

一、背景
当用户在线上浏览酒店时,作为旅行平台,如何挑选更合适的酒店推荐给用户,降低其选择的费力度,是需要考虑的一个问题。在携程 APP 中,一般会触发多种场景。在 Figure 1 中,我们列举了几种典型的场景:欢迎度排序,智能排序和搜索补偿推荐。
Figure1:用户触发的场景
欢迎度排序:在异地场景下,当用户没有明确表达自己需求的情况下,默认按照欢迎度排序展示酒店;
智能排序:在同城或者当用户在浏览上述排序结果的过程中,发现自己的兴趣并没有得到满足的时候,往往会添加筛选条件。比如添加地标选项,从而获得该地标附近的相关酒店。相比欢迎度排序,用户表达了更多的个性化需求。
搜索补偿推荐排序:如果用户在当前搜索的展示结果中,还是没有找到满足自己需要的酒店,就会不断往下翻页查看更多的搜索结果。而当满足搜索限制条件的酒店数目不足时,会触底。这个时候就会触发搜索补偿推荐。前面两个场景都没有满足用户需求,所以在搜索补偿场景中,我们需要深入挖掘用户历史行为,提供更加个性化的推荐内容。
本文将主要介绍我们在补偿推荐场景中所做的算法优化工作。包含模型迭代、模型迭代过程中遇到的技术需求以及针对技术需求所做的一些基建等。
二、推荐模型的迭代
在酒店推荐的场景中,我们需要把满足用户需求的产品优先曝光给用户,减少其使用产品的费力度。我们以用户在酒店的 TOP 点击(编者注:可以简单理解为用户点击排在 TOP 位置酒店的概率,TOP 点击命中率越高,用户体验越好)和转化命中率(CR)作为费力度指标;CR 优化问题被建模成二分类问题,离线采取 AUC 和 NDCG 作为模型效果评估标准。
分类问题的本质就是要找到一条决策边界函数 f(x),来把正样本(比如成单)和负样本(比如没有成单)数据分开。这里,x 就是模型特征,好的特征能更好地表征正负样本的差异,让函数学习事半功倍;学习函数 f(x)的过程就是建模过程。在本节中,我们分别介绍下我们在特征和建模方面所尝试的工作。
2.1 特征
推荐特征使用的特征可以分为:用户侧特征、物品侧特征以及用户和物品的交互特征。从特征的数值特性上,又可以分成:连续值特征和离散值特征。算法刚开始接入的时候,我们的模型只有连续值特征。后经历了从完全连续值特征,到离散特征比重越来越重的过程。
连续值特征既有静态的(比如用户的性别,酒店价格等),也有基于用户行为的动态的(比如用户点击某个酒店的次数)。连续值特征的优点是具备良好的泛化能力。一个用户对一个商圈的偏好可以泛化到另外一个对这个商圈有相同统计特性的用户身上。连续值特征的缺点是缺乏记忆能力导致区分度不高。比如:在同一个商圈酒店列表中,一个用户点击了(A,B,C,D),而另外一个用户点击了(W,X,Y,Z)。虽然两个用户的行为序列不同,但是统计值特征忘记了用户具体点击了哪些酒店,认为两个用户都是点击了 4 家酒店。
离散值特征是细粒度的特征:设备 ID,用户 ID,用户点击的 item ID 都可以做特征。这样一来不同的人,有不同的行为就可以在特征上有很好的区分度,因此离散值特征是模型可以把千人千面做得更进一步的基础。
