

本文最初发布于 ITNEXT 博客。
富兰克林·罗斯福曾经说过,我们往往过多地考虑了早起的鸟儿运气好,却不怎么想早起的虫子运气差。我从来不玩彩票。彩票的失败率大到惊人;实际上,成为圣人或美国总统的可能性都比赢得彩票(例如欧洲的 EuroMillions 或美国的 Powerball)大。
事件驱动型服务的并发常常是一种有保障的反面的彩票中奖,虽然对于特定的并发问题可能概率很低。然而,一切都归结于尝试次数,由于服务所处理的事件量非常大,所以一个不大可能的事件几乎变成了一定会发生的事情。例如,我们曾经遇到一个问题,其发生的概率大约为百万分之一。该服务每秒处理约一百条信息,这意味着该问题每小时会发生三次左右。根据设计,事件驱动型服务需要应对巨大的规模和吞吐量,使得并发问题特别容易发生。
并发问题,或称竞态条件,是指当某行代码并行运行时所产生的意想不到的行为,如果代码单线程运行,就不会出现这种情况。对程序员来说,处理并发问题往往不是自然而然的事情,我们习惯于以单线程的方式来考虑我们的代码。检测并确保代码并行运行的安全,往往需要一个有丰富经验、接受过专门训练的人。而且,并发问题并不明显,往往只在生产环境中才会暴露出来,因为本地或开发环境与实际环境的吞吐量有很大的差别。

火星漫游者
例如,美国国家航空航天局(NASA)有非常严格的编码准则,以及一个非常详尽、细致的质量保证过程。毕竟,调试地球以外的东西与分析大多数生产问题不太一样(虽然有时会觉得有异样的事情在发生)。一个短暂出现的错误,很可能会被大多数开发人员所忽略,但却往往是一个竞态条件的症状。NASA 可不会放过类似的问题,它甚至可能追踪到应用程序之外,开发人员甚至可能要深挖到操作系统层才能找出根本原因。事实上,那是几百万美元的风险。但是,即使有这样孜孜不倦的过程,竞态条件往往还是不可避免。例如,我还记得美国国家航空航天局(NASA)因竞态条件而与火星车失去联系的那段插曲。
并发问题的不可避免性和事件驱动型服务的高吞吐量,使得制定一个深思熟虑的策略来从根本上解决并发问题的需求变得尤为迫切。事件驱动型服务的一个重要属性是能够通过添加同一服务的多个实例来进行横向扩展。这种方法使传统的并发处理方式失效,因为不同的请求可能会被发送到不同的实例上,所以要做一个内存锁,如互斥量、锁或信号量。通常,分布式系统采用外部工具来管理分布式并发,如 Consul 或 Zookeeper。然而,对于事件驱动型服务,可以引入一个本质上完全不同的概念来处理并发。端到端消息路由是一种非常有效并且可扩展的方法,它是通过设计(使用架构解决方案)来处理并发问题,而不是实现(求助于外部工具或在服务实现中)。
