

在前文《百度时序数据库——存储的省钱之道》中,我们介绍了百度 Noah TSDB 数据缓存层所采用的数据压缩算法,并对该压缩算法的核心原理进行了详细介绍,介绍了“省钱”的理论。今天我们将整体介绍一下该数据压缩算法在百度 Noah TSDB 的应用实践,从实践上介绍如何“省钱”。主要通过回答数据在哪儿压缩、压缩哪些数据、数据怎么压缩、压缩效果怎么样这四个问题来进行介绍。
数据在哪儿压缩
既然是介绍数据压缩实践,那么肯定要先介绍我们应用数据压缩的“主战场”。哪里做数据压缩收益更大?
在之前分享的《探索与发现,揭秘百度万亿时序数据存储架构》一文中,我们介绍了 Noah TSDB 的整体架构,架构图如下:
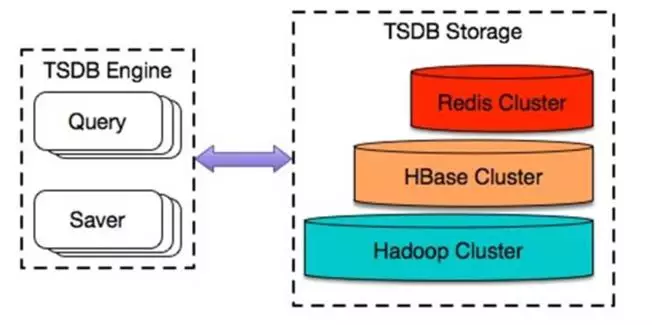
图 1 Noah TSDB 整体架构
为了保证在万亿数据点写入规模的高负载场景下,Noah TSDB 仍然能够提供低延迟的数据写入和查询能力,我们在底层存储部分进行了分层架构设计,根据不同的性能需求,将数据分别保存到不同的数据库中。数据压缩主要是应用在如下两个部分:
Redis Cluster 层
高频访问的数据放入缓存层(Redis Cluster),提供查询快速响应能力。这里是数据压缩、应用 Gorilla 算法最主要的地方。在缓存层进行数据压缩,可以减少缓存层宝贵的存储空间,保存时间跨度更长的时序数据。
HBase Cluster 层
在 HBase 层应用数据压缩,相同数据量下占用更少存储空间,可以保存更久的历史数据。不过由于监控领域的场景特性,新数据的价值高于历史数据价值,保存更多的历史数据收益相对较小(部分需要较久历史数据做历史分析的场景除外),所以这里压缩的主要收益还是降低资源使用,节约成本。
压缩哪些数据
在超大数据规模场景下,对所有的时序数据都进行压缩显然是不现实的。特别是在缓存层设计中,部分监控指标数据的访问频率不高,没有必要放入缓存层。那到底应该选哪些指标数据放入缓存层进行压缩缓存呢?
简单来讲,在选择放入缓存层指标的时候,可以做一定的用户查询行为统计,筛选出用户高频访问的指标数据放入缓存层。但是单纯以用户查询频率来设计不能有效覆盖全部需求场景,部分指标可能访问频率不是很高,但对于用户来说却非常重要,在查询该部分指标时需要快速获得响应。因此还是需要结合自身的业务需求进行指标选择。
这里简单介绍一下 Noah TSDB 选择放入缓存层的指标类型。
全量汇聚指标数据
汇聚监控指标数据总量相对不大,但却是能够反应整体服务状态的关键性指标。比如整个 Cluster 的 PVLost 之和、集群平均延迟、多维度数据等等。这部分反映全局的指标数据需要能够快速提供查询,放入缓存层。
热点监控数据
根据用户习惯,选择关注比较多的机器指标,如 CPU 利用率、内存利用率、网络 IO 等监控指标放入缓存层。
重点产品线数据
部分公司重点产品线核心指标对数据查询延迟要求比较高,经过白名单接入后一并放入缓存层进行压缩保存。
采用上述缓存策略后,我们的大部分查询请求都能命中缓存,有效减轻了后端 HBase 集群压力。
数据怎么压缩
上面介绍了我们在哪里缓存,以及要缓存哪些数据,这里我们要讲一下在有限的缓存空间里,如何压缩这些数据。
我们做数据压缩采用的核心方法就是前文提到的 Gorilla 压缩算法。算法的原理在《百度时序数据库——存储的省钱之道》中已经进行了介绍,这里不再赘述。这里主要讲一下在实际应用该算法时的一些思考与实践。
1 问题考虑
在我们具体应用 Gorilla 算法的过程中产生的几个疑问,这里选择部分和大家分享一下。
数据多版本能否支持
Noah TSDB 的上游包含流式计算模块,会对监控指标在固定聚合周期内进行数据聚合。然而同一指标的数据可能会在多个聚合周期内聚合,聚合的数据分为多个具有相同时间戳的数据写入 TSDB,会造成 TSDB 内部出现同一个指标在同一个时间戳下有多个版本,这就是监控场景常见的数据多版本问题。Gorilla 能支持数据多版本吗?
