

导言——AI 大模型以其优异的自然语言理解能力、跨媒体处理能力以及逐步走向通用 AI 的潜力成为近年 AI 领域的热门方向。业内头部厂商近期推出的大模型的参数量规模都达到了万亿、10 万亿级别。
前几天横空出世的 AI 爆款产品 ChatGPT,可以聊天、写代码、解答难题、写小说,其技术底座正是基于微调后的 GPT3.5 大模型,参数量多达 1750 亿个。据报道,GPT3.5 的训练使用了微软专门建设的 AI 计算系统,由 1 万个 V100 GPU 组成的高性能网络集群,总算力消耗约 3640 PF-days (即假如每秒计算一千万亿次,需要计算 3640 天)。
图 1. ChatGPT 的 AI 内容生成
如此大规模、长时间的 GPU 集群训练任务,对网络互联底座的性能、可靠性、成本等各方面都提出极致要求。对此,追求极致高性能与高可用的星脉高性能计算网络面世了。
在最新的自然语言理解任务榜单 CLUE 上,腾讯首个低成本、可落地的 NLP 万亿大模型训练斩获总榜、分类榜和阅读理解榜三个榜首,其在训练速度以及训练精度上全面超越传统算力集群,甚至超过人类水平。而在金榜题名的背后,星脉高性能计算网络为腾讯万亿大模型构筑了高性能网络底座。
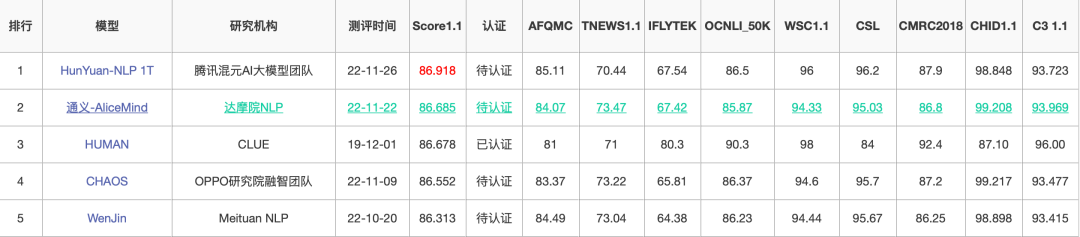
图 2. 自然语言理解任务榜 CLUE
星脉网络在极致高性能上,采用 1.6T 超带宽接入、多轨道聚合流量网络架构、异构网络自适应通信优化技术、定制加速通信库,构建了 1.6T ETH RDMA 网络,实现了 AI 大模型通信性能的 10 倍提升,GPU 利用率 40% 提升,通信时延降低 40%,单集群规模达到 2K(最大规模 32K),基于全自研网络硬件平台网络建设成本降低 30%,模型训练成本节省 30%~60%。在高可用保障上,通过全自动化部署配置核查,覆盖服务器 NUMA、PCIE、NVSwitch、NCCL、网卡、交换机数百个配置项,并通过实时 Service Telemetry 技术监控业务系统运行效率,保障大规模集群部署,实现性能实时监控与故障告警。
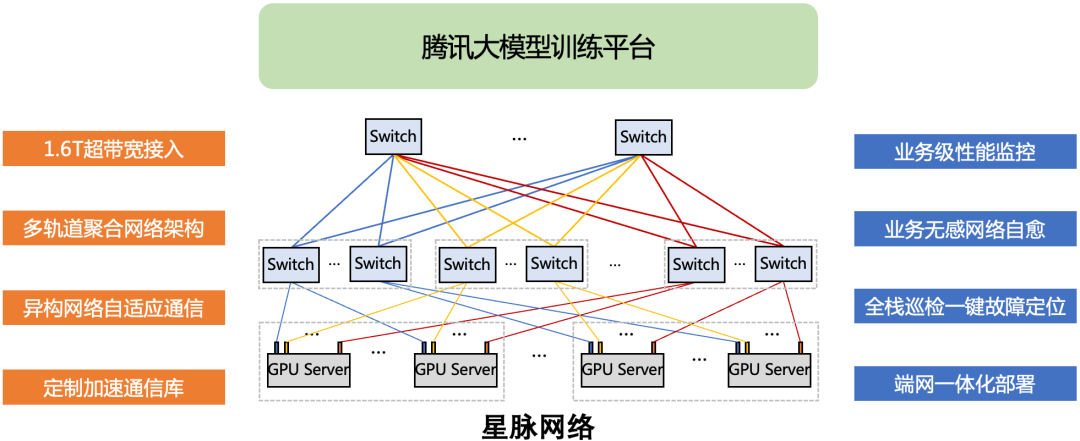
图 3. 星脉高性能计算网络
AI 时代下的网络诉求:极致网络
网络性能决定 GPU 集群算力
