

在近日召开的自然语言处理领域国际顶级学术会议 ACL2019 上,华人学者斩获了最佳长论文奖、最佳短论文奖和两篇杰出论文奖。其中,由中科院计算所张文、冯洋,腾讯孟凡东,伍斯特理工学院 Di You 和华为诺亚方舟实验室刘群合著的论文《Bridging the Gap between Training and Inference for Neural Machine Translation》获最佳长论文奖,该研究成果旨在弥合神经机器翻译在训练和推理过程之间的缺口。实验结果表明,该论文提出的方法在多个数据集上取得了显著的改进。本文将对这篇论文进行深入解读,这是 AI 前线第 87 篇论文导读。
神经机器翻译(NMT)基于上下文预测下一个词,依次生成目标语句。在训练时,模型以真实值作为上下文(context)进行预测,而在推理时,模型必须从头生成整个序列。这种输入上下文的差异会导致错误累积。此外,单词级别(word-level)的训练要求生成的序列与真实序列严格匹配,这会导致模型对不同但合理的翻译产生过度矫正。为了解决这一问题,研究人员提出不仅从真实值序列中采样得到上下文词(context word),也从模型的预测序列中采样得到上下文词。实验结果表明该方法在多个数据集上取得了显著的改进。
本论文斩获 ACL 2019 最佳长论文奖,获奖理由如下
该论文解决了 seq2seq 中长期存在的暴露偏差问题
论文所提出的解决方案是:在“基于来自参考语句的词”和“基于解码器输出的预选择词”之间切换
这个方法适用于当前的 teacher-forcing 训练范式,比 scheduled sampling 有所提升
论文的实验非常完善,结果令人信服,该方法可能影响机器翻译的未来
该方法也适用于其他 seq2seq 任务
1 介绍
暴露偏差
大多数 NMT 模型都基于编码器-解码器框架,这些模型基于之前的文本来预测下一个词,得到目标词的语言模型。在训练阶段,将真实词(ground truth word)用作上下文(context)输入,而在推理时,由于整个序列由得到的模型自行生成,所以将模型生成的前一个词用作上下文输入。因此,训练和推理时的预测词是从不同的分布中提取出来的:训练时的预测词是从数据分布中提取的,而推理时的预测词是从模型分布中提取的。这种差异称为暴露偏差,导致了训练和推理之间的差距。随着目标序列的增长,误差会随之累积,模型必须在训练时从未遇到的情况下进行预测。
为了解决这个问题,模型的训练和推理应该在相同的条件下进行。受 Data As Demonstrator 方法的启发,可以在训练过程中将真实词和预测词作为上下文一同输入网络。NMT 模型通常采用交叉熵损失(cross-entropy loss)作为优化目标,这就要求在预测序列和真实序列在单词级别上严格的成对匹配。一旦模型生成一个偏离真实序列的单词,交叉熵损失将立即纠正错误,并将下一次生成拉回真实序列。然而,这导致了一个新的问题:一个句子通常有多个合理的翻译,不能因为模型产生了和真实值不同的单词,就说这个模型出错了。
参考语句:We should comply with the rule(我们应该遵守规则)。
候选 1:We should abide with the rule(我们应该与规则住在一起)。
候选 2:We should abide by the law(我们应该遵守法律)。
候选 3:We should abide by the rule(我们应该尊重规律)。
