

2016 年,Facebook AI 研究所(FAIR)用Wav2Letter(全卷积语音识别系统)开辟了一个新领域。
在 Wav2Letter 中,FAIR 证明,基于卷积神经网络(CNNs)系统可以实现与传统的基于递归神经网络的方法一样的性能。
在本文中,我们将重点关注 Wav2Letter 核心中一个未充分利用的模块:自动分割(Auto Segmentation,简称 ASG)标准。
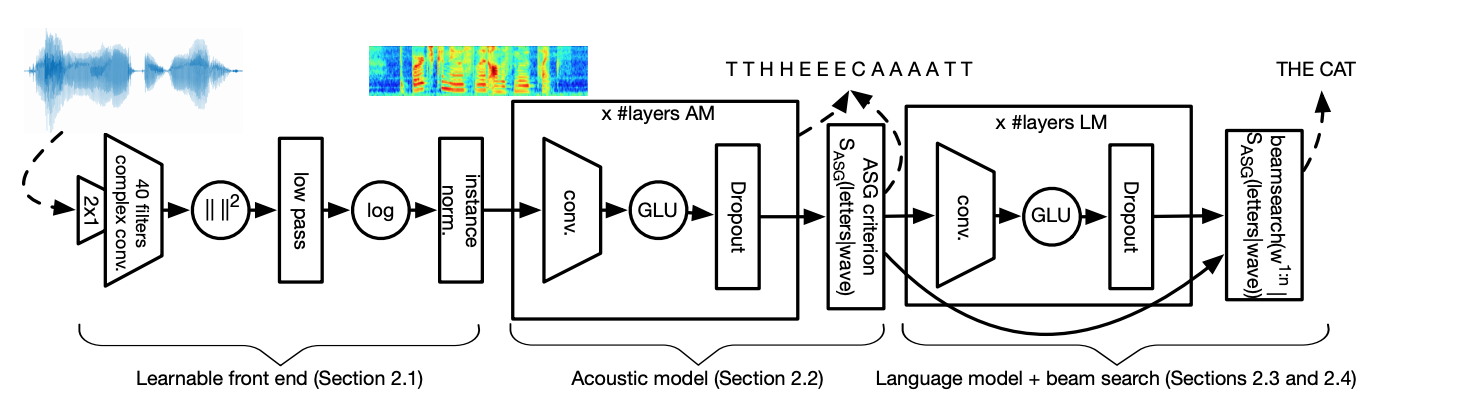
Wav2Letter 模型的架构
在如上所示的 Wav2Letter 架构中,我们可以在声学模型的右侧找到 ASG。
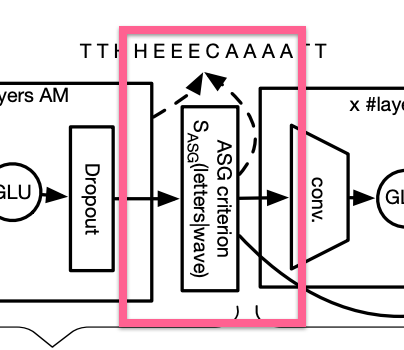
Wav2Letter 架构图中的 ASG
FAIR 报告说,利用具有 ASG 的卷积方法,在应用于TIMIT数据集时,字母错误率(Letter Error Rate,简称 LER)有显著的改善。
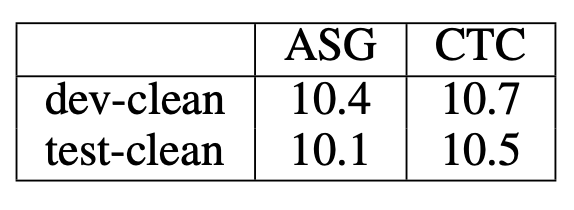
TIMIT 字母错误率
同样,尽管 Wav2Letter 仅使用了 CPU 版本的模型进行基准测试,但模型在短序列和长序列上的速度相较于 GPU 版本都有显著提高。
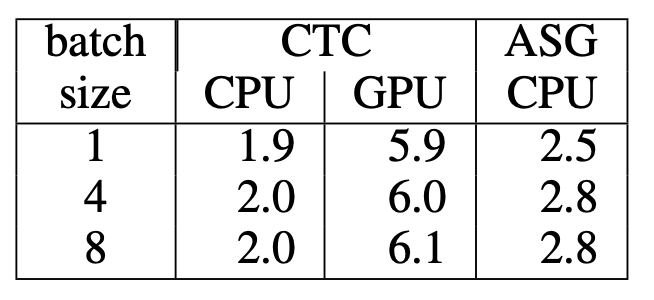
以 ms (毫秒)为单位的短序列时序
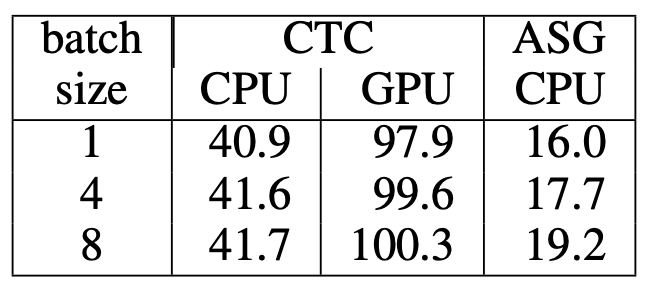
以 ms(毫秒)为单位的长序列时序
