

七牛云架构师实践日南京站于 11 月 9 日在南京成功举行,以「大数据技术的实践与分享」为主题,邀请了多名业内大咖,为大家带来了精彩演讲。bilibili 的架构师屠辉,在会上作了题为《海量监测平台的演进之路》的分享。
以下内容为根据现场演讲内容速记的实录整理。
各位下午好!我叫屠辉。目前在 bilibili 担任基础平台的架构开发。在加入 bilibili 之前,曾在京东担任 APM 平台和公网链路探测的架构开发。
今天我分享的主题是《海量监测平台的演进之路》。首先介绍一下 bilibili,我想在座的应该都很熟悉,有大量年轻人喜欢在我们的平台上发布视频。而我们的监测平台,具有平台化、数据化、自主化、全局性和定位性这样的特点。
bilibili 监控系统的演进阶段
首先,我来介绍一下 bilibili 的监控系统,在演进过程中存在的几个阶段。
人肉堆积阶段
因为 bilibili 的监测系统起步较晚,从 2015 年才有第一名运维人员入职。之前都是处在一个人肉运维的堆积阶段,这是比较原始的,这些监测系统基本上就是八仙过海各显神通,所有数据都分布在一个个孤岛上面,没有统一的整合。
监测系统的平台化建设
大概从 2016 年开始,在意识到之前分散的系统是无法整合之后,我们开始注重监测系统平台化建设。我们开始了新一代 B 站的系统研发,把一些纷乱复杂的系统去除,选用 PROMETHEUS 系统作为我们的基础。
监测数据的分析和统计
第三个是用监测系统做分析,对之前割裂的信息进行空前的聚合,我们可以基于这些海量的数据做大数据分析,例如对容量的动态扩速容的评估。
研发和运维共同合作阶段
第四个阶段是研发和运维合作的阶段。把研发和运维密切结合起来,PROMETHEUS 的特性是可以从研发侧接入到运维的监控平台,提供有力保障,可以用不同的开发语言来作为买点。
站点可靠性建设
第五个阶段是可靠性建设。首先说一下 B 站监测平台的动向覆盖,bilibili 分为两个视角。一个是用户的视角,比如说用户的视觉感观有卡顿,从运维上可以反映出一些奇怪的问题。我们需要从中介入,找到问题的根源。另外一个视角,就是运维侧发起的监控需求。两边同时往中间演进,中间有一些中间件,比如说应用程序买点和其他系统监测,达到一个纵向的覆盖。
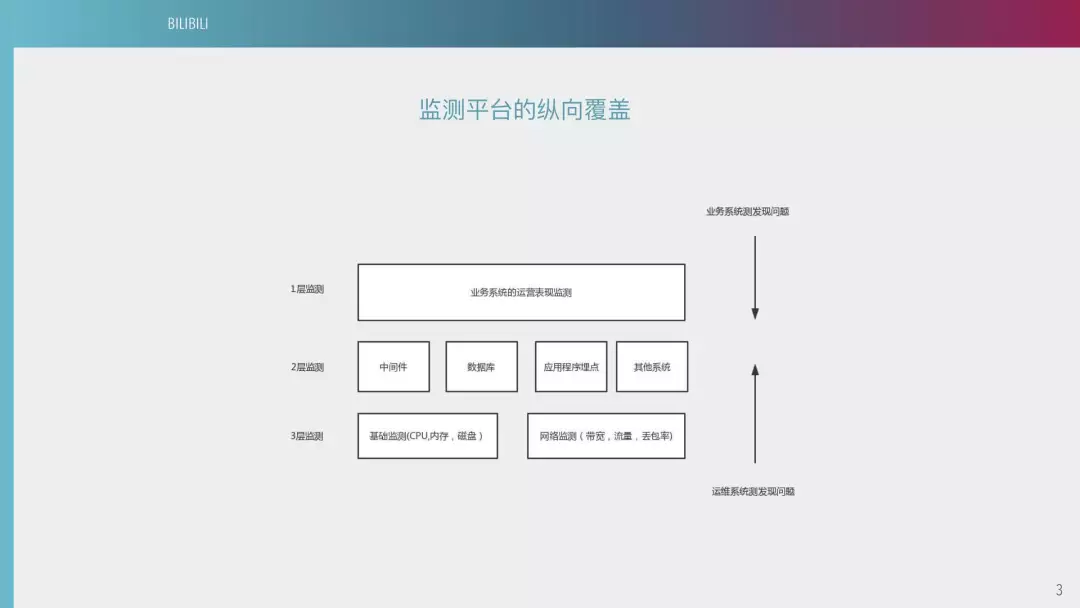
在 2016 年之前,因为 B 站都是用拉维克斯(音),只能做一些基础监控,像 CPU 、内存等,对于研发的接入成本是比较高的。所以我们的监控覆盖率就只有大概在 30% 左右,很多业务上的运维都是独立的。比如说有一些弹幕系统,运维部这边是完全没有感知的。
经过大概一年的时间,我们从 2017 年下半年开始对整个系统进行重构,我们用一个比较通用的模式来进入到监控平台,基本上是基于 PROMETHEUS 的二次开发,把它埋在一个公共框架里面。到了 2018 年我们的监测覆盖率大概可以达到 90% 。我们的愿景是最终达到 100% 的可以横向监控覆盖率。
下面我来说一下,建设海量指标的监测平台需要什么。目前 bilibili 的监测是分为两个团队两个技术站,我所在的主要是基于度量值的监控平台。
首先是多样化自主接入。不仅局限在网络监测,而且从不同的角度来洞悉全局,我们需要一个可靠的数据采集系统。
第二个是各个指标的灵活配置。监测指标全部接进来之后,每种指标的配置规则是不同的。相对来说就是纷乱复杂,无法达到一个有机的整合。
第三个是监测指标可视化。把海量的监测指标有机结合起来,针对某个系统来进行一个集中展示。例如我们对直播的监控,可以统计在线人数,用不同的活动页来展示,这样我们可以针对一个特殊的场景来解决问题,例如每半年季的活动。
第四个是告警的调用链和洞悉全局。像我个人每天可能要收到 4000 多条的告警消息,当然不可能一一看过来,所以说我们如何把一些关键的消息在最关键的时刻推送给关键的人,这是比较重要的问题。
整个系统重构之后发生了什么?