一旦模型生成第三个目标词“abide”,交叉熵损失会迫使模型生成第四个词“with”(如候选 1),从而具有更大的句子级别的相似性,并与参考语句一致,但是“by”才是正确的用法。然后,以“with”作为上下文生成“the rule”,从而模型生成的是“abide with the rule(与规则住在一起)”,这实际上是错误的。候选 1 就是一种过度矫正现象。另一个潜在的错误是,即使模型在”abide”之后预测正确的单词“by”,在生成后续翻译时,它也可能通过输入“by”而产生“the law”,这也是不恰当的(如候选 2)。假设参考语句和训练标准让模型记住了 “the rule”始终跟在单词“with”后面的模式。为了帮助模型从这两种错误中恢复并给出正确的翻译(候选 3),应该输入“with”作为上下文词,而不是“by”,即使之前预测的短语是“abide by”。此解决方案称为过度矫正恢复(Overcorrection Recovery, OR)。
这篇论文提出了一种方法弥合训练与推理之间的差距,提高 NMT 过度矫正的恢复能力。该方法首先从预测词中选择 oracle 词,然后从 oracle 词和真实词中采样得到上下文。作者不仅采用逐词贪婪搜索(word-by-word greedy search),而且还采用了语句级别(sentence-level)优化来选择 oracle 词。在训练开始时,模型大概率选择真实词作为上下文。随着模型的逐渐收敛,模型更多选择 oracle 词作为上下文。通过这种方式,训练过程从完全指导的方案转变为较少指导的方案。在这种机制下,模型有机会学习如何处理推理时所犯的错误,也能从替换翻译(alternative translation)的过度矫正中恢复过来。作者使用 RNNSearch 模型和 Transformer 模型进行了验证。结果表明,该方法能显著提高两种模型的性能。
2 基于 RNN 的 NMT 模型
作者以基于 RNN 的 NMT 为例介绍该方法。假设源序列和观察到的翻译分别为 x={x1,x2,…}和 y={y1, y2, …}。
编码器。采用双向门控循环单元来获取两个序列的隐状态。exi 代表单词 xi 的嵌入矢量表示。
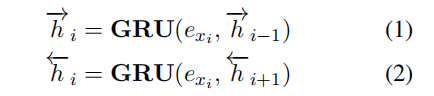
注意力。注意力机制用于提取源信息(源上下文矢量,source context vector)。在第 j 步,目标单词 yj*和第 i 个源单词之间的相关性通过源序列进行评估:
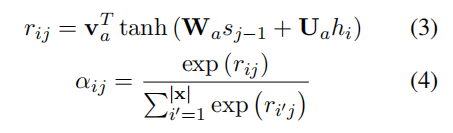
解码器。解码器应用 GRU 的一个变体来解码目标信息。在第 j 步,目标隐状态 sj 由下式得到:
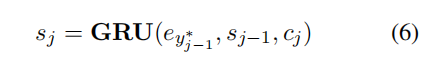
目标词典中所有词的概率 Pj 即可基于上一个真实词、源上下文矢量和隐状态得到:
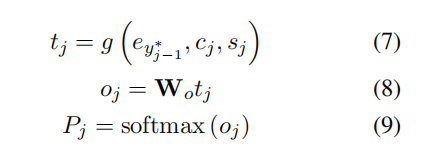
3 方法
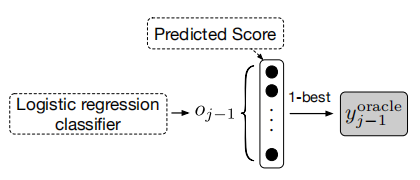
图 1 方法框架图
该方法的主要框架(如图 1 所示)是以一定的概率将真实词或之前预测的词(即 oracle 词)作为上下文。通过训练模型来处理测试期间出现的情况,也许可以减少训练和推理之间的差距。在这里,作者介绍了两种选择 oracle 单词的方法。一种方法是用贪婪搜索算法,在单词级别选择 oracle 单词,另一种方法是在语句级别选择最优的 oracle 序列。预测第 j 个目标单词 yj 包括以下步骤:
在第 j-1 步选择 oracle 单词。
从真实词 y*(j-1)中以概率 p 采样,或从 oracle 词 yoracle(j-1)中以概率 1-p 采样。
使用采样的单词作为 y(j-1),并用 y(j-1)代替公式 6 和 7 中的 y*(j-1),然后继续使用基于注意力的 NMT 进行后续的预测。