非浮点类型数据如何支持
Gorilla 算法介绍中只介绍了浮点型数据的压缩,在我们面向的监控场景中,时序数据类型涵盖整型、浮点型、字符串等多种数据类型,那么对这些非浮点类型的数据应该如何进行压缩才能具有较高的压缩率?
多值模型如何支持
相对于基本数据类型,时序场景比较特有的一种数据类型就是多值数据,单数据点同时包含[SUM、MIN、MAX、COUNT]四种数据值,如何去组织这种数据的压缩?
分布式写入冲突
在了解了 Gorilla 算法的原理后,我们看到算法在进行数据压缩的时候,会依赖同一个 DataBlock 中前一条数据的值来进行数据压缩。但是分布式环境下同一个指标的数据会被写入到不同实例,最终合入一个 DataBlock 的时候数据会乱序写入。对乱序的数据进行压缩的话,压缩效果必定大打折扣。在这种场景怎么保证压缩效率呢?
2 解决思路
针对上面我们提到的各个问题,在这里简要介绍一下我们的解决思路。
数据多版本
对于数据多版本的考虑,只要能够将同一个指标的数据写入同一个 TSDB 实例,在 DataBlock 内部是不会限制数据的唯一性的,因此数据多版本是天然支持的。
非浮点类型支持
目前不管是开源的还是友商的 TSDB,大都在压缩的时候对不同的数据类型选用最适合该类型的压缩算法,以最大限度根据数据本身的特性进行数据压缩。对于整型和浮点型数据我们都选用的是 Gorilla 压缩算法来做压缩。只不过 Gorilla 算法在设计的时候,限制了数据的精度,如在对值进行 XOR 后,只用 5 位来存储前置 0 数量。这也就代表最多只能支持 32 位数值,这会造成数据容易溢出,解压后造成数据偏差的问题。这点大家可以根据自己的业务情况来重新调整一下算法的细节部分。
多值模型的支持
对于多值模型的支持,我们增加了数据类型字段,用来区分多值数据类型和单值类型数据。对于多值类型的数据,按照约定的顺序依次对 Max、Min、Sum、Count,用单值的方式进行压缩,以这种方式处理多值数据。
分布式写入冲突
Gorilla 自己的分布式版本解决了分布式写入问题,可惜该版本没有开源我们无法得知其具体实现。但是对于该问题,简单的解决办法是只要保证同一个指标数据写入同一个 TSDB 实例中进行处理,那么在该实例上接收到的数据基本是顺序的,就可以解决上面提到的分布式乱序问题。具体实现方法可以采用如一致性 HASH 等方法实现。但是考虑到做数据路由来控制数据的写入,具有一定成本。最重要的是我们除了底层分布式存储,其余模块都是 Share-Nothing 设计,不希望在系统中引入复杂的分布式机制。因此最终解决思路是类似 HBase 的数据多版本,无需把相同指标数据写入同一个 DataBlock,可以每个分布式实例各自生成独立的 DataBlock,这样对于该实例自己维护的 DataBlock 是相对有序的,不需要做全局顺序的控制。而最终我们维护“多版本”DataBlock 即可。