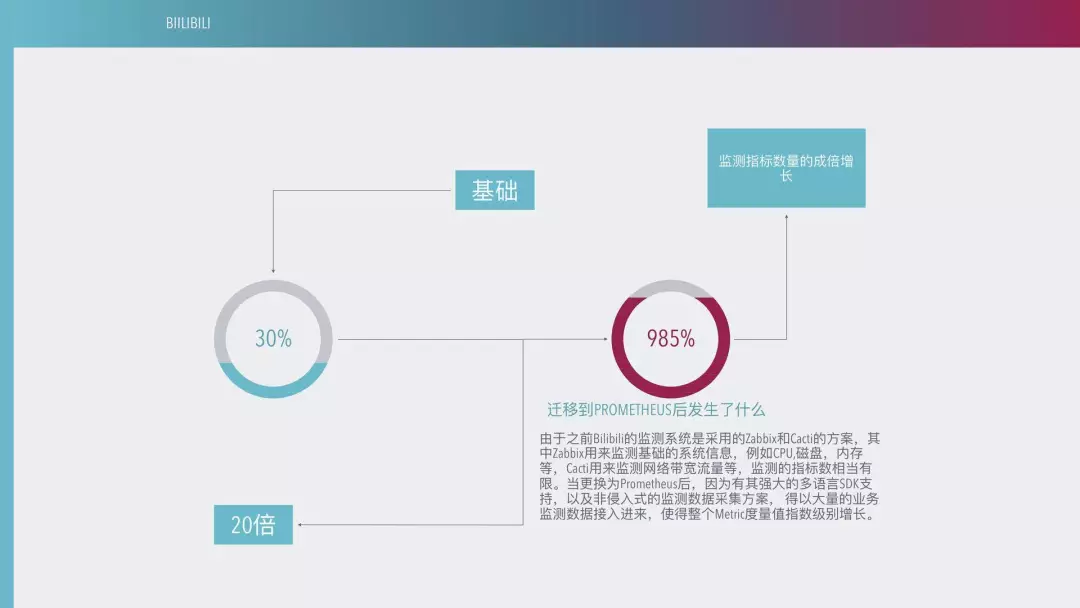
我们系统从选用 PROMETHEUS 之后,我们的数据采集量从原来的 30% 到目前翻了 20 倍。因为 bilibili 的业务比较复杂,有一些海外业务,包括在台湾、日本,包括在欧洲、美洲都有一些节点,我们的服务器是比较分散的。这就无法满足我们的监测需求,所以说我们必须采用分布式场景来做。当然网络监控目前也是统一到 PROMETHEUS 这边来。
这里就介绍一下我们的可视化监测平台。我们把所有的服务器和应用都挂在一个服务器上,从部门级别分散到应用级别,每个应用级别都有自己对应的系统。我们的监测系统不会直接把告警人写在里面,包括监测系统的规则配置等所有系统,都和这个平台关联起来,这样可以看到,主机名和一些规则配置都是基于我们这个概念来做的。
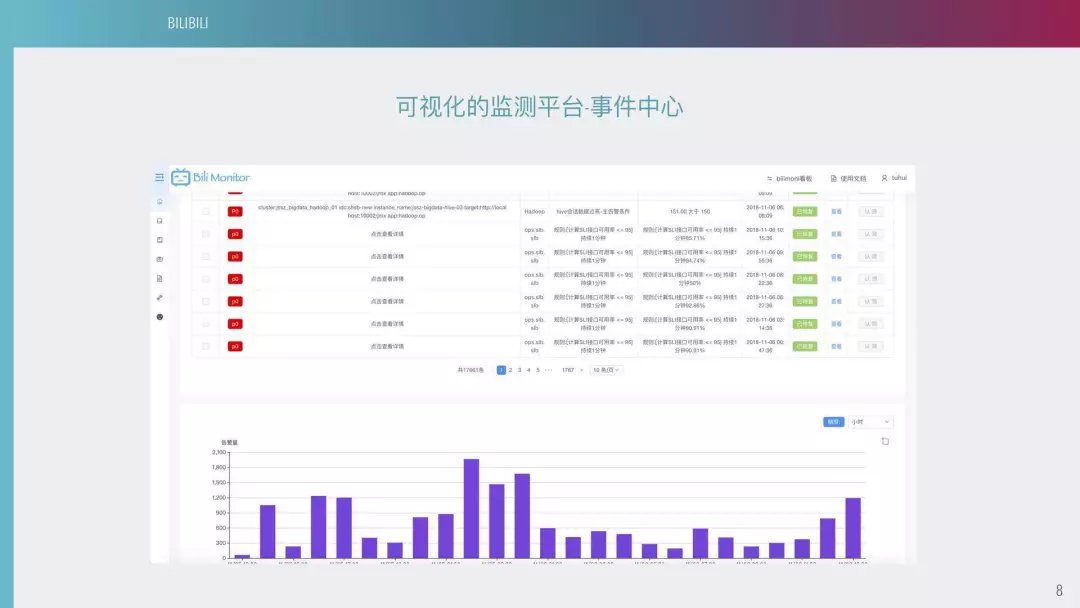
这是我们的监测平台事件中心。对每天产生的事件,有告警认领和简单统计的功能,你可以对告警屏蔽一段时间甚至进行进一步操作。当然每个告警都有它的级别,不同的级别告警频率也是不同的。目前来说,我们定了五个级别。比如 P0 级会通过电话、短信、企业微信三个渠道发送到具体接收人。P1 级别可能只有短信和企业微信,而 P2 级别,是目前最多的,一般来说都是通过企业微信来发送。P2 以下的 P3、P4、P5 都是通过邮件来发送。因为有些告警并不是致命性的问题,所以说我们会在周末对它进行静默。