

端到端机器学习是一种由输入端的数据直接得到输出端结果的 AI 系统,它可以对业务人员屏蔽复杂技术细节,同时给模型以更多自动调节空间,增加模型整体契合度。近两年来,端到端机器学习成为 AI 领域研发热点,蚂蚁集团于 2019 年 5 月发布端到端 AI 系统 SQLFlow 开源项目,受到业界广泛关注。今天,就让我们来看看它对端到端 AI 的思考与解答。
SQLFlow 是蚂蚁集团开源的使用 SQL 完成 AI 工作流构建的编译系统。SQLFlow 将多种数据库系统(MySQL, Hive, MaxCompute)和多种机器学习引擎(Tensorflow, Keras, XGBoost)连接起来,将 SQL 程序编译成可以分布式执行的工作流,完成从数据的抽取,预处理,模型训练,评估,预测,模型解释,运筹规划等工作流的构建。
接下来我们会根据以下内容逐步介绍 SQLFlow:
为什么要使用 SQL 语言描述端到端 AI 任务;
使用 SQLFlow SQL 语句构建 AI 任务;
使用 SQL 程序构建端到端 AI 工作流;
使用 SQLFlow Model Zoo 沉淀模型;
应用 SQLFlow 的场景案例;
为什么要使用 SQL 语言描述端到端 AI 任务
首先,思考一个问题,人工智能和金融有哪些耳熟能详的结合呢?
在智能征信风控方向,可以运用大数据进行机器学习,刻画用户画像,抽取个性化典型特征,推进反欺诈评估、用户征信评估。
用到的技术: 聚类 (将有相似特征的群体聚类,确定人群标签)、 分类 (学习已有分类标签的用户特征,识别新用户所属的类型、标签)、 模型解释
在智能投资顾问方向,我们以人工智能算法为基础,为客户提供自动化投资管理解决方案,包括提供投资资讯、构建投资组合、直接投资管理等服务。
用到的技术: 时序模型 、 回归 、 运筹规划
智能营销方向,上世纪 90 年代沃尔玛超市将「啤酒」与「尿布」摆在同一区域的做法,大大增加了商品销售收入,成为借助数据分析实现智能营销的经典案例。而今天,在人工智能等新技术的加持下,数据分析技术正在不断进化,千人千面的智能营销已有广泛的应用。
用到的技术: 推荐算法 、 Ranking 、 CTR 、 运筹规划
然而,构建传统的机器学习工作流程,需要经历非常多的步骤并使用复杂的技术栈:
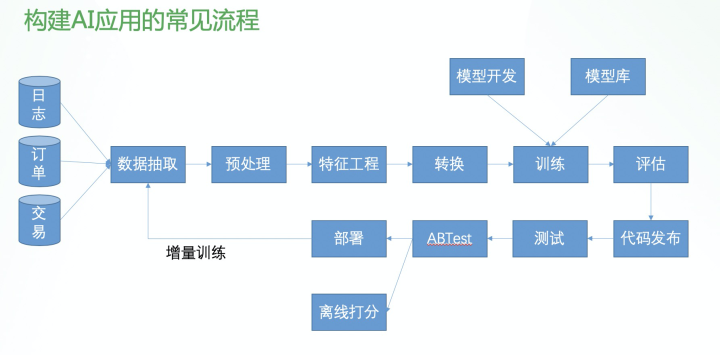
构建完整的 AI 应用,首先需要获取用于构建模型的数据,这些数据通常可以从日志、订单数据、交易记录等获得。之后通过数据抽取,将其中我们需要用到的部分信息,从多个存储位置抽取出来。抽取数据之后需要进行数据预处理,比如去掉错误的数据,填充缺失的数据,整理,排序等。预处理完成之后,我们需要从这部分数据中得到用于训练模型的特征,比如提取时间序列的周期性特征,获取交叉特征等,最后将构建的特征转换成训练框架可以接收的数据格式,才能开始训练。
