

本文讲述了从数据科学转向机器学习工程的途径及意义。
本文最初发表在 Towards Data Science 博客上,经原作者 Caleb Kaiser 授权,InfoQ 中文站翻译并分享。
在过去 20 年,机器学习一直围绕着这样一个问题展开:我们能不能训练一个模型去做一些事情?
当然,有些事情可以是任何任务。比如,预测句子中的下一个单词、识别照片中的面孔、生成某种声音。我们的目标是想看一看,如果我们能够做出准确的预测,那么机器学习是否还有效。
多亏了数据科学家几十年来的研究工作,我们现在才有了如此多的模型,可以用来做很多事:
OpenAI 的 GPT-2(以及现在的 GPT-3),可以生成人们能够阅读的文本,效果还过得去。
像 YOLOv5 这样的对象检测模型(官方版本的争论暂且不提)可以解析每秒 140 帧的视频中的对象。
像 Tacotron 2 这样的文本到语音模型可以生成听起来像人类的语音。
数据科学家和机器学习研究人员所做的工作令人难以置信,因此,第二个问题便自然而然地出现了:
我们可以用这些模型来构建什么?以及我们如何才能做到呢?
这显然不是一个数据科学的问题,而是一个工程问题。为了回答这一问题,一门新学科应运而生:机器学习工程。
机器学习工程是研究如何将机器学习应用到实际问题中
数据科学和机器学习工程之间的区别,一开始可能让人觉得有点难以捉摸,因此,让我们来看一看几个例子,对理解这一区别会很有帮助。
1. 从图像分类到机器学习生成的目录
图像分类和关键词提取分别是计算机视觉和自然语言处理的经典问题。
Glisten.ai 使用一组针对这两项任务训练过的模型创建了一个 API,从产品图像中提取结构化信息:
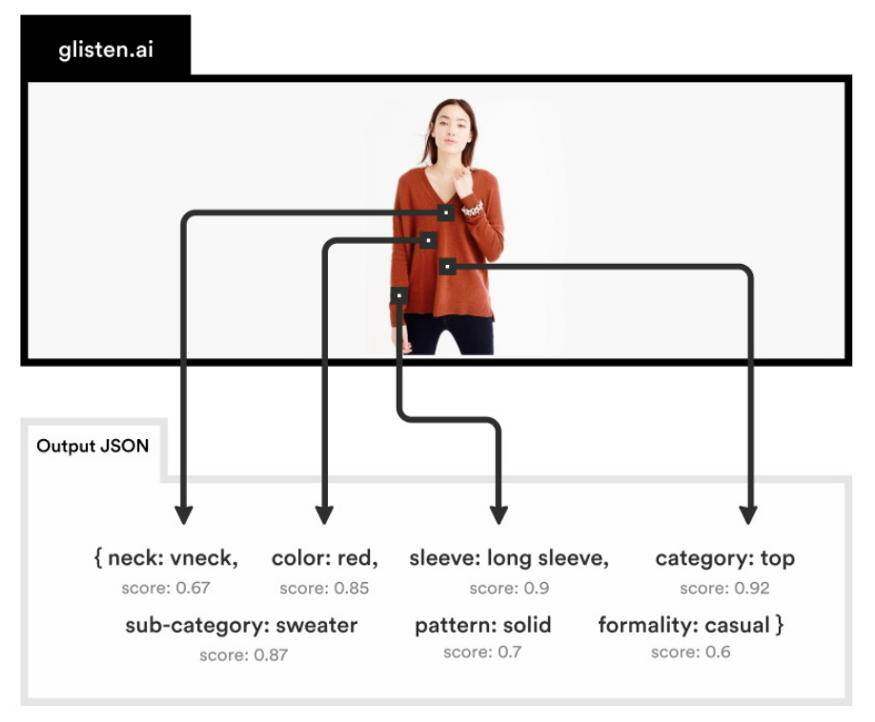
来源:TechCrunch
这些模型本身就是数据科学令人印象深刻的壮举。然而,Glisten API 是机器学习工程的一项壮举。
2. 从对象检测到防止偷猎者
一家小型的非营利组织的野生动物保护解决方案是利用技术来保护濒危物种。最近,他们升级了视频监控系统,加入了一个经过训练的对象检测模型,用来识别偷猎者。该模型的检测率已经提高了一倍。

