
背景
飞书多维表格是一款功能强大的在线数据管理与协作工具。它打破传统表格局限,将电子表格与数据库特性融合,支持看板、甘特图、表单等多种视图自由切换,可根据项目进度、任务管理等不同场景灵活展示数据。其丰富的字段类型能精准适配各类数据录入需求,且支持多人实时在线协作,团队成员可同步编辑、快速沟通。通过自动化流程与 “AI 捷径字段” 等功能,可轻松实现数据的自动计算、任务提醒、智能分析等操作,无论是项目管理、客户关系维护,还是日常工作流程优化,都能高效满足个性化业务需求。
AI 捷径字段是一个飞书的开放平台,使用者可以根据自身业务需求开发自定义插件,也可以将插件推送到 “捷径字段中心” 对外提供服务。目前,在 “捷径字段中心” 里已经有丰富的第三方应用插件,可以满足许多通用业务场景。“AI 捷径字段” 提供了详细的开发文档,让企业可以开发有定制化逻辑的内部插件,例如:在插件的实现逻辑中调用企业内部服务 API、与企业的 AI 能力进行集成。
本文将利用 AI 捷径字段的开放能力,实现飞书多维表格与 Amazon Bedrock 的集成,并演示 AI 赋能业务的典型场景。
方案
方案介绍
基本概念
飞书 AI 捷径字段:是飞书多维表格中的一项功能,它允许用户通过简单的配置,借助 AI 自动生成所需的字段,从而大大提高工作效率,用户无需了解复杂的底层逻辑和细节,只需新增一列,进行简单配置,就能借助 AI 完成高阶工作。
飞书低代码平台 FaaS(Function as a Service,函数即服务):开发者能使用编程语言编写函数代码,专注于实现特定业务逻辑。完成编写后,可便捷地将函数部署到飞书低代码平台环境中,无需操心服务器配置、安装和维护等底层工作。
Amazon Bedrock:是一项完全托管的服务,通过单个 API 提供来自领先人工智能公司的高性能基础模型,并提供通过安全性、隐私性和负责任的人工智能构建生成式人工智能应用程序所需的一系列广泛功能。使用 Amazon Bedrock,您可以轻松试验和评估适合您的使用案例的热门基础模型,通过微调和检索增强生成(RAG)等技术利用您的数据对其进行私人定制,并构建使用您的企业系统和数据来源执行任务的代理。
数据交互流程