另外,在开始训练之前,我们还需要确定使用哪个模型,XGBoost 模型还是深度学习模型,哪个模型更适合当前的场景?模型可以从现有模型库中获取并根据需要修改,或者从头编写新的模型使用。另外在构建机器学习模型时,我们需要不断的评估模型的表现如何,以获得最优的模型,这时就要使用各种评价指标描述训练好的模型。当模型评估结果验证达标之后,就需要将模型代码发布一个新的版本,部署到线上环境。发布之前还要通过线下测试,小流量 ABTest,然后推全部署。如果是离线任务则需要更新定时任务使用新的模型代码。
当模型的时效性比较强的时候,我们还需要不断的使用新的数据更新模型,就是“增量训练“,这样每次增量训练就不得不再次从头走一次完整的流程。
要完成这一整套流程,需要用到复杂的技术栈。
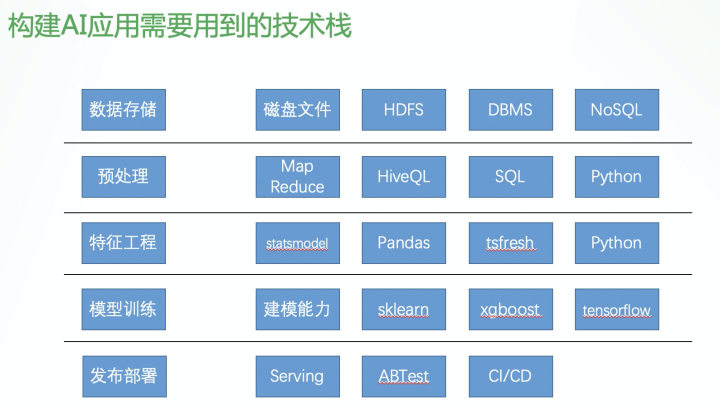
我们需要的数据可能存储在磁盘,或者像 HDFS 这样的分布式文件系统,或者可以从结构化的数据库系统中获得,或者是 NoSQL 引擎(比如 mongodb)存储的数据;在预处理阶段,有可能需要编写 MapReduce Job 来处理 HDFS 上的大量的数据,或者使用 Hive 编写 SQL 语句完成处理,亦或直接编写 Python 代码处理数据;在特征工程阶段,又需要使用类似 statsmodels, tsfresh 或者编写 Python 程序使用诸如 Pandas 之类的库完成预处理;在模型训练阶段,算法工程师首先需要掌握各种建模的能力,算法原理和基础知识,也需要熟练使用各种机器学习引擎如 sklearn, XGBoost, Tensorflow, Pytorch 等;最后在上线部署阶段,还需要了解模型如何接入 Serving 系统,怎么样做 ABTest,怎么编写 CI/CD 任务保证模型上线不影响线上业务。
构建 AI 应用,不仅需要冗长的链路和复杂的技术,从业务需求到 AI 系统上线也需要特别长的沟通链路。

比如业务同学和产品同学在构建产品思路的时候,在他的脑海中的 AI 系统需要完成的任务,传达给开发同学之后,有可能传达不到位,需要反复的沟通。有时甚至做了一半还需要重做。
另外从需求到上线,为了保证线上服务和数据产出的稳定,也需要通过许多的步骤。比如业务同学说:「活动要上线了,时间点很关键,明天必须发布!」开发同学接到需求,加班加点,开发验证完成之后,模型准确率提升 10 个点,准备发布模型。SRE 同学则会把控上线之前的各项准备,包括预发测试是否通过,压力测试是否通过,CPU 负载是否有提升,硬件资源是否能承载新的模型,模型预测延迟是否提升了等……完成流程也需要很长时间。然而如果没有 SRE 的把关,线上的服务很难保证稳定性。
使用 SQL 作为描述和构建 AI 任务的语言,可以降低构建 AI 应用的门槛,提升效率。
