

Kubernetes 为职业数据科学家提供了无与伦比的功能组合。简化软件开发工作流的特性也为数据科学工作流提供了支持。
正文
本文最初发布于Opensource.com,经原作者授权由 InfoQ 中文站翻译并分享。

图片来源:opensource.com
首先,让我们从一个没有争议的观点开始:软件开发人员和系统管理员都喜欢将Kubernetes作为一种在 Linux 容器中部署和管理应用程序的方法。Linux 容器是可重复构建和部署的基础,但是,Kubernetes 及其生态系统为让容器适合运行应用程序提供了基本特性,比如:
持续集成和部署:你可以实现从 Git 提交到向在生产环境中运行的新代码传递测试套件的整个流程;
全面监控:跟踪系统组件的性能和其他指标并以有意义的方式可视化让其更易分析;
声明式部署:依靠 Kubernetes 在临时环境中重建生产环境;
灵活的服务路由:这意味着可以扩展服务或将更新逐步发布到生产环境(如果需要,还可以将其回滚)。
你可能不知道,Kubernetes 还为职业数据科学家提供了无与伦比的功能组合。简化软件开发工作流的特性也为数据科学工作流提供了支持。要知道为什么,我们先来看看数据科学家是怎么工作的。
数据科学项目:预测客户流失率
有些人对数据科学的定义很宽泛,包括机器学习(ML)、软件工程、分布式计算、数据管理和统计。另一些人则狭义地将数据科学定义为将某些领域的专业知识与机器学习或高级统计相结合,寻找解决实际问题的方法。在本文中,我们不会给出数据科学家的明确定义,但是,我们将告诉你数据科学家在一个典型的项目中可能要做什么,以及他们可能如何工作。

拥有订阅客户的企业都面临一个问题:有些企业可能不会续订。客户流失检测旨在主动识别那些可能不会续签合同的客户。一旦这些客户被识别出来,企业可以选择用特定的干预措施(例如销售电话或折扣)来锁定这些老主顾,以降低他们离开的可能性。整体上,流失预防问题有几个部分:预测哪些客户可能会离开,确定哪些干预措施可能会留住客户,以及在干预预算有限的情况下,将哪些客户作为优先目标。数据科学家可以对其中任何一个或所有部分进行研究,但是我们将以第一部分为例。
要解决这个问题,第一步是确定合适的定义,以便将“流失”纳入预测模型。对于怎样算失去一个客户,我们可能有一个直观的定义,但数据科学家需要形式化的定义,比如说,将客户流失预测问题定义为:“考虑客户在过去 18 个月的活动,他们有多大可能在未来 6 个月中取消他们的合同?”

