

本文作者 Raja Sekar 已经有三年多 Spark 的使用经验,他认为 Spark 的 DataFrame 非常优秀,可以解决大多数分析工作负载问题,但仍然有一些地方使用 RDD 会更方便。于是,他萌生出了一个使用原生语言重新实现 Spark 的想法,想看看重写后在性能和资源管理效率方面可以达到怎样的效果。最后他选择了最近很火的 Rust,重写后的 FastSpark 不仅在运行速度上比 Spark 更快,而且能够节省相当多的内存,作者接下来的目标也很简单:将其作为 Apache Spark 的替代方案。
这一切都始于我对各种分布式调度器和分布式计算框架的研究,而 Spark 就是其中的一个。因为有三年多使用 Spark 的经验,所以我对 Spark 的内部原理已经有了一定的了解。Spark 之所以取得巨大成功,不仅是因为速度和效率,还因为它提供了非常直观的 API。pandas 之所以这么流行,也是因为这个。否则的话,如果出于对性能的考虑,人们可以选择其他更好的替代方案,比如 Flink、Naiad 或者像 OpenMP 这样的 HPC 框架。
Spark 是一个通用的分布式框架,RDD 非常适合用来处理非结构化数据或复杂的任务。而现在的 Spark 都是关于 DataFrame 和 SQL,它们比 RDD 更受欢迎。DataFrame 的性能比 RDD 更好。RDD 是 Spark 生态系统的基础,那为什么 DataFrame 会获得更好的性能呢?是因为做了查询优化吗?以最简单的查询为例,你可以使用 RDD 定义出最好的数据和计算流,但 DataFrame 仍然可能胜过你定义的查询。秘密在于 Tungsten 引擎。Spark 的性能主要依赖内存。Spark 在处理典型任务时,JVM 很快就会把资源消耗光。因此,Spark 使用“sun.misc.Unsafe”来直接管理原始内存。这样造成的结果是 DataFrame API 不如 RDD 灵活。它们只能处理固定的预定义数据类型,所以你不能在数据流中自由地使用数据结构或对象。在实际当中,DataFrame 可以解决大多数分析工作负载,但仍然有一些地方使用 RDD 会更方便。
于是,我有了一个使用原生语言重新实现 Spark 的想法,看看它在性能和资源管理效率方面可以达到怎样的效果。Spark 已经经过多年的优化,所以我不指望在性能上能有巨大的差别,如果有,很可能是在内存使用方面。另外,我希望它可以像 Spark 一样通用。我决定使用 Rust 来实现,因为我也没有太多其他的选择。虽然 C++也非常适合做这个,但我更喜欢 Rust 的简洁,而且 Rust 在很多方面与 Scala 相似。如果你看过代码库里的示例代码,就会知道它与典型的 Scala Spark 代码有多么相似。我实现了一个非常基本的版本,支持部分 RDD 操作和转换。不过我还没有实现文件的读取和写入,所以暂时需要手动编写代码来读取文件。
FastSpark 项目开源链接:
https://github.com/rajasekarv/native_spark
性能基准测试使用了一个 1.2TB 的 CSV 文件。
使用了 5 个 GCloud 节点(1 主 4 副);
机器类型:n1-standard-8(8 个 vCPU,30GB 内存)。
这是一个简单的 reduceBy 操作,参考代码:FastSpark和Spark。
FastSpark 使用的时间为:19 分钟 35 秒
Apache Spark 使用的时间为:1 小时 2 分钟
这个结果十分令人惊讶。我并不指望在运行速度方面会有什么不同,我比较期待的是内存的使用情况。因为任务运行在分布式进程上,无法测量 CPU 使用时间,所以我测量了执行节点在程序运行期间的 CPU 使用情况。
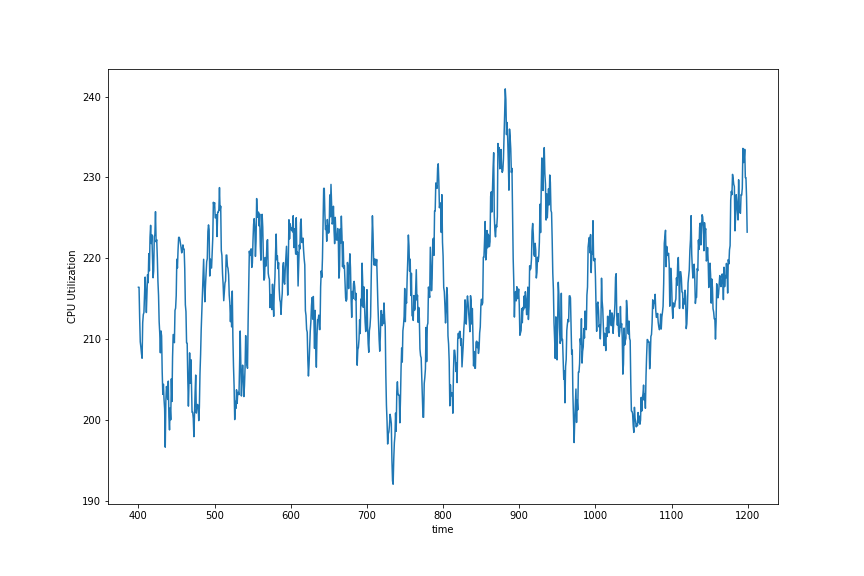
FastSpark
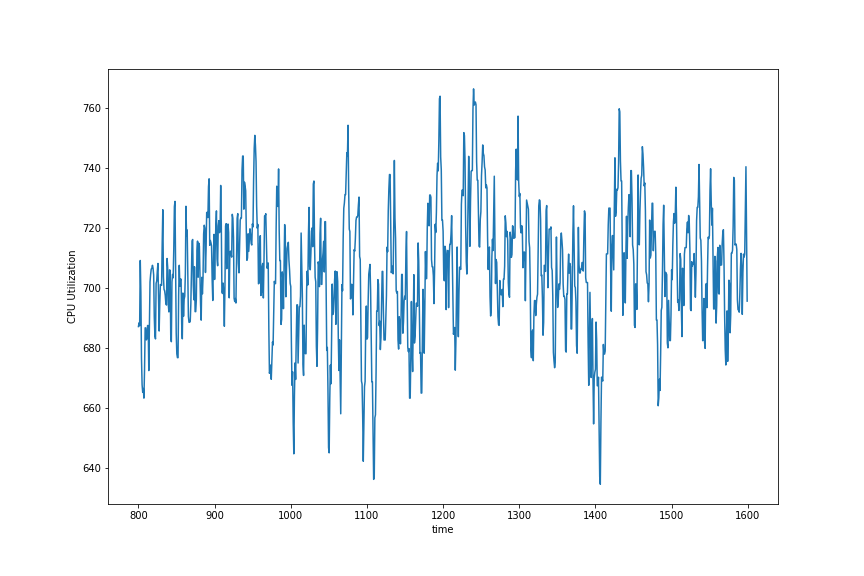
Apache Spark
可以看到,FastSpark 进行了大量的 I/O 操作,CPU 使用率约为 28%,而 Spark CPU 使用率始终为 100%。iotop 显示,FastSpark 在执行期间 I/O 完全饱和,而 Spark 只使用了一半多。