根据阿姆达尔定律,串行通信决定了并行系统整体运行效率,并行系统节点数越多,其通信占比越高,通信对整体系统运行效率的影响越大。
在大模型训练任务场景,动辄需要几百甚至几千张 GPU 卡的算力,服务器节点多、跨服务器通信需求巨大,使得网络带宽性能成为 GPU 集群系统的瓶颈。
特别是 MoE(混合专家系统)在大模型架构中的广泛应用,由于其稀疏门控特性构建在 All-to-All 通信模式之上,会随集群规模的增长对网络性能提出极高要求。业界近期针对 All-to-All 的优化策略,都是极致利用网络提供的大带宽来缩短通信耗时,从而提升 MoE 模型的训练速度。
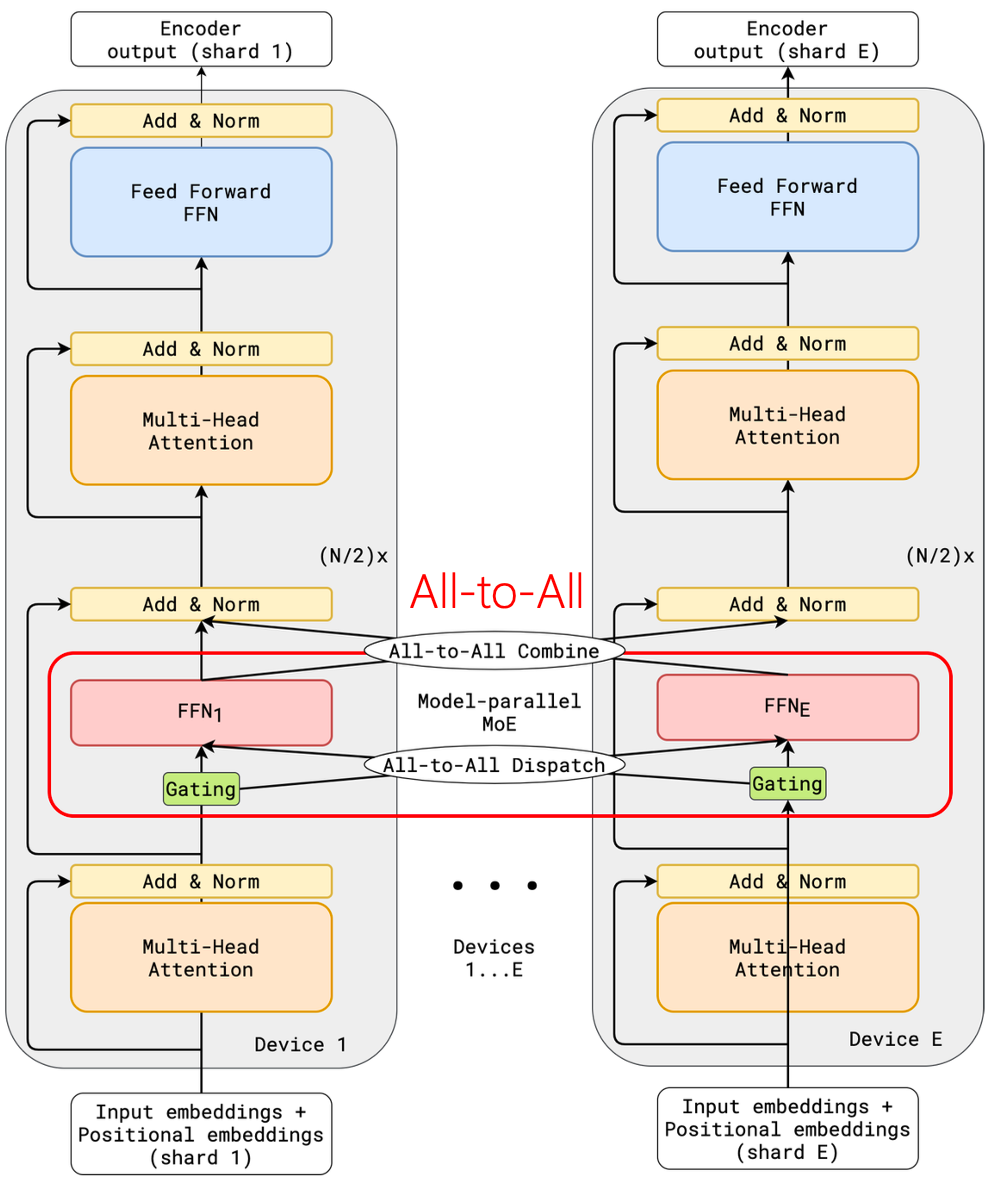
图 4. MoE 模型引入 All-to-All 集合通信操作
Lepikhin, Dmitry, et al. “Gshard: Scaling giant models with conditional computation and automatic sharding.” arXiv preprint arXiv:2006.16668 (2020).
网络可用性决定 GPU 集群算力稳定性
GPU 集群规模达到一定量级后,如何保障集群系统的稳定性,是除了性能外必须面对的另一个挑战。网络的可用性,决定了整个集群的计算稳定性,这是由于:
1)网络故障域大:相比单点 GPU 故障只影响集群算力的千分之几,网络故障会影响数十个甚至更多 GPU 的连通性,只有网络稳定才能维持系统算力的完整性。
2)网络性能波动影响大:相比单个低性能 GPU 或服务器容易被隔离,网络作为集群共享资源,性能波动会导致所有计算资源的利用率都受影响。
因此在大模型任务训练的整个周期中(数天、数周),维持网络的稳定高效,是 GPU 训练集群在工程化实践中极其重要的目标,对网络运维带来新的挑战。
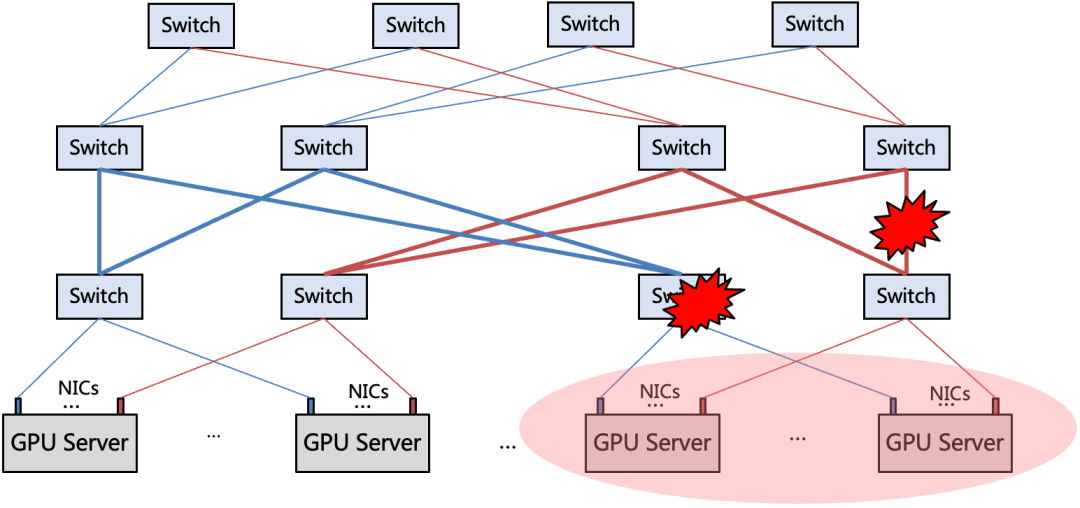
图 5. 网络故障 / 性能对集群算力影响大
创造高性能——AI 训练集群下的极致性能网络
