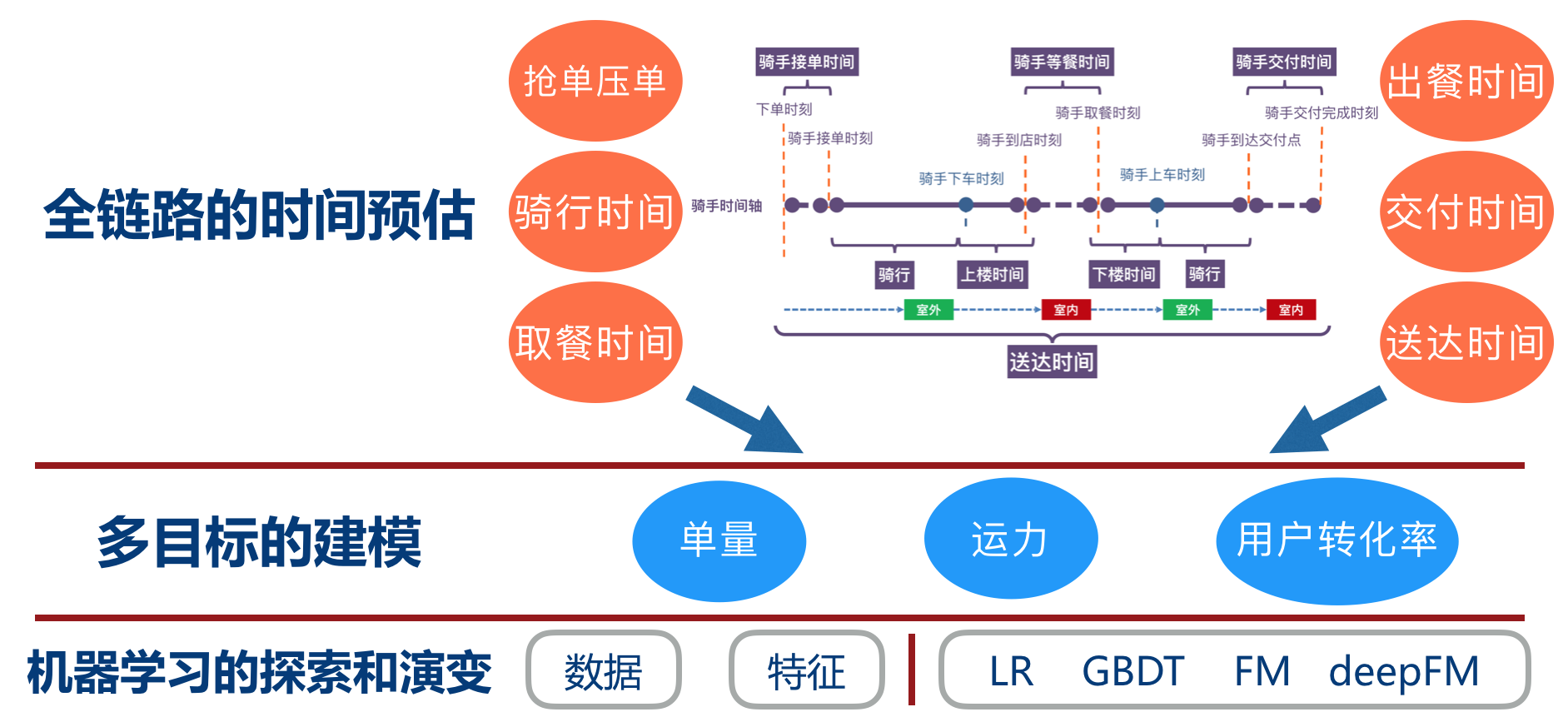
ETA 的探索与演变
具体 ETA 在整个配送业务中的位置及配送业务的整体机器学习实践,请参看《机器学习在美团配送系统的实践:用技术还原真实世界》。
2.业务流程迭代中的模型改进
2.1 基础模型迭代及选择
与大部分 CTR 模型的迭代路径相似,配送 ETA 模型的业务迭代经历了 LR->树模型->Embedding->DeepFM->针对性结构修改的路径。特征层面也进行不断迭代和丰富。
模型维度从最初考虑特征线性组合,到树模型做稠密特征的融合,到 Embedding 考虑 ID 类特征的融合,以及 FM 机制低秩分解后二阶特征组合,最终通过业务指标需求,对模型进行针对性调整。
特征维度逐步丰富到用户画像/骑手画像/商家画像/地址特征/轨迹特征/区域特征/时间特征/时序特征/订单特征等维度。
目前版本模型在比较了 Wide&Deep、DeepFM、AFM 等常用模型后,考虑到计算性能及效果,最终选择了 DeepFM 作为初步的 Base 模型。整个 DeepFM 模型特征 Embedding 化后,在 FM(Factorization Machine)基础上,进一步加入 deep 部分,分别针对稀疏及稠密特征做针对性融合。FM 部分通过隐变量内积方式考虑一阶及二阶的特征融合,DNN 部分通过 Feed-Forward 学习高阶特征融合。模型训练过程中采取了 Learning Decay/Clip Gradient/求解器选择/Dropout/激活函数选择等,在此不做赘述。
2.2 损失函数
在 ETA 预估场景下,准时率及置信度是比较重要的业务指标。初步尝试将 Square 的损失函数换成 Absolute 的损失函数,从直观上更为切合 MAE 相比 ME 更为严苛的约束。在适当 Learning Decay 下,结果收敛且稳定。
