

美国总统特朗普先生虽年逾古稀,但仍活跃在社交媒体上,“推特治国” 形象深入人心。特朗普早在竞选阶段就和媒体结下了梁子,他时常谴责媒体曲解自己的观点,传播假新闻。2017 年 2 月 16 日,特朗普上任后举行的首场发布会上,他花了 75 分钟炮轰媒体,指责许多媒体发布假消息,并在推特上点名纽约时报、NBC 新闻、ABC、CBS、CNN 是美国人民的敌人。曾有媒体做过统计,特朗普上任头六个月在推特发文总共 991 条,其中 82 条都是针对媒体的。我们有没有想过让计算机来阅读特朗普的推文,理解他本人和粉丝对某些话题的看法呢?那么问题来了,要如何让计算机能够读懂推文所表达出来的情绪呢?
人们很少为推文所透露的情绪究竟是积极的还是消极的而发憷。但对计算机来说,几乎就是一个难于上青天的蜀道了:复杂的句子结构、讽刺、比喻等等,使得计算机难以判断句子所表达的含义和情感。然而,如果我们能够让计算机自动评估推文所透露出来的情绪的话,那么就可以大规模挖掘人们对各种问题的意见了,还有助于我们理解某些群体为什么会持有某些观点。
从更基本的层面上来说,理解文本的情感是自然语言理解的一个关键部分,因此,如果我们希望计算机能够有效地与我们进行交流的话,就必须解决这个问题。
在这篇博文中,我将介绍谢菲尔德大学的一个小型研究项目的成果,该项目是 SoBigData 项目的一部分。我们测试了不同的文本处理方法,并分析了它们能够捕获到多少情绪。
前言
这个项目的目的是测试计算机如何通过机器学习来理解文本所表达的情绪。为此,我们给计算机馈送了大量推文,每条推文都被人们贴上了积极、中立或消极的情绪标签。每条推文都有一个相关的主题,这一点很重要,因为根据讨论主题的不同,句子可能会有非常不同的情绪。举个例子,如果我们讨论的是 “质量” 的主题,那么,这个单词 “high” 传递出来的是情绪积极的,而在讨论 “价格” 的主题时,这一单词所透露的就是消极的情绪了。又比如 “Green” 这个单词,在讨论 “环境问题” 的主题时,这个单词是积极的,但在讨论 “艺术” 主题时可能就是中立的了。现在计算机的任务就是预测给定推文和相关主题所表达出来的情绪。
计算机是如何阅读文本的?
如果你没有机器学习的经验,你可能会觉得这似乎是一个奇怪的问题。但是,机器学习是基于统计学的基础之上的,因此,机器学习系统要处理的任何东西,都必须用数字来表示。将文本转换为数字这一过程是在所谓的嵌入模型中完成的,开发这些模型本身就是主要研究领域之一。嵌入模型将单词或句子转换为向量,在训练过程中,向量会不断调整,使得意义相近的单词和句子都得到相似的向量结尾。在理想情况下,向量应该能够捕捉含义、上下文、情绪等。但这根本不是一项简单的任务,这就是为什么开发了许多不同的嵌入模型的原因。通常来说,较新的模型表现得更好,但它们也可以针对特定的任务进行调整。
成熟的机器学习系统能够在情绪分析等方面达到最先进的水平,这简直太猛了。它们由多个组件组成,其中文本嵌入只是其中的一个组件,通常很难评估系统的哪些部分是性能瓶颈。由于任何文本都需要表示为机器学习系统能够使用的向量,因此,任何分析(包括预测推文的情绪)在很大程度上都依赖于所选择的嵌入模型。但这并不是说系统的其他部分也同样重要。
为使文本嵌入的作用更加透明,我们开始测试它们在预测情绪方面的性能,为此,我们将系统设计成模糊程度最低。
我们如何预测情绪?