面对千亿、万亿参数规模的大模型训练,仅仅是单次计算迭代内梯度同步需要的通信量就达到了百 GB 量级,此外还有各种并行模式、加速框架引入的通信需求,使得传统低速网络的带宽远远无法支撑 GPU 集群的高效计算。因此要充分发挥 GPU 计算资源的强大算力,必须构建一个全新的高性能网络底座,用高速网络的大带宽来助推整个集群计算的高效率。面向 AI 大模型训练需求,腾讯推出了业界领先的高性能计算网络架构——星脉:采用 1.6T 超带宽接入、多轨道聚合流量网络架构、异构网络自适应通信、定制加速通信库,构建了 1.6T ETH RDMA 高性能网络。
超带宽计算节点
AI 大模型训练是一种带宽敏感的计算业务,腾讯星脉网络为每个计算节点提供 1.6T 的超高通信带宽,带来 10 倍以上的通信性能提升。
星脉网络主要特点有:采用无阻塞 Fat-Tree 拓扑,单集群规模支持 2K GPU,超 EFLOPS(FP16)的集群算力;可灵活扩展网络规模,最大支持 32K GPU 计算集群;计算网络平面配备 8 张 RoCE 网卡,提供 1.6Tbps 的超高带宽接入。
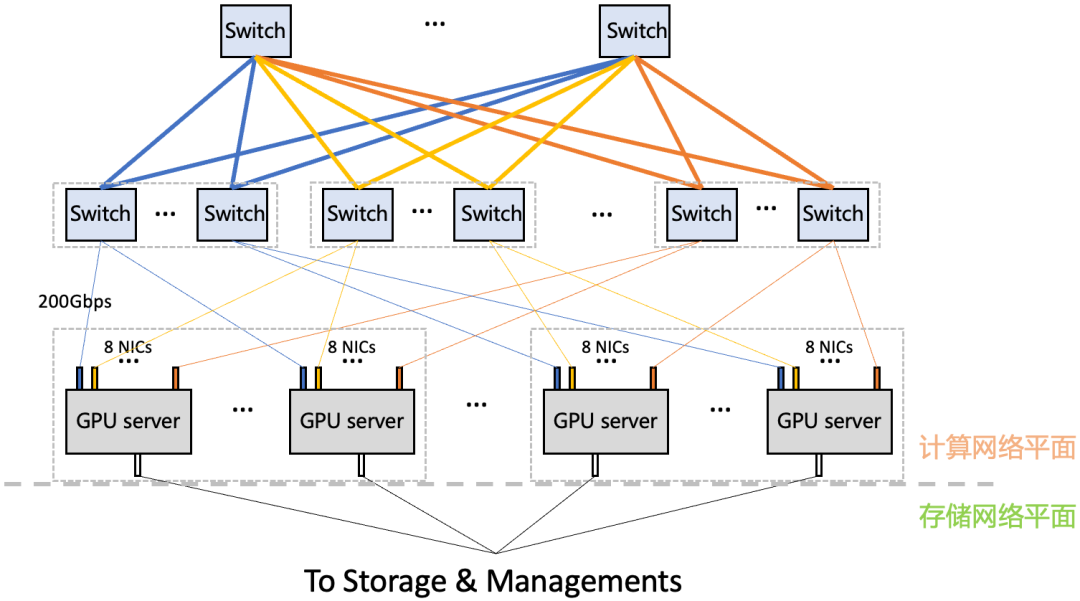
图 6. 星脉组网架构
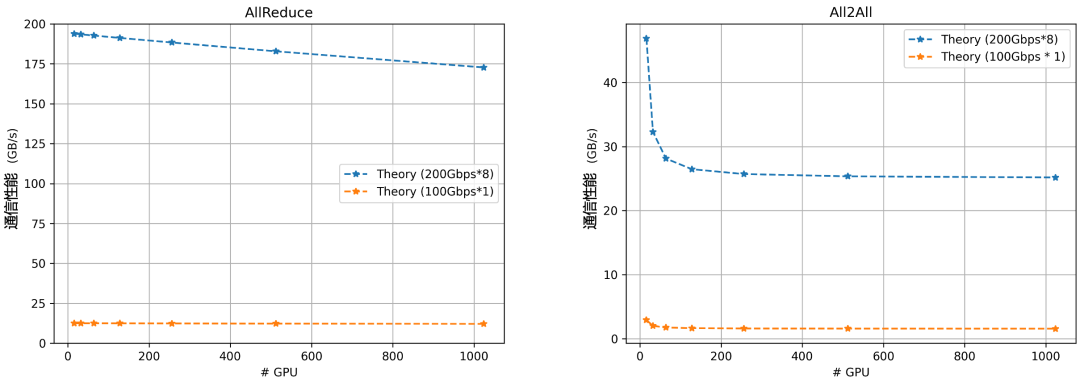
图 7. 集合通信性能理论建模
上图从理论上展示了 1.6Tbps 带宽与 100Gbps 带宽的集合通信性能对比。可以看到,对于 AllReduce 和 All-to-All 这两种典型通信模式,在不同集群规模下,1.6Tbps 超带宽都会带来 10 倍以上的通信性能提升。
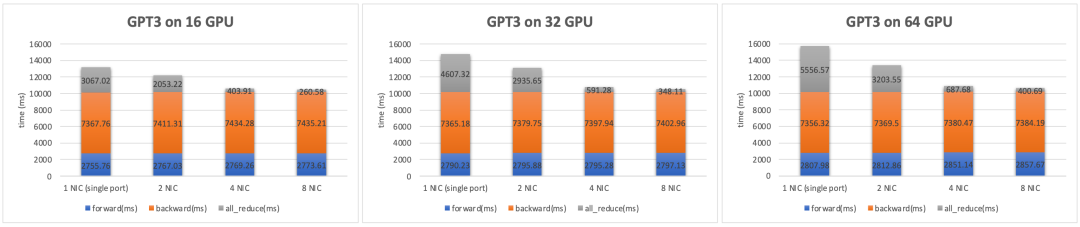
图 8. GPT3 模型训练性能
上图是对 GPT3 模型的实测性能数据,主要通信模式是 AllReduce。以 64 GPU 规模为例,由于 1.6Tbps 超带宽网络将 AllReduce 的耗时大幅缩短 14 倍,将通信占比从 35% 减少到 3.7%,最终使得单次迭代的训练耗时减少 32%。从集群算力的角度,相当于用同样的计算资源,超带宽网络能将系统算力提升 48%。
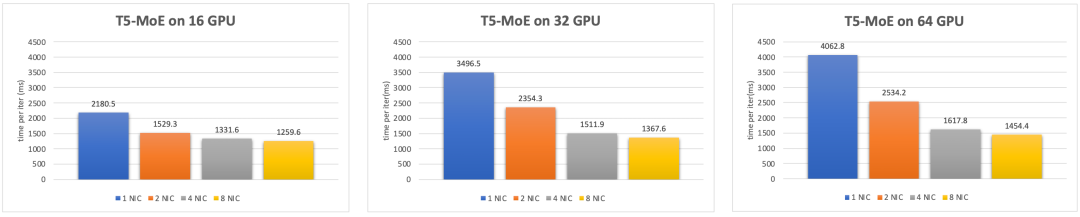
图 9. T5-MoE 模型训练性能
上图是对 T5-MoE 模型的实测性能数据,主要通信模式是 All-to-All。同样可以看到,在 64 GPU 模型下,1.6Tbps 带宽下的单次迭代训练耗时降低 64%。从集群算力的角度,相当于用同样的计算资源,超带宽网络能将系统算力提升 2.8 倍。
多轨道流量聚合架构