多年来,我们借助 RabbitMQ 和 Kafka,在多个不同的生产用例中尝试了几种不同的方法。我们最终决定在可能的时候通过设计来处理并发问题,而不是通过实现。以下是我们在生产中全面使用的一些解决方案,希望可以为你处理并发问题带来一些灵感。
并发问题示例
让我们用一个例子来说明。想象一下,我们有一个产品在线销售平台,用户可以订阅“新进 ”和 “热销补货”产品的通知。每当所需产品的库存增加时,用户可以通过邮件、短信等方式接收通知。持有产品和库存信息的服务在每次库存发生变化时都会发送一个事件。订阅服务必须知道产品库存何时从 0 变为 1,并在变化时发送通知。下图说明了这种情况。
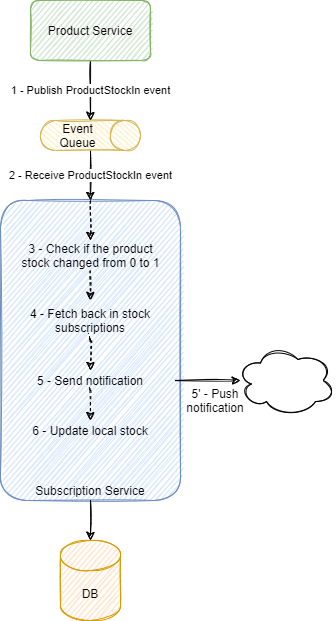
订阅服务处理 ProductStockIn 事件,在产品库存改变时作出反应。因为只有当库存从 0 变为 1 时,订阅才有价值,该服务在内部状态中保存每个产品的当前库存。ProductStockIn 事件流包括以下动作:
1. 产品服务发布事件;
2. 订阅服务处理事件;
3. 获取本地库存,检查库存是否从 0 变为 1;
4. 获取当前的订阅信息;
5. 针对每条订阅发送通知;
6. 更新本地库存数据。
在单线程思维模式下,这种方法讲得通,不会产生任何问题。然而,为了充分优化服务资源并达到合理的性能,我们应该给服务添加并行性。如果服务处理两个或两个以上的事件会发生什么?一个竞态条件会使服务把同一个订阅发布两次。如果服务处理两个库存变化事件(例如,库存从 0 到 1 和从 1 到 2),并同时运行步骤 3 的验证,那么它将传入两个事件,产生一个竞态条件,并因此把相同的通知发送两次。
要处理这个问题,只需简单地用传统的并发处理方法(如锁、互斥量、信号量等)锁定线程执行。然而,传统方法只适用于单实例服务,如下图所示。
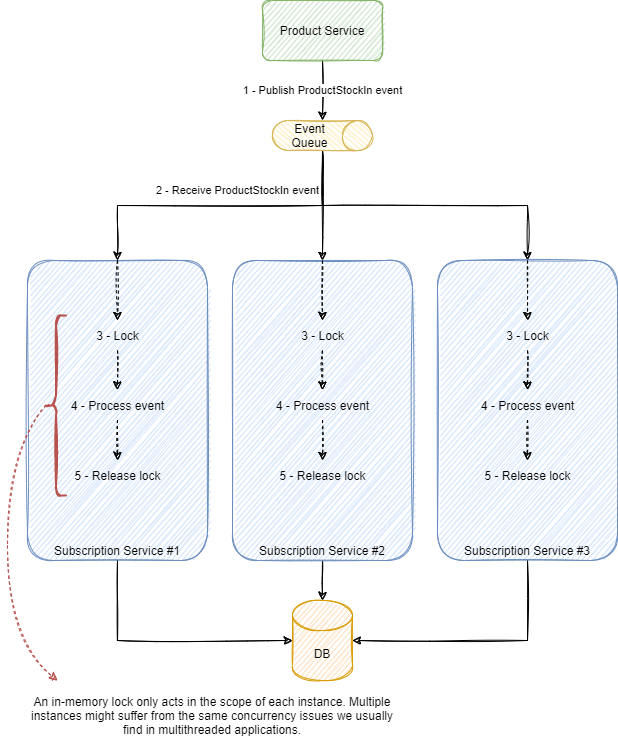
由于内存中的锁只被做锁的实例共享,其他实例仍然能够同时处理其他事件。同一产品的两个库存变化事件可以由不同的实例来处理,即使两个实例都锁定了它们的执行,也只在它们各自的实例内有效,没有什么可以防止两个实例之间产生并发问题。由于事件驱动型服务的一个重要属性是水平扩展的能力,这类传统的方法在这种情况下可以说相当不充分。
本地锁的一个替代方法是使用数据库来防止并发问题。处理货币时有一个典型的悲观方法(下文会介绍更多关于悲观方法和乐观方法的内容),就是将操作包裹在一个事务中。然而,通常来说,没有一种简单直接的方法可以保证存在外部依赖时的交易一致性,而又不涉足我们最想也应该避免的分布式交易领域。使用事务性一致性也受限于支持它的技术,许多 NoSQL 数据库并不提供与传统关系型数据库相同的保证。
悲观方法 vs 乐观方法
有两种处理并发的方法:悲观方法和乐观方法。
