

很多大数据系统每天都会收集数 PB 的数据。这类系统通常主要用于查询给定时间范围内的原始数据记录,并使用了多个数据过滤器。但是,要发现或识别存在于这些大型数据集中的唯一属性可能很困难。
在大型数据集上执行运行时聚合(例如应用程序在特定时间范围内记录的唯一主机名),需要非常巨大的计算能力,并且可能非常慢。对原始数据进行采样是一种发现属性的办法,但是,这种方法会导致我们错过数据集中的某些稀疏或稀有的属性。
介绍
我们在内部实现了一个元数据存储,可以保证实时发现大量来自不同监控信号源的所有唯一属性(或元数据)。它主要依赖于后端的 Elasticsearch 和 RocksDB。Elasticsearch 让聚合可以查找在一个时间范围内的唯一属性,而 RocksDB 让我们能够对一个时间窗口内具有相同哈希的数据进行去重,避免了冗余写入。
我们提供了三种监控信号源的元数据发现:指标、日志和事件。
指标
指标是周期性的时间序列数据,包含了指标名称、源时间戳、map 形式的维度和长整型数值,例如 http.hits 123456789034877 host=A。
在上面的示例中,http.hits 是指标名称,1234567890 是 EPOC UTC 时间戳,34877 是长整型数值,host=A 是维度{K,V}键值对。我们支持发现指标名称和带有维度 map 的名称空间。
日志
日志是来自各种应用程序或软件/硬件基础设施的日志行。
我们用以下格式表示日志:
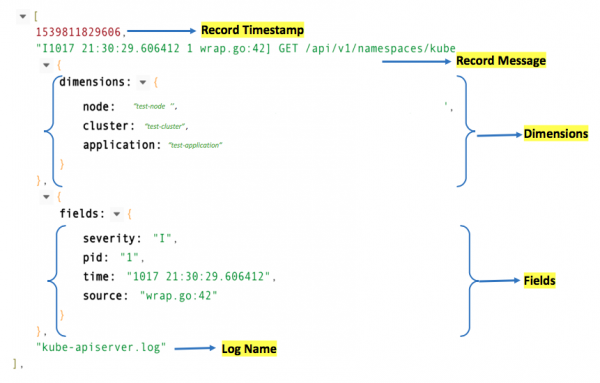
日志对用例(也称为名称空间)来说总是可发现的。每个日志行都可以是某种特定类型,例如 stdout 或 stderr。
日志信号的类型(也称为名称)也是可发现的,如上例所示,键值 map 也是可发现的。
事件
事件类似于日志和指标。它们可以被视为一种稀疏指标,表示为系统内的事件。它们是非周期性的。例如,路由器交换机变为不可用时会被记录为事件。此外,它们可能会有点冗长,可能会包含大量的文本信息用以说明事件期间发生了什么。
事件的一个简单示例:
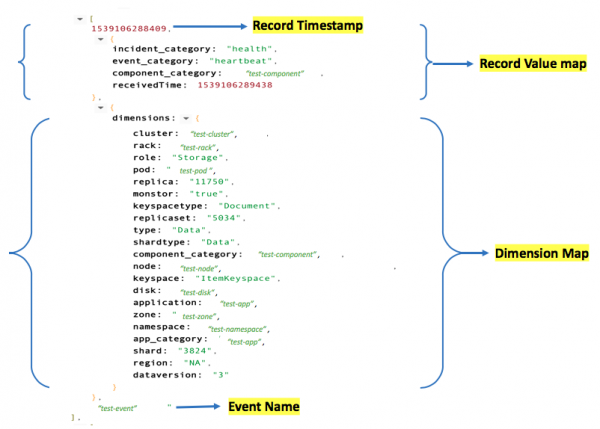
与日志和指标类似,事件也有名称空间和名称,两者都是可发现的。可发现的字段键让我们能够在已知字段上执行聚合操作,例如 MIN、MAX 和 COUNT。
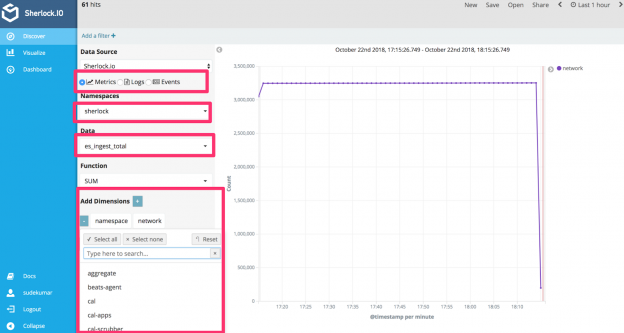
下面的截图突出显示了我们的产品控制台中的发现属性:
