
2019 年 5 月,美团正式推出新品牌「美团配送」,升级配送开放平台。那你知道支撑美团配送大脑的实时特征平台是如何建设的吗?如何实现每分钟生产千万级的实时特征?如何在 70w+QPS 的场景下实现 4 个 9 响应耗时在 50 毫秒的需求?本文将为大家介绍配送实时特征平台的发展历程,关键技术和实践经验。
配送业务介绍
1. 商业模型
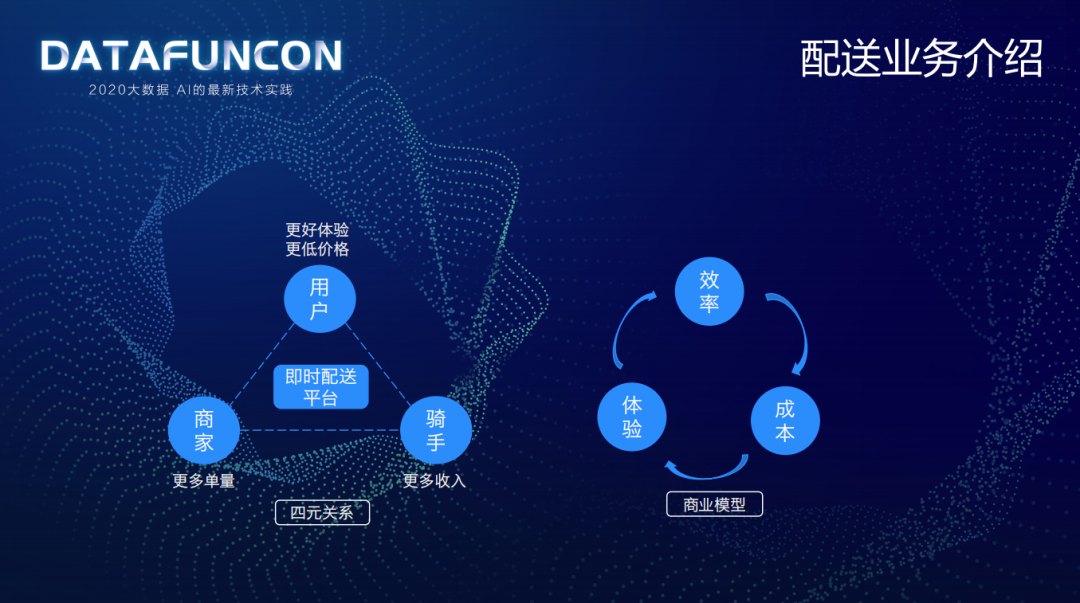
配送的业务最主要的就是一个履约的行为,将用户、商家和骑手关联起来,促进配送效率提升、用户体验提高、配送成本降低,从而形成一个闭环的商业模型。
即时配送平台核心职责就是调整好用户、商家、骑手三元的关系,用更低的成本为用户带来更好的体验,为商家带来更多的单量,为骑手带来更多的收入。
2. 履约模型
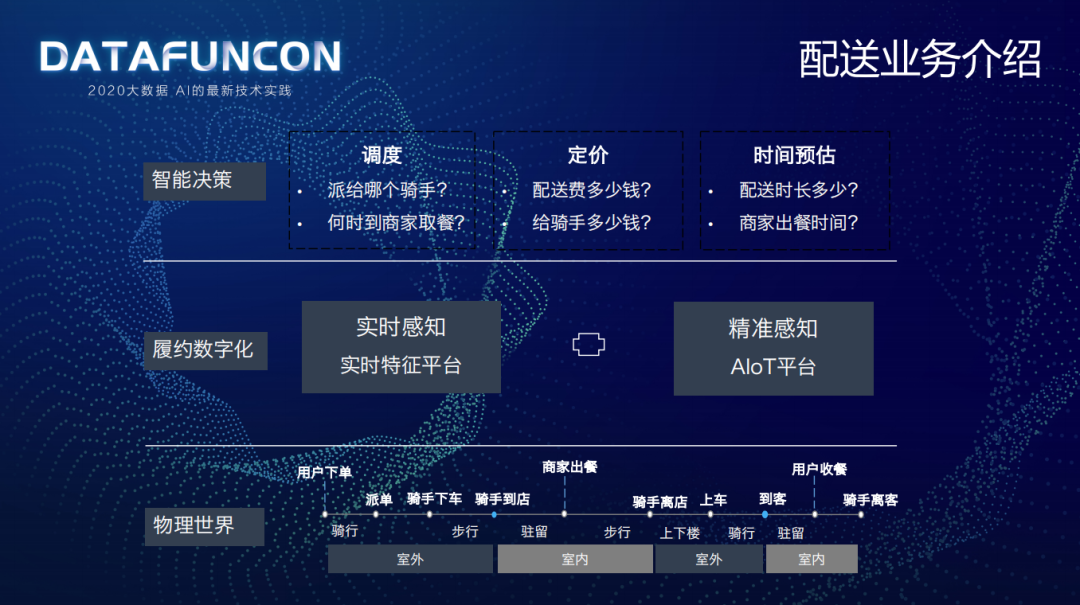
配送就是一个履约的过程,不像电商主要是线上完成,配送主要是线下完成履约。
物理世界中,一个运单的完成过程是从用户下单开始到用户收餐骑手离客为止,需经历一系列室内室外的场景——用户下单,系统派单,骑手室外骑行到目的地然后下车步行到商家,等待取餐驻留室内,商家出餐,骑手取餐离店后步行上车,室外骑行到用户目的地,下车步行上楼送餐,驻留室内等待用户收餐,最后用户收餐骑手离客。
可以看到物理世界是比较复杂的一个过程,那就需要智能决策系统来做一定的调度,派给哪个骑手?何时到店取餐?同时要做一个合理的定价,针对恶劣天气和爬楼梯等特殊情况收的费用肯定是不同的,收多少配送费?付给骑手多少配送费?最后还要给出一个合理的时间预估,配送时长是多少?商家多久可以出餐?
算法要做以上这些智能决策过程中,就需要做履约过程整个链路的数字化,通过实时特征平台来做实时感知的数字化,通过 AIoT 平台完成如骑手骑行、爬楼等行为精准感知的数字化;本次主要介绍实时感知数字化的实时特征平台。
实时特征平台建设
1. 背景

