

混沌工程六个阶段
从笔者所在团队的实践出发,我们将混沌工程总结为六个阶段,并对各个阶段的落地过程加以总结,希望能够对大家落地混沌工程有所帮助。今天主要是抛砖引玉,后续针对每个阶段,陆续会有专门的文章进行介绍。而混沌工程理论相关的部分,大家可以参考由 Netflix 出版的《混沌工程》迷你书。

上述各阶段涉及的部门和人员的数量,远远超过了当初的预估,因此该部分成为我们确定顺序的最主要因素,强烈建议大家实施混沌工程,一定要争取来自于管理层的支持以及周边团队的理解和配合,否则很容易导致项目虎头蛇尾。
单机破坏
重要性说明
以集群选主机制为例说明单机破坏的优先级和重要性,如果单机在某些场景异常后,集群无法选主,进而导致系统整体不可用。该问题如果在单机房破坏场景时才发现,那系统整体不可用了,你还能找出啥别的问题呢?一个机房的破坏场景,往往涉及多个部门的联动,大部分业务团队的各类角色均会参与其中,难道最后就得到一个结论:选主机制有问题。如果真是这样,你还打算继续干下去吗?
排序考虑
单机破坏能够在测试环境中发现绝大多数问题,并能扫清后续阶段的阻塞点,因此排在首位可谓是当之无愧。
破坏手段
在测试环境下,先从重启服务器开始,然后是关机,资源异常(如 CPU 打满)等场景。注意单机破坏场景不要把自己”拒之门外”。举个例子,把机器的 CPU 打满,但是没有设置打满的时长,结果自己也无法登录机器了,只能重启。
https://github.com/Netflix/SimianArmy/tree/master/src/main/resources/scripts
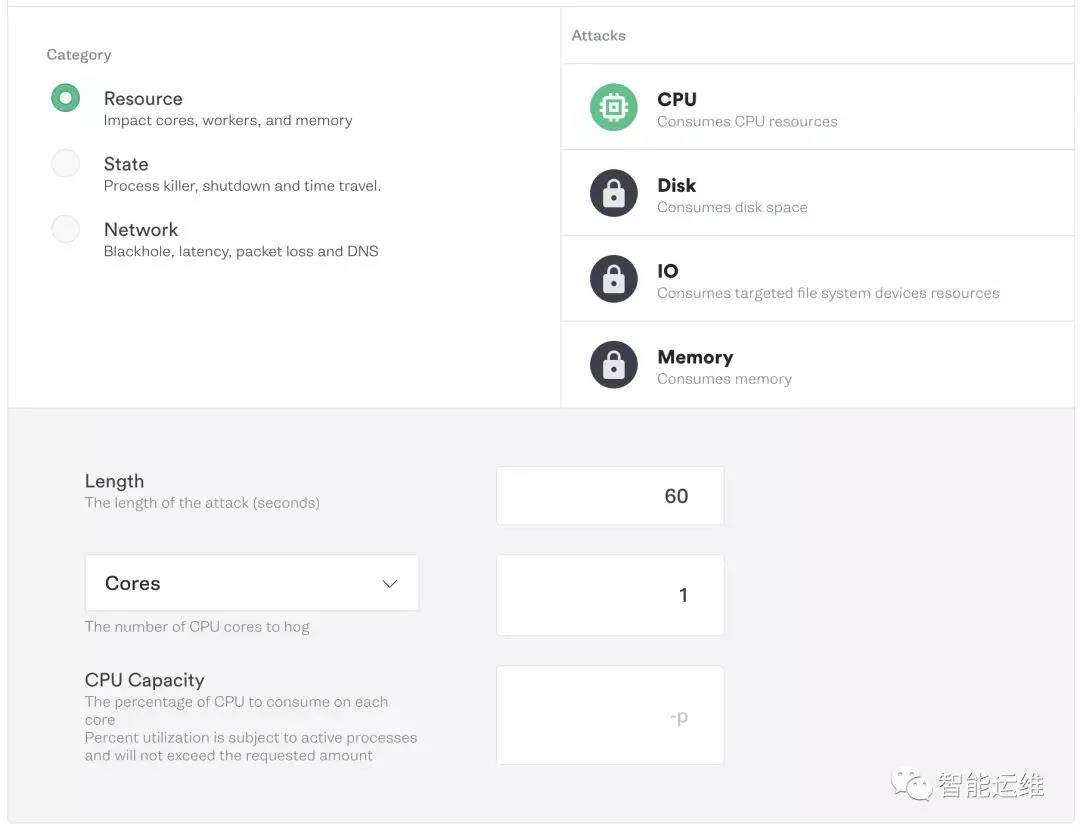
落地建议
初期仅在测试环境中进行,仅进行重启场景的验证就足以发现很多问题;
给出单机破坏的全部场景和验收方法,由各个团队自行落地;
不恋战,只要问题不阻塞单机房破坏环节,不影响黄金流程即可进入下阶段。
单机房破坏
重要性说明
单机房故障是造成服务整体崩溃的主要原因之一,全球互联网巨头大多发生过单机房故障导致服务崩溃的情形。诸如外网出口异常,内网跨机房专线异常,机房核心交换机异常,各种网络抖动和拥塞,IDC 供电设备异常等等,相信大家都不陌生,因此其重要性可见一斑。
排序考虑
高频故障场景,故障后影响较为严重,业界有较多的最佳实践可供参考,模拟单机房破坏的难度和风险均较低,因此紧随单机破坏其后。
破坏手段
将跨机房的专线端口关闭即可,恢复则是将端口重新 up 即可,整个耗时可以控制在秒级。演练前,业务方需要提前将流量迁移到其他机房,观察跨机房的残余流量符合预期后再进行操作,否则就对残余流量进行排查,从而避免发生较为严重的故障。