首先需要区分编程语言主要的两种描述方法:描述意图和描述过程。简而言之,描述意图是在描述「做什么」,描述过程是描述「怎么做」。比如,夏天大家有空喜欢吃点烧烤喝点啤酒,描述意图的方式,说「我想去撸串」这一句就够了。而描述过程,就需要说「我今天晚上下班后,叫上老王小李,去公司楼下的烧烤店,点 100 个串和 10 个啤酒,最后用支付宝扫码付款」。可以看到描述意图可以非常简洁,而具体的执行方案,可以根据意图中构建得出。这点也是 SQL 不同于其他语言的关键点。
在描述模型训练任务时,使用 SQLFlow SQL 只需要编写 SELECT * FROM iris.train TO TRAIN DNNClassifier LABEL class INTO my_dnn_model; 即可,如果使用 Python 完成相同的任务则需要编写如下图这样的较长的代码。

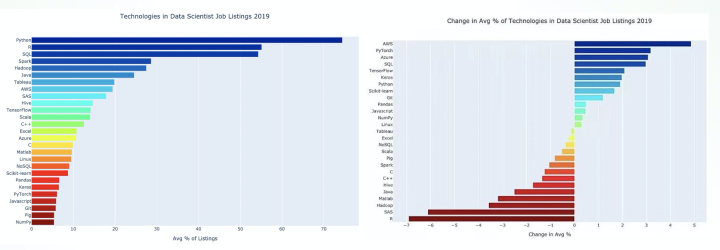
SQL 语言除了有非常简洁的优势之外,在数据科学领域,SQL 语言的已有用户量大,并且在不断的增加。这里也有两个统计图,统计了数据科学类任务所使用的工具的流行程度和增长趋势。SQL 语言流行程度排名第三,增量排在第四名。数据科学领域正在更多的使用 SQL 是我们希望使用 SQL 语言描述 AI 任务的原因。除了在表达能力上 SQL 语言有非常简洁的优势之外,在蚂蚁内 MaxCompute 被广泛使用也是我们选择 SQL 的一个原因。
如何使用 SQLFlow SQL 语句构建 AI 任务
SQLFlow 是一个开源项目,您可以在任意环境部署 SQLFlow。SQLFlow 提供了两种用户界面:基于 Jupyter Notebook 的 Web 图形界面和命令行工具。在 Jupyter Notebook 中,输入的 SQL 语句会发送到 SQLFlow server 完成编译和执行。
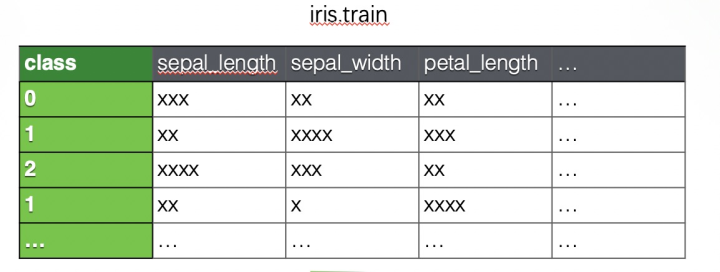
对于模型训练任务,SQLFlow 拓展了标准 SQL 语法,增加了 TO TRAIN 从句来描述模型训练。我们以 iris(鸢尾花)数据集为例,训练数据格式如下图:
训练的 SQL 语句是:
其中 SELECT * FROM iris.train 部分使用一个标准的 SQL 语句,获取模型训练的数据,这个 SQL 语句可以是任意的 SELECT 语句,比如包含嵌套、JOIN 等操作也是支持的。第二行 TO TRAIN DNNClassifier 指定训练的模型是 DNNClassifier,DNN 分类器。第三行 WITH 语句指定了模型训练需要的一些参数。LABEL class 指定使用数据库中的 class 列作为训练标签,INTO my_dnn_model 指定训练好的模型保存的名字。运行这条 SQL 语句,SQLFlow 会开始模型的训练,并保存一个叫做 my_dnn_model 的模型用于预测,评估、解释等。
然后我们可以使用下面的这段 SQL 进行模型评估:
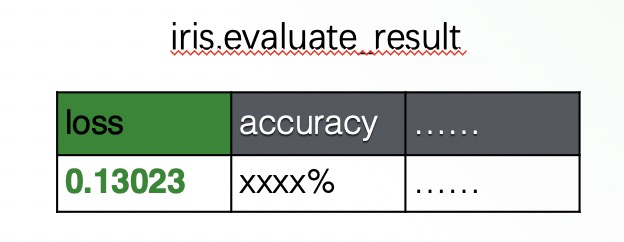
其中, SELECT * FROM iris.test 指定使用另一个表 iris.test 作为验证集,TO EVALUATE my_dnn_model 指定要评估的模型是我们刚才训练的 my_dnn_model,LABEL class 指定评估数据集中的标签列为 class,INTO iris.evaluate_result 指定评估指标的输出表。模型评估任务执行完成之后,就会输出如下图这样的评估指标的表。您也可以在 SQL 语句中使用 WITH 指定要输出的指标,就会作为结果表的一列数据输出。
在模型训练完成之后,我们可以使用下面的 SQL 语句进行预测:
我们使用的预测表 iris.pred 的 class 列是空的,是希望输出的结果。SQL 语句中 TO PREDICT iris.pred_result.class 指定预测结果输出到表 iris.pred_result 的 class 列。USING my_dnn_model 指定使用之前训练的 my_dnn_model 这个模型来预测新的数据,这样 SQLFlow 将预测的结果输出到表:iris.pred_result 的 class 列。
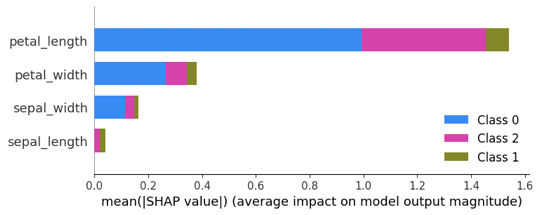
有时,我们希望进一步地了解模型,模型究竟是怎么通过输入得到输出,就需要「解释」训练好的模型,看到底哪些输入会如何影响模型的输出。SQLFlow 深度集成了 SHAP 和 Tensorflow 的模型解释功能,只需要编写如下的 SQL 语句:
在使用 Jupyter Notebook 的情况下可以输出下面的模型解释结果的图。从图中可以看到,输入数据中的特征 petal_length 对模型判断鸢尾花的类别起到至关重要的帮助。
SQLFlow 目前提供了充足的常用模型库,使得我们可以快速使用 SQL 语句实验、验证最终构建 AI Pipeline。目前已经支持的模型包括深度学习常用的网络包括 DNN, RNN, LSTM 的分类、回归,基于 XGBoost 的树模型的分类回归以及 Deep Embedding Clustring,kmeans 聚类模型,还有常见的金融行业模型包括评分卡模型,ARIMA, STL 时间序列模型等。
使用 SQL 程序构建端到端 AI 工作流
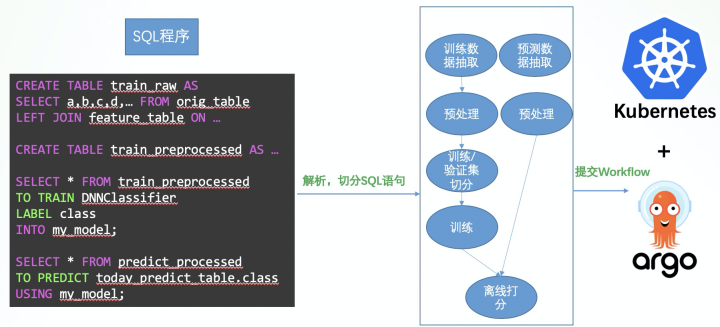
SQLFlow 不仅可以使用 SQL 语句完成 AI 应用中的模型训练、评估、预测、解释等单个任务,还可以将一整个 SQL 程序(包含许多 SQL 语句的一个 SQL 程序)编译成为一个完整的工作流任务执行。在之前列出的「构建 AI 应用的常见流程」中,SQLFlow 已经支持和计划支持的步骤标注在了图中。