同时,在迭代中考虑到相同的 ETA 承诺时间下,在前后 N 分钟限制下,早到 1min 优于晚到 1min,损失函数的设计希望整体的预估结果能够尽量前倾。对于提前部分,适当降低数值惩罚。对于迟到部分,适当增大数值惩罚。进行多次调试设计后,最终确定以前后 N 分钟以及原点作为 3 个分段点。在原先 absolute 函数优化的基础上,在前段设计 1.2 倍斜率 absolute 函数,后段设计 1.8 倍斜率 absolute 函数,以便让结果整体往中心收敛,且预估结果更倾向于提前送达,对于 ETA 各项指标均有较大幅度提升。
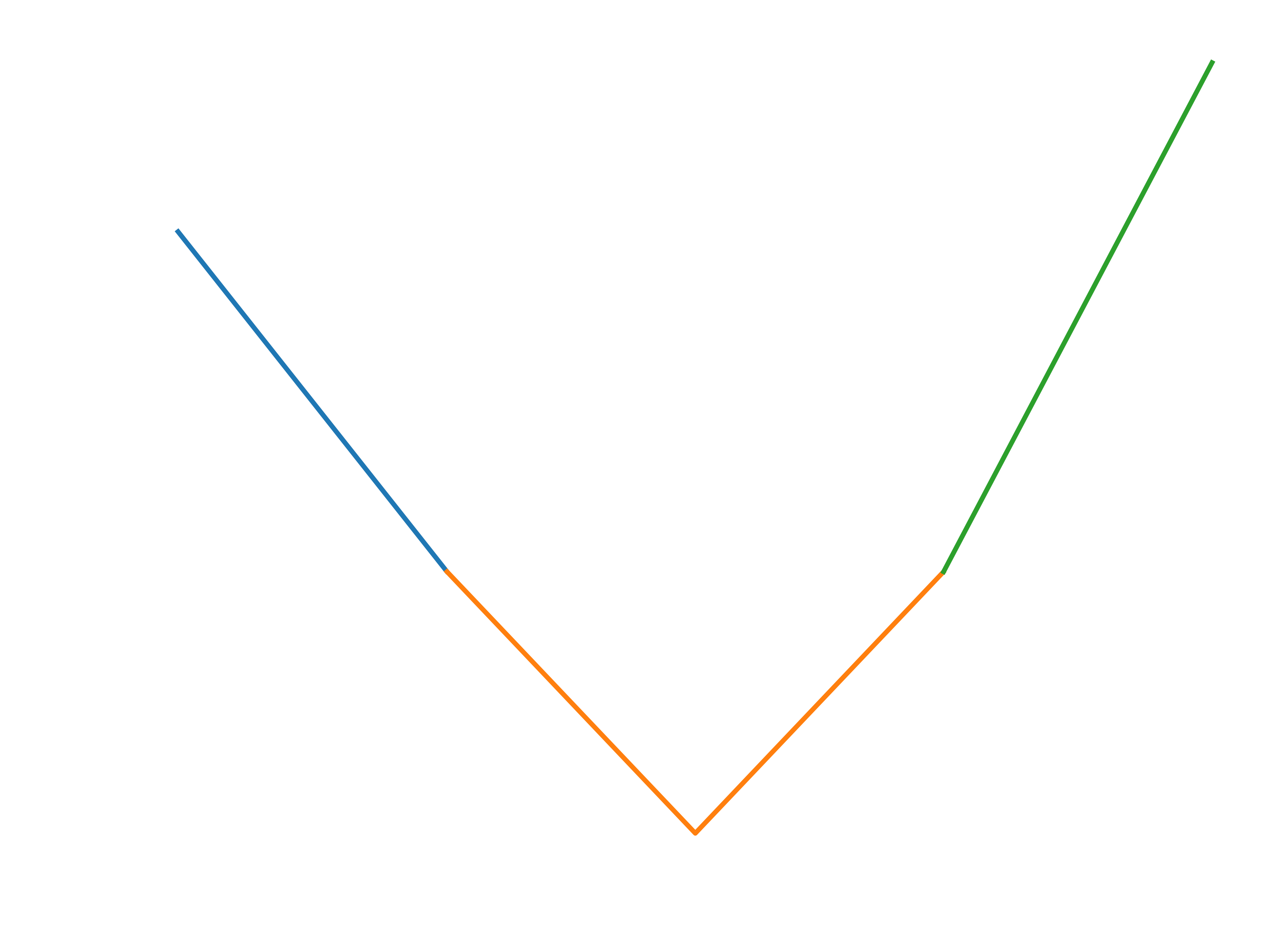
损失函数
2.3 业务规则融入模型
目前的业务架构是”模型+规则”,在模型预估一个 ETA 值之后,针对特定业务场景,会有特定业务规则时间叠加以满足特定场景需求,各项规则由业务指标多次迭代产生。这里产生了模型和规则整体优化的割裂,在模型时间和规则时间分开优化后,即模型训练时并不能考虑到规则时间的影响,而规则时间在一年之中不同时间段,会产生不同的浮动,在经过一段时间重复迭代后,会加大割裂程度。
在尝试了不同方案后,最终将整体规则写入到了 TF 模型中,在 TF 模型内部调整整体规则参数。
对于简单的(a*b+c)*d 等规则,可以将规则逻辑直接用 TF 的 OP 算子来实现,比如当 b、d 为定值时,则 a、c 为可学习的参数。
对于过于复杂的规则部分,则可以借助一定的模型结构,通过模型的拟合来代替,过多复杂 OP 算子嵌套并不容易同时优化。
通过调节不同的拟合部分及参数,将多个规则完全在 TF 模型中实现。最终对业务指标具备很大提升效果,且通过对部分定值参数的更改,具备部分人工干涉模型能力。
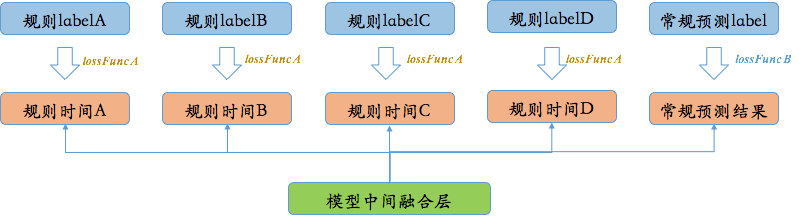
多目标补时结构