因为告警太多,所以说很多运维人员不想在周末接收到这种非致命性告警,所以我们在周末会把一些级别下调,调到 P3 左右。这里可以看到,每天的告警量最高在 2000 左右,平均一天大约在 1500 条左右。
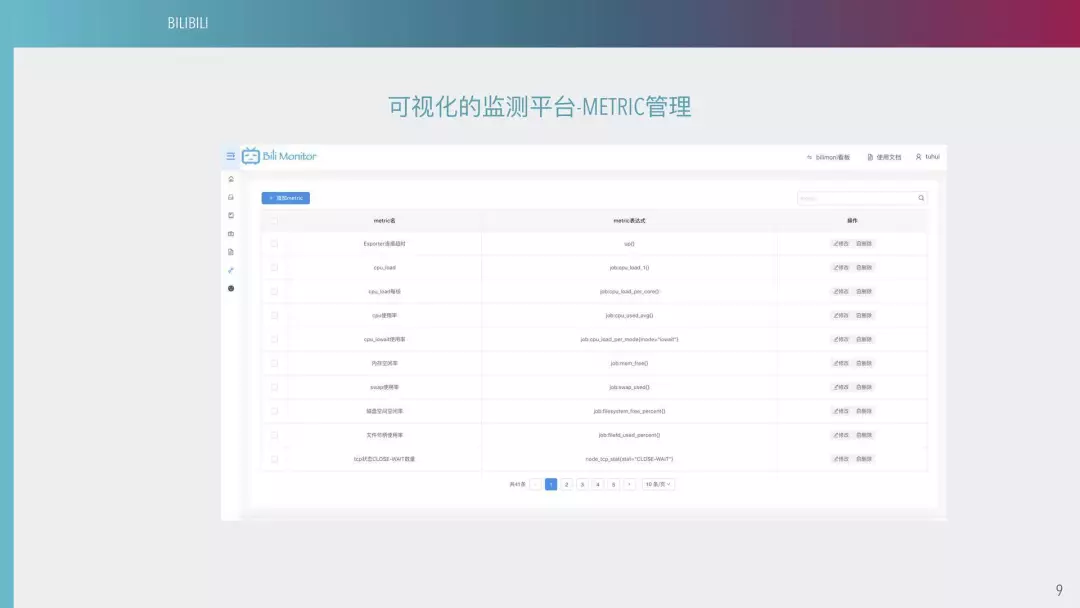
这是我们可视化的监测平台 METRIC 管理。在用了 PROMETHEUS 以后,我们原则上不添加新的 METRIC,不同的 METRIC 之间肯定是不到 1000 个,包括一些中间的,还有一些个性化的埋点。
这个是我们的可视化监测平台。其中定制化的不多,稍微改了一些界面。
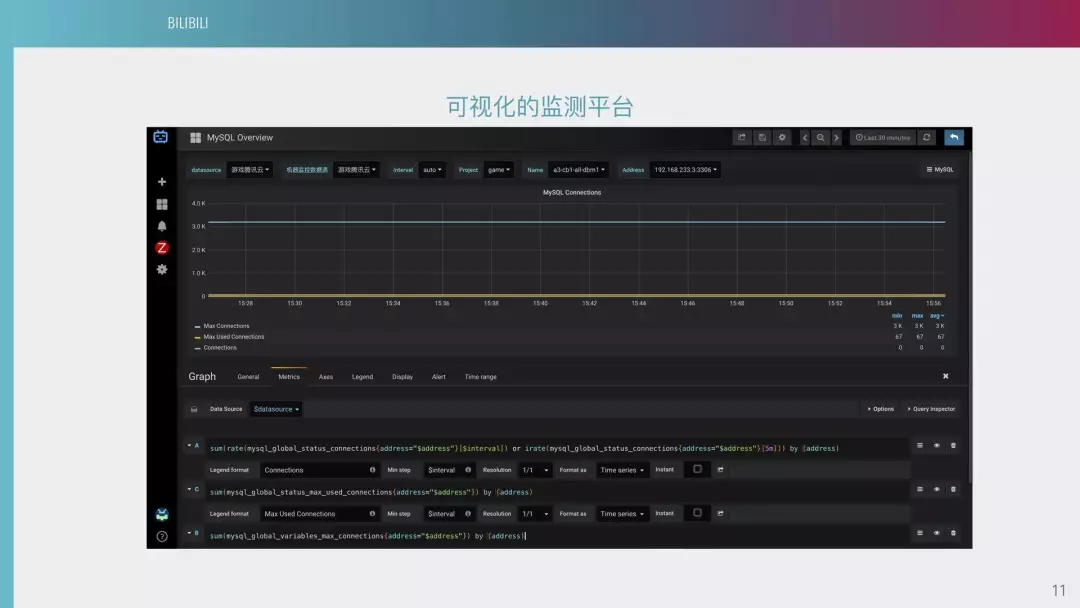
这是可视化的监测平台中的告警配置。我们目前的告警可视化后端,都是 PROMETHEUS。下面是它的查询语句呈现出的图形,上面是一些筛选的条件。
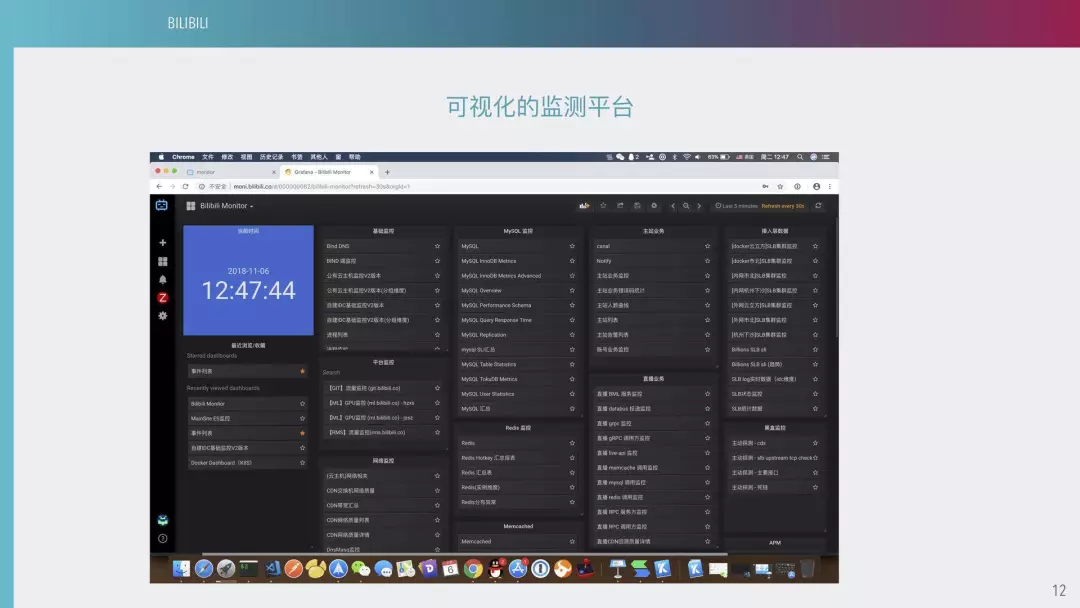
这是我们可视化监测平台的首页。其中包括时钟、基础监测,以及网络方面的信息。它是分几个级别,包括基础侧、中间件、应用侧,是我们根据主站的调用关系、外部链路的首超时、冗段这些数据,来进行不同的级别分层。目前我们所有的监控平台都是基于这个来做的。
下图是监控模板和它的一些配置,主要是数据的展示。
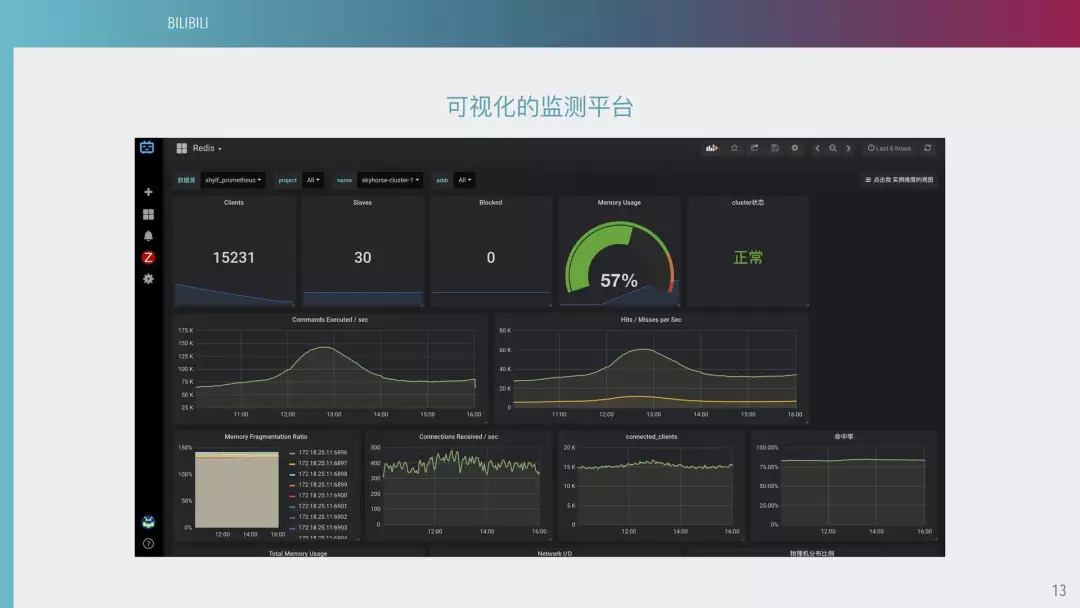
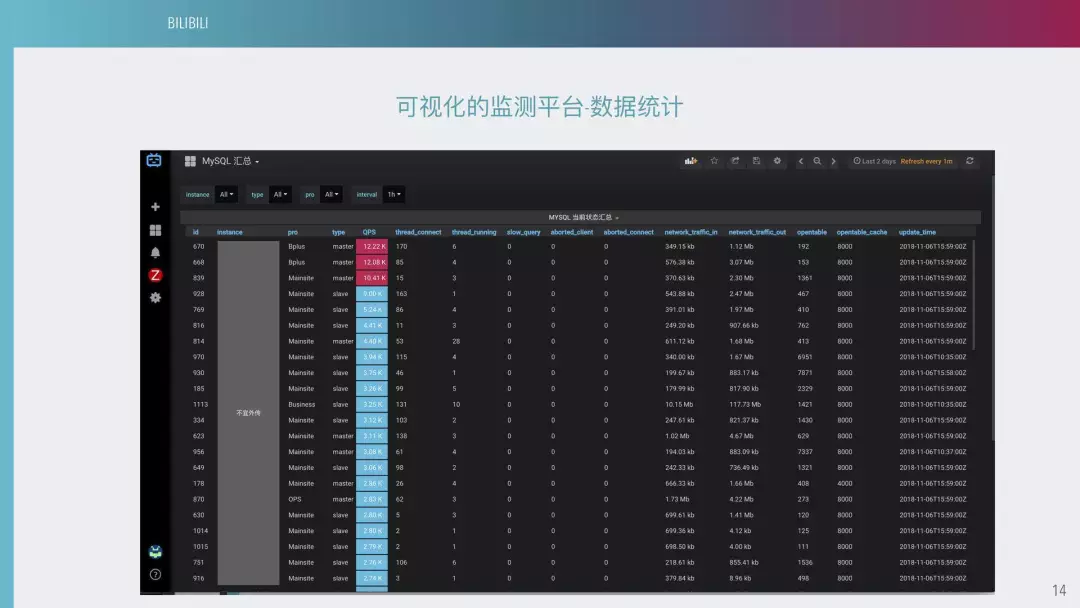
