

Deepfake 自诞生以来,就与造假、伪造等词语紧紧捆绑在一起,只要出现在人们的视野中,就一定与新的造假方法有关。虽然遭到了公众的联合抵制,但是这并不能削减研究人员对相关技术探索的热情,就在今天,一种新的“Deepfake”技术又出现了。
据国外科技媒体 The Verge 报道,近日三星人工智能研究中心和伦敦帝国理工学院的研究人员提出一种新型端到端系统,只需要一张照片,加上一段音频,就能让爱因斯坦张嘴演讲,让百年以前就去世的人大唱歌手碧昂斯的歌曲,甚至还可以为合成视频里的人物配上对应的表情。
一张照片+一段音频=合成视频
先来看看通过照片+音频合成的视频到底效果如何?
通过著名科学家爱因斯坦的一张照片,再配合上他本人之前的演讲,就能合成出这样一段视频:
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.5x
被称为“俄国妖僧”的拉斯普京早在百年以前就去世了,但是通过这项技术,他竟然能在视频里大唱著名歌手碧昂斯的热单《Halo》:
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.5x
虽然声音仍然是碧昂斯的,但是通过视频能够看到,照片中人物的口型几乎和歌词是一模一样的。
如果说之前的两个案例还算是正常发挥,那么下面这段视频就有些“放大招”的意思了:
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.5x
不仅合成了与输入音频匹配的视频,而且还可以通过调整表情以传达特定情感。请记住,创建这些视频所需的只是一张图片和一个音频文件,算法完成了其余所有工作。
这几个案例虽然看上去有些唬人,而且合成的视频并非是 100%完美无缺的,但它是这项技术发展速度之快的最新例证,其背后的原理值得探索。
技术原理
据介绍,这是一套端到端系统,生成的视频拥有与音频同步的唇部运动和自然的面部表情,例如眨眼和皱眉。这项研究的相关论文也入选了 CVPR 2019。
论文地址:https://arxiv.org/pdf/1906.06337.pdf

图 1:论文提出的端到端人脸合成模型,能够使用一个静止图像和一个包含语音的音轨生成逼真的人脸序列。
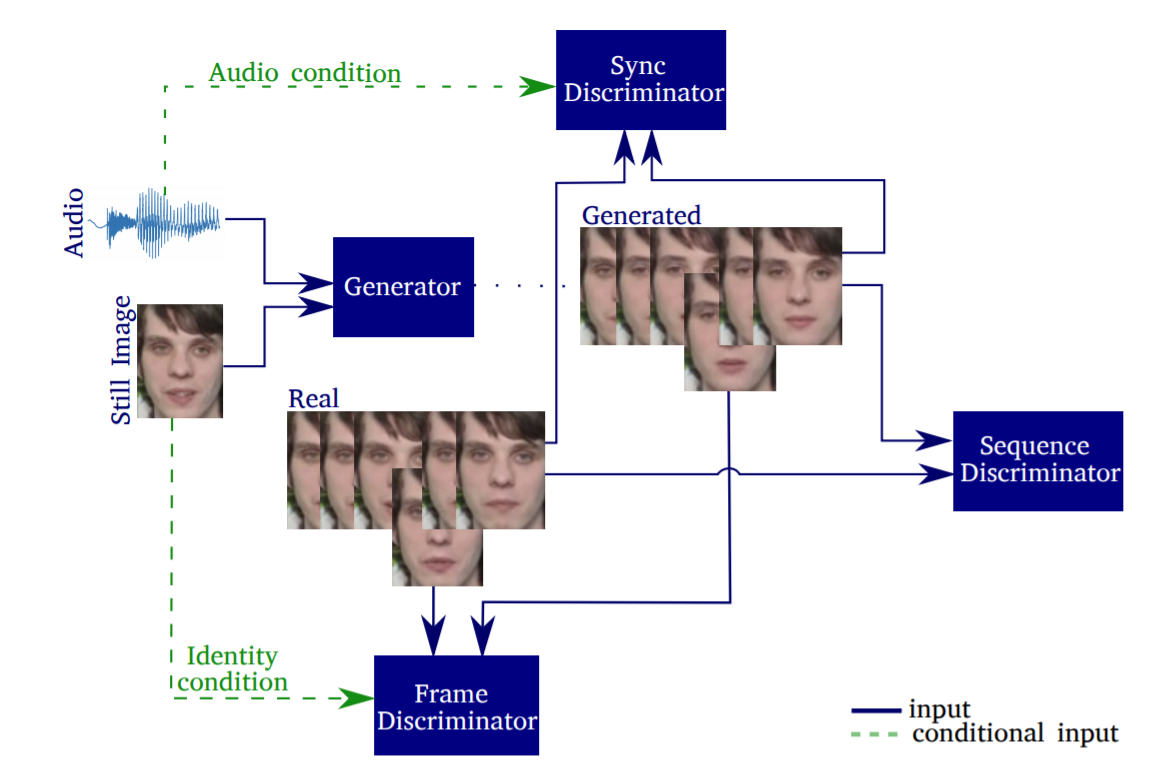
图 2:语音驱动面部合成的深层模型"
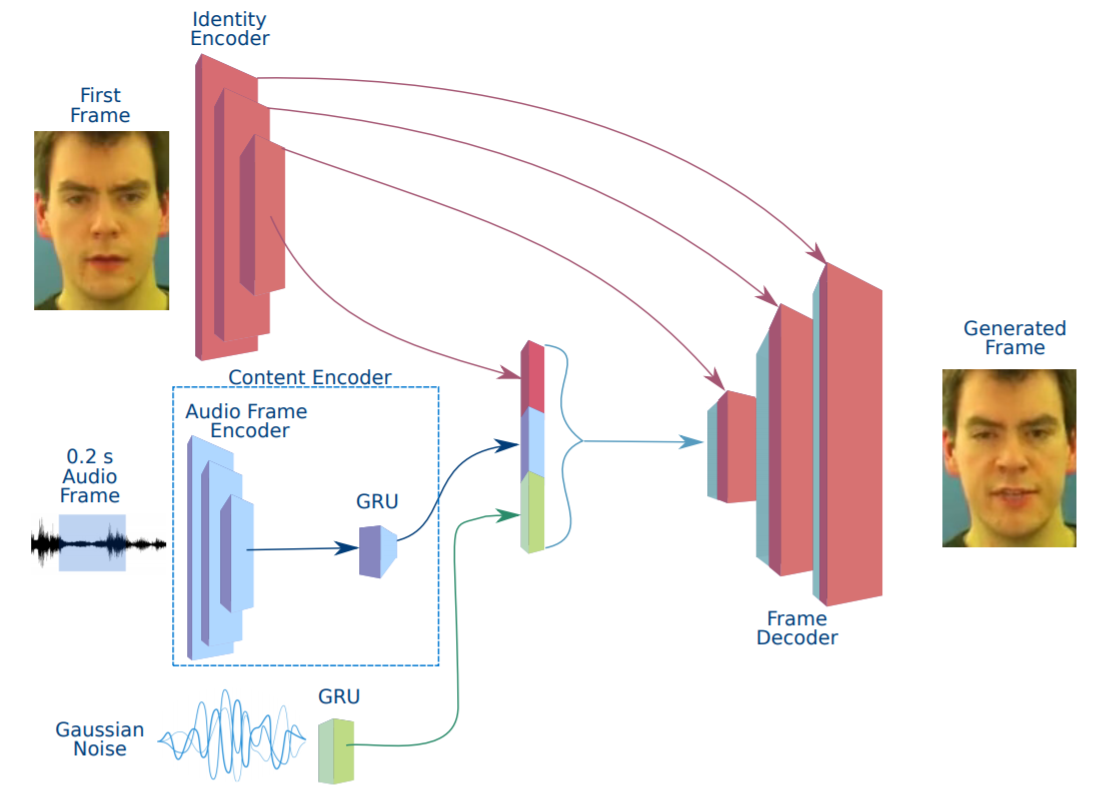
图 3:生成器网络结构