悲观的并发策略通过阻止对所需资源的并行访问来防止并发。这类策略假设存在并发,并因此预先限制了对资源的访问。这类策略适用于高并发的用例,即两个进程很可能同时访问同一资源。
乐观并发策略假设不存在并发。这类策略是在并发问题发生时,提供一个策略来处理失败的操作,抛出一个错误或是重试该操作。乐观并发在并发几率较低的环境中最有效。
悲观并发会影响性能,并且限制了解决方案的整体并发性。乐观并发可以提供很好的性能,因为它不锁定任何东西,只是对失败做出反应。在低并发环境中,几乎就像没有并发处理策略一样。然而,当并发的可能性很高时,与限制对资源的访问相比,重试操作的成本通常要高很多。在这些情况下,最好使用悲观并发。
Kafka 主题剖析
Kafka 是一个流行的事件流平台。如果你用它来实现简单的发布 - 订阅和事件流用例,并且不太关注它的内部工作原理,那么你可能会因为使用其事件路由功能而错过一些强大的功能。
发布的事件被发送到主题。Kafka 主题(类似于队列,但即使在消费后也会持续保持每个事件,就像分布式事件日志一样)被划分为不同的分区。下图是对 Kafka 主题的剖析:
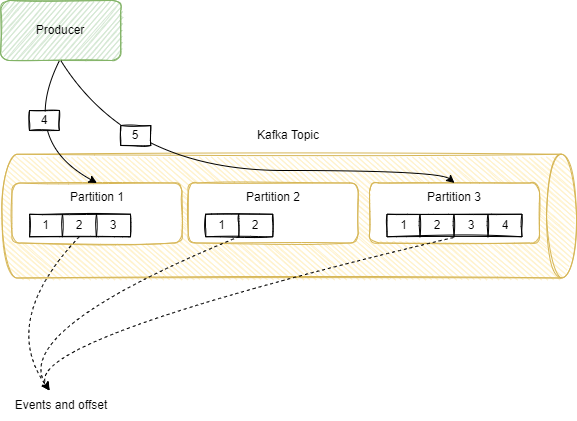
当应用程序将一个事件发布到一个特定的主题时,它会被存储在一个特定的分区。为了将事件分配到分区,Kafka 会对键做哈希计算出分区,当没有键时,它就会在分区之间循环。然而请注意,使用键,我们可以确保所有键相同的事件被路由到相同的分区。我们将会看到,这是一个关键属性。
消费者处理来自主题的事件。通常,事件驱动型服务是可以横向扩展的,我们可以通过增加同一服务的实例来增加其吞吐量。因此,一个服务,例如我们在这个例子中讨论的订阅服务,可以有多个实例同时从同一主题消费,这就容易受到我们之前讨论的并发问题的影响。一个分区有且只有一个服务实例消费。
Kafka 保证每个分区的顺序,但不保证主题的顺序。也就是说,如果你发布一条消息到一个主题,并不能保证消费者按顺序收到这些消息(尽管很可能会按顺序收到,除非发生网络分区或再平衡,而这并不常见)。然而,Kafka 保证单个分区中消息的顺序。每个分区都仅被一个消费组中的一个实例所消费。
Kafka 是一个分布式事件流平台,关键词是“分布式”。分区被分配到一台机器上,这意味着一个主题在物理上可以存储在几台机器上(连同其容错副本)。这实现了高可扩展性和高可用性。然而,如果你和分布式系统打交道的时间足够长,很可能就知道在几台机器上保证顺序有多难,因此它只保证分区内的顺序而不是整个主题内的。
不过,也并非全无作为,它提供了以下三个特性:
一个分区有且只有一个服务实例消费。
路由键相同的事件被路由到同一个分区。
一个分区中可以保证顺序。