方法和设计
所有监控信号最初都由我们的 ingress 服务实例负责接收。这些服务节点使用自定义分区逻辑将不同的输入监控信号(日志、指标和事件)推送到 Kafka 数据总线主题上。元数据存储 ingress 守护程序负责消费这些监控信号,然后将它们写入到后端 Elasticsearch。
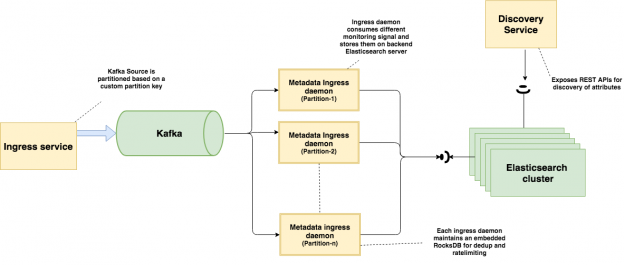
我们收集的监控信号被推送到 Kafka 总线上,它们是我们的源数据流。Kafka 的一个优点是它提供了持久存储,即使下游管道处于维护或不可用状态。我们还在入口服务上使用自定义 Kafka 分区器,以确保具有相同哈希值的键始终位于相同的 Kafka 分区上。不同的监控信号内部使用不同的哈希值。例如,我们使用基于名称空间+名称的哈希值来表示指标信号,而日志信号则使用了基于“名称空间+维度{K,V}”的哈希值。这种分组有助于降低下游 Kafka 消费者需要处理的数据量基数,从而有效地减少内存占用总量。
与我们的元数据存储入口守护进程类似,还有其他一些消费者将原始监控信号写入到后端存储,如 Hadoop、HBase、Druid 等。单独的发现管道可以在随后将这些原始监控信号输出,而无需执行昂贵的运行时聚合。
我们使用 RocksDB 作为元数据存储的嵌入式数据缓存,避免了对后端 Elasticsearch 数据接收器的重复写入。我们之所以选择 RocksDB,是因为它的基准测试结果非常令人满意,并且具有很高的配置灵活性。
元数据存储入口守护程序在处理记录时,会将记录的键哈希与高速缓存中已存在的哈希进行对比。如果该记录尚未加载到缓存中,就将它写入 Elasticsearch,并将其哈希键添加到缓存中。如果记录已存在于缓存中,则不执行任何操作。
RocksDB 缓存偏重于读取,但在刚开始时(重置缓存)时出现了一连串写入。对于当前负载,读取超过了 50 亿,以及数千万的写入,大部分写入发生在前几分钟。因此,在刚开始时可能存在消费者滞后的情况。对于较低的读写延迟,我们努力将所有缓存数据保存在 RocksDB 的内存中,以避免二次磁盘存储查找。我们还禁用了预写日志(WAL)和压缩。在基准测试中,我们发现 16GB 的内存就足以存储哈希值。
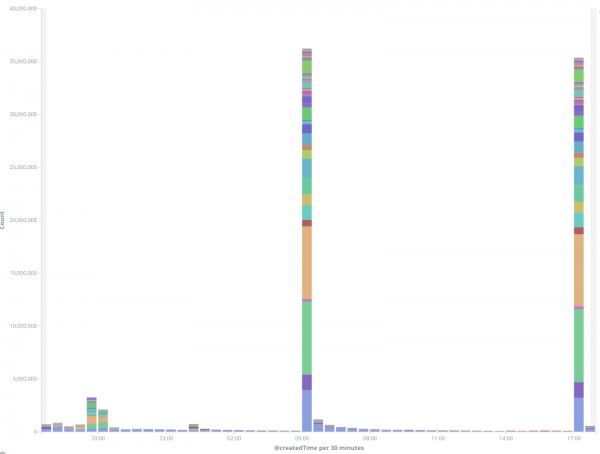
上图表示写入后端 Elasticsearch 的文档数。峰值对应于重置高速缓存之后的那段时间。
出于监控的目的,我们将所有 rocksDB 统计数据作为指标发送到我们的监控平台中。