离散特征的优点就是记忆力强区分度高。我们还可以让离散特征通过特征组合的方式,挖掘用户对于酒店更深层次的兴趣偏好:比如点击 item A 的人也喜欢 item B,我们可以直接基于(A,B)生成一个组合离散特征,来学习 A 和 B 的协同信息。
离散特征的缺点是泛化能力相对较弱。这是因为特征粒度太细,预测的时候命中率会偏低。同时在模型训练的时候,细粒度的特征相对粗粒度的特征更容易获得权重,让泛化能力强的粗粒度的特征学到的信息更少,进一步的恶化了模型的泛化能力。
举一个例子来说:每个样本都有一个唯一的样本 id,如果我们以样本 id 为特征,那么我们模型训练的时候,样本 id 特征可以完美的拟合 label;但实际测试中,会发现因为模型严重过拟合而效果非常差。这是设计离散特征需要考虑的特征记忆性和泛化性的 tradeoff,也就是特征尽可能细和特征在测试数据中命中率尽可能高的 tradeoff。
我们结合业务场景,探索出技术方案:可以让离散值特征在线上也有良好的泛化能力,从而最终让模型兼具较强的记忆能力和泛化能力。在工程方面:因为组合特征的存在,我们特征空间会很大(e.g. 现在酒店推荐场景特征可以轻松到亿级别),对模型训练和在线 serving 工程提出新的挑战。这也是我们在推进大规模离散 DNN 训练框架要解决的关键问题。
2.2 模型
我们模型经历了从 Logistic Regression (LR),Gradient BoostingDecision Tree(GBDT)到 Deep Neural Network(DNN)的迭代过程。在业务开始阶段,数据量和特征量都比较少,通常会采用 LR 模型。随着算法的迭代,数据量和特征规模越来越多的时候,基于 XGBOOST 或者 LightGBM 构建 GBDT 模型是业务成长期快速拿到收益的好的选择。当数据量越来越大的时候,需要基于 DNN 的框架来把个性化模型做的更细。下面对三种模型的特点做一些简单的介绍。
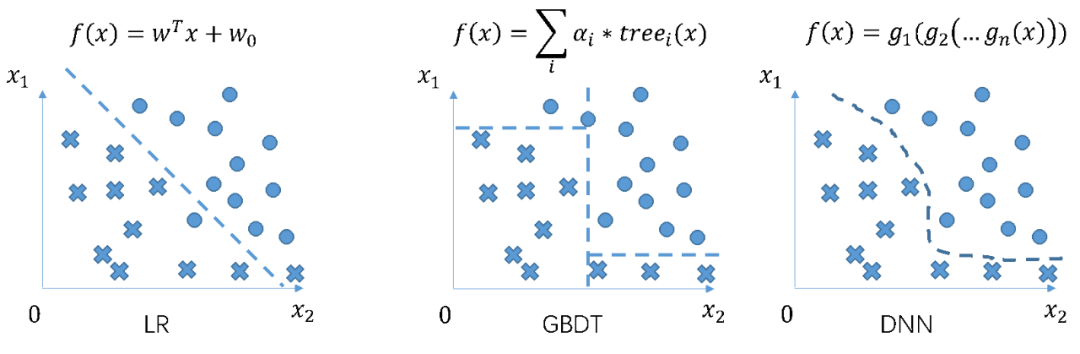
Figure2:模型决策边界
在 Figure 2 中,展示了三个模型的决策边界:
LR
在 LR 里,决策边界函数是线性的。
模型的优点:可以通过模型的权重大小,解释特征的重要性;同时 LR 支持增量更新;在引入大规模离散特征的情况下,业界在 LR 时代的经典做法是对 LR 加 L1 正则并通过 OWLQN 或者 Coordinate Descent 的方式进行优化,也可以通过 FTRL 算法让模型稀疏避免过拟合。
模型的缺点:线性决策边界这个假设太强,会让模型的精度受到限制;另外,模型的可扩展性程度低。
GBDT
在 GBDT 中,决策边界是非线性的;模型通过将样本空间分而治之的方式,来提高模型精度。
模型的优点:树模型可以计算每个特征的重要性程度,来获得一些可解释性;同时模型比 LR 有更高的精度。
模型的缺点:不支持大规模的离散特征,不支持增量更新;模型可扩展性程度低。
我们在酒店推荐场景中,尝试了 pointwise loss 和 pairwise loss,每次尝试都获得了不少的提升。
DNN