除了超带宽计算节点,星脉网络对通信流量做了基于多轨道的流量亲和性规划,使得集群通信效率达 80% 以上。
多轨道流量聚合架构将不同服务器上位于相同位置的网卡,都归属于同一 ToR switch;不同位置的网卡,归属于不同的 ToR switch。由于每个服务器有 8 张计算平面网卡,这样整个计算网络平面从物理上划分为 8 个独立并行的轨道平面,如下图所示(不同颜色代表不同的轨道)。
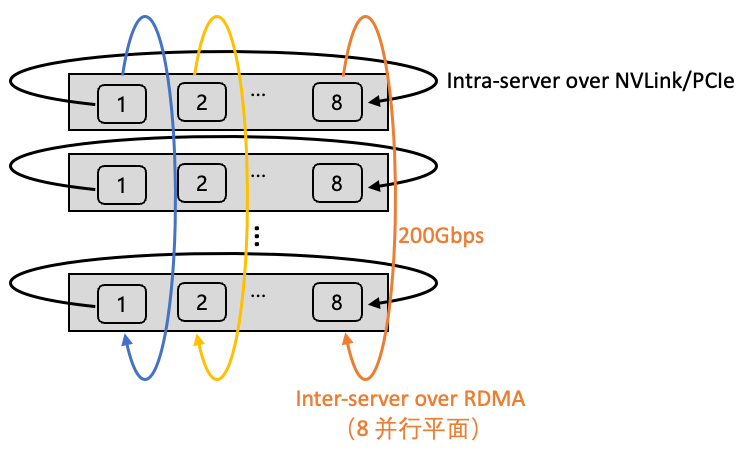
图 10. 多轨道流量聚合架构
在多轨道网络架构中,AI 训练产生的通信需求(AllReduce、All-to-All 等)可以用多个轨道并行传输加速,并且大部分流量都聚合在轨道内传输(只经过一级 ToR switch),小部分流量才会跨轨道传输(需要经过二级 switch),大幅减轻了大规模下的网络通信压力。
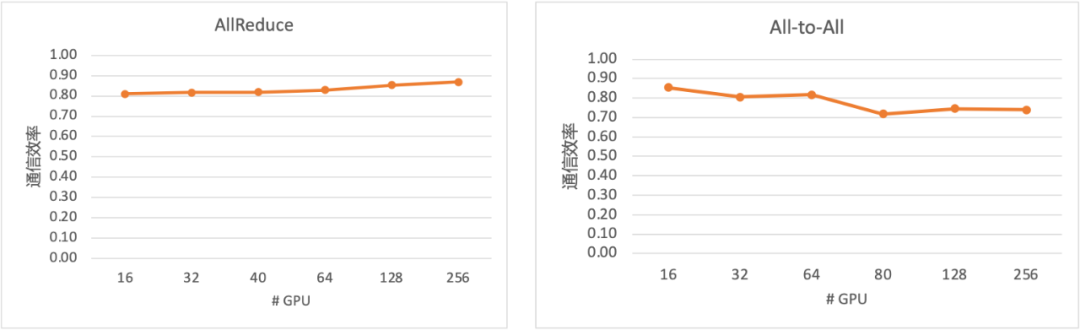
图 11. 集合通信效率
从上图实测的集合通信性能可以看出,在不同网络规模下,AllReduce 与 All-to-All 始终能维持较高的集合通信效率。
异构网络自适应通信
大规模 AI 训练集群架构中,GPU 之间的通信实际上由多种形式的网络来承载的:机间网络(网卡 + 交换机)与机内网络(NVLink/NVSwitch 网络、PCIe 总线网络)。星脉网络将机间、机内两种网络同时利用起来,达成异构网络之间的联合通信优化,使大规模 All-to-All 通信在业务典型 message size 下的传输性能提升达 30%。
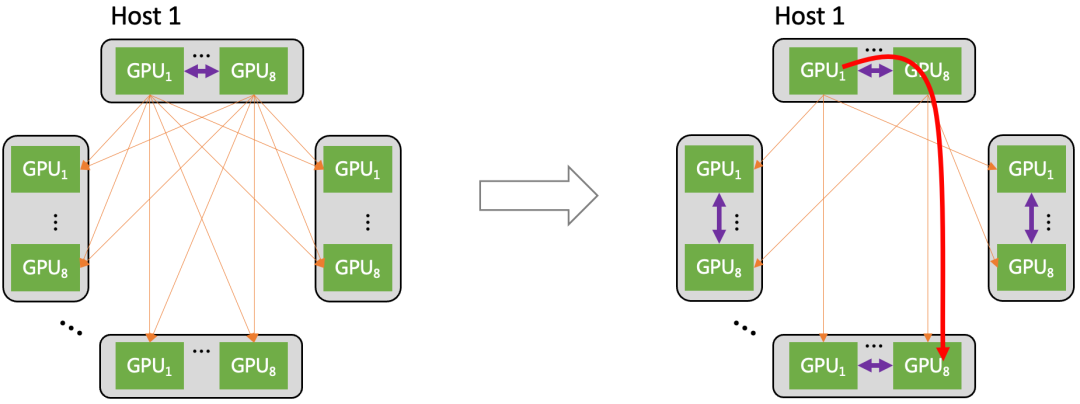
图 12. 异构网络自适应通信
上图展示了 All-to-All 集合通信如何利用异构网络来优化。当机间、机内网络同时使能时(右图):不同 host 上相同位置的 GPU 仍然走机间网络通信;但是要去往不同位置的 GPU(比如 host1 上的 GPU1 需要向其他 host 上的 GPU8 发送数据),则先通过机内网络转发到对应位置的 GPU 代理上,然后通过该 GPU 代理走机间网络来完成通信。