来源:Silverpond
像 YOLOv4 这样的对象检测模型是数据科学的成功案例,而 Highlighter,用于训练模型的 WPS 平台,是一个令人印象深刻的数据科学工具。然而,WPS 的偷猎者检测系统是机器学习工程的一项壮举。
3. 从机器翻译到 COVID19 的登月计划
机器翻译是指使用机器学习将数据从一种形式“翻译”到另一种形式,有时是在人类语言之间,有时是在完全不同的格式之间。
PostEra 是一个药物化学平台,使用机器翻译将化合富“翻译”成工程蓝图。目前,化学家正在利用这个平台进行开源研究,以寻找针对 COVID19 的治疗方法:
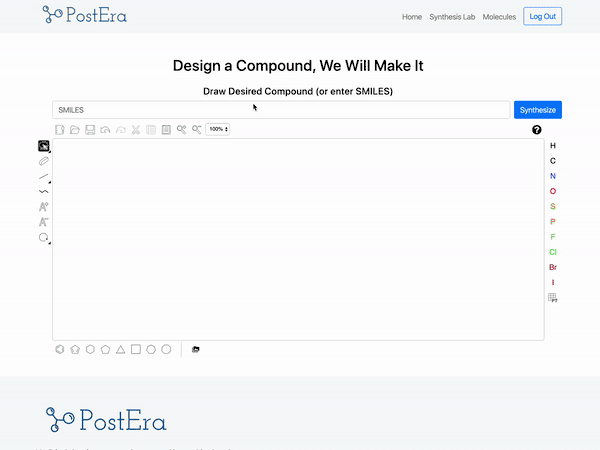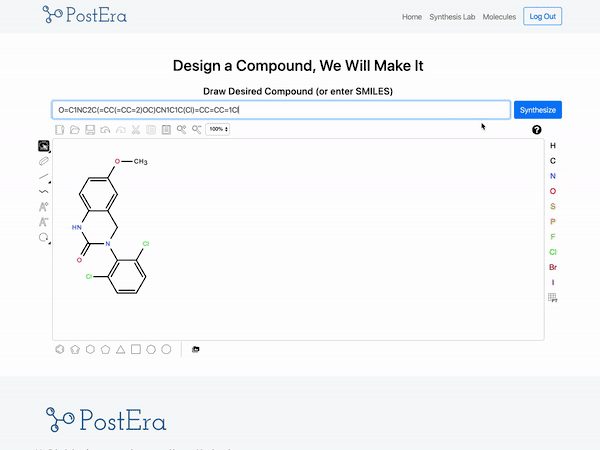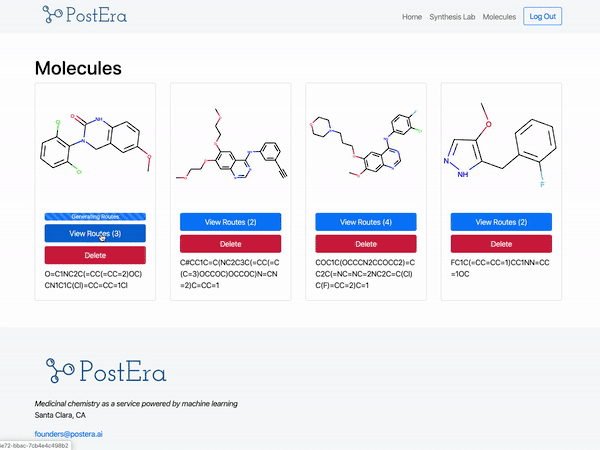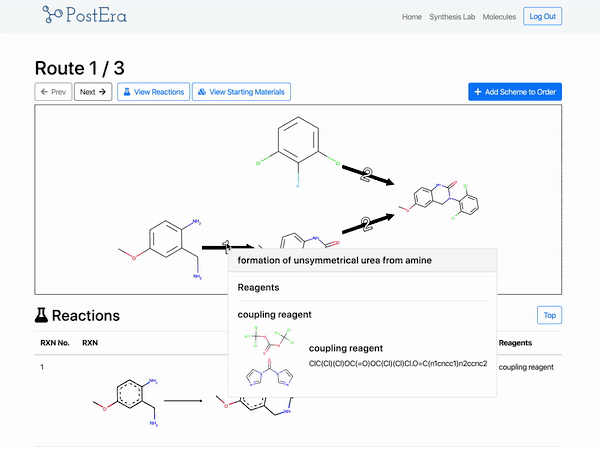
来源:PostEra
开发一种能将分子转化为一系列“路线”(从一个分子到另一个分子的转换)的模型模型是数据科学的一大壮举。而构建 PostEra 平台是机器学习工程的一项壮举。
4. 从文本生成,到机器学习“地下城主”
OpenAI 的 GPT-2 在发布时,是有史以来最强大的文本生成模型。参数高达惊人的 15 亿个,它代表了 Transformer 模型的一大进步。
《AI Dungeon》是一款经典的地牢爬行者(dungeon crawler)游戏,但它有一个转折:它的地下城主其实是 GPT-2,对《选择:故事你决定》(Choose Your Own Advisence Stories)中的文字进行了微调:

训练 GPT-2 是数据科学的一项历史性壮举。用它建造一个地牢爬行者游戏,则是机器学习工程的一项壮举。
然而,机器学习工程面临的主要挑战是,它引入了一种全新的工程问题,这些问题我们目前还没有简单的答案。
机器学习工程包含哪些内容?