我们使用 Elasticsearch 6.x 为后端聚合提供支持,用以识别监控信号中的不同属性。我们构建了一个包含 30 个节点的 Elasticsearch 集群,这些节点运行在配备了 SSD 和 64 GB RAM 的主机上,并通过我们的内部云平台来管理它们。我们为 Elasticsearch JVM 进程分配了 30 GB 内存,其余的留给操作系统。在摄取数据期间,基于监控信号中的不同元数据对文档进行哈希,以便唯一地标识文档。例如,根据名称空间、名称和不同的维度{K,V}对日志进行哈希处理。文档模型采用了父文档与子文档的格式,并按照名称空间和月份创建 Elasticsearch 索引。
我们根据{K,V}维度对根文档或父文档的 document_id 进行哈希处理,而子文档则根据名称空间、名称和时间戳进行哈希处理。我们为每一个时间窗口创建一个子文档,这个时间窗口也称为去抖动时段。去抖动时间戳是去抖动时段的开始时间。如果在去抖动期间发现了一个子文档,这意味着子文档的名称空间和名称的唯一组合与其父文档拓扑会一起出现。去抖动时间越短,发现唯一属性的时间近似就越好。Elasticsearch 索引中的父文档和子文档之间存在 1:N 的关联关系。
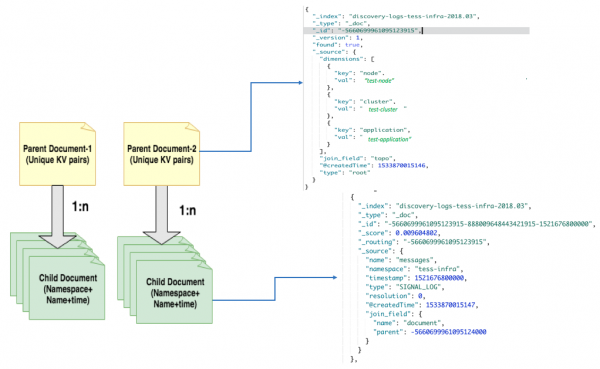
Elasticsearch 中的父子文档动态模板是这样的:
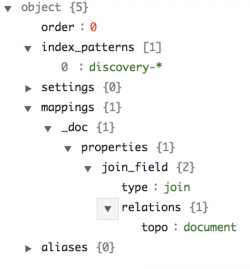
子文档的模板是这样的:

我们为 Elasticsearch 集群维护了两个负载均衡器(LB)。READ LB IP(VIP)用于客户端节点,负责所有的读取操作,WRITE LB VIP 则用于数据节点。这样有助于我们在不同的客户端节点上执行基于聚合的计算,而不会给数据节点造成太大压力。
如果你要频繁更新同一个文档,那么 Elasticsearch 不是最好的选择,因为文档的片段合并操作非常昂贵。在出现高峰流量时,后台的文档片段合并会极大地影响索引和搜索性能。因此,我们在设计文档时将其视为不可变的。
我们使用以下的命名法为 Elasticsearch 集群创建索引:

例如,以下是后端 Elasticsearch 服务器的索引:
nfoq.cn/resource/image/23/17/23d0650fe039c39c6609242c2dc51917.png)
我们按照月份来维护索引,并保留三个月的索引。如果要清除索引,就直接删除它们。