落地建议
如果近期公司内部发生类似的单机房故障,那是单机房破坏发起的最佳时机;
通过数据分析来揭示风险,如跨机房交互的模块数量及比例,跨机房的流量带宽的增长趋势、使用率和成分分析,每次机房级网络调整各个业务受影响程度的统计,各个业务方对较大网络操作的接受度等;
借助网络调整的机会,来间接实现第一次单机房破坏;
如果仅仅破坏部分机房(如所有在线机房)是不足以发现所有的问题和隐患的,需要对所有机房逐一进行一次演练,才能发现一些潜藏的依赖和问题;
单机房破坏的时间点尽量参照网络调整的时间点,大多数在凌晨 1 点左右进行。
依赖治理
重要性说明
依赖主要是第三方依赖和基础设施,包括但不限于 Mysql、Redis、K8S、DNS、LB、ELK、Hadoop 等,上述任何服务的故障,对业务影响都极为严重。以近期发生的 AWS 的 DNS 故障为例,持续 15 小时,多个业务受损。
排序考虑
基础设施可谓是牵一发动全身,故障频率低,故障影响大,因此依赖治理放在了单机和单机房之后。
破坏手段
基础服务和一般的业务场景无区别,主要也是通过单机破坏和单机房破坏等通用手段来进行快速的问题识别。
落地建议
对于依赖的破坏,为了减少对业务方的影响,初期可以通过业务方的测试/预发环境+依赖的正式环境组合来进行破坏,也可以在离线机房对基础设施进行破坏;
基础设施很大占比是开源软件,进行 Trace 的改造成本较高,因此要了解第三方依赖内部的关键点,并针对性的进行破坏演练。以 Mysql 为例来说,一般 Mysql 前面都会有一层 Proxy,如果 Proxy 正常,而 Mysql 异常会发生什么问题呢?事实证明,很多坑都在这个地方,而要想发现这个坑,那必然需要对 Mysql 的业务有一定的理解,也就是所谓的白盒;
攘外必先安内,各类依赖大部分都是其他部门提供的服务,沟通成本和配合度上会有区别,因此需要先搞定自身的问题,然后再来进行第三方的依赖治理,不然很容易被人怼回去,毕竟很多依赖属于基础设施,牵一发动全身,人家配合的成本也是极大的;
对于循环依赖需要在架构层面明确原则,然后再进行整体的改造。
全链路故障注入
重要性说明
所谓的精准注入,只影响特定的客户 ID、地域、设备类型、接口,还可以对注入的行为和比例等进行精准控制,从而大幅缩小故障范围,将故障的风险收敛到最小。因为是精准注入,因此必须具备全链路的观测能力,才能够将上述的细微的注入影响进行描述,否则,你可能很难回答,延时增加了 3s,是哪些模块的作用导致的。