数据压缩效果怎么样
以上便是一些我们在使用 Gorilla 压缩算法的一些实践经验。最后看看基于我们的实际场景进行优化改造后采用该数据压缩算法的压缩效果。
压缩算法上线后 Redis 集群整体节省了约 80% 的存储空间。而相对上线前,额外增加的 CPU 消耗不超过 10%,基本上对系统没有增加太多的负担。
内存使用变化
压缩前:
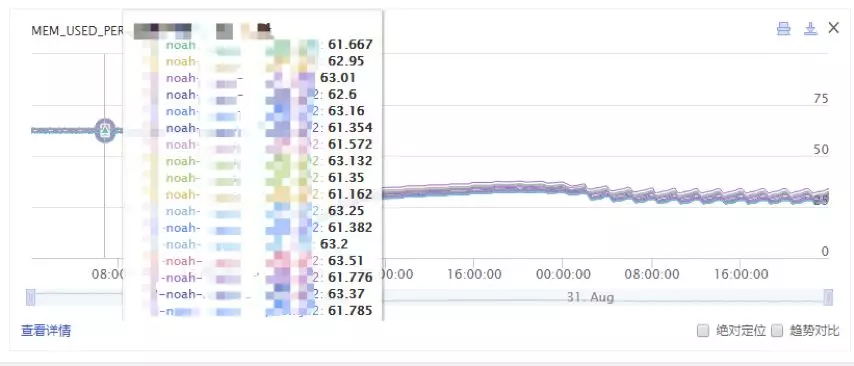
图 2 采用压缩算法前的内存使用情况
压缩后:
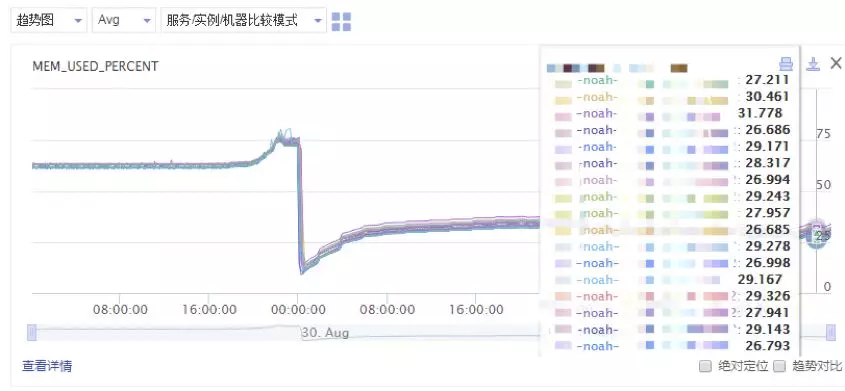
图 3 采用压缩算法后的内存使用情况
线上环境影响
Redis_lost 指标是我们统计出现的数据丢点情况。在之前访问 Redis 集群的时候,由于集群压力大导致常态存在一些 PVLost。
上线前:
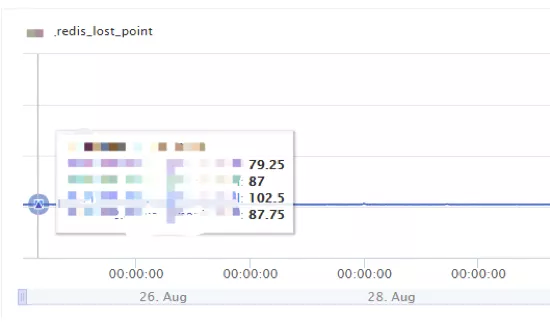
图 4 采用压缩算法前的 Redis 丢点情况
上线后:
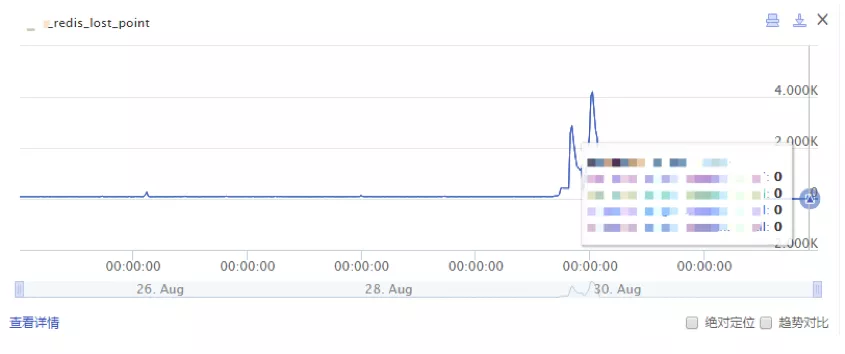
图 5 采用压缩算法后的 Redis 丢点情况
增加数据压缩后,没有对服务负载造成影响,此外还因为压缩后容量的增加,数据丢点的情况也得到了改善。
总结
以上就是我们 Noah TSDB 的缓存方案设计,以及在具体应用 Gorilla 算法时的一些考虑,从方案以及算法上的设计都需要根据实际生产场景进行权衡,如果各位看官能够有所收获的话本人倍感荣幸。我们的缓存设计仍有可优化的空间,比如缓存策略是否可以根据线上查询动态自学习调整,同时压缩算法本身还有可以优化的点。如果有任何建议和想法,欢迎一起探讨。
作者介绍:
任杰,百度高级研发工程师,负责百度智能运维产品(Noah)的分布式时序数据存储设计研发工作,在大规模分布式存储、NoSQL 数据库方面有大量实践经验。
本文转载自公众号 AIOps 智能运维(ID:AI_Ops)。
原文链接:
https://mp.weixin.qq.com/s/5m6yDCtj4VNMPFGGycPQcw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论