异构网络通信带来的优势有两点:1)异构网络通信使得机间网络的流量数目大幅减少;2)异构网络通信使机间网络的流量大部分都聚合在轨道内传输(只经过一级 ToR switch)。异构网络通过将小流聚合为大流的方式来减少流量的数目,减少对机间网络的冲击(RDMA QP 数量、拥塞控制、微突发等),从而提升整网的传输性能。
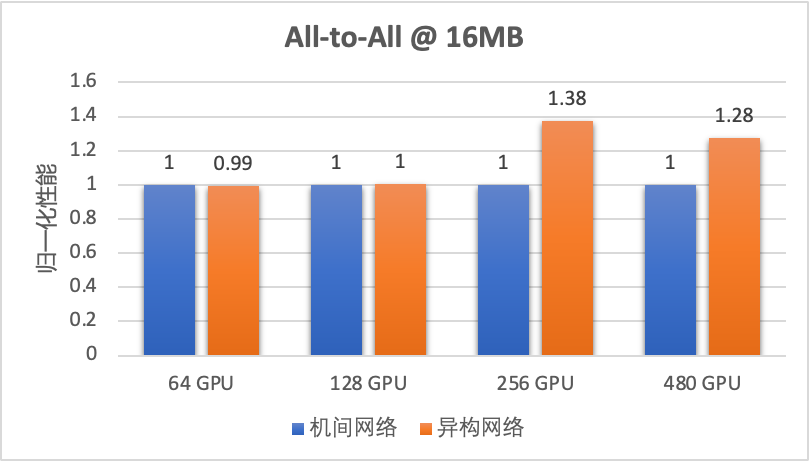
图 13. 异构网络自适应通信提升 All-to-All 性能
从上图的实测数据可以看出,异构网络通信在大规模 All-to-All 场景下对中小 message size 的传输性能提升在 30% 左右。
定制加速通信库
腾讯高性能集合通信库 TCCL(Tencent Collective Communication Library)定制适配星脉网络硬件平台,在 AllReduce/AllGather/ReduceScatter 等常用通信模式下带来 40% 的性能加速。
星脉网络基于 1.6Tbps ETH RDMA 网络定制,从网络性能、建设成本、设备供应、网络可靠性等多方面综合考虑,大量部署了 2*100Gbps 的单网卡硬件。从服务器角度上看,需要管理、配置 8 张 2*100G 的网卡;从网络架构角度上看,每张网卡需要上联两个 LA/ToR switch 来保证带宽与可靠性。组网架构图如下所示。
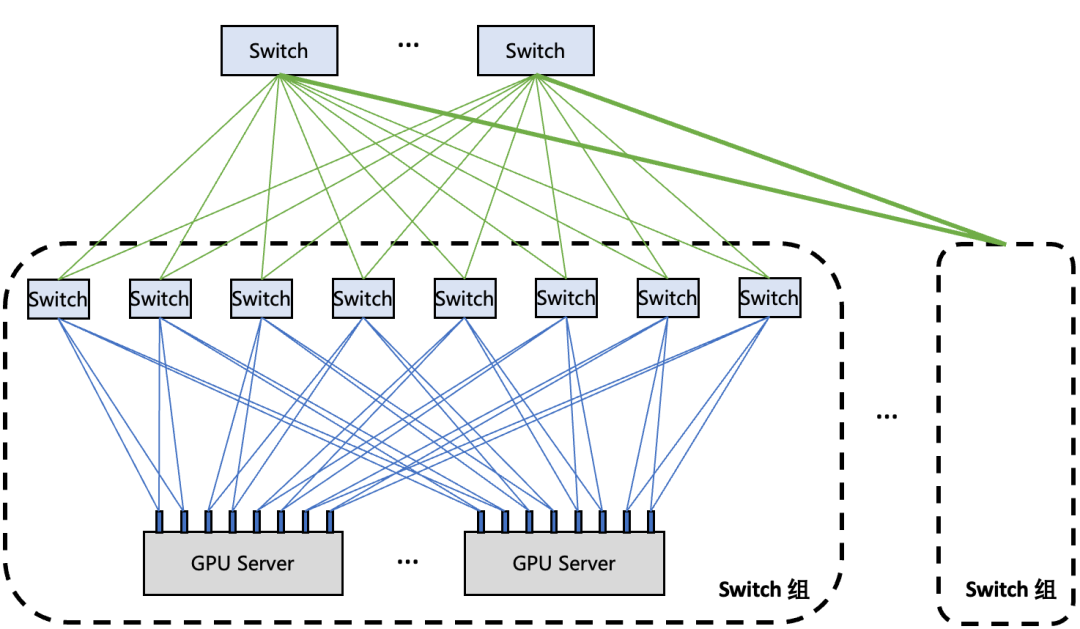
图 14. 2*100G 网卡双端口动态聚合组网架构
面对定制设计的高性能组网架构,业界开源的 GPU 集合通信库(比如 NCCL)并不能将网络的通信性能发挥到极致,从而影响大模型训练的集群效率。为解决星脉网络的适配问题,我们基于 NCCL 开发了高性能集合通信库 TCCL,在网卡设备管理、全局网络路由、拓扑感知亲和性调度、网络故障自动告警等方面融入了定制设计的解决方案。
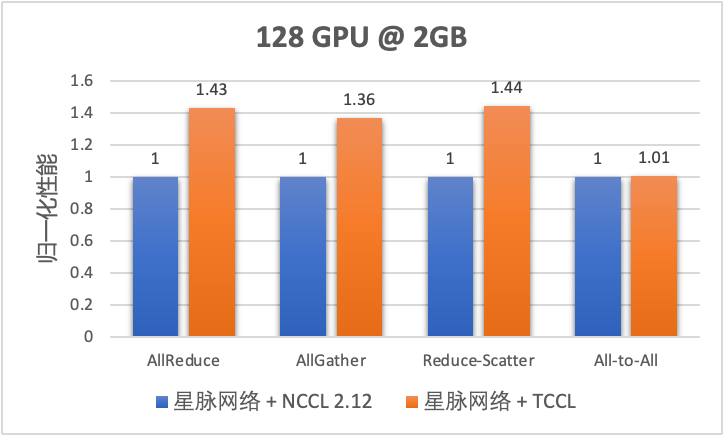
图 15. TCCL 集合通信性能
从上图实测的集合通信性能可以看出,在 AllReduce/AllGather/ReduceScatter 等常用通信模式下,针对星脉网络定制的 TCCL 都会带来 40% 左右的通信性能提升。
驾驭高性能——最大以太 RDMA 网络的工程实践
一匹马再快,若桀骜不驯,也难以称之为“良驹”。