数据流程分为三个阶段:1)多维表格前端,2)捷径服务端,3)Amazon Bedrock 服务器。业务逻辑和与 Amazon Bedrock 交互的代码封装在 FaaS 中,部署在捷径服务端。前端交互是多维表格文档,要处理的数据通过固定格式的表单与捷径服务端进行交互,然后再将接收到的用户数据和参数通过 Bedrock API 进行处理。需要注意的是在插件中访问的互联网资源需要申请域名白名单,向不在白名单内的域名发送的请求会被拒绝。
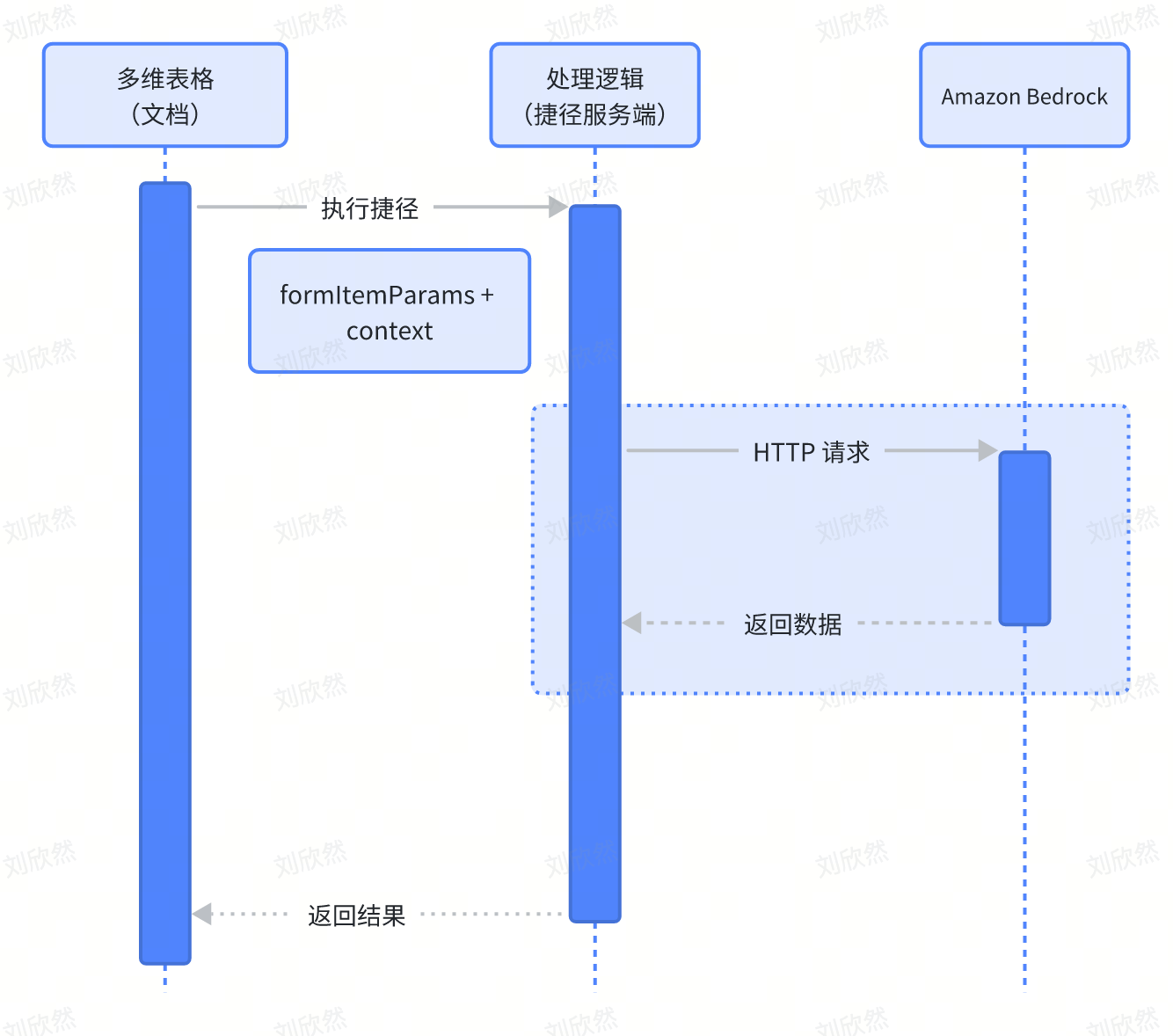
开发流程
运行环境:Nodejs 版本:14.16.0
克隆项目:
git clone https://github.com/Lark-Base-Team/field-demo.git项目目录结构:
├── config.json // 本地调试授权的配置文件├── package-lock.json├── package.json├── src│ └── index.ts // 项目入口文件└── tsconfig.json启动本地服务,可以在模拟环境中进行调试:
# 安装依赖npm install# 启动本地服务npm run start集成 Bedrock 代码示例 index.ts:
// 定义捷径的入参 formItems: [ { key: 'prompt', label: t('prompt'), component: FieldComponent.Input, props: { placeholder: t('prompt_placeholder') }, validator: { required: true, } }, { key: 'bedrockEndpoint', label: t('endpoint'), component: FieldComponent.Input, props: { placeholder: t('endpoint_placeholder') }, validator: { required: true, } }, { key: 'accessKey', label: t('accessKey'), component: FieldComponent.Input, props: { placeholder: t('accessKey_placeholder'), }, validator: { required: true, } }, { key: 'secretKey', label: t('secretKey'), component: FieldComponent.Input, props: { placeholder: t('secretKey_placeholder'), }, validator: { required: true, } }, { key: 'modelType', label: t('modelType'), component: FieldComponent.SingleSelect, props: { placeholder: t('modelType_placeholder'), options: [ { label: 'Amazon Nova Pro', value: 'amazon.nova-pro-v1:0' }, { label: 'Amazon Nova Lite', value: 'amazon.nova-lite-v1:0' }, { label: 'Amazon Nova Micro', value: 'amazon.nova-micro-v1:0' }, { label: 'DeepSeek R1', value: 'deepseek.r1-v1:0' } ] }, validator: { required: true, } } ], // 定义捷径的返回结果类型 resultType: { type: FieldType.Text, }, // formItemParams 为运行时传入的字段参数,对应字段配置里的 formItems (如引用的依赖字段) execute: async (formItemParams , context) => { const { prompt, modelType, bedrockEndpoint, accessKey, secretKey } = formItemParams; /** 为方便查看日志,使用此方法替代console.log */ function debugLog(arg: any) { console.log(JSON.stringify({ formItemParams, context, arg })) } // 创建 Bedrock Runtime 客户端 const client = new BedrockRuntimeClient({ endpoint: bedrockEndpoint, // 设置你的 Amazon Bedrock endpoint credentials: { accessKeyId: accessKey, secretAccessKey: secretKey, } }); const message = { content: [{ text: prompt }], role: ConversationRole.USER, }; const request = { modelId: modelType.value, messages: [message], inferenceConfig: { maxTokens: 1000, // The maximum response length temperature: 0.7, // Using temperature for randomness control }, }; try { const response = await client.send(new ConverseCommand(request)); console.log(response.output.message.content[0].text); const generatedText = response.output.message.content[0].text; return { code: FieldCode.Success, data: generatedText }; } catch (error) { console.error('调用 Amazon Bedrock API 时出错:', error); return { code: FieldCode.Error, errorMessage: '调用 Amazon Bedrock API 时出错' }; } },发布流程