在 DNN 中,决策边界是高度非线性的。我们知道计算机通过与或非这种简单的逻辑,可以表达各种复杂的对象:音频,视频,网页等。而 DNN 每一层网络比与或非更加复杂,DNN 通过多层神经元叠加,成为一个万能函数逼近器。在理想情况下,只要有足够的数据量,不论我们实际的决策边界如何复杂,我们都可以通过 DNN 来表达。
同时 DNN,支持增量更新,支持根据业务场景进行灵活定制各种网络结构,支持大规模离散 DNN,在离散模型中学习出来的 Embedding 向量还可以用在向量相似召回里面。正因为有这么多的好处,DNN 正在成为业界推荐算法的标配。
这个模型的缺点是:特征经过不同层交叉,交互耦合关系过于复杂,而导致可解释性不好;工程复杂度在我们用不同结构的时候所有不同。
下面的表总结了三个模型的特点:
酒店推荐算法
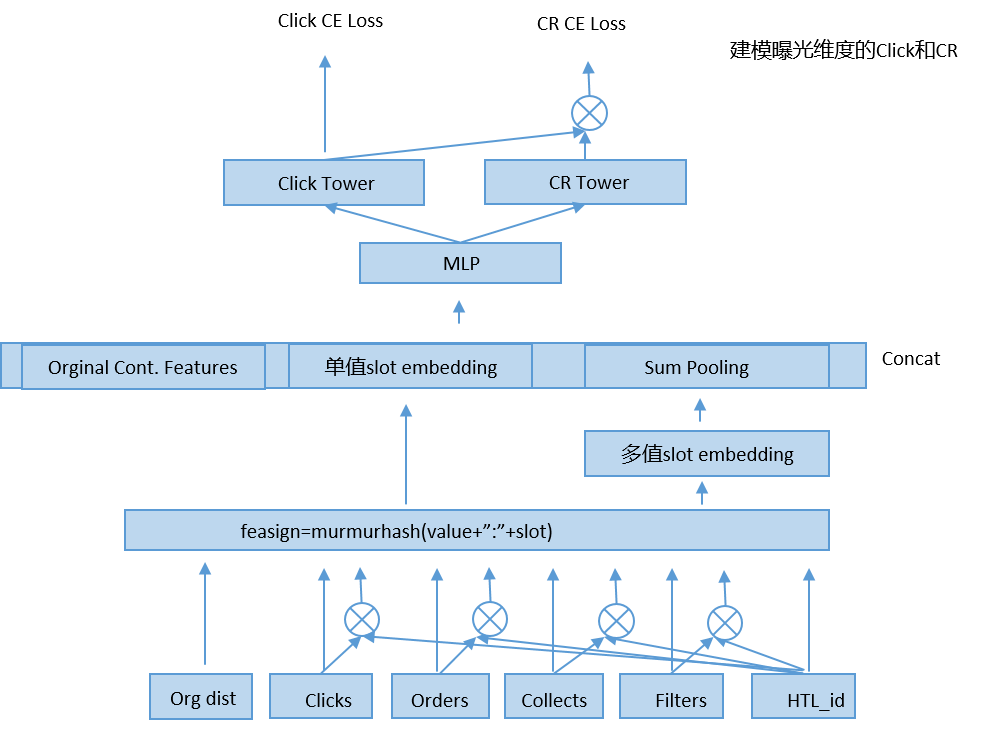
Figure 3:模型结构
用户在酒店的行为包括点击(click)和转化(CR)。在 LR 和 GBDT 的算法迭代阶段,我们优化目标只用到了 CR 信息。后来在 DNN 模型优化过程中,在模型建模中也引入了 click 信息,主要有两方面的考虑:
1)相对 CR,click 行为更加稠密;同时 click 也能反映一定的用户个性化偏好。所以合理的利用稠密的 click 信息,会对最终 CR 的学习有所帮助。
2)在酒店列表中,用户是先有点击,再有转化。对用户的行为漏斗建模,方便分析转化不好是哪个阶段导致的。对因为点击率偏低导致转化低的酒店,可以做定向优化和机制上的细节调整。
在引入了 click 信息后,需要解决的是如何进行多目标建模的问题。因为 DNN 结构灵活,我们尝试了各种多目标学习的方式,最后采取了 Figure 3 所示的 ESMM 的模型结构。整个模型从下到上包括如下三个步骤。
1)离散特征签名:签名是通过 hash 函数使“特征-slot”映射到 feasign,作为特征的唯一标示。每个 feasign 会通过模型学习得到一个 K 维 embedding 向量。
2)Pooling 和 Concat:离散特征由单值离散和多值离散组成:单值离散是指一个 slot 只有一个唯一值,比如用户 id;多值离散则是一个 slot 会有多个值,比如用户历史点击行为。相同的 slot 会放到一起做 sum pooling,这一操作把多值离散从 N*K 维向量映射为 1*K 维 embedding 向量;再和单值离散的 1*K 维 embedding concat 连接。
3)Multilayer Perceptron(MLP)和损失函数:通过 pooling 和 concat 将每条样本映射为固定长度的 1*M 维向量,通过全连接神经网络,以交叉熵为损失函数拟合是否点击、转化两个二分类目标。
基于以上的模型框架,我们相对 pairwise 的 GBDT 模型,有了显著的提升。后来在以上模型结构的基础上,我们针对离散特征,做了更多模型交叉的尝试,其中 Deep Cross Network(DCN)模型结构,在用户费力度指标和 AUC/NDCG 这些模型指标上都获得了非常大的提升。