我们预测情绪的方法相当简单,并受到协作过滤的启发。每条推文都有一个相关的主题,重要的是,必须根据这个主题来评估情绪(因为同样一个说法,对一个方面来说是积极的,而对另一方面则是消极的)。由于推文和相应的主题,都有相同维度的向量表示,因此我们可以采取两者的内积,给出一个代表情绪的数字。没有理由认为应该让它与 “原始” 嵌入一起使用,所以,在使用内积之前,我们应学习并将转换(稍后将进一步说明)应用到主题向量空间。通过这种方式,我们就可以得到情绪,即使这个话题此前从未见过。
我们希望能够预测三种不同的情绪(积极、中立、消极),因此,实际上我们学习了主题空间的三种不同转换,分别是预测积极情绪、中立情绪和消极情绪。当时用三个变换的主题向量中的每一个获取推文的内积时,我们得到三个数字,可以理解为模型对每种情绪的推测:这一数值越高,表明模型越认为这就是这条推文所透露出来的情绪。
项目概述
我们想测试不同的单词嵌入对推文情绪有何影响。为预测情绪,我们训练了一个模型,该模型学习了主体向量的三个变换,这样,推文和三个主题向量的内积就是模型对这三种情绪的投票。
我们有几个不同的选择。首先,我们必须要选择要测试的嵌入模型。其次,我们需要决定如何转换主题向量。最后,我们还需要一个已经被人工贴上情绪标签的推文数据集,这样,我们就可以训练和测试这个模型了。
决定设置
数据集
我们使用了为 SemEval-2017 Task 4 提供的英文数据集(http://alt.qcri.org/semeval2017/task4/)。这个数据集包含了大约 26000 条不同主题的推文,所有这些情绪都是人工标注的。我们保留任务组织者定义的分割,即,大约 20000 条推文用于训练,6000 条推文用于测试。
嵌入模型
我们选择测试以下四个嵌入模型:
2003 年的 Neural-Net Language Models(NNLM),是最早尝试用神经网络学习单词嵌入的实验之一。该模型构建了 128 维的词向量,并将其作为一种单词嵌入基线,更高级的模型应该能够击败这种基线。
NNLM 如上所述,但现在有了标准化的词向量,有时可以观察到它们产生更好的结果。
2018 年初的 Embeddings from Language Models(ELMo),已被证明在许多不同的任务中实现了最先进的结果,构建 1024 维词向量。