图 4:向生成器网络添加残差连接的影响。
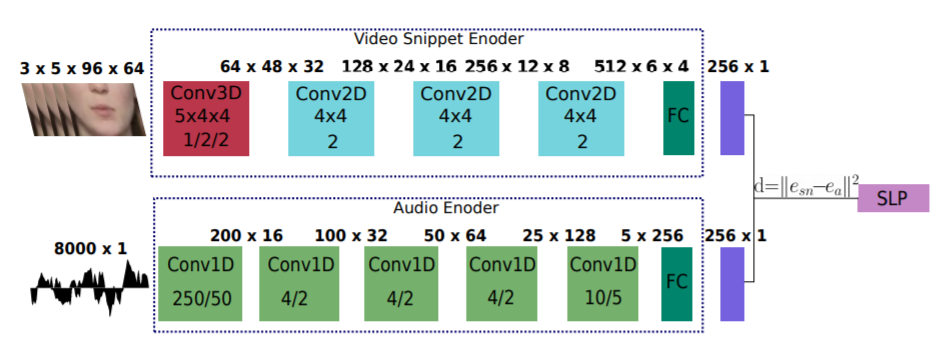
图 5:同步鉴别器决定视听对是否同步。 它使用 2 个编码器来获取音频和视频的嵌入,并根据它们的欧几里德距离决定它们是否同步。
与 Speech2Vid 模型相比,这一方法在最终呈现效果上提升了不少:

从上图可以看出:Speech2Vid 模型虽然也做到了让人物开口讲话,但是除了嘴部动作几乎没有表情,而新方法的效果让人物的表情、动作更加自然,虽然会显得有些夸张,但是比起直勾勾瞪着人的表情已经进步了不少。
Speech2Vid 模型是另一种仅使用音频语音段和目标身份的面部图像来生成说话人脸的视频的方法,可通过该篇论文了解:https://link.springer.com/content/pdf/10.1007%2Fs11263-019-01150-y.pdf
Deepfake 技术会走向何方?
制作类似 Deepfake 的技术正在变得越来越容易,尽管像这样的研究还没有大规模商业化,但最初的 Deepfake 制造者很快就把他们的技术捆绑到易于使用的软件中,同样的情况也会发生在后来出现的这些新方法上。
注:Deepfake 技术已经被一些公司进行了小范围的商业化,AI 前线也曾经进行过报道,感兴趣的读者可以点此回顾。
类似的研究层出不穷,让人们担心它们可能被用于误导和宣传,这个问题甚至已经困扰到了一些国家的立法者。尽管有无数种方法整明技术是无害的,但它确实已经造成了真正的伤害,尤其是对女性而言。
而合成技术产生的“合成数据”也有着不小的商业价值。合成数据可以减少对生成和捕获数据的依赖,可以做到比手工标记数据更便宜、更快速,还可以最大限度减少公司对第三方数据源的需求等等。
“技术是一把双刃剑”,这句话已经被无数次的提起。目前尚不知道本文提到的合成技术研究团队未来会将这项技术用在哪里,这项技术暂时也还没有开源,不论今后它的命运如何,只希望不再有更多无辜的人受到影响,相信各个国家也会加快对这类层出不穷的新技术的立法管理,技术无罪,但是掌握技术的人应该守好底线。
参考链接:

InfoQ编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论