

什么是 A/B Testing?
关于 A/B 有很多层的定义,通俗来说,A/B 是一种工具,通过分隔 A 和 B 两个版本,统计数据,进而看哪个版本的数据效果更好,对产品目标更有帮助。
在这里我更多想从 A/B 本身的意义来说一下它的定义。
以我们的业务迭代为例,我们会定义产品的业务数据指标(这些指标通常是可以直接和间接反映我们的业务目标的),然后我们在业务迭代中不断提出假设,期望通过做这些假设的改变来提升相对应的业务指标。而在这里 A/B 就是用来衡量我们提出的业务改进假设是否有效的一种方法,从统计学意义上说是一类假设验证的方法。
我觉得这样定义的好处是,A/B 不仅仅是一个工具,更多是一种与业务发展融合在一起的迭代思路,并且在 A/B 背后实际有着科学的统计学的依据支撑着,你也会更加关注每一个业务假设是否真的是有效的。
用户增长中最忌讳的是盲目套用其他业务线的增长手段,而忽视了自己业务的分析和推导的过程,凡事是否正确,需要我们测一测才知道。
产品在什么阶段适合 A/B Testing?
对于一个初创项目,产品刚刚孵化,这种时候不太适合做 A/B 测试,因为这个时候我们的目标相对是比较明确的,就是快速形成“原型”产品和大框架,把“产品生下来”,因此也基本上不会有太多抠细节的部分。
而当产品到了一定的阶段,模式已经成型比较稳定,相对处于快速迭代的阶段,就比较适合利用 A/B Testing 来助力业务发展了。

A/B Testing 的步骤
说 A/B Testing 的步骤之前,我想说,A/B Testing 实验不是说你做了一次实验拿到结果就再也不用做 A/B 了,它更多是一个不断优化和理解产品以及用户的过程。
因此,这里所说的 A/B Testing 的步骤不是指我们如何在平台上面配置一次 A/B 实验,而是更大范围的,如何用 A/B Testing 优化产品的步骤。
总的来说,业界一般会给 A/B Testing 划分为 8 个步骤。

这是我学习看到的 8 阶段 A/B 划分,可以看到我们技术同学最关注的创建 A/B 实验,实际上只是其中的第 4、5 步,而除此之前,我们还有很多工作要做,那么要科学做 A/B 我们究竟每一步应该做些啥呢?我们来看一下。
1. 建立产品漏斗
这一步往往在我们的工作中会被忽略掉,我觉得,不管是业务还是技术同学,我们都有必要了解自己的产品链路以及用户的漏斗,知道了用户从哪里来,我们希望用户去哪里,才能够有准备的做增长。例如用户拉新的流程,它的漏斗大致可以是:

2. 确定产品链路核心指标
在明确了产品的漏斗之后,我们需要明确要观察产品链路中的哪些核心指标。
如果你的关注点仅仅是一个页面,那你可能更多需要细看当前页面的用户指标;如果你关注的产品链路比较长,你应该关注整个链路上各个节点之间的指标。
以上面“用户拉新”的例子来说,我们可能要关注每一个节点的用户量(PV/UV),还要看每一层的转化率(例如: 点击/曝光)等等。
确定了指标之后,我们就需要把这些指标纳入长期的观察中。

3. 观察指标,提出优化假设
接着我们的产品同学就可以根据指标分析当前的业务状况,然后结合需要优化的数据指标,提出相对应的业务假设。这里开始,就有统计学知识入场了。
这里我们说假设实际上包含了两种:
原假设,又叫零假设、无假设(Null Hypothesis),代表我们希望通过试验结果推翻的假设。
备择假设(Alternative Hypothesis),代表我们希望通过试验结果验证的假设。
可以看得出原假设是悲观主义的。为啥要这么分一下,说实在我自己一开始也很懵逼。我们这里先提出这两个概念(原假设、备择假设),他们的作用在后面几步会看到。
假如说我们的场景是:优化页面上面按钮的点击率,而我们的预计做法是加大按钮的尺寸。
那么原假设的表述就是:加大按钮的尺寸,按钮点击率不会有任何变化。
而备择假设的表述则是:加大按钮的尺寸,按钮点击率会有影响(我觉得影响包含提升和降低,不过大多数的讲解中这个假设只会写提升,我理解我们正常不会假设为数据降低,这点可以探讨一下)。
另外要注意的是,在假设检验中,原假设和备择假设有且只有一个成立。
确定了假设,接下来我们就进入实验的设计了。