2018 年初的 Universal Sentence Encoder(USE),一种经过训练的模型,可在许多任务中找到有用的单词嵌入。构建 512 维词向量。
以上提到的所有四种嵌入模型,都可以从 TensorFlow Hub 方便地获得:https://tfhub.dev/
转换模型
用于转换主题向量空间的模型的选择,是一项很棘手的任务。为什么呢?因为,一方面,我们希望保持原始向量空间尽可能不变;另一方面,我们希望转换足够灵活,以便嵌入单词中的信息实际上能够用来预测情绪。因此,我们决定测试这两种不同的转换模型。
一种简单的仿射变换。这种转换只能表示最基本的转换,如缩放、旋转、剪切和平移,因此,在某种意义上,这将测试 “原始” 嵌入捕获了多少信息。
一种更为复杂的转换,是由神经网络表示。我们使用一个具有两个隐藏层的神经网络,每个隐藏层是嵌入维数的 8 倍:ReLU 激活函数和 Dropout。网络将主题向量作为输入,并输出转换后的主题向量。这种转换可以以高度非线性的方式扭曲主题空间,因此应该能够获得更高的准确度。然而,这样一来训练将更加困难,并更可能对训练集出现过拟合现象。
最后的模型将学习上述每种类型的三种转换,对应于我们想要预测的三种情绪。
纠正数据集中的不平衡
使用真实数据总是很有挑战性的。尤其是如果某个情绪或者主题被过分代表,那么这个模型很可能会在训练期间完全专注于此,这将会导致预测其他情绪,或使用其他主题。相反,我们希望确保模型对所有主题和情绪给予同样的权重,而不管它们出现的频率有多高。纠正这些错误的效果是相当戏剧化的,也是一个值得记住的好教训,所以,让我们花上几分钟的时间来讨论这个问题。
数据集中的不平衡
绘制每种情绪的推文数量,如下图所示,数据集显示,类出现了巨大的不平衡的现象。
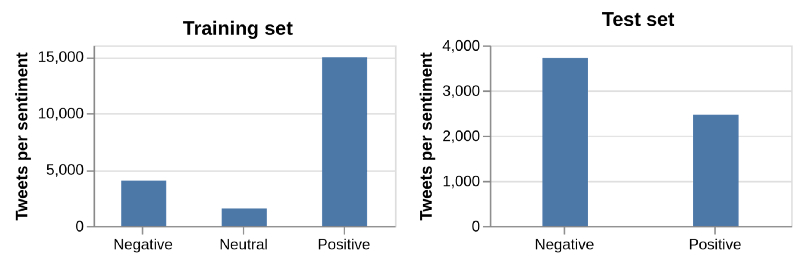
为训练集和测试集分配情绪类。
尤其在训练数据中,积极的情绪被严重高估,事实上,近 73% 的训练推文都有积极的情绪。这意味着,该模型将比其他模型更能从预测积极情绪中获益。另一方面,中立情绪只与不到 10% 的推文相关,如果有助于预测积极情绪的话,那么模型可能只是学会了忽略这种情绪。