下图是我们的汇总,它可以看到每台机器的 QPS,找到一些关键的指标和相关的负责人。
与很多互联网公司不同,bilibili 采用的是一个大运维体系。从 2015 年做运维开始,我们所有的监控都是统一的整合,很多都是研发提供给我们的。所以我们来比较了解一下,研发大概需要什么样的运维监测系统。
海量数据检索能力
不管是基础监控,还是研发埋点的上报数据,都需要一个统计的数据检索,这个 PROMETHEUS 就完全能满足需求。
故障的发现能力
因为研发的所有数据都已经上报了,研发这一侧完全没有监控能力。所以整个监控的压力全部压在技术平台这边,所以我们对每一个监控都要有及时发现的能力,把它反馈给研发。
高度自由化的系统
作为一个平台建设者,我们的系统并不处在人肉运维的阶段。比如配置一个复杂的告警,每天可能有十几个研发从早到晚找你,并不能够满足大量的需求,所以说我们需要一个高度自由化的系统。
目前来说,我们这一块做得还是不够。因为这里所有都是基于 PROMETHEUS 来做的,就无法满足如计算冗段的值数据复杂的一些复杂场景。如何解决这个问题,当然会成为我们今后工作的重点。
使 SRE 的落地成为可能
因为 bilibili 是主推 SRE 的,目前公司有大概十个平台全部是做这个的,所以站点可靠性建设是一个长期的过程,光靠运维或者研发一方的各自努力是不行的,必须进行合作共赢,需要一个大强度的整合。
挡在我们新一代监测系统之前的几座大山
第一座大山-配置复杂的问题
