
DeepSeek AI 推出 DeepSeek-OCR,一个开源系统,使用光学 2D 映射来压缩长文本段落。这种方法旨在增强大语言模型处理文本密集型输入的能力。这种被称为 “上下文压缩新范式” 的方法表明,与传统标记化相比,视觉编码可以更高效地存储和检索语言。
DeepSeek-OCR 由两个核心组件构成:负责视觉压缩的 DeepEncoder,以及作为解码器的 DeepSeek3B-MoE-A570M。该系统实现了 97% 的 OCR 精度,压缩比低于 10×,可将十个文本标记压缩为一个视觉标记。即便在 20× 的压缩比下,它仍能保持约 60% 的精度,这表明即使大幅减少标记数量,也能保留有意义的内容。
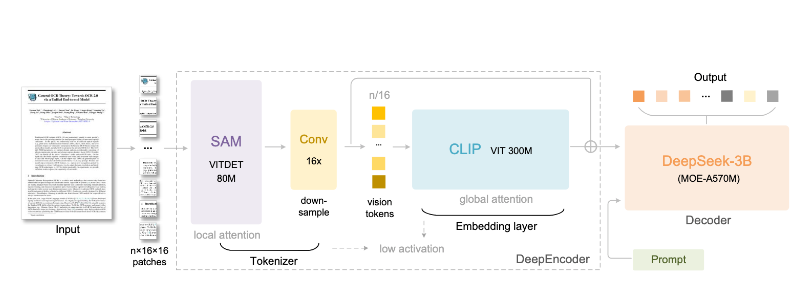
来源:https://arxiv.org/pdf/2510.18234
DeepEncoder 架构在高效处理高分辨率输入的同时,将激活内存降至最低。它结合窗口注意力机制、全局注意力机制以及 16× 卷积压缩器,能够进行大规模图像处理而不出现 GPU 内存问题。DeepSeek-OCR 已经超越 GOT-OCR 2.0 和 MinerU 2.0 等先进模型,以每页少于 800 个视觉标记的高效配置实现了更高的精度。
解码器采用混合专家(MoE)架构,可以对不同的 OCR 子任务进行专门处理,同时保持速度和精度。这使得模型能够以媲美全尺寸 OCR 软件套装的精准度,读取图表、公式以及多语言文档,且在计算资源的消耗上大幅降低。
研究团队将 DeepSeek-OCR 定位为不仅仅是 OCR 系统——它更是下一代 LLM 内存机制的潜在基础。通过将长上下文存储为压缩的视觉标记,模型可以有效地 “记住” 过去的信息,而不会增加标记数量。
人工智能社区的早期反馈充满了好奇。一位 Reddit 用户写道:
这看起来像是 Gemini 2.5 已经拥有的东西,除非他们在背后使用了额外的工具。我曾处理过一些文本密集型图像,标记数量甚至少于实际转录的文本,但它依然能够毫无问题地处理它们。
发布之后,开发人员就模型在本地运行的实操细节展开了讨论。在 Reddit 上,一位用户提出了自己的疑问:
我希望我能够知道如何在我的台式电脑上运行这些视觉模型。它们不会转换成 GGUF 格式,而且我不确定还有其他什么方法可以运行它们,因为我现在肯定能用上这样的东西。有什么建议吗?
另一位用户给出了说明:
可以借助 Python 的 transformer 库来运行,不过这会是全精度模式,所以需要一定的显存(VRAM)。一般来说,3B 模型应该能在大多数 GPU 上运行。
DeepSeek-OCR 的代码和模型权重已在 GitHub 上开放,DeepSeek 邀请研究人员们去重现它的结果,并在此基础上进一步拓展研究。该系统在通过视觉通道对大型文本文件进行压缩和解码方面的出色性能,或许会对未来 LLM 在效率与内存平衡问题上提供新的思路和方向。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】