测试集中的分布截然不同。消极情绪比积极情绪更加丰富,没有一条推文透露出来的情绪是中立的。这使得模型平等对待所有的情绪变得更加重要。
实际上,在 NNLM 上使用仿射变换模型进行的测试表明,由于训练数据的普遍性,因此经过训练后的模型明显倾向于积极情绪。在本次测试中,我们将训练数据中的主题分为训练集和评估集,分别占主题的 90% 和 10%。
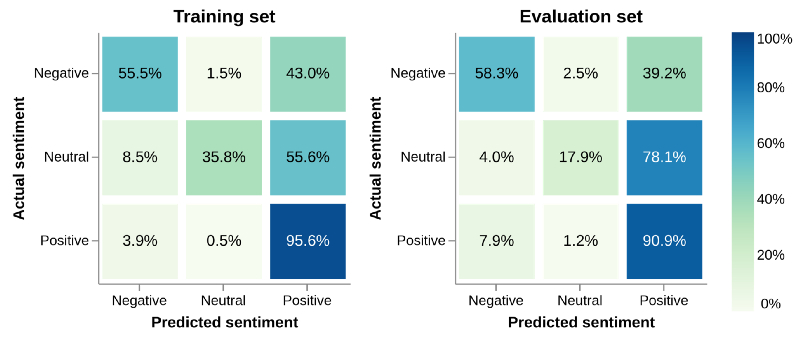
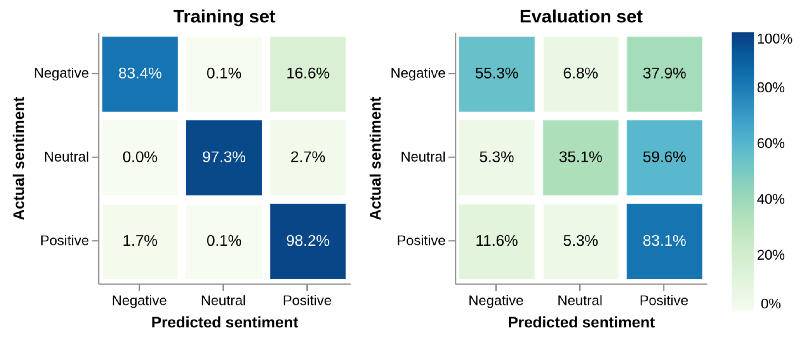
显示推文的实际情绪和模型预测的情绪的混淆矩阵(confusion matrix)。百分比显示了特定的实际情绪被预测为模型的三种情绪中的任何一种的频率。完美的模型应该有 100%的对角线,这意味着预测总是正确的。然而,从此图可以看出,无论实际情绪是什么,这个模型通常会选择预测积极情绪。(译者注:混淆矩阵,是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。基于实际的名称可以更容易判断机器是否将两个不同的类混淆了。在机器学习领域,混淆矩阵通常被称为列联表或误差矩阵。
上图显示了情绪预测的混淆矩阵,其中,每列对应于一种预测的情绪。每一行显示的是实际的情绪,每个矩阵元素的数量和颜色显示具有这种实际情绪的推文在列中显示的百分比。
理想情况下,对角线应接近 100%,这意味着几乎所有推文的预测情绪都是正确的,但即使是训练集中,也会存在很大的非对角线元素。这表明了即使模型知道正确的情绪,也会更倾向于在大多数情况下默认预测积极情绪。43% 的消极情绪的推文和 55% 以上的中立情绪的推文被预测为积极情绪。这对于分别为 39% 和 78% 的评估集来说更加槽糕。
但是,在训练集和测试集中,每个主题的推文数量也存在很大的不同。
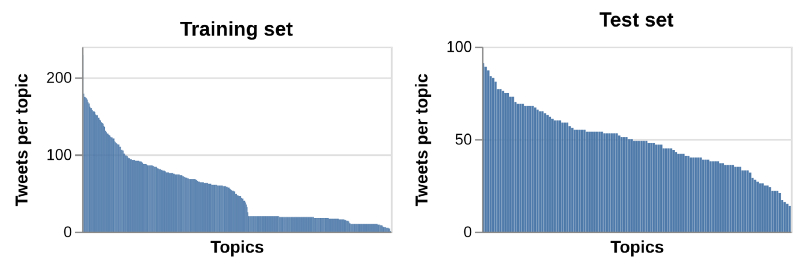
训练集和测试集中与每个主题相关的推文数量。主题基于推文数量从左到右排序,为清晰起见,此处略去了主题的名称。
特别是对训练集来说,我们看到每个主题的推文数量存在明显差异:有些主题有超过 100 条推文,而大约一半的主题只拥有约 20 条推文或更少。
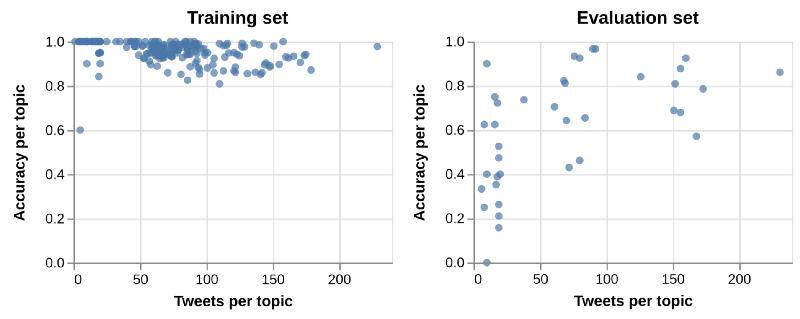