在执行节点上,FastSpark 峰值的内存利用率不超过 150MB,而 Spark 达到了 5-6GB,并在这个范围内波动。这种巨大的差异可能是由于 JVM 对象分配造成的,对象分配是非常昂贵的操作。我最初的实现版本比当前版本慢了两倍多。最初的实现版本使用了很多克隆和装箱,移除掉一部分之后就带来了巨大的性能提升。
同样的逻辑使用 Rust 实现比 FastSpark RDD 要快两倍多。性能分析显示,上述的 FastSpark 程序在分配和系统调用方面占用了 75%的运行时间,主要是因为 Rust 实现的版本为动态分派装箱了大量数据。
下面是在本地运行 4 种不同实现版本的结果(处理 10GB 数据)。文件是 CSV 格式,并且保存在硬盘上(是的,我的硬盘很慢),这里主要关注 user 时间。
Rust 基本版本:
FastSpark 版本:
Apache Spark RDD 版本:
Apache Spark DataFrame版本:
CPU 密集型任务
Spark 的分析任务几乎总是需要消耗大量 CPU,因为我们通常会使用压缩文件,如 Parquet 或 Avro。下面是读取 Parquet 文件(从 10GB CSV 文件生成,800MB 左右)并执行相同操作的结果。
FastSpark 版本:
现在变成需要消耗大量 CPU,它把所有的 CPU 时间都花在解压缩和哈希操作上。
Spark DataFrame 版本:
这就是 Dataframe API 提供的优化结果。代码与之前是一样的,只是用 Parquet 代替了 CSV 格式。但需要注意的是,Spark SQL 生成的代码只选择需要的列,而 FastSpark 使用 get_row_iter 遍历所有行。
我写了一段读取文件的代码,只读取需要的列,让我们看看结果。代码请参考这里。
FastSpark(只选择需要的列):
这样的速度相当快了。它仍然是 IO 密集的。此外,它只使用了大约 400MB 内存,而 Spark DataFrame 使用了 2-3GB。这是我更喜欢 RDD API 的原因之一,我们可以对数据流进行更灵活的控制。虽然抽象对于大多数应用程序来说是没问题的,但有时候我们需要完成一些任务,而具有良好的性能的底层 API 更适用。
实际上,这可以让 FastSpark DataFrame 变得比 Apache Spark DataFrame 更强大、更通用。与 Spark 不一样的是,FastSpark DataFrame 可以支持任意的数据类型,还可以通过为数据类型实现自定义散列来连接具有不同数据类型的列。不过 FastSpark DataFrame 还没有开源出来,因为现在还处在试验阶段。我倾向于选择类似 pandas 那样的设计,不仅灵活,还具有很高的性能。如果有可能,它还可以与 Python 对象进行互操作,但又不同于 PySpark。
这个工作流非常简单,也在非常大型的数据集上运行过,所以我选择了它。当然,这也可能是我的个人偏好。如果可能的话,请读者自己运行代码,并向我反馈结果。Spark 经过了很多优化,特别是 shuffle,在这方面我的实现(非常简单)比 Spark 要慢得多。另外,使用 FastSpark 执行 CPU 密集型任务通常会更快。
主要目标:
将其作为 Apache Spark 的替代方案。这意味着用户端 API 应该要保持一致。
在与 Python 集成方面比 PySpark 做得更好。
已完成:
项目处于非常初级的 POC 阶段,只支持少数的 RDD 操作和转换。
分布式调度器已实现,但离投入生产还差得很远,而且非常脆弱。容错和缓存还没有完成,但应该很快就能完成。
未来规划:
通用的文件读取器很快就可以完成。文件接口与 Spark 的不一样。支持 HDFS 还需要做大量的工作,但支持其他文件系统应该很简单。这个项目的主要目标之一是让它成为 Apache Spark 的完全替代品(至少支持 Python 和 R 语言等非 JVM 语言),所以我将尽量保持用户端 API 的兼容性。
因为代码是试验性的,所以其中有很多硬编码的东西。支持配置和部署将是下一个优先事项。
shuffle 操作实现得还很简单,性能也不好,这个需要改进。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 7 条评论