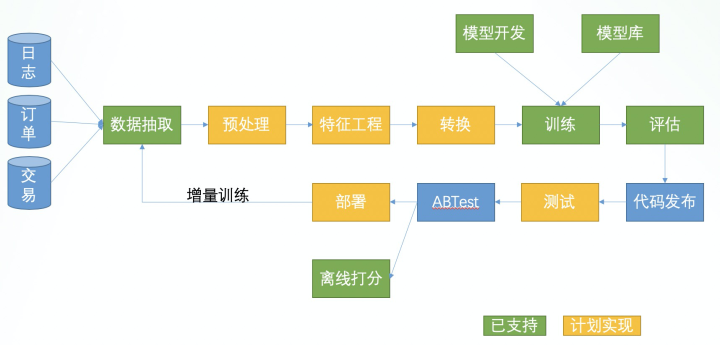
其中绿色标注的是目前 SQLFlow 已经支持的。SQLFlow 可以支持多种 SQL 引擎的方言,包括 MySQL, Hive, MaxCompute,并在逐步扩展。不论 SQLFlow 对接的是哪种数据库引擎,只要是当前对接的数据库支持的 SQL 语句,都可以被 SQLFlow 识别并发送至对应引擎执行,以此来支持使用 SQL 语言完成的数据抽取、预处理的工作。SQLFlow 还计划使用 TO RUN 关键字来拓展自定义数据预处理、特征工程的能力。SQLFlow 在训练时可以支持可选的 COLUMN 从句,将支持多种常见的数据转换的操作,比如归一化、随机化、Embedding、分桶等。另外,SQLFlow 也计划支持可以直接将训练好的模型部署到在线 Serving 的系统。
这样,我们可以编写一大段 SQL 语句,完全交给 SQLFlow 编译和执行。包括使用 JOIN 操作的 SQL 语句,从各个表抽取需要的数据,使用标准 SQL 完成预处理或者使用自定义函数完成预处理,最后开始训练和预测的 SQL 语句。
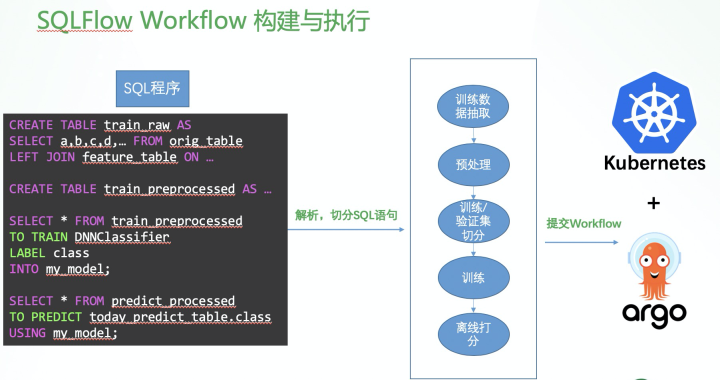
对于这样的一个包含许多语句的 SQL 程序,SQLFlow 会将其解析,编译成一个可以在 Kubernetes + Argo 集群上运行的 workflow。workflow 中每一个步骤(step)可以是执行标准的 SQL,也可以是执行分布式模型训练或预测任务。这个 Workflow 会被提交到 Kubernetes 集群上,交由 Argo Workflow Engine 调度执行。这个 workflow 的执行结果会从 Kubernetes 集群返回到用户。
通常情况,使用 SQL 语句编写的一个 SQL 程序,会被编译成一个顺序的 workflow,step by step 地执行。但有些 SQL 语句的 step 不是相互依赖的,可以并发地执行。如果我们使用如 Hive 这样的引擎,同时提交两个 SQL 语句,其实是可以生成 2 个 Map-Reduce 任务并发的在集群上执行的。SQLFlow 会自动的分析 SQL 程序中的 SQL 语句之间的依赖关系,并尽量的增大 SQL 程序的并发度,生成一个具有依赖关系 workflow 执行,最大限度的利用集群资源,降低整段 SQL 程序的执行时间。这个功能,省去了很多传统平台上,用户需要手动的构建任务和任务之间依赖关系的工作,因为所有的任务都可以用 SQL 语言描述,计算的依赖图自然可以自动生成。
使用 SQLFlow Model Zoo 沉淀模型
在构建 AI 应用时,另一个关键的任务就是需要编写模型定义的代码。SQLFlow 社区提供了 Model Zoo 框架,方便模型开发的同学不断的沉淀应用场景为通用的模型,并贡献到私有或公有的模型库,减少业务和开发之间的沟通成本。