上述三个特性为实现真正有用的解决方案奠定了基础。它可以提供工具,按顺序消费事件而不发生并发问题,正如我们接下来要看到的。
通过设计处理并发
如上所述,我们可以应用悲观或乐观的解决方案来处理并发。不过,还有一个完全不同的方法,就是通过设计来处理并发。我们不是应用策略来处理并发,而是将系统设计成根本没有并发。当然,这是一个非常理想的方法,但在非事件驱动解决方案中往往不可行。利用我们前面讨论的三个特性,事件驱动型服务成为通过设计方法处理并发的主要受益者。
在事件驱动型服务中,通过设计处理并发有一个非常有效的方法是使用将事件路由到特定分区的能力。由于每个分区只被一个实例所消费,所以我们可以根据路由键将每组事件路由到特定的实例。有了正确的路由键,我们就可以在设计系统时避免在同一实体内发生并发。
举例来说,我们如何将这个理念应用到我们讨论的产品和订阅服务的例子中?比方说,我们使用产品 ID 作为路由键。根据我们刚才讨论的特性,同一产品的所有事件将被路由到同一分区,由于一个分区只被唯一的实例所消费;该产品的所有事件将只由一个实例来处理,如下所示:
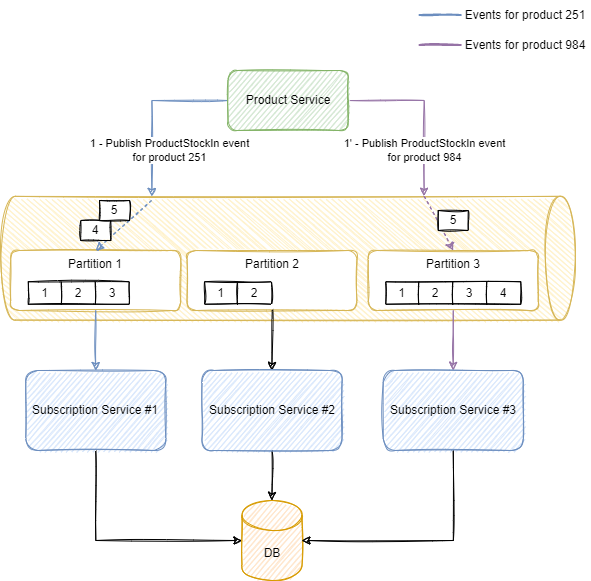
产品 251 的所有库存事件保证都由订阅服务实例 #1 所消费,并且只由该实例消费。由于没有其他实例可以处理同一产品的事件,所以我们可以使用传统的方法来处理并发问题,即使用锁等进程内并发处理策略。我们将分布式并发问题转化为进程内并发问题,这样处理起来就比较简单了。在订阅服务内部,我们甚至可以使用相同的策略将事件路由到特定的线程。这种端到端的事件路由可以以一种高度可扩展且可持续的方式消除并发。
由于 Kafka 保证了单个分区内的顺序,所以事件也是有序的。因此,我们也避免了处理失序事件的复杂性。
通过设计解决并发问题,我们将系统设计成完全没有并发。这样做性能更高,错误更少,因为它不像悲观方法那样涉及特定资源锁定,也不像乐观方法那样涉及重试操作。这也有利于新功能的开发,因为开发者无需考虑并发的边缘情况;我们可以假设并发根本不存在。
小结
分布式系统中的并发是一个棘手的问题,悲观方法和乐观方法都是一种选项,但它们通常意味着性能损失。虽然在某些用例中很有用,但由于涉及到锁定或重试,它们会影响到微服务的可扩展性。事件驱动型服务和将事件路由到特定服务实例的能力提供了一种优雅的方式来消除解决方案中的并发,即通过设计来解决并发,这为真正做到水平可扩展奠定了基础。
查看英文原文:
https://itnext.io/solving-concurrency-in-event-driven-microservices-79bbc13b597c

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论