在这里,整体架构就简化为多目标预估的架构,这里采用多任务架构中常用的 Shared Parameters 的结构,训练时按比例采取不同的交替训练策略。结构上从最下面的模型中间融合层出发,分别在 TF 内实现常规预测结构及多个规则时间结构,而其对应的 Label 则仍然从常规的历史值和规则时间值中来,这样考虑了以下几点:
模型预估时,已充分考虑到规则对整体结果的影响(例如多个规则的叠加效应),作为整体一起考虑。
规则时间作为辅助 Label 传入模型,对于模型收敛及 Regularization,起到进一步作用。
针对不同的目标预估,采取不同的 Loss,方便进行针对性优化,进一步提升效果。
模型结构在进行预估目标调整尝试中:
尝试过固定共享网络部分及不固定共享部分参数,不固定共享参数效果明显。
通常情况下激活函数差异不大,但在共享层到独立目标层中,不同的激活函数差异很大。
2.4 缺失值处理
在模型处理中,特征层面不可避免存在一定的缺失值,而对于缺失值的处理,完全借鉴了《美团“猜你喜欢”深度学习排序模型实践》文章中的方法。对于特征 x 进入 TF 模型,进行判断,如果是缺失值,则设置 w1 参数,如果不是缺失值则进入模型数值为 w2*x,这里将 w1 和 w2 作为可学习参数,同时放入网络进行训练。以此方法来代替均值/零值等作为缺失值的方法。
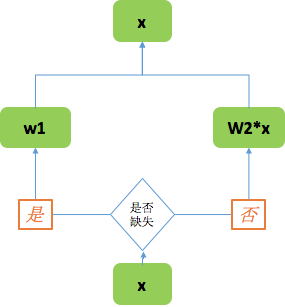
缺失值处理
3.长尾问题优化
3.1 模型预估结果+长尾规则补时
基础模型学习的是整体的统计分布,但对于一些长尾情形的学习并不充分,体现在长尾情形下预估时间偏短(由于 ETA 拥有考核骑手的功能,预估偏短对骑手而言意味着很大的伤害)。故将长尾拆解成两部分来分析:
业务长尾,即整体样本分布造成的长尾。主要体现在距离、价格等维度。距离越远,价格越高,实际送达时间越长,但样本占比越少,模型在这一部分上的表现整体都偏短。