SQLFlow 为快速构建 AI 任务提供了足够的模型弹药库。使用 ModelZoo 框架,算法开发可以将模型贡献成公开的模型,让更多的 SQLFlow 用户享受便利,也可以定向地分享给部分用户,保证模型的安全使用不泄密。基于模型库,业务同学可以直接使用 SQL 语句引用模型库中的模型,探索业务应用,发布业务应用;算法同学可以更加专注于提升模型效果、开发、更新模型的工作上面。这样不仅可以减少沟通成本,也可以提升工作成果的复用能力。
另外,Model Zoo 平台的代码也是完全开源的。用户完全可以在公司内部搭建自己的 Model Zoo 并且只在公司内分享模型。同时,用户可以连接到公开 Model Zoo 获取或者贡献新的模型。这样不便于对外公布的,和业务场景强绑定的一些模型,就可以在公司内逐步沉淀,构建公司自己的核心算法库。
应用 SQLFlow 的场景案例
下面,我们结合一些蚂蚁的实际场景,解释 SQLFlow 在实际业务应用中的使用方法。
第一个例子是资金流入流出预测。我们这里展示的是使用天池的公开数据集,其实蚂蚁内部的业务也在使用相同的方法。这个数据集包含了资金的申购,赎回在一段时间内的详情(脱敏),我们需要预测未来时间内资金申购、赎回的量。
在示例 SQL 语句中,我们使用了模型 sqlflow_models.ARIMAWithSTLDecomposition 应对此类场景。ARIMAWithSTLDecomposition 模型在金融领域有较为广泛的应用,该模型将输入的时间序列数据自动的提取不同时间窗口的周期性特征构建模可以获得比较好的结果。另外,SQLFlow 也提供了基于 LSTM 的深度学习模型用于训练时间序列模型,可以参考教程:
WITH 中指定了一些模型的参数配置,这些可以参考模型定义中的参数解释:
因为此数据集数据量不大,这个训练任务可以在一台机器上完成训练。此模型训练之后可以达到 MAPE 5% 的表现。
第二个例子是较为复杂的场景,使用 SQLFlow 构建点击率预估模型。我们以 kaggle 的一个开源数据集 (https://www.kaggle.com/c/criteo-display-ad-challenge/data) 为例,蚂蚁在类似的场景中,也会使用同样的方法构建模型。这个数据集中,列 l1~l13 是脱敏之后的连续值特征,c1~c26 列是离散类别特征,离散类别特征存储为 hash string。
我们可以使用以上的 SQL 语句描述训练一个「Deep and Wide」模型,将 l1~l13 列作为模型的线性部分的输入,将 c1~c26 特征作为模型的 DNN 部分输入。其中 COLUMN 语句分别可以使用正则表达式指定哪些些列作为模型哪部分的输入。我们将离散特征通过 HASH 分桶,然后增加 embedding 层的方法,将原始字符串特征输入传递给模型。注意这条 SQL 语句同时也可以包含部分预处理功能,使用 COALESCE 函数填充 l1~l13 列中的缺失值。