传统的破坏方式,粒度只能控制在单机级别,很多影响非预期且及不可控。以 TC 命令为例,如果是按照一定比例进行破坏,你无法精准控制哪些请求会受到影响,运气足够差的情况下,也许你不希望被影响的请求全军覆没,而你期望被影响的请求则无一命中。另外,传统的破坏方式也没有统一的标准,有些需要用 tc 命令,有些是 iptables 命令,有些是写死/etc/hosts 文件,没有方便易用的方式,且本身存在较大的风险,很难进行大范围推广。下面是两者的对比:
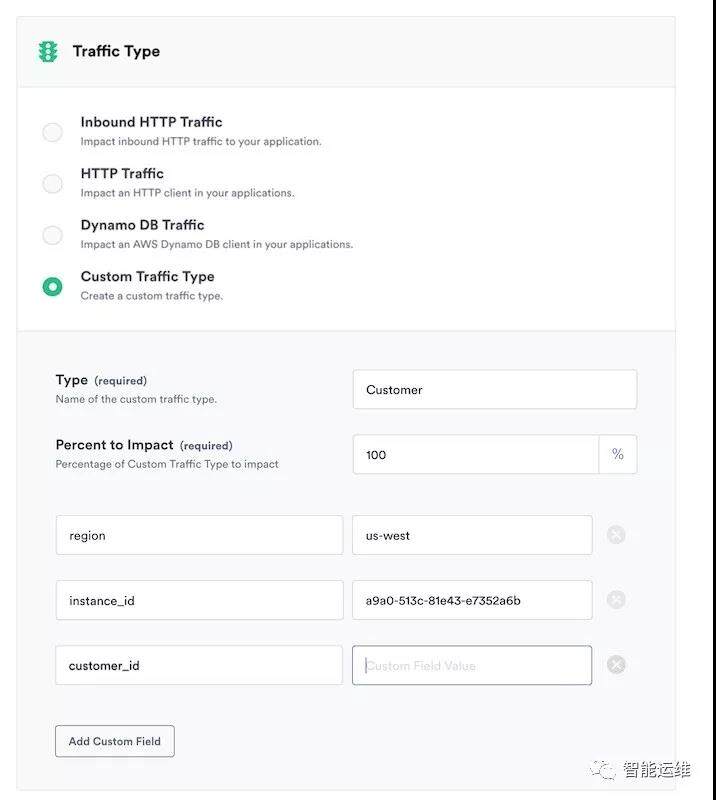
排序考虑
全链路追踪能力是故障注入的基础,需要所有的模块全部进行适配改造,否则调用链就会在某个阶段中断,进而导致不可完全追踪。同时对于一些开源软件,也需要进行适配,其成本是前四个阶段中最高的,耗时最长的,因此,故障注入往往会放在后期。
破坏手段
微服务化一般是基于 Istio 进行注入,或者在接入层进行注入均可。此处我们也在 Istio 的紧张改造中,后面可以给大家写专门的文章进行分享。
落地建议
对系统进行分级,首先将黄金流程进行改造,确保最核心的功能具备了能力,然后慢慢外扩到所有功能
CI/CD 整合
上述的四个手段,只能解决线上的存量问题,但无法阻止增量问题。因此,还需要将上述的各种能力,整合在 CI/CD 过程当中,在测试阶段进行拦截,从而彻底杜绝这类问题在线上发生的可能性。该部分目前我们也正在逐步建设和完善中,因此各种坑后续慢慢交流。
产品化
虽然通过 CI/CD 阶段的整合,可以将问题拦截在测试阶段,但这时候,每次都是测试阶段发现问题后让研发返工,对于研发就造成了极大的资源浪费。因此,需要将混沌工程形成的各种标准和规范,以产品化的形式交给研发同学使用,进而让大家都满意。
以单机起停脚本为例进行说明,每个模块的研发不同,可能存在的问题也不一样,这时候,发现问题后进行修改,不如提供一个统一的服务起停管理工具给研发使用,从而彻底解决该问题。开源软件类似 Systemd,Supervisor 和 Monit 都可以很好的解决这类问题,且对程序没有侵入性,不存在什么改造成本。
再高阶一些,就可以参考 Netflix 开源的各种软件https://github.com/Netflix/
参考文章:
Gremlin 发布面向混沌实验的应用级故障注入(ALF)平台

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论