从根本上来说,ASG 标准是一种特殊类型的损失函数。
ASG 构建于更早的算法(如 Connectionist Temporal Classification,简称 CTC)之上,该算法长期以来是语音识别模型的主流。
为了理解 ASG,我们首先需要理解用像 CTC 这样的算法解决的具体问题。接着,我们简要介绍一下 CTC,以便我们最终了解 ASG 的不同之处,并在此基础上进行改进。
从声音到字母
Wav2Letter 的核心是个声学模型,就像我们也许已经猜到的那样,它可以预测声波中的字母。
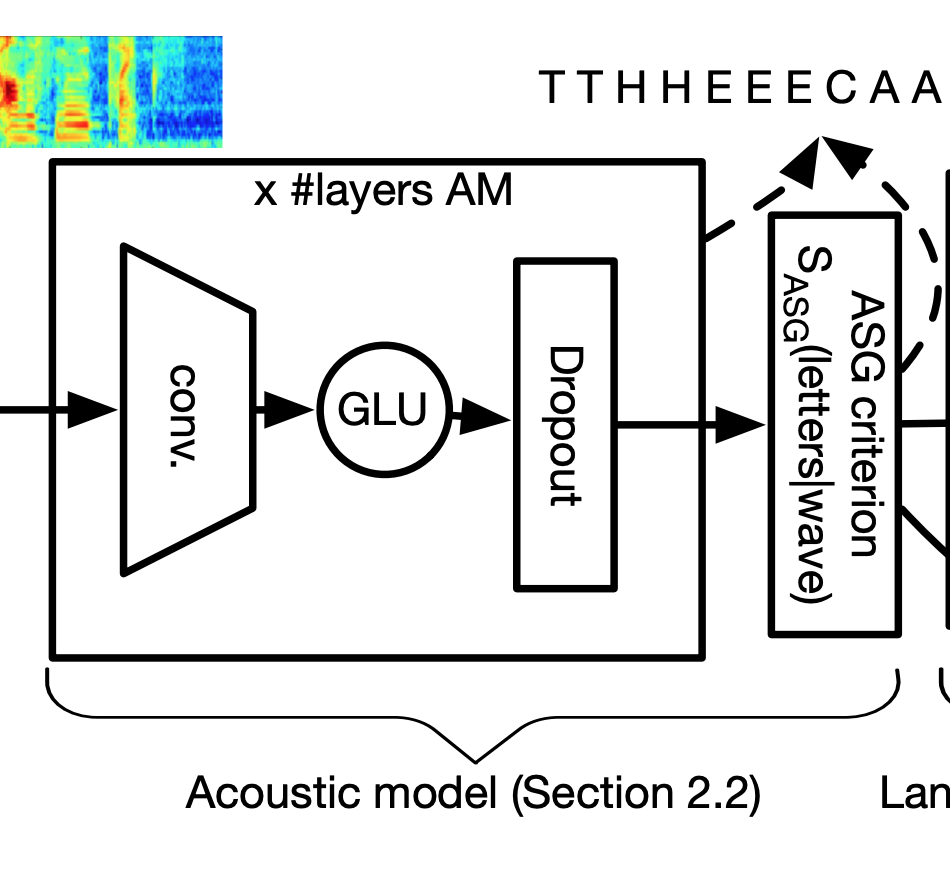
Wav2Letter 的声学模型
具体来说,Wav2Letter 把音频处理成片,通过各种卷积层传送它们,并为每个音频输出一组概率。每个概率集包含模型字符字典中每个字符的估计值。
这意味着,对于每个音频片,我们会估计那一刻说的是‘e’或是‘t’或是‘s’,还是任何其他可能的字母。
该声学模型形成由这些概率组成的链,链上的每个链环都代表在当时特定字母出现的估计值。
这条链包含我们声学模型的假设。为了得到最终预测,我们需要把这条概率链转换成整条音频切片中最有可能出现的字母序列。
对齐问题
请记住,Wav2Letter 的声学模型本质上是声波到字符的分类器。该模型“看”到一点声波的输入并说:“好,这个看起来像‘H’或可能是‘S’”。
但是,与静态图像不同,声波会随着时间流动。如果我们的短句是“THE CAT”,我们如何知道说话的人何时不再说“T”,而是说“H”呢?