在项目目录下执行 npm run pack,然后将 output/output.zip 文件上传即可。然后提交多维表格捷径插件表单,可发布给所有用户,或公司内使用。具体开发和发布流程可以参考“字段捷径插件开发指南”。
典型场景
使用 Amazon Nova Pro 识别多维表格中的图片,帮助业务人员快速完成业务分析,加速决策流程
本案例展示多维表格与自定义字段捷径的交互方式,利用 Amazon Nova Pro 在图像内容识别场景中的优势,帮助业务人员无门槛使用 AI 应用工具并提高工作效率。
创建一个全新的飞书多维表格文档,将我们之前准备好的原始图片以附件的形式上传到多维表格内指定列(原始图片列)中。再新增一列,字段类型选择 “字段捷径中心”,然后在 “字段捷径中心” 搜索并使用我们自己之前发布的插件,‘待处理字段’使用我们放置图片的列,‘处理命令’就是大模型 Prompt。
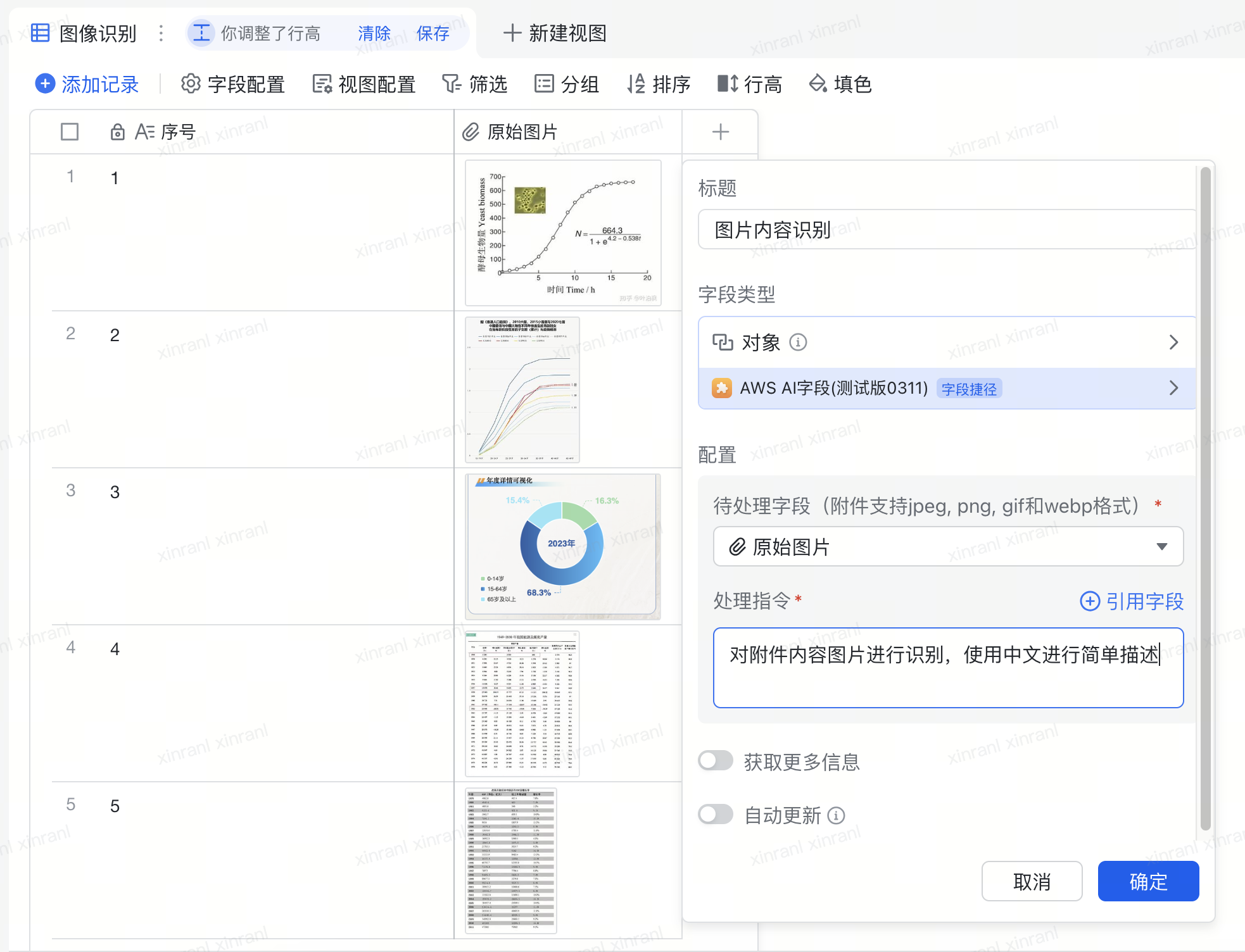
配置完成后,多维表格自动调用指定的字段捷径,并将 “原始图片” 列的数据作为参数传递给插件。我们使用的是异步调用,插件会将图片发送到后端的 Amazon Bedrock 服务中,调用 Amazon Nova Pro,根据 Prompt 进行图片分析,并将结果输出到 “图像识别” 列中。多维表格可以支持自动更新,不论你新增图片,还是在原有行中更新图片,多维表格都会调用插件更新输出内容。
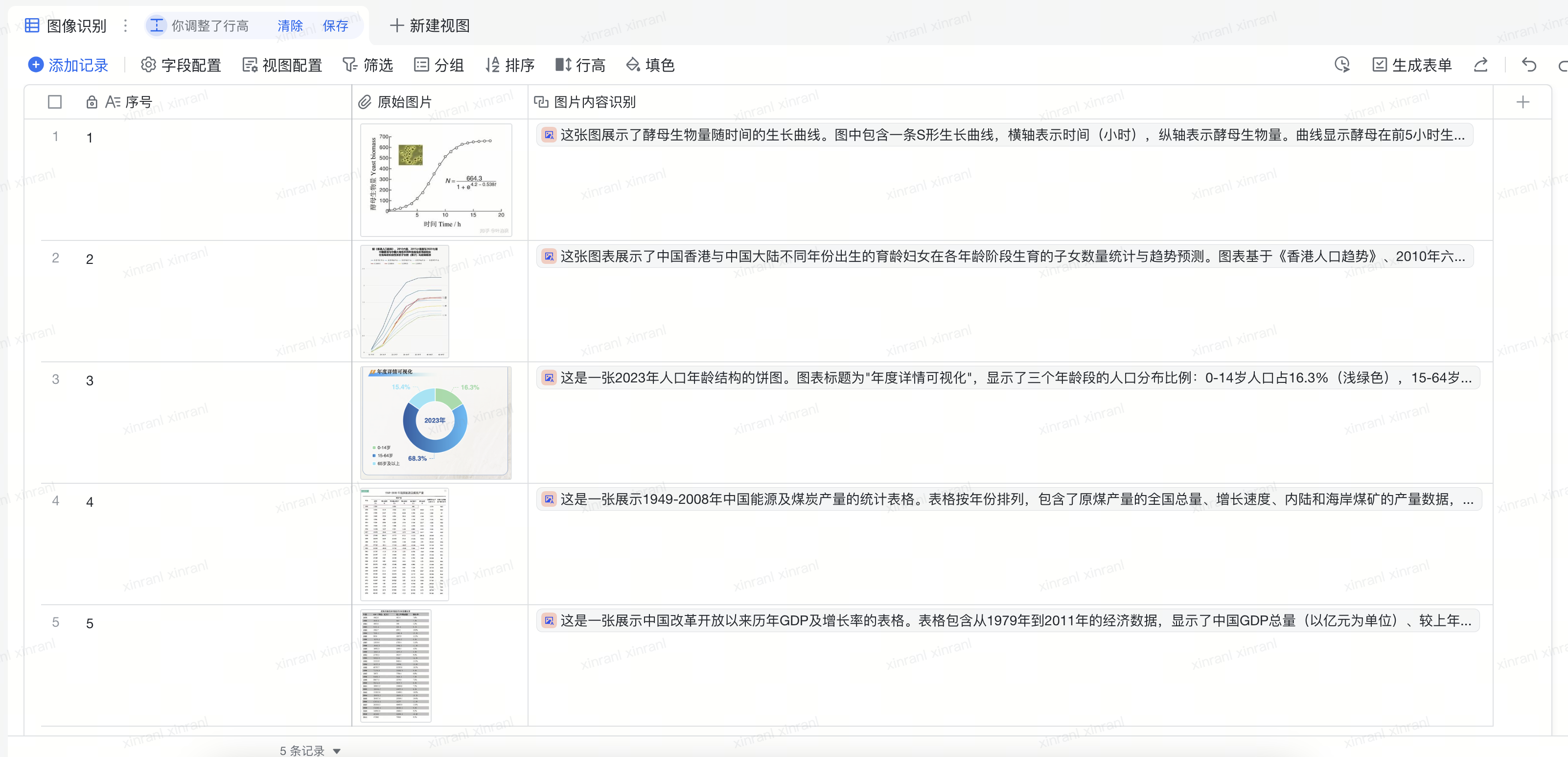
结论
飞书多维表格已经内置了很多基础工具,可以满足用户常见的业务需求。但面对用户的个性化场景,就需要利用 “捷径字段” 这个开放平台,开发符合自己业务需求的工具。随着 AI 能力的越来越成熟,很多业务场景都可以借助 AI 提高工作效率。本案例就是将飞书多维表格与 Amazon Bedrock 进行集成,让 AI 赋能业务。用户不仅可以开发企业内部自己使用的工具,也可以将工具发布到 “字段捷径中心” 对外提供服务,拓展企业的 ToB 业务渠道。