我们的发现服务是一个作为 Docker 镜像进行部署的 Web 应用程序,它公开了 REST API,用于查询后端元数据存储。
发现服务提供的关键 REST API 包括:
在不同的监控信号(日志/事件/指标)上查找名称空间(或用例);
查找给定时间范围内名称空间的所有名称;
根据输入的名称空间、名称列表或给定的时间范围查找所有监控信号的维度键值;
根据输入的名称空间和给定时间范围查找值键;
根据输入维度{K,V}过滤器查找所有名称空间或名称;
对于给定的名称空间、名称和不同的维度过滤器,还可以根据该唯一输入组合找到其他关联维度。
我们的元数据存储入口守护程序部署和托管在内部 Kubernetes 平台(也称为Tess.io)上。元数据存储入口守护程序的应用程序生命周期在 Kubernetes 上作为无状态应用程序进行管理。我们的托管 Kubernetes 平台允许在部署期间自定义指标注解,我们可以在 Prometheus 格式的已知端口上发布健康指标。监控仪表盘和警报是基于这些运行状况指标进行设置的。我们还在发现服务上公开了类似的指标,以捕获错误/成功率和平均搜索延迟。
性能
我们能够在 10 个元数据入口守护进程节点(下游 Kafka 消费者)上每分钟处理 160 万个指标信号而不会出现任何性能问题;
可以在几秒钟之内发现任何唯一的元数据属性;
在我们的生产环境中,我们的去抖动窗口间隔设置为 12 小时,在每个去抖动期间,我们拥有约 4,000 万的唯一基数(最多可达 6000 万)。
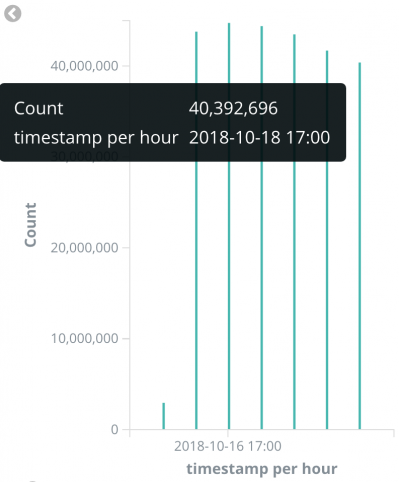
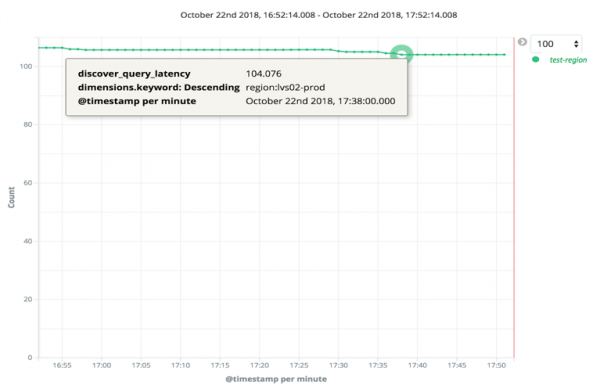
目前,我们发现生产环境中触发的大多数查询的平均延迟为 100 毫秒。而且我们发现,跨名称空间触发的查询比基于目标名称空间的查询要慢得多。
结论
将发现功能与实际数据管道分离让我们能够快速深入了解原始监控数据。元数据存储有助于限制需要查询的数据范围,从而显著提高整体搜索吞吐量。这种方法还可以保护原始数据存储免受发现服务的影响,从而为后端存储节省了大量的计算资源。
查看英文原文:https://www.ebayinc.com/stories/blogs/tech/an-approach-for-metadata-store-on-large-volume-data-sets/

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论