然后,数据科学家需要决定模型应该考虑有关客户活动的哪些数据——实际上,就是研究并形式化客户流失定义的第一部分。具体地说,数据科学家可能会考虑有关客户在该历史窗口中实际使用该公司产品的信息、客户规模、客户-服务交互次数,甚至是他们在其提交的服务工单上所留下的评论的语气。模型所考虑的度量值或数据称为特征。
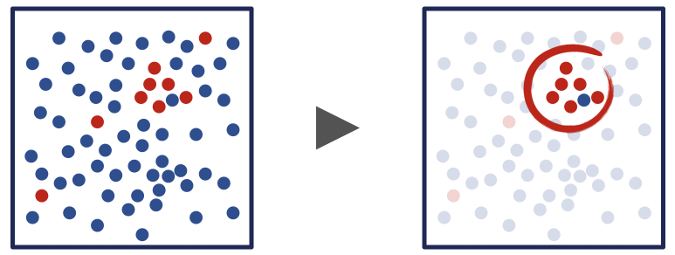
有了流失定义和一组要考虑的特征之后,数据科学家就可以开始对历史数据(包括特征集和给定时期内给定客户的最终结果)进行探索性分析了。探索性分析可以包括可视化特征组合,以及查看它们是否与客户会流失相关。更一般地说,这部分处理是为了识别历史数据中的结构,以及是否有可能根据描述客户的数据在留下的客户和流失的客户之间找到清晰的划分。
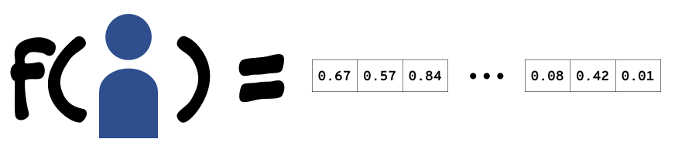
对于某些问题,数据中是否存在结构并不明显——在这些情况下,数据科学家将不得不从头做起,确定要收集的一些新数据,或者确定一种对可用数据进行编码或转换的新方法。然而,探索性分析通常会帮助数据科学家确定在训练预测模型时要考虑的特征,并提出一些转换这些数据的方法。数据科学家的下一项工作是特征工程:找到一种方法来转换和编码特征数据——这些数据可能位于数据库表中、事件流中或者是通用编程语言的数据结构中——以便能作为模型训练算法的输入。通常,这意味着将这些特征编码为浮点数的向量。不是任何编码都行;数据科学家需要找到一种可以保留特征结构的编码,这样,类似的客户就可以映射到类似的向量,否则算法的性能就会很差。
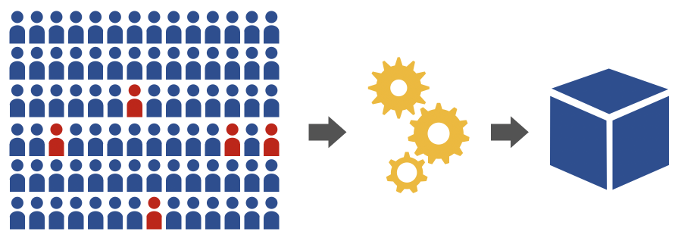
直到现在,数据科学家才准备好训练一个预测模型。对于预测客户是否会流失的问题,模型训练管道从标注过的客户历史数据开始。然后,它使用在特征工程过程中开发出的技术从原始数据中提取特征,生成带有“true”或“false”标记的浮点数向量,并对应到你所感兴趣的窗口中将会流失或不会流失的客户。模型训练算法将这些特征向量集合作为输入,优化过程,以错误率最低的方式分离真假向量。预测模型最终是一个函数,它接受一个特征向量并返回 true 或 false,指示与该向量对应的客户是否可能流失。
在这个过程的任何一点上,数据科学家可能需要重新回到以前的阶段——也许是改进特征工程方法,收集不同的数据,甚至是更改他们试图预测的指标。在这种情况下,数据科学工作流和传统的软件开发生命周期非常像:在实现过程中发现的问题可能会迫使工程师更改接口的设计或数据结构的选择。这些问题甚至可以级联到需求分析,对项目的基础情况进行更广泛的反思。幸运的是,Kubernetes 可以像支持软件开发生命周期一样支持数据科学家的工作流。
面向数据科学的 Kubernetes
数据科学家和软件工程师有许多相同的关注点:可重复的实验(比如可重复的构建);可移植和可复制的环境(如在开发、过渡和生产环境中具有相同的设置);凭证管理;跟踪和监控生产环境中的指标;灵活的路由;轻松扩展。不难看出,应用程序开发人员使用 Kubernetes 所做的事情与数据科学家可能想做的事之间有一些类似之处:
可重复的批处理作业,如 CI/CD 管道,类似于机器学习管道,多个协同阶段在其中以可重复的方式一起处理数据、提取特征、训练、测试和部署模型;
描述服务之间连接的声明性配置有助于创建跨平台的可重复学习管道和模型;
微服务架构支持在管道中对机器学习模型进行简单地调试,并帮助数据科学家和他们团队中的其他成员进行协作。
数据科学家与应用程序开发人员面临许多相同的挑战,但他们也面临一些独特的挑战,这些挑战与数据科学家的工作方式以及机器学习模型比传统服务更难测试和监控这一事实有关。我们将重点讨论一个与工作流相关的问题。
大多数数据科学家使用交互式笔记本(interactive notebooks)工作,这是一个笔记本环境,通常由Project Jupyter开发,提供一种交互式迭代编程环境,用户可以在其中混合说明性本文和代码、运行并更改代码、检查其输出。
这些特性使得该环境对探索性分析非常灵活。然而,它们并不是用于协作或发布的理想软件工件——想象一下,如果软件开发人员发布工作的主要方式是将来自交互式REPL脚本发布到 pastebin 服务。