模型长尾,即由于模型自身对预估值的不确定性造成的长尾。模型学习的是整体的统计分布,但不是对每个样本的预估都有“信心”。实践中采用 RF 多棵决策树输出的标准差来衡量不确定性。RF 模型生成的决策树是独立的,每棵树都可以看成是一个专家,多个专家共同打分,打分的标准差实际上就衡量了专家们的“分歧”程度(以及对预估的“信心”程度)。从下图也可以看出来,随着 RF 标准差的增加,模型的置信度和准时率均在下降。
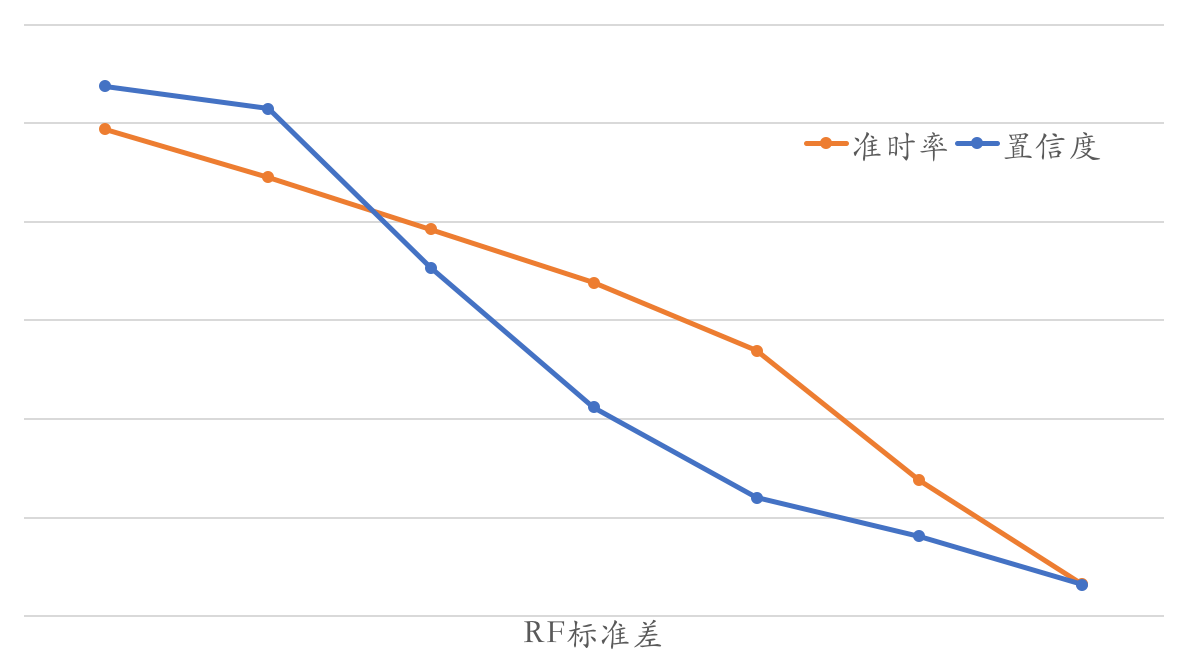
模型长尾因子
在上述拆解下,采用补时规则来解决长尾预估偏短的问题:长尾规则补时为 <业务长尾因子 , 模型长尾因子> 组合。其中业务长尾因子为距离、价格等业务因素,模型长尾因子为 RF 标准差。最终的 ETA 策略即为模型预估结果+长尾规则补时。
4.工程开发实践
4.1 训练部分实践
整体训练流程
对于线下训练,采取如下训练流程:
Spark 原始数据整合 -> Spark 生成 TFRecord -> 数据并行训练 -> TensorFlow Serving 线下 GPU 评估 -> CPU Inference 线上预测
整个例行训练亿级数据多轮 Epoch 下流程持续约 4 小时,其中 TF 训练中,考虑到 TF 实际计算效率并不是很高,有很大比例在数据 IO 部分,通过 Spark 生成 TFRecord 部分,在此可将速度加速约 3.6 倍。而在数据并行训练部分,16 卡内的并行度扩展基本接近线性,具备良好的扩展性。由于 PS 上参数量并未达到单机无法承受,暂时未对参数在 PS 上进行切分。Serving 线下 GPU 评估部分,是整个流程中的非必需项,虽然在训练过程中 Chief Worker 设置 Valid 集合可有一定的指标,但对全量线下,通过 Spark 数据调用 Serving GPU 的评估具备短时间内完成全部流程能力,且可以指定大量复杂自定义指标。
数据并行训练方式
整个模型的训练在美团的 AFO 平台上进行,先后尝试分布式方案及单机多卡方案。考虑到生产及结果稳定性,目前线上模型生产采用单机多卡方案进行例行训练。