为了学习“这就是‘T’的样子”,Wav2Letter 需要理解随着时间的推移,口语是如何在字母之间转换的。
只有理解了这些转换,该模型才可以开始将声音的表示映射到正确的字符标签。
但是,我们遇到了问题。用于语音识别的训练数据通常只有音频和书面文本,这两者之间没有对齐的数据。我们也许输入一个 3 秒钟长的.wav 文件,里面包含某个人说的“The Cat”和一个.txt 文件,里面包含这些字母:“The Cat”。我们知道,在“The”中,“T”在“H”之前出现,但是,文本没有告诉我们出现的时间。
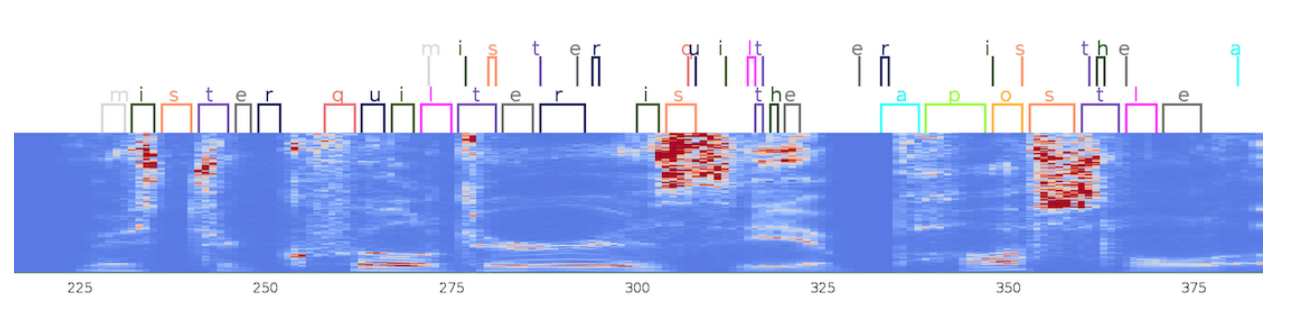
一个音频片中,来自 CTC(顶部)和 ASG(底部)的字母对齐示例
手动对齐每个字母来匹配音频中的时刻会很耗时,并且在大规模的时候几乎不可能做到。我们也不能依赖像“一个字母持续 500 毫秒”这样肤浅的一般规则,原因很简单,人们说话的速度不同。
那我们该怎么做呢?用 CTC。
CTC 如何解决对齐问题?
传统上,从业者用CTC算法解决了这种对齐数据的缺乏。
在本节中,我们将只涉及 CTC 最好的地方。这样,我们可以看到 ASG 和它的差异所在。关于这个问题,可以参考在Distill上更深入解释CTC的文章。
对应每个音频片,CTC 期望所有可能的字母都有一组概率。另外,至关重要的是,有一个特别的“空白”标签。
Wav2Letter 的声学模型把概率集的输出链输入到 CTC,CTC 用以找出最高概率输出。并且,它不需要任何计时数据就可以做到。
怎么做?