与同事分享交互式笔记本就像分享实体笔记本一样——里面有一些很好的信息,但是必须仔细查找才能找到。由于笔记本的脆弱性和对环境的依赖性,同事在运行笔记本时可能会看到不同的输出——甚至更糟:它可能会崩溃。
面向数据科学家的 Kubernetes
数据科学家可能不想成为 Kubernetes 专家——这很好!Kubernetes 的优点之一就是构建更高级工具的强大框架。
Binder服务就是其中一个工具,采用一个 Jupyter 笔记本的 Git 存储库,构建容器镜像来提供服务,然后在路由公开的 Kubernetes 集群中启动镜像,这样就可以从公网访问。由于笔记本的一大缺点是其正确性和功能可能依赖于其环境,因此,如果有一个高级工具可用来构建不可变环境为 Kubernetes 上的笔记本提供服务的话,就可以避免许多让人头疼的事。
你可以使用托管的 Binder 服务或运行自己的Binder实例,但是,如果你想在这个过程中获得更大的灵活性,你还可以使用Source-To-Image(S2I)工作流和工具,以及Graham Dumpleton提供的Jupyter S2I镜像上线自己的笔记本服务。事实上,对于基础设施专家或打包专家来说,Source-To-Image 工作流是构建可供主题专家使用的高级工具的良好起点。例如,Seldon 项目使用S2I来简化模型服务发布——只要向构建器提供一个模型对象,它将构建一个容器并将其作为服务公开。
Source-To-Image 工作流的一个优点是,它支持在构建映像之前对源存储库进行任意操作和转换。有个例子可以说明这个工作流有多强大,我们创建了一个S2I构建器镜像,该镜像以一个 Jupyter 笔记本作为输入,该笔记本展示了如何训练模型。然后,它处理这个笔记本以确定它的依赖关系,并提取 Python 脚本来训练和序列化模型。有了这些,构建器就会安装必要的依赖项并运行脚本来训练模型。构建器的最终输出是一个 REST Web 服务,它为由笔记本构建的模型提供服务。你可以看下 notebook-to-model-service S2I 的运行视频。同样,这不是数据科学家必须开发的工具,但是,创建这样的工具是 Kubernetes 专家和打包专家与数据科学家合作的绝佳机会。
面向生产环境机器学习的 Kubernetes
对于正在开发技术利用机器学习解决商业问题的数据科学家,Kubernetes 提供了很多帮助,同时,它也为将这些技术投入生产应用的团队提供了很多帮助。有时候,机器学习代表一个独立的生产工作负载——用于训练模型和提供见解的批处理作业或流作业——但是,机器学习作为智能应用程序的一个重要组成部分越来越多地投入到了生产应用。
Kubeflow项目的目标用户是机器学习工程师,他们需要在 Kubernetes 上搭建和维护机器学习工作负载和管道。对于精通基础设施的数据科学家来说,Kubeflow 也是一个非常好的发行版。它提供模板和自定义资源来在 Kubernetes 上部署一系列机器学习库和工具。
Kubeflow 是在 Kubernetes 上运行 TensorFlow、JupyterHub、Seldon 和 PyTorch 等框架的一种很好的方式,因此,它代表了真正可移植工作负载的一个路径:数据科学家或机器学习工程师可以在笔记本电脑上开发管道并将其部署到任何地方。这是一个快速发展的社区,开发了一些很酷的技术,你应该看看。
Radanalytics.io是一个面向应用程序开发人员的社区项目,其重点是基于容器中的扩展计算开发智能应用程序的独特需求。Radanalytics.io 项目包括一个容器化的 Apache Spark 发行版,以支持可伸缩的数据转换和机器学习模型训练,以及 Spark 操作界面和 Spark 管理界面。该社区还为智能应用程序的整个生命周期提供了支持,提供了 Jupyter 笔记本模板和镜像、TensorFlow 训练和服务以及 S2I 构建器,后者可以部署应用程序及其所需的扩展计算资源。如果你想在 OpenShift 或 Kubernetes 上开始智能应用程序构建,radanalysis.io 的示例应用程序或有关会议演讲会是一个不错的起点。
查看英文原文:Why data scientists love Kubernetes

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论