尽管 PROMETHEUS 提供一个很强大的查询系统,但有一定的学习成本,如果有相对复杂的告警配置,一般需要专业的工程师才能完成,无法完全下放研发。
第二座大山-平台的扩展能力
原生的 PROMETHEUS 并没有很好的企业级解决方案,并且不支持集群化,所有都分散在各个机房,PROMETHEUS 的机房也比较复杂,首先有 IDC,也有海外的公有云和自己的私有云,基本上是一个混合云的架构。所以说我们的 PROMETHEUS 不支持集群化方案,我们必须在不同的环境去部署 PROMETHEUS,每台系统之间都是无法有效集合在一起。也就是你要查一个数据,可能首先要知道这个数据在哪个云上,业务在哪里,才能查询到,所以说这是一个比较麻烦的问题。
第三个座大山-告警的智能化
这个问题主要是如何应对告警公报。如果每天收集到 4000 多条消息,这些消息是完全没有价值的,你根本不可能一条条看过来。我们目前是采用一个打标签的方式,也在研究一些机器学习的算法,来把它应用到一个告警平台里面去,可以对相同内容的告警进行一些智能的聚合。
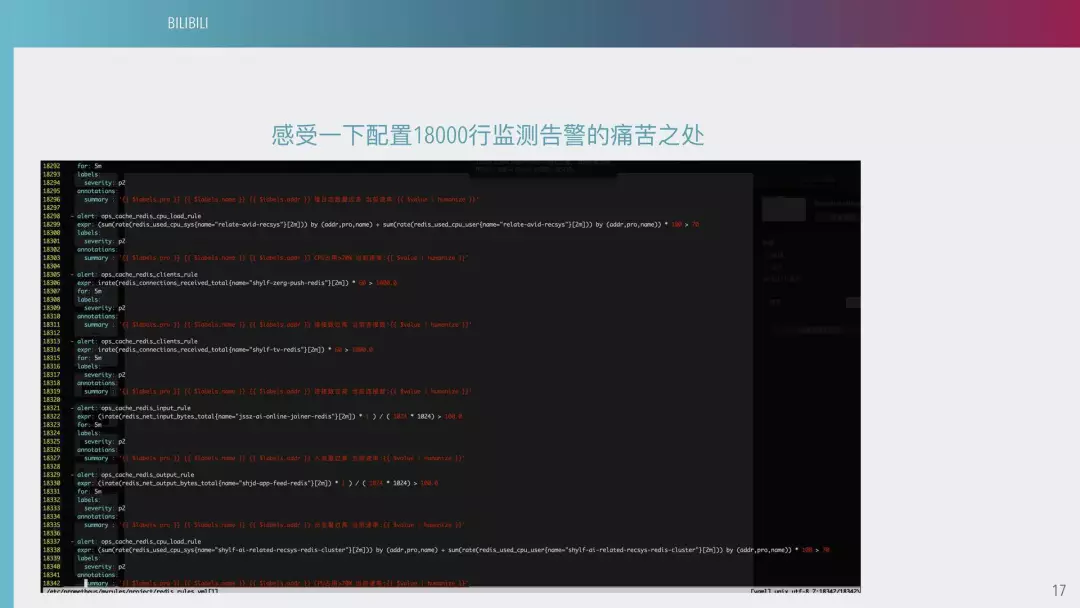
配置 18000 行监测告警的痛苦
在这种情况下调配,我们一般来说是安排两个运维工程师坐班不停地跟研发配告警规则,如果是相似的可以做到一些程序化,如果有一些特殊的需求就无法满足了。
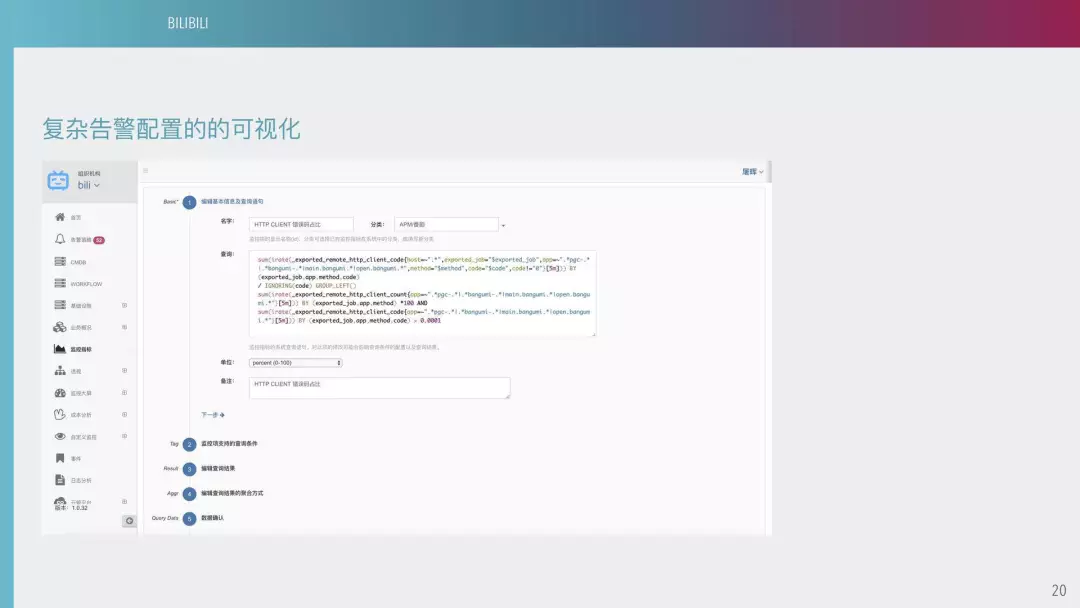