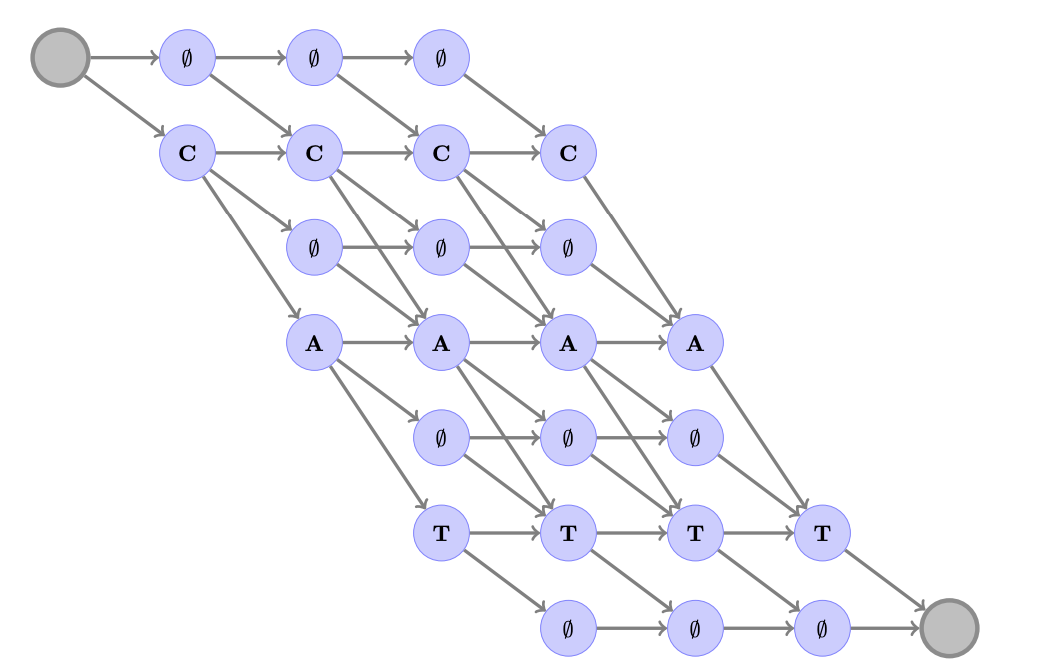
我们以单个音频文件的简化示例为例,其中说话人说的是“hello”。
正如我们所看到的,我们的输入是每个音频片上字母的概率集,是由我们的声学模型将音频转化而来。
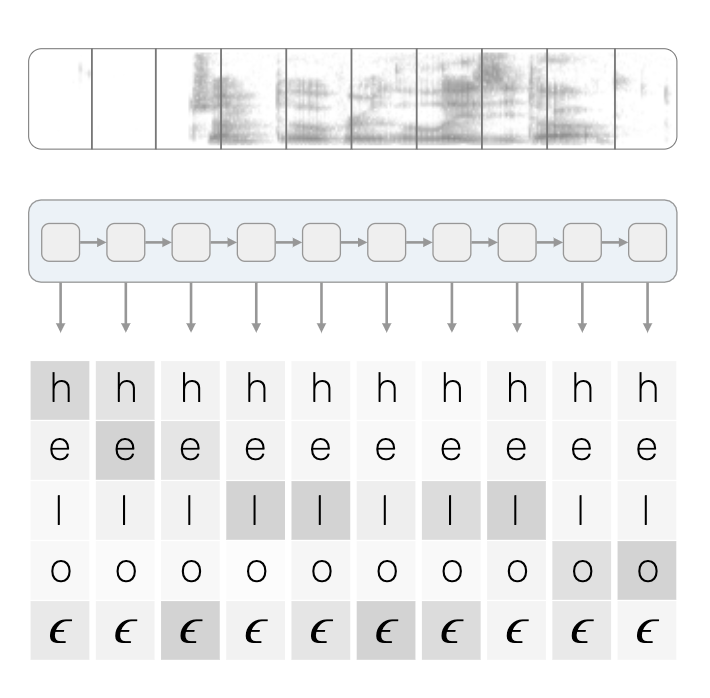
由声学模型生成的概率链
在这个例子中,我们想象我们的字典中只包含‘h’‘e’‘l’‘o’和之前提到的特别空白标签,这个标签有个正式的科学名称:波浪 e(squiggle e)。
每个时间片都有每个字母的估计值。较暗的单元代表该字母的概率更高。信不信由你,这就是我们用来推断声音和字母之间可能对齐的所需。
把这个字母网格想象成图。
CTC 逐列扫描每个可能的组合:
对于“cat“这个词,显示了每个有效 CTC 对齐的图
该图为我们提供了音频字母的每个可能对齐方式。(在实际操作中,CTC 使用动态编程技术,使该过程比听上去的更有效)。
CTC 对每个可能对齐的概率求和。一旦完成,CTC 显示最可能对齐的一段。
更正式的说法是,CTC 旨在通过该可能对齐的路线图让路径上的总分最大化。
对于我们的“hello”示例,下面是两个极有可能的对齐方式:
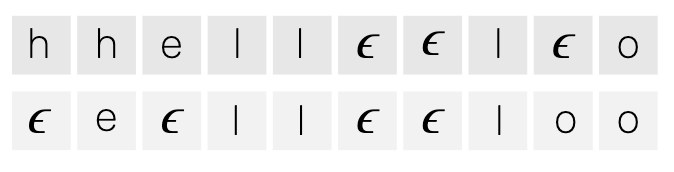
这些生成的对齐将从合理到荒谬排列。