3.1 如何选择 oracle 词
一般情况下,在第 j 步,NMT 模型需要用真实值 y*(j-1)作为上下文词(context word)来预测 yj,所以我们可以选择一个 oracle 词 yoracle(j-1)来近似上下文词。oracle 词应该与真实值相似,或者是真实值的近义词。选择 oracle 词的一个方法是单词级别的贪婪搜索,输出每一步的 oracle 单词(word-level oracle,WO)。此外,也可以通过扩大搜索空间,对候选翻译按语句级别的衡量标准进行排序,例如 BLEU、GLEU、ROUGE 等指标。选择的翻译即为 oracle 语句,该翻译中的单词即为语句级别的 oracle(sentence-level oracle,SO)。
单词级别 oracle
对于第 j-1 步,选择 oracle 词的直接方法是从公式 9 得到的词概率分布 Pj-1 中选择概率最高的词,如图 2 所示。在实现中,作者采用 Gumbel-max 方法获得更鲁棒的 oracle 词。
图 2 单词级别 oracle(不含噪声)
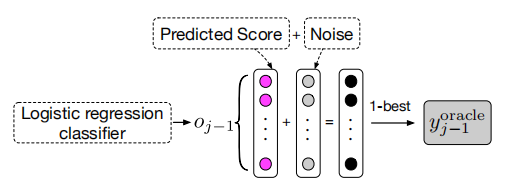
图 3 单词级别 oracle 加入 Gumbel 噪声
作者将 Gumbel 噪声以正则项的形式,加入公式 8 中的 o(j-1),如图 3 所示,然后经过 softmax 函数,y(j-1)的词分布可以近似为:
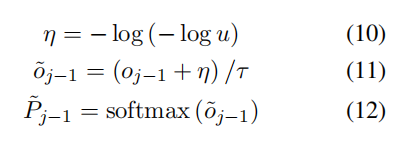
当τ趋近于 0 时,softmax 函数近似为 argmax 函数,当τ接近无穷大时,逐渐变成均匀分布。最佳的单词级别 oracle 可由下式得到:
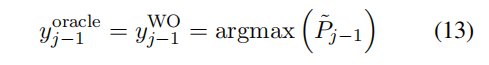
语句级别 oracle
语句级别的 oracle 能够通过 n-gram 匹配得到更灵活的翻译。在这篇文章中,作者采用 BLEU 作为衡量指标。为了选择语句级别的 oracle,作者首先对一个 batch 的所有句子进行束搜索,假设束大小为 k,则得到 k 个最佳的候选翻译。然后计算每个候选翻译与真实值之间的 BLEU 分数,分数最高的则作为 oracle 语句。将其表示为:
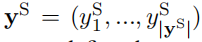
那么在解码的第 j 步,语句级别 oracle 词即可表示为:
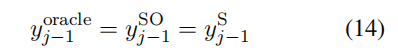
但是语句级别的 oracle 存在一个问题。当模型从真实词和语句级别 oracle 词中采样时,两个序列应该具有同样数量的单词。然而简单的束搜索解码算法不能保证这一点。因此作者引入了强制解码(force decoding)来确保两个序列的长度相同。
强制解码
假设真实序列的长度为|y|,强制解码的目的是生成一个长度为|y|的序列,后面跟着一个终止语句符号(EOS)。这样在束搜索中,当一个候选翻译的长度不等于|y*|,却以 EOS 终结语句时,强制解码会强制它生成|y|个单词:
当第 j-1 步,候选翻译的长度还没达到|y|,但是 EOS 已经是第 j 步的首选词时,则从词分布 Pj 中选择第二个候选词作为该翻译的第 j 个词。
当第|y|+1 步时,如果 EOS 不是词分布的首选词,则让它成为候选翻译第|y|+1 个词。
这样,就可确保所有的 k 个候选翻译的长度都为|y*|,然后再根据 BLEU 分数对 k 个候选翻译进行排序,然后选择第一个作为 oracle 语句。
3.2 衰减采样