为了驾驭高性能,我们先是实现了端网部署一体化以及一键故障定位,提升高性能网络的易用性,进而通过精细化监控与自愈手段,提升可用性,为极致性能的星脉网络提供全方位运营保障。
端网部署一体化
众所周知,RDMA 为业务带来了大带宽低时延,但同时其复杂多样化的配置也往往被网络运营人员诟病,因为一套错误的配置往往影响业务性能,还有可能会带来很多的不符合预期的问题。在星脉网络之前,据统计 90% 的高性能网络故障 case 均是配置错误导致的问题。出现这一问题的主要原因就是网卡配置套餐多,取决于架构版本,业务类型和网卡类型。在高性能网络运营平台提供的端网一体部署能力下,大模型训练系统的整体部署时间从 19 天缩减到 4.5 天,并保证了基础配置 100% 准确。
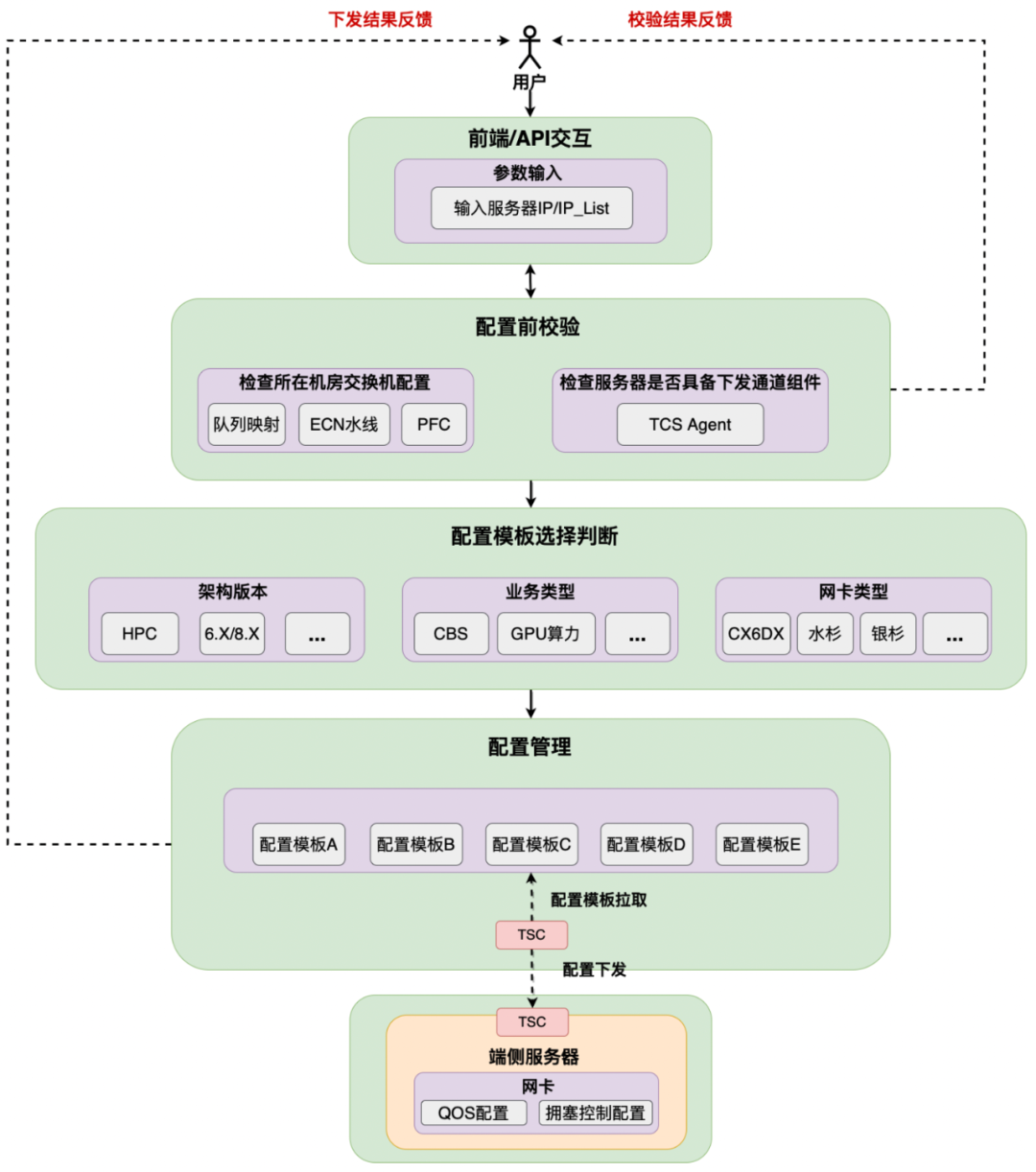
图 16. 高性能网络自动化部署
对此,我们先是实现了基础网络自动部署流程,整个自动部署的框架主要具备三方面的特点,第一是通过 API 提供单台 / 多台并行部署的能力。第二是在部署前,我们提供预校验的功能,一个是检查需要部署的机器上联交换机是否也配置了合理的拥塞控制相关配置,否则会影响到 RDMA 使用的性能。并将结果反馈给到用户。
最后是自动选择配置模板,我们会识别影响网卡配置模板的因素,包括架构版本,业务类型以及网卡类型,例如不同的网卡类型,配置的命令不同,选择的模板也不同。但这个流程对于用户侧是完全透明的。

图 17. 高性能网络自动化验收
在网络与端侧的基础配置完成后,为了保证交付质量,运营平台会做进一步的自动化验收,其中包含:
1)端网基础环境校验:通过端网状态数据以及周边建设系统的信息采集,在硬件上判断 PCIe,光模块,连线等是否正确。在软件上通过配置审计校验端网配置是否正确。
2)RDMA 基础测试:通过运行 Perftest,并进行数据采集分析,判断网卡性能是否达到预期。
3)通信库性能测试:通过运行 NCCL/TCCL test,并进行数据采集分析,判断集合通信性能是否达到预期。
4)模型 & 可靠性测试:运行典型模型训练,判断业务模型性能是否达到预期;通过设计端侧故障模拟、网络内故障模拟以及交换机配置错误等三类故障来判断业务可用性是否达到预期。
以上四个步骤全部通过后正式转为交付状态,否则会联动自动故障定位手段进行相关排查。
全栈巡检,一键故障定位