请注意:我们的第 2 个对齐,尽管技术上有效,但它甚至没有包含一个“H”! 其他对齐方式也许是“HHHHHELLOO”或“HEELLLLLOO”,而不太可能的是“OOOOOOOOOO”和“LLLLLOOOOO”。
为了生成最终输出,CTC 删去了重复字母……
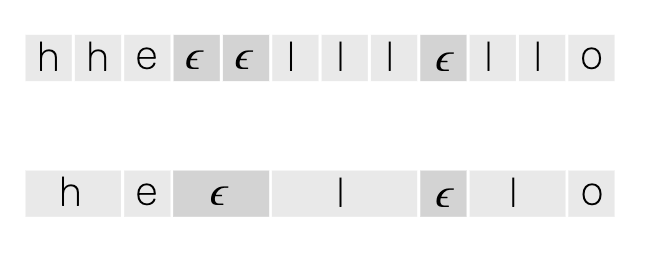
……并且删去了特别的空白标签,波浪 e。
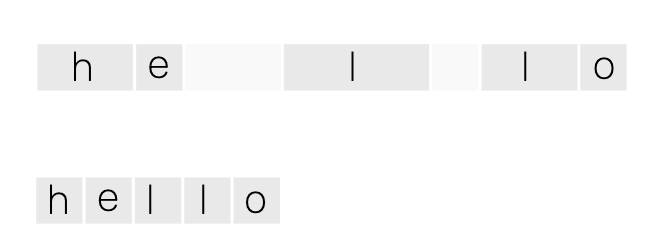
删去重复字母和波浪 e 之后,我们最终得到我们最高可能性的输出:“hello”。
该输出可以与我们音频的书面文本进行比较。我们可以根据我们文本的事实来计算我们模型的损失。好!
我们来回顾一下。
CTC 完成了两件重要的事情:
首先,通过扫描可能的对齐和链接高度可能单个字母的猜测,我们最终获得了该音频的一个有效的预测文本,而该音频没有任何一个对齐数据。
CTC 还可以处理音频中的变化。比如,当说话的人停留在字母“h”上时,CTC 在对齐中可以包含多次“h”。我们删除重复的字母,仍然可以得到“hello”。
其次,我们特殊的波浪 e 有两个作用,分别是垃圾帧(如在字母之间可能发生的静默或呼吸)的分隔符及重复字母的分隔符。
波浪 e 使得 CTC 模型可以处理无法识别出任何字母的噪声帧。此外,它允许模型生成像“hello”这样的词,即使“I”是个重复的字母,而 CTC 有着删除重复字母的机制。
好,那么, ASG 到底是什么?