在蚂蚁点击率预估实际任务中,我们通常会有很多的预处理 SQL 语句,获得这张训练数据表,然后将训练数据再切分成训练集和验证集,再使用 SQLFlow 进行训练。这些步骤在蚂蚁都是使用 MaxCompute 的 SQL 语句编写的。所以整个点击率预估应用,从预处理到训练只需要编写一段 SQL 语句即可。不同于其他图形化平台,SQL 程序也可以存入代码仓库,方便 code review。
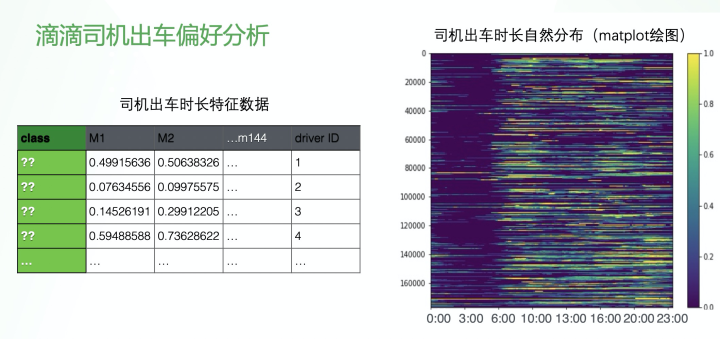
最后一个例子是 SQLFlow 的重要贡献者滴滴在去年云栖大会分享的一个应用:滴滴司机出车偏好分析。探索出不同类别的司机,可以为后续策略投放和管理提供信息。左侧数据表中为每个司机的每天的出车时长数据,每一列表示 10 分钟,一天有 144 个 10 分钟,就是 144 个数据点,每个点是在这 10 分钟内司机出车的时间比例。这样我们就可以在 JupyterNotebook 使用 matplot 得到如下图的这样的可视化展示,这张图里明显看不出来任何规律。
然后我们使用 DeepEmbeddingClusterModel 来进行聚类分析,编写如下的 SQL:
其中 model.n_clusters=5 指定把数据聚成 5 类。然后使用下面预测 SQL 语句输出聚类结果:
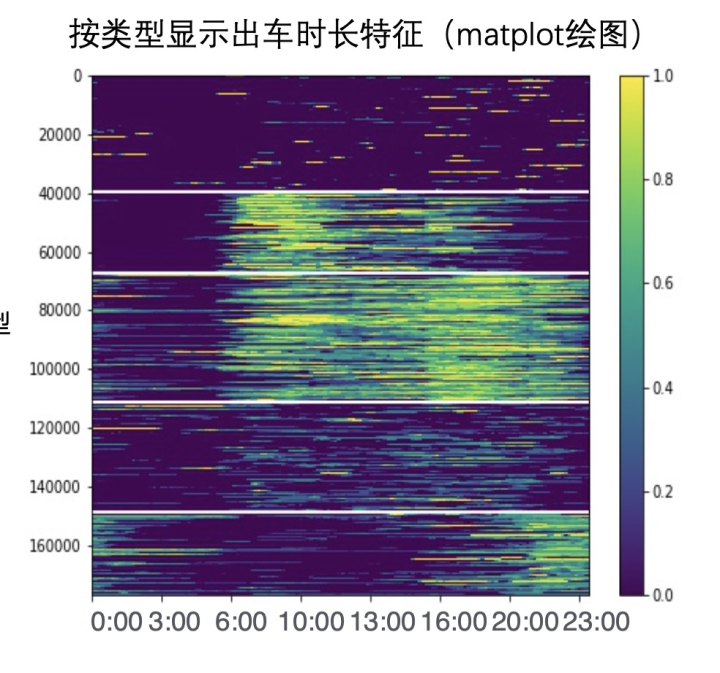
然后再次使用 matplot,根据类别绘制司机出车时长,可以得到如下这张图,比如我们可以这样解释这张图:司机分成了自由职业司机,定时上下班司机,996 司机,佛系司机,夜猫子司机 5 大类。当然我们也可以探索不同数目的聚类结果,可能会发现更多的规律。
总结
SQLFlow 不但将数据库和 AI 系统连接起来,还提供将一段 SQL 程序自动根据依赖关系编译成并发执行的工作流,在 Kubernetes 集群上分布式地运行。SQLFlow 提供了丰富的内置模型和 Model Zoo,用户只需要编写 SQL 就可以完成完整 AI 任务的构建,算法同学可以更加专注于建模工作,大大降低构建 AI 系统的成本和时间。如果您对 SQLFlow 项目感兴趣,可以在 SQLFlow Github 社区获得帮助。也可以使用我们提供的本地 playground 快速试用:
https://github.com/sql-machine-learning/playground/blob/master/dev.md
本文转载自公众号金融级分布式架构(ID:Antfin_SOFA)。
原文链接:
https://mp.weixin.qq.com/s/LydAst4w5-O2d1rUPVsTWg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论