回顾过往,网络运营在服务器与交换机之间形成了分界线。然后在端网协同的高性能网络下,不仅仅需要考虑传统交换机上的问题定位,更要结合端侧“网卡,中间件等”的状态数据综合判断。在端侧能力具备的条件下,困扰了网络运营人员多年的问题“是否出现在网络交换机上”迎刃而解。同时也随着端侧运营能力的加强,针对不同的运营用户,自动排障的工具集也将多样化。
例如“一机八卡”的复杂拓扑下,连线与网段配置的正确率直接影响到应用是否能够成功建立,对此,我们通过封装交换机与服务器状态数据,联动网管拓扑信息,做到快速诊断与自动化检查。一方面在网络交付时屏蔽问题,另一方面快速定位运营中的网络挪线等操作带来的通信问题。
除了软件相关问题外,硬件故障也一样逃不出高网运营平台的法眼,例如在验收中发现部分网卡 8QP 带宽最多只能跑到 50Gbps 左右。通过故障池的沉淀,一键自动检测出 PCIE 带宽协商出错,定界为硬件故障,并自动推送到服务器运营相关人员进行网卡硬件更换。
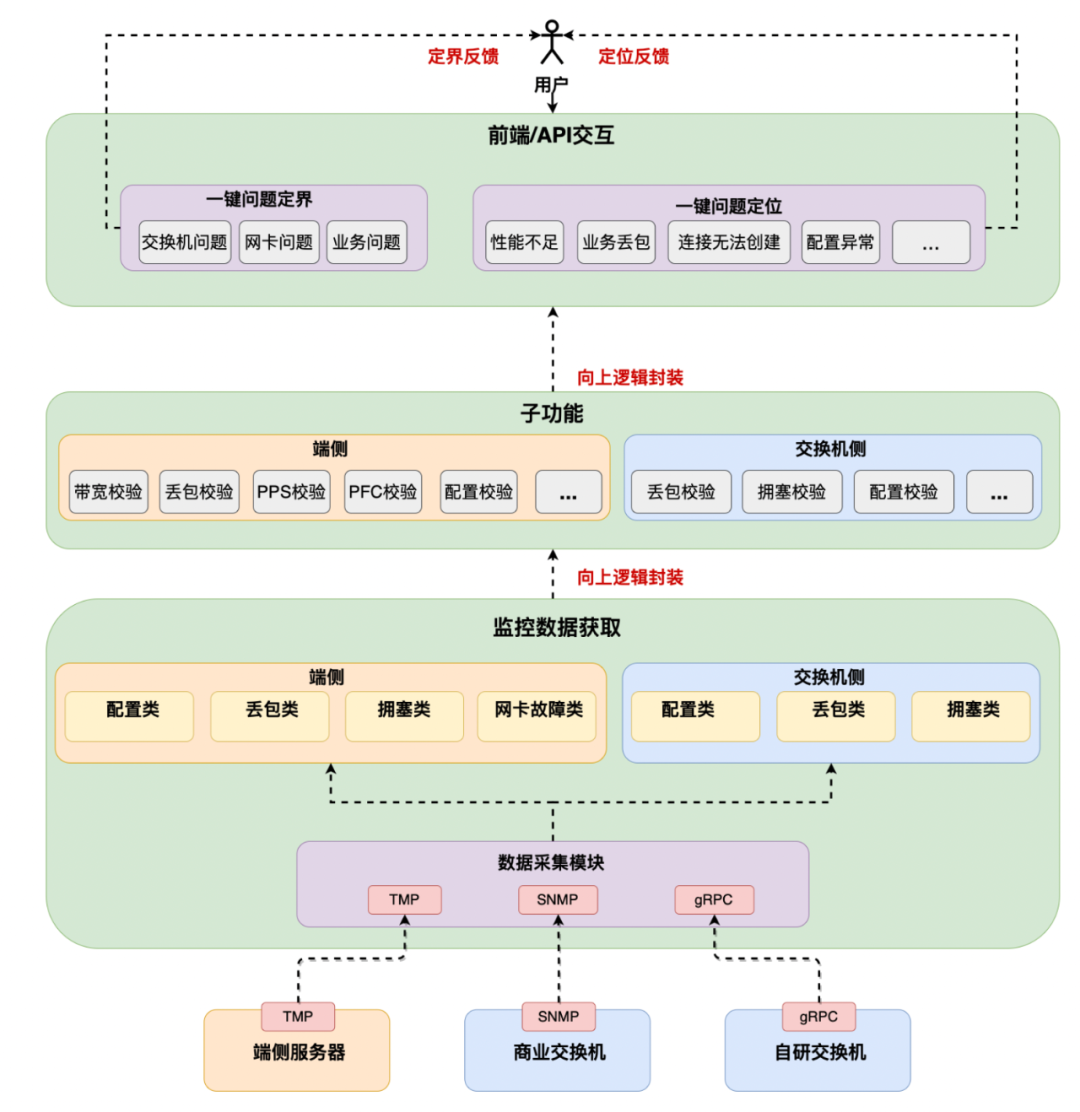
图 18. 高性能网络自动排障
高性能网络一键故障定位提供了两方面的功能,一方面可以快速定界问题所向,精准推送到对应团队的运营人员(网络 or 业务),减少团队之间的沟通成本,划分责任界限。另一方面可以一键快速定位问题根因,并给出解决手段。
整体系统具备层次化多维度的特征,通过端侧服务器以及交换机上的各种计数,向上逻辑封装抽象为子功能,例如带宽校验 & 丢包校验等。之后继续向上逻辑封装,形成定位与定界的场景,底层复杂的技术与逻辑彻底透明化,自下而上,最终呈现到用户的只有简单易用的场景按钮。目前高性能网络运营平台已支持“性能不足”、“业务丢包”、“配置异常”、“连接建立不成功”四个维度的一键故障定位,优雅地为高性能网络业务提供一键自检,健康可视等功能。
业务无感秒级网络自愈
一些网络故障(例如静默丢包)的发生是不可被预期的,在网络故障演练时发现,一些网络故障(例如静默丢包)发生后通信库就会出现超时,导致训练业务进程长时间卡死,虽然可以依靠拉起定期的保存的 checkpoint,但是也需要回退版本,损失精度,且整个过程需要几十分钟来加载和推送参数等。此前我们通过网络上的各种探测手段,或是基于探针,或是基于设备状态,加上控制器路由隔离手段,将故障自愈时间控制在 20s 以内。然而在面对高性能业务的秒级自愈要求下,我们转变了避障思路,需求起源于业务,那么为何不把避障的主动权交于业务呢?为了让极致性能恒久,我们推出了秒级故障自愈产品——“HASH DODGING”。