在较高的层次上,我们可以这样说,机器学习工程是指采用经过训练的模型并构建生产应用程序所需的所有任务:
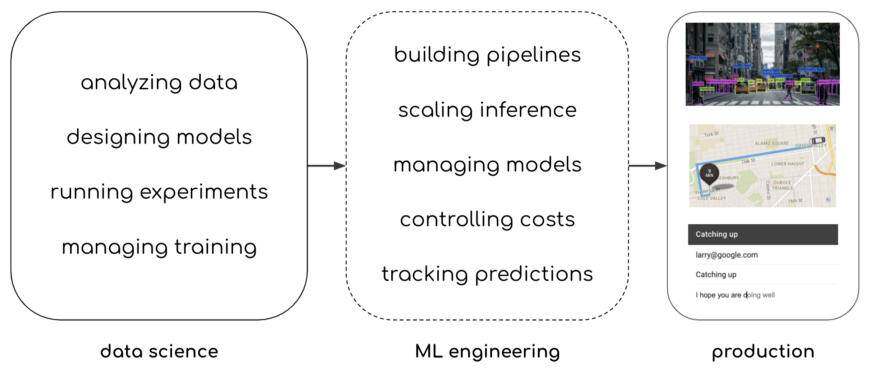
为了让这一点更加具体,我们可以用一个简单的例子来阐明。
让我们回到《AI Dungeon》,由机器学习驱动的地牢爬行者。这款游戏的架构很简单:玩家输入一些文本,游戏调用模型,模型生成响应,然后游戏将响应显示出来。构建它的明显方法是将模型部署为微服务。
理论上,这应该类似于部署任何其他 Web 服务。用类似 FastAPI 之类的东西将模型封装在 API 中,用 Docker 将其容器化,部署到 Kubernetes 集群,并用负载平衡器将其公开。
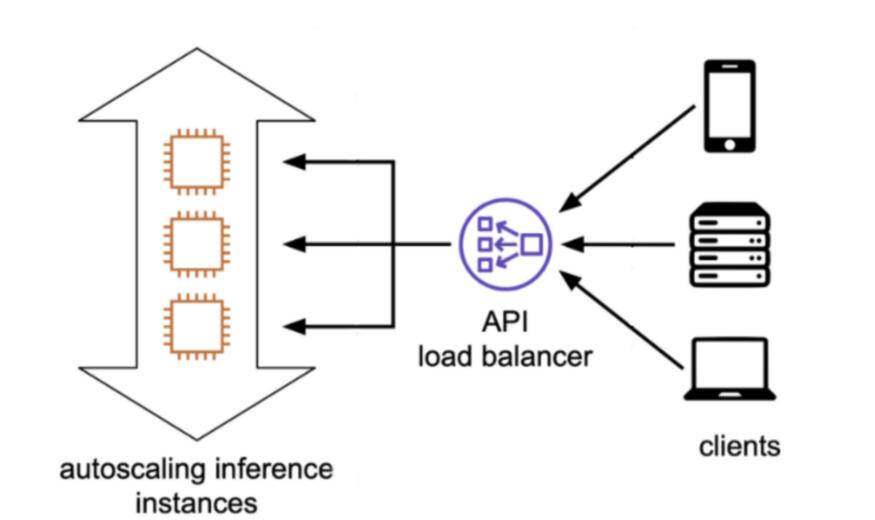
来源:Cortex 推理架构
实际上,GPT-2 使事情复杂化了:
GPT-2 是庞大的。完全训练过的模型大小超过了 5 GB。为了提供服务,你需要一个配置有大型实例类型的集群。
GPT-2 是资源密集型的。单个预测可以锁定 GPU 很长一段时间。低延迟很难实现,单个实例无法同时处理多个请求。
GPT-2 是昂贵的。基于上述事实,将 GPT-2 部署到生产环境就意味着(假设你有相当大的流量),你将运行许多大型 GPU 实例,这会变得非常昂贵。
当你考虑到游戏发布后很快就拥有超过 100 万玩家时,这些问题就会变得更加严重了。
编写一个高性能的 API,使用 GPU 实例提供一个集群,使用 Spot 实例来优化成本,为推理工作负载配置自动缩放,实现滚动更新以便 API 不会在每次更新模型时崩溃——这是大量的工程工作,而且这还是一个简单的机器学习应用程序。
许多机器学习应用程序都需要一些共同的特性:如再训练、监视、多模型断电、批预测等,每一个特性都会显著提高复杂性。
解决这些问题是机器学习工程师(与机器学习平台团队合作,具体要取决于组织)所做的事情,而且由于大多数用于机器学习的工具都是为数据科学而不是工程设计的,这使得他们的工作变得更加困难。
幸运的是,这种情况正在改变。
我们正在为机器学习工程而不是数据科学构建一个平台
几年前,我们中的一些人从软件工程过渡到机器学习工程。我们花了几周的时间研究数据科学的工作流程,并编写胶水代码使机器学习应用程序正常工作,之后,我们就开始思考如何将软件工程原理应用于机器学习工程中。
例如,以《AI Dungeon》为例。如果他们正在构建一个普通的 API,一个不涉及 GPT-2 的 API,那么他们将会使用 Lambda 之类的东西,并在 15 分钟内启动他们的 API。然而,由于为 GPT-2 服务的机器学习特有的挑战,来自软件工程的编排工具将无法工作。
但是,为什么这些原理不能继续适用呢?