分布式方案:
采用 TF 自带的 PS-Worker 架构,异步数据并行方式,利用tf.train.MonitoredTrainingSession协调整个训练过程。整个模型参数存储于 PS,每个 Step 上每个 Worker 拉取数据进行数据并行计算,同时将梯度返回,完成一次更新。目前的模型单 Worker 吞吐 1~2W/s,亿级数据几轮 Epoch 耗时在几小时内完成。同时测试该模型在平台上的加速比,大约在 16 块内,计算能力随着 Worker 数目线性增加,16 卡后略微出现分离。在目前的业务实践中,基本上 4-6 块卡可以短时间内完成例行的训练任务。
单机多卡方案:
采用 PS-Worker 的方案在平台上具备不错的扩展性,但是也存在一定的弊端,使用 RPC 的通讯很容易受到其他任务的影响,整个的训练过程受到最慢 Worker 的影响,同时异步更新方式对结果也存在一定的波动。对此,在线上生产中,最终选取单机多卡的方案,牺牲一定的扩展性,带来整体训练效果和训练速度的稳定性。单机多卡方案采取多 GPU 手动指定 OP 的 Device,同时在各个 Device 内完成变量共享,最后综合 Loss 与梯度,将 Grad 更新到模型参数中。
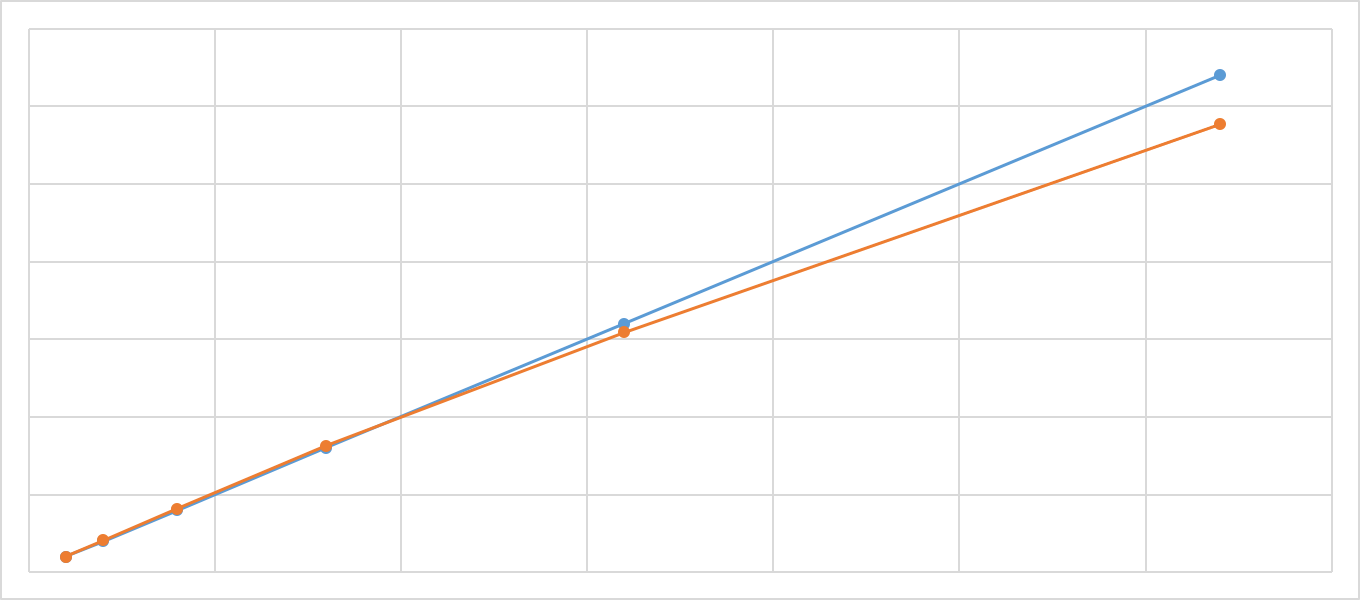
加速比曲线
TF 模型集成预处理
模型训练过程中,ID 类特征低频过滤需要用到 Vocab 词表,连续型特征都需要进行归一化。这里会产生大量的预处理文件,在线下处理流程中很容易在 Spark 中处理成 Libsvm 格式,然后载入到模型中进行训练。但是在线上预测时,需要在工程开发端载入多个词表及连续型特征的归一化预处理文件(avg/std 值文件等),同时由于模型是按天更新,存在不同日期版本的对齐问题。
为了简化工程开发中的难度,在模型训练时,考虑将所有的预处理文件写入 TF 计算图之中,每次在线预测只要输入最原始的特征,不经过工程预处理,直接可得到结果:
对于 ID 类特征,需要进行低频过滤,然后制作成词表,TF 模型读入词表的 list_arr,每次 inference 通过 ph_vals,得到对应词表的 ph_idx。
对于连续型特征,在 Spark 处理完得到 avg/std 值后,直接写入 TF 模型计算图中,作为 constant 节点,每个 ph_in 经过两个节点,得到相应 ph_out。
4.2 TF 模型线上预测
配送机器学习平台内置了模型管理平台,对算法训练产出的模型进行统一管理和调度,管理线上模型所用的版本,并支持模型版本的切换和回退,同时也支持节点模型版本状态的管理。
ETA 使用的 DeepFM 模型用 TensorFlow 训练,生成 SavedModel 格式的模型,需要模型管理平台支持 Tensorflow SavedModel 格式。
实现方案 S 线上服务加载 TensorFlow SavedModel 模型有多种实现方案:
自行搭建 TensorFlow Serving CPU 服务,通过 gRPC API 或 RESTful API 提供服务,该方案实现比较简单,但无法与现有的基于 Thrift 的模型管理平台兼容。
使用美团 AFO GPU 平台提供的 TensorFlow Serving 服务。
在模型管理平台中通过 JNI 调用 TensorFlow 提供的 Java API TensorFlow Java API,完成模型管理平台对 SavedModel 格式的支持。
最终采用 TensorFlow Java API 加载 SavedModel 在 CPU 上做预测,测试 batch=1 时预测时间在 1ms 以内,选择方案 3 作为实现方案。
远程计算模式