作者采用衰减采样机制从真实词 y(j-1)和 oracle 词 yoracle(j-1)中采样得到上下文词 y(j-1)。在训练开始时,由于模型没有经过良好的训练,使用 yoracle(j-1)作为 y(j-1)过于频繁会导致收敛非常缓慢,甚至陷入局部最优。另一方面,在训练结束时,如果上下文词 y(j-1)在很大概率上仍然是从真实词 y*(j-1)中选择的,则模型不会完全接触到推理时会遇到的情况,从而不知道如何在推理时采取行动。因此,从真实词中选择的概率 p 是不固定的,但随着训练的进行,它必须逐渐降低。在开始时,p=1,即模型完全基于真实词进行训练。随着模型逐渐收敛,模型将更多的从 oracle 词中选择上下文词。
根据训练 epoch 逐渐衰减采样概率 p:
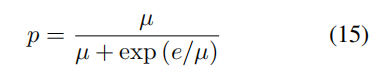
3.3 训练
用上述方法选择 y(j-1)后,可根据公式(6)、(7)、(8)、(9)得到 yj 的词分布。目标是最大化真实值序列的概率。因此,通过最小化以下损失函数训练模型:
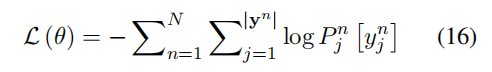
4 实验
4.1 NIST 中译英(Zh->EN)
对于 NIST 中译英(Zh->EN)任务,作者采用了两个基线模型进行验证。
RNNsearch
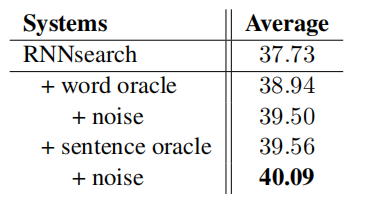
表 1 中译英翻译任务实验结果
作者对比了三种对基于 RNN 的 NMT 模型进行增强的方法:Coverage、MRT 和 Distortion。与这三种方法对比,作者提出的基线系统 RNNsearch 的表现 1)超越了 Coverage,2)达到了与 MRT 和 Distortion 一样的表现。
作者与其他两个解决暴露偏差的方法进行了对比:SS-NMT 和 MIXER。从表 1 中可以看出,SS-NMT 和 MIXER 都能取得一定的提升,但是作者提出的 OR-NMT 不仅超越了 RNNSearch 的基线,并且取得了更大的提升。与其他两个方法相比,OR-NMT 在四个测试数据集上将 BLEU 分数提升了 2.36 分。
Transformer
作者在 Transformer 模型上测试了提出的方法。从表 1 可以看出,单词级别的 oracle 可以取得+0.54 BLEU 分的提升,语句级别的方法可以进一步带来+1.0 BLEU 分的提升。
4.2 因素分析
作者提出了单词级别 oracle、语句级别 oracle 和在 oracle 选择中结合 Gumbel 噪声这三种方法来解决过度矫正的问题。表 2 给出了这三种因素的影响。
表 2 中译英翻译任务因素分析实验
在只采用单词级别 oracle 时,模型表现提升了 1.21 BLEU 分数点,说明输入之前预测的词作为上下文可以减轻暴露误差。采用语句级别 oracle 时,可以进一步提升 0.62 BLEU 分数点。说明语句级别 oracle 的表现优于单词级别 oracle。作者认为,这种优势可能来自于单词生成的更大的灵活性,它可以缓解过度矫正的问题。通过在单词级别 oracle 和语句级别 oracle 的生成过程中加入 Gumbel 噪声,模型的 BLEU 得分分别提高了 0.56 和 0.53。这表明 Gumbel 噪声可以帮助选择每个 oracle 词,证明了 Gumbel-Max 提供了一种从分类分布中进行采样的有效和可靠的方法。
4.3 收敛性
作者研究了不同因素对收敛性的影响。图 4 给出了 RNNsearch 以及不同变体的训练损失曲线。图 5 给出了不同因素的 BLEU 分数值对比。可以看出,RNNsearch 收敛较快,并且在第 7 个 epoch 达到最佳结果,但是第 7 个 epoch 后训练损失依然持续下降,所以 RNNsearch 的训练可能会过拟合。图 4 和图 5 也显示出,加入 Gumbel 噪声会稍微拖慢收敛速度,但是模型达到最佳表现后训练损失不会再继续下降。这表明 oracle 采样和 Gumbel 噪声能避免过拟合。