在模型推进的过程中,我们也遇到了很多问题。包括如何做 normalization、如何处理异常值和缺省值、在从 LR 到 GBDT 再到 DNN 升级中如何处理数据分布变化,这些细节对最终模型线上效果都有直接的影响。当然还有一些很基础性的困难,是跟工程团队一起克服推进的。这个困难主要包括两方面:
1)DNN 模型结构灵活,在离散特征加成下,规模也很大。我们需要一个模型训练平台,支持我们定义 any model 并且支持 any scale 规模模型的训练。
2)在 DNN 这种复杂的非线性模型下,线上线下不一致问题会被放大。一个直接的影响是线下 AUC 提升很明显,但是线上效果是负向的。
针对这两个问题,我们开发了一套大规模离散 DNN 模型训练框架和统一特征处理框架,分别解决以上两个问题。
三、推荐工程的演进
针对策略需求,推荐中台做了很多的标准化服务。在本章节中,我们主要介绍推荐中台里面的大规模离散 DNN 训练框架和特征处理框架。
3.1 大规模离散 DNN 训练框架
大规模离散 DNN 模型因为具备很高精度和灵活性,成为目前业界做推荐算法的主流方法。但要推进大规模离散 DNN 在我们业务场景中落地,有一个前提:需要一个能训练大规模离散 DNN 模型的框架。我们结合长期实践经验,开发了一套分布式大规模离散 DNN 训练平台。这个平台具备如下特点:
支持任意形式的模型 Any Model:训练框架前端采取 tensorflow。Tensorflow 允许我们定义任意在推荐中常用的网络结构,并提供网络结构梯度计算功能。
支持任意规模的模型 Any Scale:训练框架后端是一个异步参数服务器;服务器节点可以任意横向扩展。服务器会做梯度融合和权重更新的工作。
开箱即用的默认参数:参数服务器中的参数(学习率,初始值范围)和权重更新函数是经过长期实践的结果;用这组默认的参数,不用调参,基本上在我们碰到的推荐业务场景都具备良好的效果。DNN 调参是比较关键的,参数调整不合适会直接影响模型精度;而因为 DNN 的复杂性,调参往往需要较长的时间摸索。我们调研的相对通用的默认参数,是目前上线快速迭代的前提。
模型框架有如下几个部分组成:
Front 前端:采取 Tensorflow,策略同学通过 python 编写模型结构;tensorflow 本身提供灵活的网络结构定义和梯度计算能力。Tensorflow 是我们策略扩展性的保障。
Client 端:Front 通过 Client 和 Server 进行通信;通信的内容就是(feasign, grads/weights)。Client 可以看作一个路由器:feasign 可以看作是 ip,我们根据 feasign 把相应的特征分发到相应的 server 机器上;而 grads/weights 可以看作通讯报文;而通信 push/pull 可以看作 http 的 post/request 请求。
Server 端:基于 BRPC 协议,用 c++编写的后台。目前酒店推荐模型扫描一天只需要 6 分钟,训练效率高于 xgb。Server 端把每次请求里相同的梯度信息做 merge,并且根据自定义的优化器进行权重更新。Server 可以通过增加节点来横向扩展。Server 是我们工程能力扩展性的保障。