TensorFlow Java API 的底层 C++动态链接库对 libstdc++.so 的版本有要求,需要 GCC 版本不低于 4.8.3,而目前线上服务的 CPU 机器大部分系统为 CentOS 6, 默认自带 GCC 版本为 4.4.7。如果每台线上业务方服务器都支持 TensorFlow SavedModel 本地计算的话,需要把几千台服务器统一升级 GCC 版本,工作量比较大而且可能会产生其他风险。
因此,我们重新申请了几十台远程计算服务器,业务方服务器只需要把 Input 数据序列化后传给 TensorFlow Remote 集群,Remote 集群计算完后再将 Output 序列化后返回给业务方。这样只需要对几十台计算服务器升级就可以了。

在线序列化
线上性能
模型上线后,支持了多个业务方的算法需求,远程集群计算时间的 TP99 基本上在 5ms 以内,可以满足业务方的计算需求。

线上效果
总结与展望
模型落地并上线后,对业务指标带来较大的提升。后续将会进一步根据业务优化模型,进一步提升效果:
将会进一步丰富多目标学习框架,将取餐、送餐、交付、调度等整个配送生命周期内的过程在模型层面考虑,对订单生命周期内多个目标进行建模,同时提升模型可解释性。
模型融合特征层面的进一步升级,在 Embedding 以外,通过更多的 LSTM/CNN/自设计结构对特征进行更好的融合。
特征层面的进一步丰富。
作者简介
基泽,美团点评技术专家,目前负责配送算法策略部机器学习组策略迭代工作。
周越,2017 年加入美团配送事业部算法策略组,主要负责 ETA 策略开发。
显杰,美团点评技术专家,2018 年加入美团,目前主要负责配送算法数据平台深度学习相关的研发工作。
本文转载自美团技术博客:https://tech.meituan.com/2019/02/21/meituan-delivery-eta-estimation-in-the-practice-of-deep-learning.html

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论