告警配置自主化下放是目前我们是和友商合作进行的,对我们所有的配置文件进行图形化的配置,可以基于一些标签,用服务器进行筛选,然后对服务进行筛选。因为所有的监控都在我们这边,所以说你们会看到形形色色的监控。
原生的 PROMETHEUS 是不支持告警的,如果这边告警断了以后你是无法察觉到,就是你告警是完全报不出,你不知道它的数据。这边是一个配置,就是把所有的配置做成图形化。
目前我们把这些配置下到研发,大概有 300 多个研发,完全让他们自主化配置,可以对它进行一些静默操作。
下图是一些复杂告警配置。比如说一个主站的监控,可能要监测到设备耗时,是一些第三方组件的耗时,所有的服务都是在我们这个平台上托管。等于我们现在把所有的监控通过这个平台下放给研发,让研发可以自主配置。

下图是一个复杂告警配置。像这样的语句是计算 HTDP 错误码占比,正常情况下应该是有一定比例的,当超过一定的比例以后我们就要发出告警。假如你要写 PROMETHEUS 的告警语句,是相当复杂的,如果你是没有受过专业学习的普通研发,可能这个语句都写不了。所以说我们目前会有一个运维人员把具体的语句写好,再在平台上创建一个指标,普通的人只要针对这个指标过滤一些方法、UIL,来决定到底哪个 UIL 需要报警。用这样的方法,就解放出我们很大的工作量。
下图是我们 PROMETHEUS 的企业解决方案。这可以基本上把挡在我们面前的三座大山解决,可以提高我们研发 PROMETHEUS 的很多潜力,包括一些告警策略可视化、监测指标白名单等等都是可以完善的。