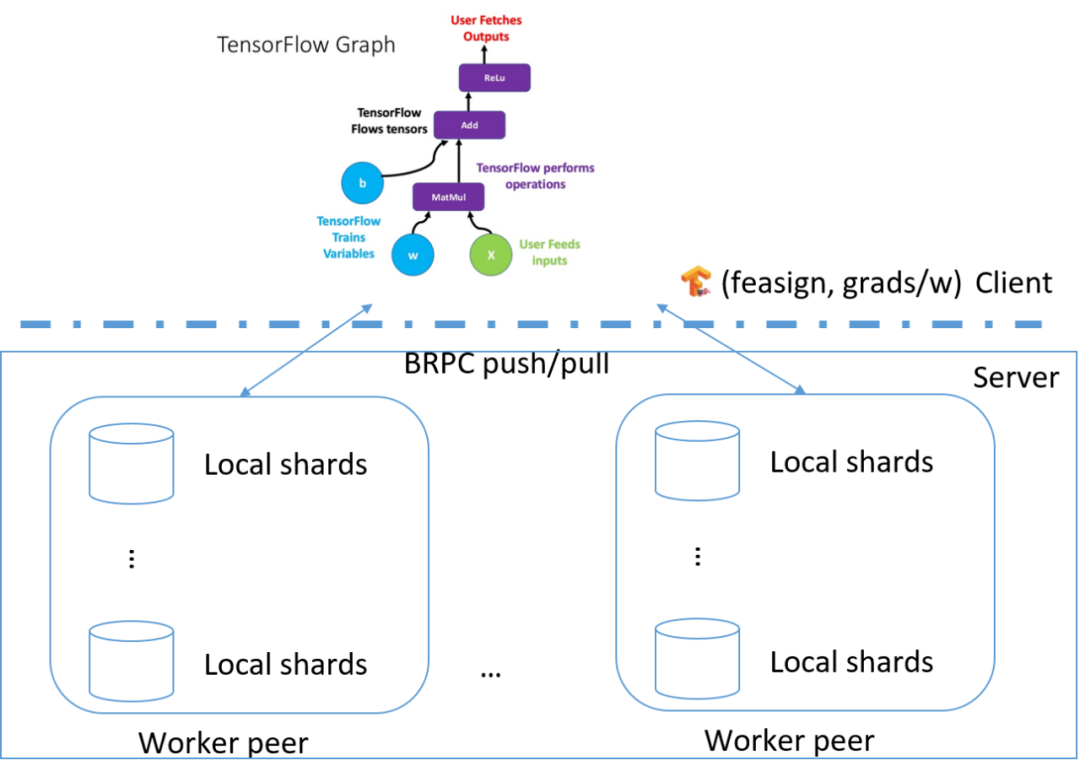
我们构建了分布式训练集群,开发了 python API 接口以支持用户模型任务的创建,任务队列的管理以及日志监控等。现在这套大规模离散 DNN 的训练框架以中台服务的形式,同时支持着许多其他场景推荐模型的迭代。
3.2 统一特征处理框架
线上线下不一致是目前推荐算法应用常见的问题。出现这个问题的本质原因有两个方面:
1)输入不一致:在业务的早期,我们并没有完善的落日志服务。离线训练数据的输入来自 hive 表的落盘数据;而线上的特征是来自近线数据服务。虽然工程同学建立了一定的数据同步机制,但仍然难以保证线上和线下数据严格一致。
2)OP 不一致:在业务早期,离线特征处理 OP 的逻辑是由策略的同学在 hive 调度框架上以 hive sql 的形式实现的;而线上代码则由策略同学跟工程的同学沟通后,由工程的同学开发的 java OP。这里面既存在策略工程两边同学沟通代价,也带来了因为不同人在实现 OP 细节的时候存在的不一致。
如果没有标准的框架来做特征处理的话,每次上线都会花很多时间在分析、排查线上线下问题上。
针对这个问题,推荐中台专门开发了一套统一的特征处理框架。在这个框架里面,我们做到了数据跟框架的解耦,以方便框架做不同业务场景的扩展。数据以标准化的 Protobuf(PB)协议定义,线上用户请求的时候框架会填充 PB 里面的上下文、用户侧和 Item 侧的信息。线上用这个 PB 作为特征抽取的输入,并同时异步落盘 PB 数据到 hive 表中。这样一来线上线下特征输入都是同一份 PB 数据,保证输入严格一致。同时我们线上线下用同一个特征抽取 JAR 包,特征配置也是同一份,这样保证 OP 严格一致。
通过这种方式,彻底地解决了线上线下不一致问题。特征抽取框架作为推荐中台模型服务的重要组成部分,支持很多业务场景做标准化的特征工程迭代。在这套框架下,工程同学专注优化框架性能,策略同学专注实现 OP 算子。这样一来,策略工程同学各司其职,减少不必要的沟通代价,增加整体迭代效率。
四、总结
本文主要介绍了我们在推进酒店排序模型迭代过程中,在策略和工程方面做的尝试,线上也取得了不错的效果。实际酒店业务中,排序模型仅仅是整个系统中的一环。线上推荐系统还要综合考虑用户端、平台方和酒店端的多方生态。但不论如何,准确的预估用户的个性化偏好,是任何精细化机制策略的基础。
在未来的工作中,我们还会面临很多挑战。比如酒店业务同学非常关注的黑盒模型的可解释性问题,我们在 DNN 模型可解释方面也做了一些探索性工作。随着基建的愈加完善,我们在算法上面还会有更深入的探索。
作者简介:
Yorkey,携程高级算法专家,主要从事大规模分布式推荐系统设计和算法研发工作。
本文转载自:携程技术中心(ID:ctriptech)
原文链接:干货 | 携程酒店推荐模型优化

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论