因此,我们开始研究机器学习工程的工具,这些工具应用了这些原理。我们的开源 API 平台 Cortex 使得机器学习工程师能够尽可能轻松地将模型部署为 API,使用任何软件工程师都熟悉的界面:

来源:Cortex repo
该 API 平台被《AI Dungeon》以及上面列出的其他机器学习初创公司用来部署他们的模型。其背后的设计理念,以及我们在 Cortex 的所有工作,都非常简单:
我们将机器学习工程的挑战视为工程问题,而不是数据科学问题。
对于 API 平台来说,这意味着我们将使用 YAML 和 Python 文件,而不是难以版本化、依赖隐藏状态并允许任意执行顺序的笔记本。我们没有使用带有“Deploy”按钮的 GUI,而是构建了一个 CLI,你可以通过它实际管理部署。
你可以将这一理念应用于生产环境中使用机器学习的许多挑战。
例如,可重复性不仅仅是机器学习的一个挑战。这在软件工程中也是一个问题,但我们使用版本控制来解决这一问题。虽然像 Git 这样的传统版本控制软件并适用于机器学习,但你仍然可以应用这些原理。DVC(Data Version Control,数据版本控制)就是这样做的,它将类似 Git 的版本控制应用于训练数据、代码及其生成的模型。
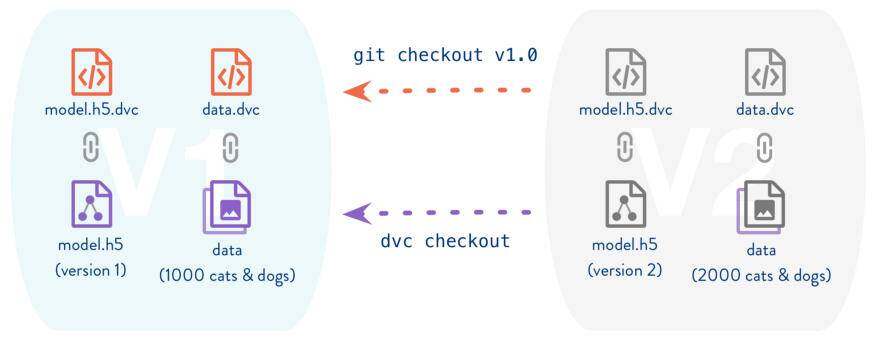
来源:DVC
那么,那些初始化模型和生成预测所需的样板文件和胶水代码文件又该如何处理呢?在软件工程中,我们会为此设计一个框架。
最后,我们在机器学习工程中也看到了这种情况。例如,Hugging Face 的 Transformer 库,为大多数流行的 Transformer 模型提供了一个简单的界面:
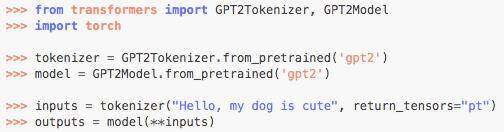
来源:Hugging Face
有了这六行 Python 代码,你就可以从 GPT-2 下载、初始化并提供预测,GPT-2 是最强大的文本生成模型之一。这六行 Python 代码所做的事情,即使是成熟的、资金充足的团队在三年前也难以做到。
我们之所以对这个生态系统如此兴奋,除了我们是其中一部分这一事实之外,还因为它代表了数十年来机器学习研究与人们每天面临的问题之间的桥梁。每当其中一个项目消除了机器学习工程的障碍,新团队解决机器学习问题就会变得容易多了。
在未来,机器学习将会成为每个工程师的一部分。几乎没有什么问题是机器学习不能解决的。这一切发生的速度,完全取决于我们能够以多快的速度开发像 Cortex 这样的平台,并加速机器学习工程的普及。
作者介绍:
Caleb Kaiser,Cortex Lab 创始团队成员,曾在 AngelList 工作,最初在 Cadillac 供职。
原文链接:
https://towardsdatascience.com/moving-from-data-science-to-machine-learning-engineering-68916173eaf3

InfoQ 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论