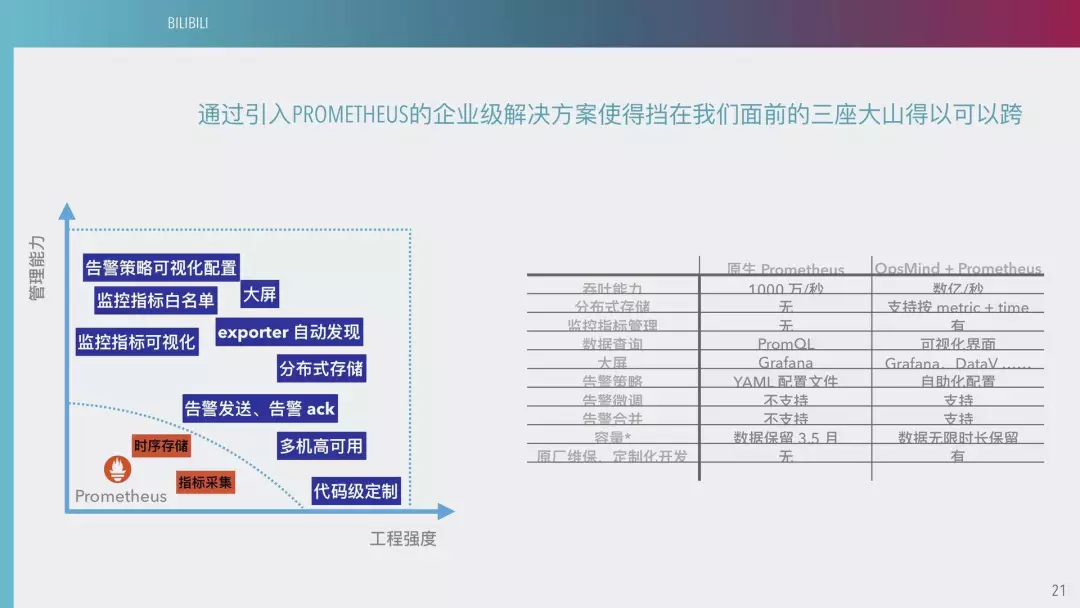
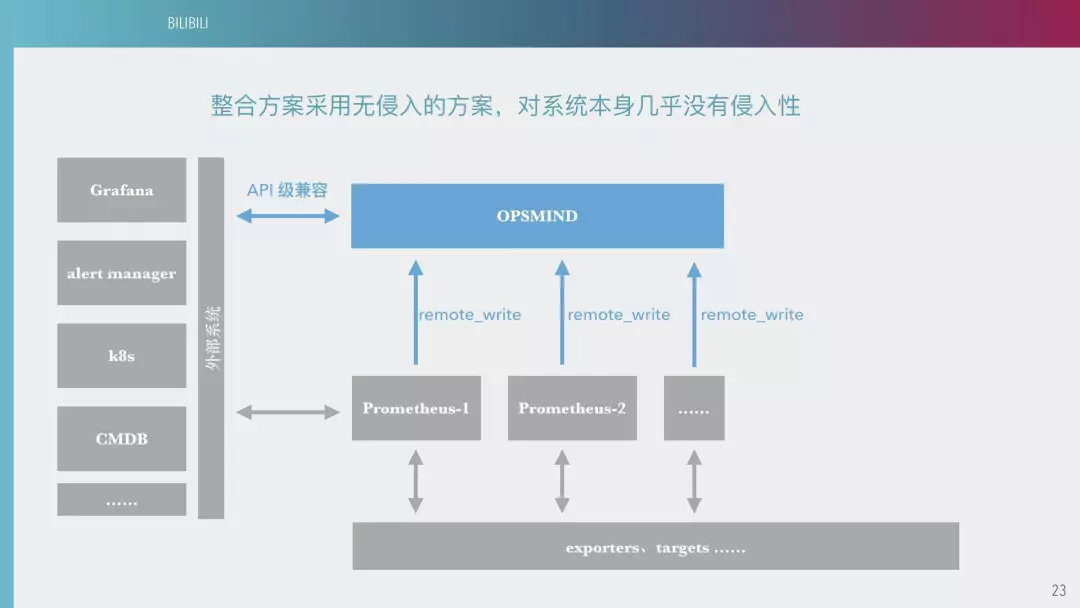
针对告警配置无法下放和 PROMETHEUS 的企业平台化问题,我们通过和 OPSMIND 合作,使得 bilibili 基于 PROMETHEUS 的企业级监测方案获得了很大的提高,成功缩减了人力成本,提升了平台的交付能力,同时也夯实了间系统的工程强度,为后续基于监测数据大数据分析和 AIOPS 的实施提前扫清了障碍。目前使用 11 台服务器分布式环境承载 1 亿条时序指标,成功解决了原有系统的性能和容量问题,将两名配置专员从日常的机械性工作中解放出来。
原来 PROMETHEUS 一个简单的告警可能要反复写,目前通过抽象以后,可以把原来 10 万行的告警配置通过优简化大概到 300 条左右,因为这些都可以通过标签来选择了,而不需要创建新的,这样就降低我们维护的劳动成本。平均每天我们需求方之前大概需要 120 人次,由人力输出变成一个服务型输出,响应时间也大大缩短。
下图是 PROMETHEUS 的整合方案。我们的数据通过不同的结构上报到 PROMETHEUS 以后,会有一些自己的外部系统来进行 PROMETHEUS 的数据展示。同时这是一个双写过程,把这个数据拷贝一份,上到我们 PROMETHEUS 平台,和外部系统的一个展示功能,通过这边可以做一些告警。对整个系统是无损的,对我们架构来说用不着太大的改进。