让我们回到仿射模型的测试,观察给定主题的推文情绪预测的平均准确率,结果表明,推文越多,主题的准确率就越高。
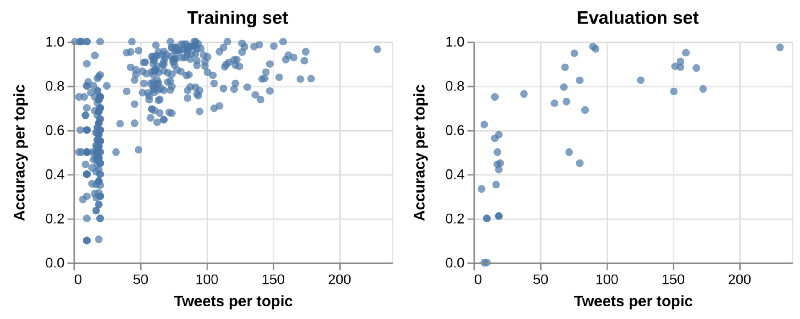
给定主题中推文情绪预测的平均准确率。有个明显的趋势是,具有更多相关推文的主题通常会获得更高的平均准确率。
出现这种趋势是有道理的:该模型从学习一种转换中受益匪浅,这种转换适用于包含更多推文的主题。但实际上,这并非我们想要的结果,因为这意味着模型可能不会很好地进行归纳。我们希望模型即使在看不见的主题上也能表现良好,对某些主题过拟合在这方面可能不会有什么帮助。
处理类似这样的类不平衡的一种方法是,通过类的频率的倒数来衡量模型对错误预测的惩罚。这意味着,对于频率较低的数据,模型会收到很大的误差,因此会更加关注这些错误。让我们看看,这将会如何影响模型的训练。
纠正情绪不平衡
重新训练模型,只使用情绪频率的倒数来惩罚错误,我们已经达到了更好的模型。好的模型。
NNML 上仿射模型的混淆矩阵,纠正训练集中的情绪不平衡。
对于训练集的所有情绪来说,对角线接近 100%。对评估集的预测也有所改进,尽管还存在很大的改进空间。
我们还看到训练集中的每个主题的准确率有所提高,尽管这并没有得到明确的鼓励。
NNML 仿射模型的平均主题准确率,纠正了训练集中的情绪不平衡。
有趣的是,评估集的性能似乎有所下降。一种解释可能是评估集中的大多数推文都有积极的情绪,为了更好地表现出消极和中立的情绪,模型牺牲了一些准确性。
纠正主题不平衡
接下来,我们来看看如果只使用主题频率的倒数来惩罚错误会发生什么。这也带来了训练集上更好的情绪预测,这可能是因为,无论与主题相关的推文数量有多少,对主题衡量的权重都是平等的,这将使得模型直面更多种的情绪。
NNML 上仿射模型的混淆矩阵,纠正训练集中的主题不平衡。
但是,要看真正的效果究竟如何,需要看每个主题的准确性。对于训练集来说,现在准确率与主题中的推文数量几乎无关,大多数主题都接近于 1。
纠正情绪和主题的不平衡
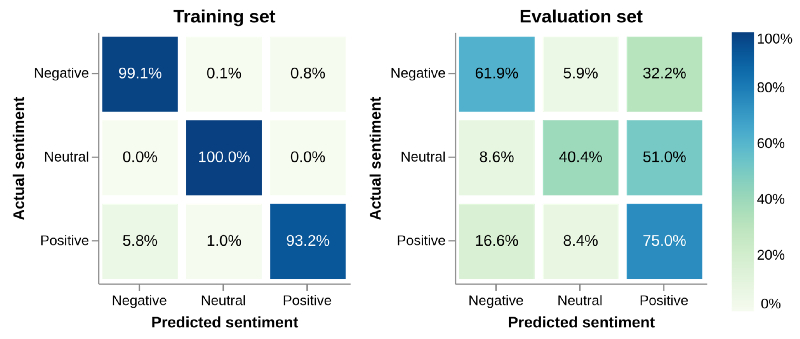
最终的模型将根据情绪和主题的频率来权衡错误预测的惩罚。这是通过简单地将主题频率和情绪频率的倒数相乘,并使用得到的数量作为权重来完成的。这将鼓励模型在训练期间能够平等对待所有情绪和主题。