自动分割标准(Auto Segmentation Criterion,简称 ASG)与 CTC 有这两个不同之处:
没有特别的空白标签(波浪 e)。
ASG 避免某种类型的规范化。
就是这样而已。
我们来看看这两点。
没有空白标签让事情变得更简单更快
在 Wav2Letter 中, FAIR 报道,实际上使用特殊的空白标签来处理字母之间音频的垃圾帧“没有优势”。
因此,ASG 删去了该标签。对于重复的字母,ASG 用“2”来表示,而不是用空白标签。在我们的示例中,“hello”将变成“hel2o”。
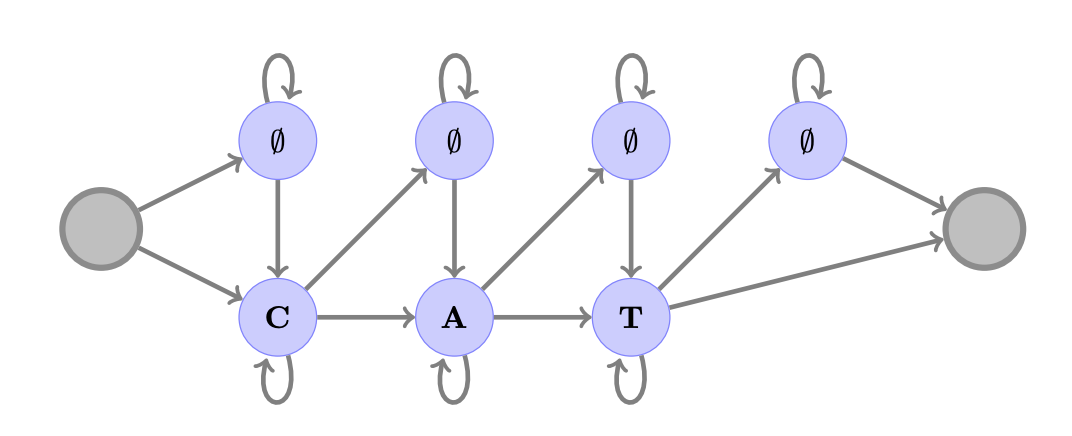
对于“CAT”,一个 CTC 图显示可接受的字母序列
对于“CAT”,一个 CTC 图显示可接受的字母序列。请注意,没有特别的标签来表示垃圾帧。
通过删除特别标签,ASG 大大简化了该算法在生成对齐时必须搜索的图。这可能是报告中的一些性能提升的原因。
ASG 允许声学模型来学习字母之间的关系
CTC 希望其输入在帧级别上规范化。对于用我们的声学模型创建的链上的每个概率集,每个字母的概率用该框架中的其他字母的概率来规范化。
对于 CTC 来说,每个帧都是其自己的小世界。重要的是要找出这些帧中字母到字母预测的最高总和。
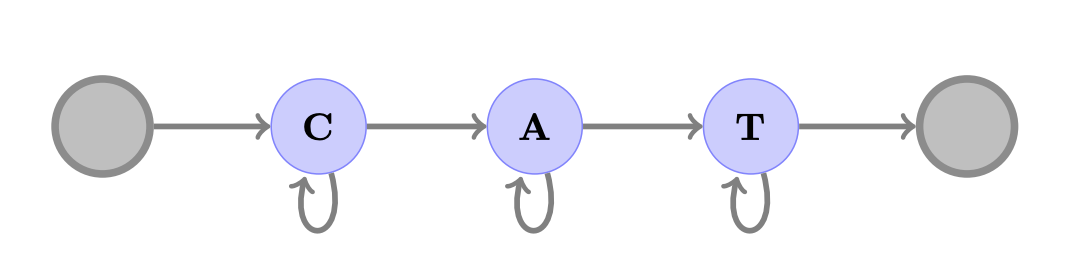
5 个帧中用于“CAT”所有有效对齐的 CTC 图。节点之间相互连接,但是线段没有表示给定连接的概率更大或更小。
出于各种技术原因,ASG 没有进行帧规范化。规范化的细节并没有那么重要:
ASG 给 Wav2Letter 的声学模型赋予了通常用于语言模型的能力:学习字母之间转换可能性的能力。
在实际的语言中,某些字母的组合比其他的更有可能。这些字母的特定组合可能性被称为“转换(transitions)”,可以提高模型的准确性。