4. 设计 A/B 实验方案
实验设计上,我们要明确一些信息:
我们要写明,实验目标是什么,包括上面说的假设。
在实验分组上,我们要考虑如何划分分组,是否要有 A/A 对照,要切多少流量来做实验?
另外在投放上,我们的实验要针对谁做?是否要投放在特定的地区?或是投放在特定的端?
另外,A/B 实验中最好每次只做一个“变量”的改变(虽然受限于时间你也可以同时做多个变量,例如经典的奥巴马参选的 A/B 版本海报),这样对于后续的数据分析和拿明确的结论会比较有好处。
5. 开发 A/B 实验
这一步,是我们最熟悉的阶段,一般的项目需求评审都是从这里开始的,开发同学会借助 Runtime SDK 编写 UI 逻辑、分桶逻辑等,这里先不赘述里面的细节。
6. 运行实验
开发完成后,我们就要准备上线了,这时要设定实验运行时的配置,例如:
我们主要需要设定:
指标的样本量(反过来样本量也决定了实验的运行时长)。
实验的显著性水平(α)、统计功效(1-β),一般业界普遍设定 α 为 5%,β 为 10%~20%。
为什么要设置显著性水平(α)、统计功效(1-β)?
这是因为,所有的实验,在概率统计学上都是存在误差的,而误差会导致我们做出错误的判断。
这里常见的错误判断包括:
第 I 类错误(弃真错误):原假设为真时拒绝原假设;第 I 类错误的概率记为 α(alpha),对应就是显著性水平值。
第 II 类错误(取伪错误):原假设为假时未拒绝原假设。第 II 类错误的概率记为 β(Beta),取反后(1-β)对应就是统计功效值。
再白话一些,以上面的例子来说:
第一类的错误是指,加大按钮的尺寸,按钮点击率实际没有什么变化,但因为误差,我们认为有变化。
第二类的错误是指,加大按钮的尺寸,按钮点击率实际产生了变化,但因为误差,我们认为没有变化。
这里如果觉得绕,可以多感受几遍。设置好这些,发布完代码后,我们就可以发布实验了。

7. 实验数据分析
我们前面说过: A/B Testing 的统计学本质就是做假设检验。
当然在开始假设检验前,我们要先验证一下,我们的数据本身是正确的。
然后我们就要根据实验的数据看:
实验显著性是否满足要求?
实验的结论是否证实了假设对数据的提升?
实验是否带来了漏斗中其他数据变差?
关于实验的显著性,这里我们还会用到一个 z-test 计算 p 值的方式来进行校验。
p 值表示,我们观察实验样本有多大的概率是产生于随机过程的,p 值越小,我们越有信心认为原假设是不成立的,如果 p 值小于显著性水平(α),则我们可以认为原假设是不成立的。
8. 实验结论
最后,我们根据这次实验的分析结果,总结实验结论。
例如:这次实验我们具体通过做了 xx 提升了 xx 指标,并且没有对其他的指标产生影响,通过这次实验的结论,我们推理出在 xx 场景下,适合使用 xx 方式来提升 xx 指标。
当然如果没有达到预期的目标,我们就要调整策略提出更进一步的优化假设。
这 8 步,有时候我们也会缩减为一个 5 步的循环:
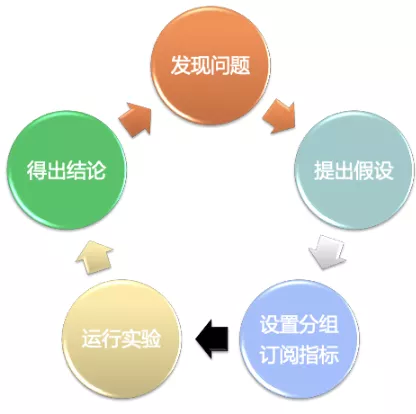
总的来说,所做的事情是差不多的。
在电商业务中做 A/B Testing,我们面临什么挑战?
说了这些,我们再来看看目前在电商中做 A/B 测试,我们都面临什么样的挑战?
我个人觉得主要的挑战就是:
A/B 测试直观感觉成本高,业务有接受门槛。
电商业务都讲究跑得快,这点我也和不少同学聊过,其实大家对于接受做 A/B 测试这件事情,感觉不是这么的 buy-in,原因还是直观感觉成本高,开发得开发两(n)个版本,耽误了上线时间。不过讲道理来说,我们不仅仅要追求“跑得快”,还得“方向对”。
相信前面说了这么多,我们可以看到结合 A/B Testing 来做业务,是一个比较科学的过程,有 A/B Testing 我们在业务过程中会更加注重假设求证、数据推导以及验证,同时 A/B 上线相比“一把梭上功能”也可以降低迭代带来的业务风险,甚至结合 A/B 你可以发掘业务中存在的问题,更加了解你的用户的行为,此外通过 A/B 获得的业务的增长经验可以沉淀下来通用化。
另外 A/B 不是一次性的事情,而是一个长期迭代的过程,大家做 A/B 是要以“不断优化”的心态来做,而不是“一次到位”。
从 A/B “平台”的角度来说,要帮助业务解决这些挑战,我们有很多的问题要解:
解决 A/B 成本高的问题(这里我们从几个角度来解决):
1.平台的操作效率(是否简单易用),平台工具是否通俗易懂(A/B 那么多统计学的概念的理解成本能否被我们平台侧抹平)。
2.开发更加规范,我们需要从开发 sdk 上规范业务的定制 A/B 开发,提供开发。
3.开发效率提升:
从工程侧,我们可以利用代码脚手架、代码生成等方式来提升效率。
从平台功能上来说,我们可以提供 UI Editor 等之类的工具,把一些“静态配置”类的部分开放给运营和产品,允许他们做改动来做 A/B 实验,减少开发人员自己的投入。
4.A/B 的能力需要融入到其他的流程、平台、系统里面。
未来运营在使用其他平台的时候,不会感觉 A/B 配置是一个割裂的部分,当然这里的方案也是需要我们好好思考的,现在 A/B 的能力要融入到其他平台的成本还是非常高的。
我想这些也是我们接下来一步步需要解决的问题。
本文转载自公众号阿里技术(ID:ali_tech)。
原文链接:
https://mp.weixin.qq.com/s/3Lvuja4fDFSiqwyEgdYxlQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论