这种方式生成的模型,似乎确实在考虑情绪和主题不平衡之间进行了很好的权衡。情绪预测相当准确,而且在评估集上的表现没有受到影响。
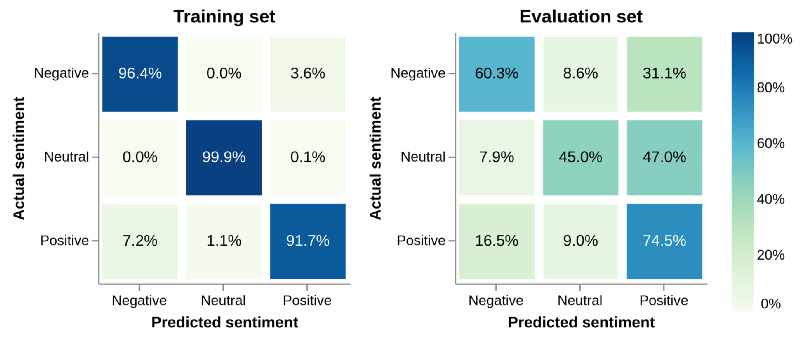
"NNML 上仿射模型的混淆矩阵,纠正训练集中的两种不平衡。
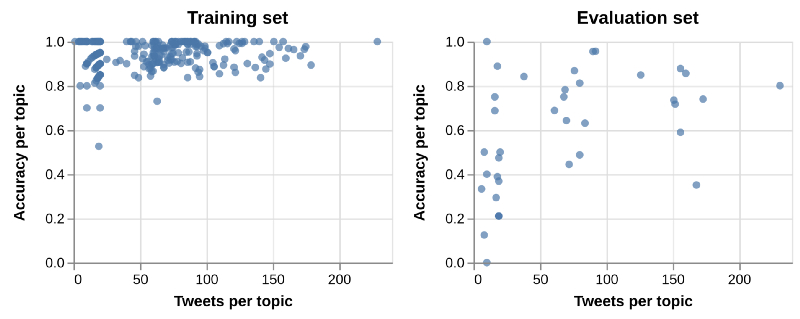
每个主题的平均准确率同样独立于主题相关的推文数量。
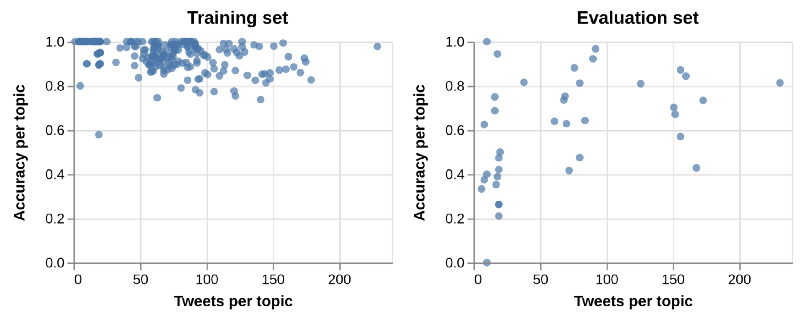
NNML 仿射模型的平均题目正确率,修正了训练集的两种不平衡。
虽然纠正类不平衡明显对训练集有所帮助,但评估集的表现仍然没有什么明显起色。但该模型似乎不能很好地推广到新主题,这可能意味着仿射变换的局限性太大,或者训练集不能很好地代表评估集。我们将在回顾最后的实验时再回过头来看这一点。
信息汇总
现在,在考虑到数据集中的类不平衡,以及已经决定嵌入和转换模型之后,我们准备测试这些模型。看看单词陷入能够收集到多少情绪信息。
该设置遵循标准的机器学习方法:我们用 10 组(fold)交叉验证(cross-validation)来训练模型,并评估测试集上每组的最佳模型。这给我们提供了一个衡量标准,当在(稍微)不同的数据集上训练时,我们可以预期模型的性能会有多大的变化。
包含一些基线实验总是一个好主意。这些应该是你可以想到的最简单的方法,如果你的高级模型无法击败这些方法,那么你就会知道出错了。我们选择了两个简单的基线:1)使用训练集中最频繁的情绪(我们将使用积极的情绪)作为任何推文的预测;2),使用训练集中的随即将情绪作为预测。
如下图所示,展示了对所有八个模型和两条基线进行训练以及对不可见测试集进行评估的结果。穿过数据点的垂直线表示 10 个交叉验证组的一个标准差。
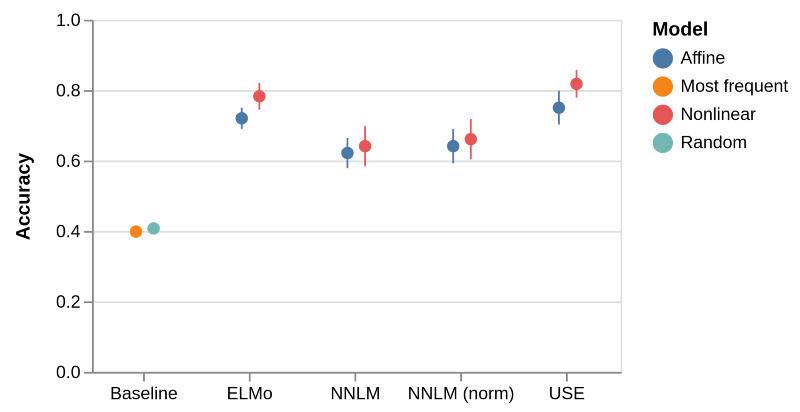
在这里,有很多有趣的观察等待我们去做。首先,在基线之上的任何嵌入的模型都有很大的改进。因此,正如所预期的那样,嵌入这个词捕获了可以用来推导推文情绪的信息。其次,转向 NNLM 嵌入,使用非线性模型似乎并没有什么改进。这很有趣,因为它表明了嵌入空间足够简单,仿射模型能够使用嵌入中所有可用的情绪信息。这与最新的嵌入方法 ELMo 和 USE 形成了对比。