有些转换明显比其他的更有可能。比如,在英语中,“TH”这个序列比“TS”更有可能(ts 仅出现在像“tsar”或“tsetse fly”这样晦涩的词中)。
ASG 拥有自己的权重矩阵,该矩阵为每个字母之间的可能转换建模。就像任何其他标准权重矩阵那样,这些权值是通过反向传播训练的。通过使用该矩阵,ASG 允许声学模型学习转换分数(一个字母跟随另一个字母的可能性),并把它们融合到我们用来生成字母到字母预测最可能的对齐图的边缘。
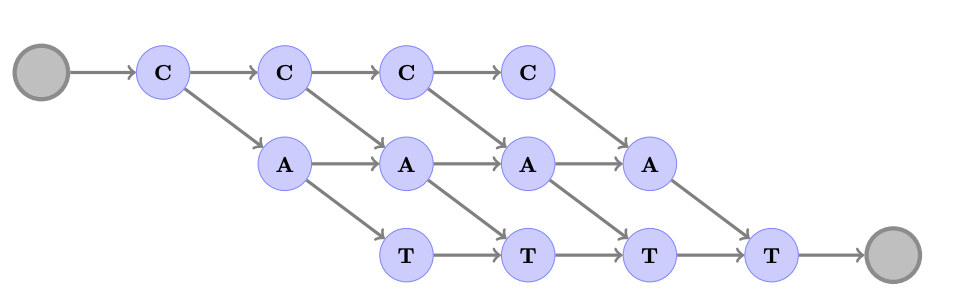
“CAT”的 ASG 图展开了 5 帧。图形节点之间的边缘(线)包含字母之间转换的学习分数。
因为该声学模型包含对字母序列的有用理解,所以,实际上,Wav2Letter 的解码器在为其最终文本打分时,使用的是来自声学模型和其真实语言模型输出的转换数据。
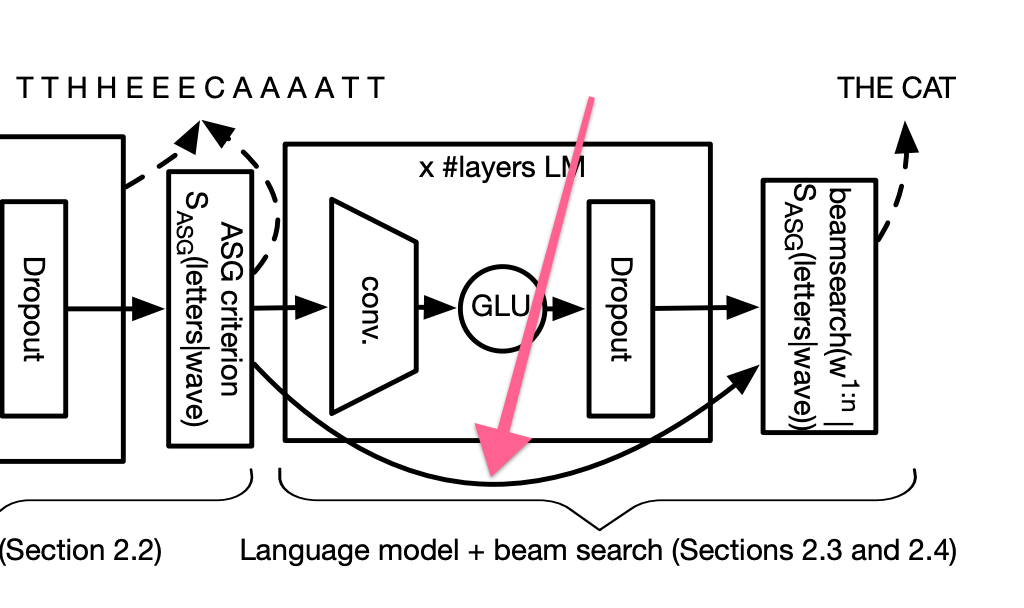
ASG 连接到 Wav2Letter 解码器中的集束搜索
结论
我们来做个总结。
像 Wav2Letter 这样的语音识别系统面临着一个恼人的问题:几乎没有关于声音和转录是如何及时对齐的信息。
但是,为了生成准确的逐字母预测,我们需要知道一个字母何时开始以及另一个字母何时结束。我们的声学模型学习的就是把声波和特定字母关联起来。
通常,深度学习实践者用一个称为 CTC 的算法来解决该问题。尽管在很多情况下,CTC 工作得很好,但是它包含一个额外的标签,提高了复杂性并可能降低速度。它还包括一个规范化形式,限制了声学模型可以学习的内容。
ASG 是一种特殊类型的损失函数,其通过删除 CTC 额外的标签及允许该声学模型使用自身的权重矩阵来学习字母之间的转换来改进 CTC。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论