我们创造性地提出基于 Hash 偏移算法的网络相对路径控制方法。即,终端仅需修改数据包头特定字段(如 IP 头 TOS 字段)的值,即可使得修改后的包传输路径与修改前路径无公共节点。该方案可在网络数据平面发生故障(如静默丢包、路由黑洞)时帮助 TCP 快速绕过故障点,不会产生对标准拓扑及特定源端口号的依赖。也可用于保证多路径协议(如 MPTCP)中各子流均匀负载到不同网络节点,避免性能退化。
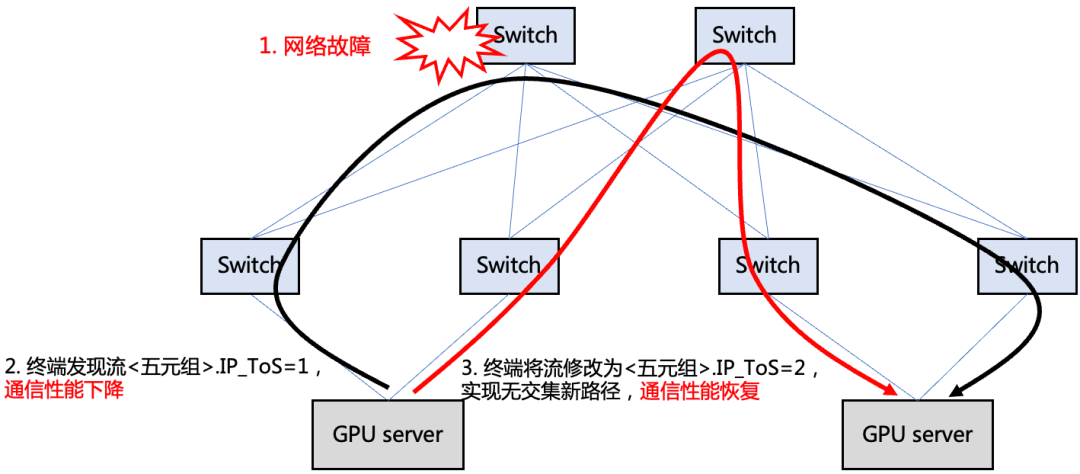
图 19. 单路径传输协议使用本方案实现确定性换路
通过端网协同,我们先是在端侧实现了协议栈层面的 TCP&RDMA 状态检测,通过内核获取协议栈状态信息。从而细粒度的获得业务流吞吐、丢包等信息,将故障发现降低到 600ms 以内。其次在故障换路上,相对于更换五元组改变 hash 结果的不确定性,我们在自研交换机上实现了基于 HASH 偏移的确定性换路特性,业务可以通过更换魔术字来确保 100% 更换到其余路径上。当发生静默丢包时,端侧无需依赖于网络,自身快速秒级内避障。
结语
未来随着 GPU 算力的持续提升,GPU 集群网络架构也需要不断迭代升级,才能保证系统算力的高利用率与高可用性。星脉高性能计算网络作为腾讯大规模训练集群的重要基石,会持续在超带宽、异构网络通信、通信库定制加速、智能监控等技术上不断创新,为 AI 大模型训练构筑可靠的高性能网络底座。
今日好文推荐
想彻底改变云行业!Spark发源地UC伯克利分校再推开源项目应对云成本飙升:平均降至三分之一
你的Flutter应用该考虑迁移代码了:Dart 3将在2023年成为100%健全的空安全语言
公众号推荐:
AGI 概念引发热议。那么 AGI 究竟是什么?技术架构来看又包括哪些?AI Agent 如何助力人工智能走向 AGI 时代?现阶段营销、金融、教育、零售、企服等行业场景下,AGI应用程度如何?有哪些典型应用案例了吗?以上问题的回答尽在《中国AGI市场发展研究报告 2024》,欢迎大家扫码关注「AI前线」公众号,回复「AGI」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 2 条评论