在 ELMo 和 USE 中,我们确实观察到在非线性模型的使用情况有所改善,这表明这些模型学习的嵌入空间更加复杂。对于 NNLM,归一化向量确实比非归一化向量有更好的表现趋势,但是在我们的实验中,效果并不显著。最后,虽然 ELMo 和 USE 都包含比 NNLM 嵌入更多的信息,但它们在这些实验中的表现却非常相似。USE 似乎通常包含比 ELMo 略多的信息,但也并没有多多少。然而,这仍然很有趣,因为 USE 嵌入空间的维数比 ELMo 空间要低得多,因此,模型训练速度要快得多。
我们实现目标了吗?
没有,绝对没有。关于单词嵌入的信息内容,还有很多有趣的问题需要回答。
例如,我们用三点量表(消极、中立、积极)来处理情绪。如果处理情绪要扩展到更细粒度的话,比如五点量表,就需要更多的嵌入。这些嵌入包含这么多信息吗?
询问是否需要巨大的嵌入空间也是合理的。ELMo 的嵌入是 1024 维,但信息可能嵌入在更低维度的空间中。嵌入空间的降维如何影响情绪预测?
在测试主题空间的两种不同变换时,我们发现,只有较新的嵌入才需要非线性变换。扩展转换的类型,包括创建一些更复杂的神经网络,以及测试哪些嵌入可以从哪些转换中获益,这将是一件非常有趣的事情。这可以让我们能够深入了解不同嵌入空间的复杂性。
结果
在这个项目中,我们想测试不同的单词嵌入对推文的情绪预测有什么样的影响。为此,我们构建了两个模型,在尽可能不干扰的情况下来预测情绪,从而使我们能够看到元是单词嵌入包含了多少情绪信息。
结果表明,无论新的还是旧的单词嵌入,确实都包含了关于情绪的信息,新的单词嵌入包含的内容要比旧的更多,这并不奇怪。结果还表明,对于较新的嵌入,主体向量的非线性变化的比仿射变换表现得更好,这表明这些空间比较旧的嵌入更加复杂。
总之,单词嵌入通常包含大量关于推文情绪的信息,而更新的嵌入包含的信息要多得多。它强调了高级嵌入模型在预测推文情绪方面的重要性,但这并不过分令人惊讶。
原文链接:
https://towardsdatascience.com/making-computers-understand-the-sentiment-of-tweets-1271ab270bc7

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论