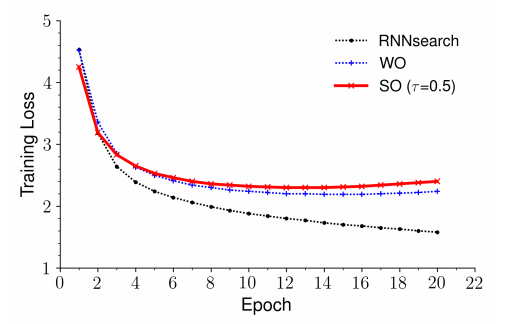
图 4 中译英翻译任务不同因素的训练损失曲线
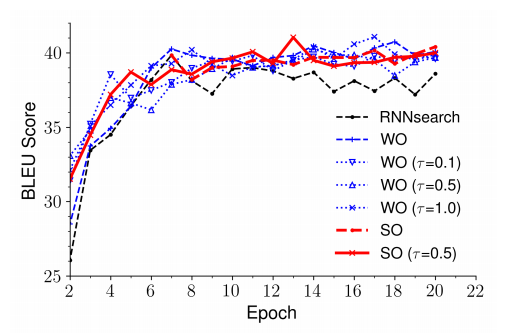
图 5 验证集上中译英翻译任务不同因素的 BLEU 分数变化趋势
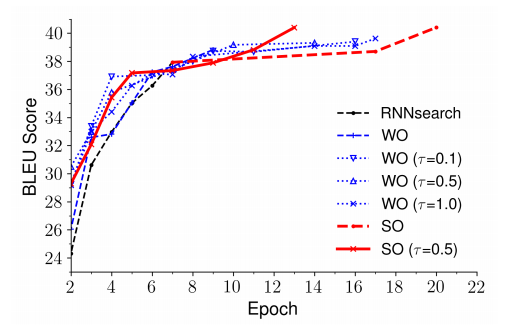
图 6 MT03 测试集上中译英翻译任务不同因素的 BLEU 分数变化趋势
图 6 给出了 MT03 数据集上的 BLEU 分数曲线。在语句级别 oracle 加入噪声时,可以得到最佳模型。没有噪声时,模型收敛后的 BLEU 分数较低。这也很好理解,在训练过程中如果没有正则项,只是一直重复使用模型自己的结果,容易导致过拟合。
4.4 序列长度
图 7 给出了在 MT03 测试集上从不同长度的源语句中生成翻译的 BLEU 分数值。从图中可以看出,论文的方法在所有的区间都对 baseline 有较大的提升,尤其是(10,20]、(40,50]和(70,80]区间。交叉熵损失需要预测序列与真实值序列完全相同,这对于较长的语句来说更难做到,而语句级别 oracle 可以减轻这种过度矫正。
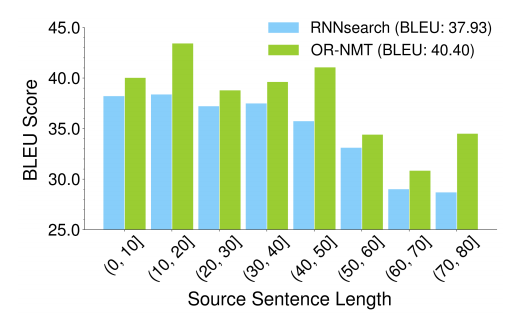
图 7 MT03 测试集不同程度源语句模型表现对比
4.5 暴露偏差的影响
为了证明该方法带来的提升是由于解决了暴露偏差问题,作者从中译英训练数据中随机选择了 1000 对句子,然后用预训练的 RNNSearch 模型和提出的模型对源语句进行解码。RNNSearch 模型的 BLEU 分数为 24.87,而论文模型提升了 2.18 分。然后作者统计了论文模型预测分布中真实词的概率高于基线模型的数量,记为 N。在参考语句中共有 28266 个词,N=18391,比例为 18391/28266=65.06%,证明了该方法带来的提升是由于解决了暴露偏差问题。
4.6 英译德翻译实验
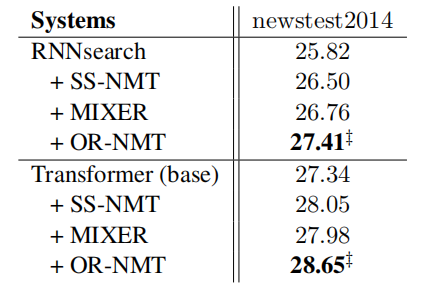
表 3 英译德翻译任务实验结果
作者在 WMT’14 上也验证了所提方法。从表 3 中可以看出,论文提出的方法大大提升了基线模型的表现,并且优于其他相关方法。该实验说明论文模型对不同语言之间的翻译均有效。
5 总结
端到端的 NMT 模型训练时将真实值单词作为上下文,而模型推理时则由模型生成的前一个单词作为上下文。为了减少训练和推理之间的差异,在预测一个词时,作者从真实值单词或预测词中抽样得到一个词作为上下文输入。预测词,即 oracle 词,可以通过单词级别或语句级别优化生成。与单词级别 oracle 相比,语句级别 oracle 可以进一步增强模型的过度矫正恢复能力。为了使模型充分地暴露在推理时的环境中,作者采用衰减采样,从真实值单词采样得到上下文词。作者用两个基线模型和相关工作在真实翻译任务上进行了验证,该方法在所有数据集上都有显著提升。这篇论文很好地解决了 seq2seq 中存在的暴露偏差问题,用充分的实验证明了方法的有效性。
查看论文原文:
Bridging the Gap between Training and Inference for Neural Machine Translation
https://arxiv.org/abs/1906.02448

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论 2 条评论