海量监测平台的建设任重而道远,我觉得可以分为下图所示的四个阶段。

首先是初级阶段。B 站的运维起步比较晚,从 2015 年开始,所以很长一段时间我们都是处在初级阶段。
入门阶段是 2015 年到 2017 年之间,通过整合所有监测系统,引入 PROMETHEUS 监测方案来统一。目前我们通过和友商的合作,把一个复杂的告警配置完全下放,我们自身只是专注于平台化建设。例如海量的 PROMETHEUS 探测目标的管理。
接下来是高级阶段。我们目前所用的,都是一些业务系统上淘汰下来的,所以说高可用的几乎没有。做好平台的高可用、消除单点故障,是这个阶段的关键。一个机房可能只有一台 PROMETHEUS ,如果一个挂了,整个机器在监控平台机房就会挂掉。一旦发生了致命性故障,其实并不会影响到生产系统,所以说随着我们的数据不断接入,我们的重要性越来越高,我们需要一个高可用消除单点故障。
最后是一个智能运维阶段。因为监控本身是有规律的一些数据,我们可以基于这些做一些大数据分析,进行一个整合,这样我们就可以从繁重的劳动中解脱出来。
以上就是我演讲的全部内容,谢谢大家!
作者介绍:
屠辉,拥有 10 年以上运维经验,现任哔哩哔哩基础平台架构师。
本文转载自公众号七牛云(ID:qiniutek)。
原文链接:
https://mp.weixin.qq.com/s/SQMuNgBdeKzxd6ST5xwpMw
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论