2017 年开始做实时特征平台建设的背景是为了解决两大问题:
千万订单履约过程智能化:最开始履约过程是由简单的规则构建的,现在要实现从规则配置化向智能化过渡,包含智能调度、ETA 时间预估、配送费定价和爆单等场景;算法实时决策需要分钟级数据的时效性。
现有开发模式无法及时响应:当时实时特征开发散落在 4 个业务团队,进行烟囱式开发,流程长、效率低,存在一些重复建设;实时特征开发耦合在业务系统中,稳定性风险较高。
2. 目标 &规划

基于建设背景,设定了建设目标——建设分钟级时效的实时特征平台,多粒度刻画履约过程,提升研发效率,降低研发成本。
基于建设目标,设定了三阶段的演进计划:
第一阶段——系统化:和业务系统划清边界、确定实时平台架构;将系统搭建起来,验证是否可以支撑业务场景;将新增特征进行收口管理。
第二阶段——规模化:建设高可用的系统,支撑更多的实时特征,将旧特征“绞杀”进行统一收口管理。
第三阶段——平台化:将实时计算整合,进行完善的服务治理。
3. 系统化
① 设计思路
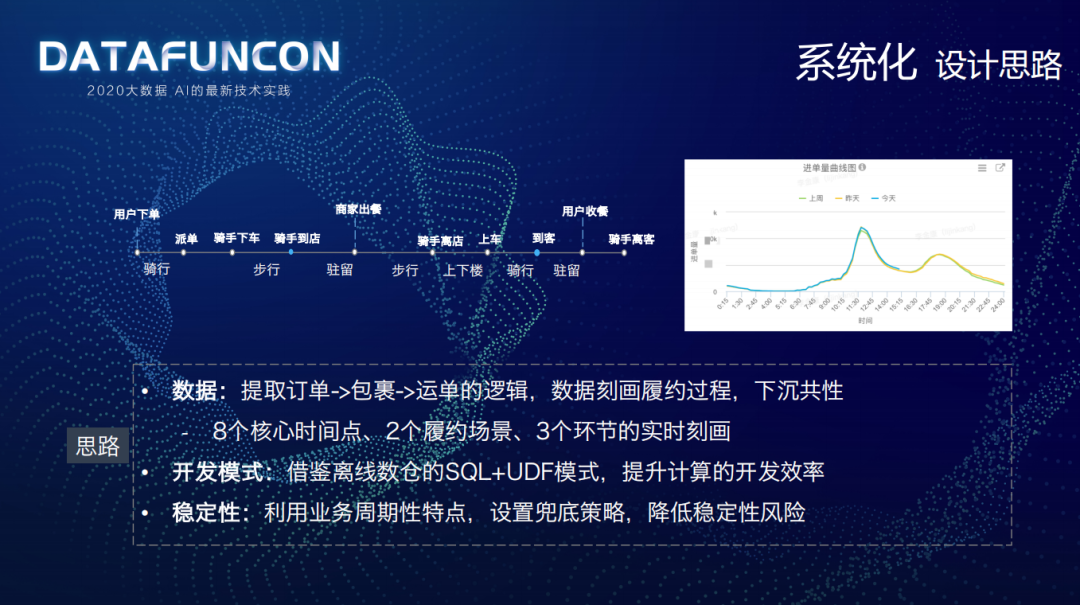
② 整体架构

进行系统化整体架构设计时,先制定了左侧的架构标准:
流程标准化:从数据输入,加工计算到数据输出做了一个流程的标准化。
数据分层,将共性沉淀下来。
特征兜底,降低风险。
基于架构标准,最终制定了右侧的架构图,共分为 6 层:
数据源层:主要有包裹表、运单表、骑手表以及运单扩展表。
数据层:ODS 层将数据进行清洗和转换,在 DWD 进行维表建模和合流,最后形成索引数据和明细数据的宽表。
计算层:通过标准化的 SQL 对宽表数据进行计算。
存储层:存储计算层输出的特征数据。
服务层:通过实时特征服务将存储层数据统一输出应用层应用。
应用层:主要有 ETA 时间预估策略服务、调度策略服务、保单策略服务以及定价策略服务。
管理系统:主要就是一些元数据的管理,比如数据源、特征口径以及存储的管理;还包含兜底策略管理,降级模块,可以对单特征降级,也支持批量降级的核按钮。
③ 数据层关键点
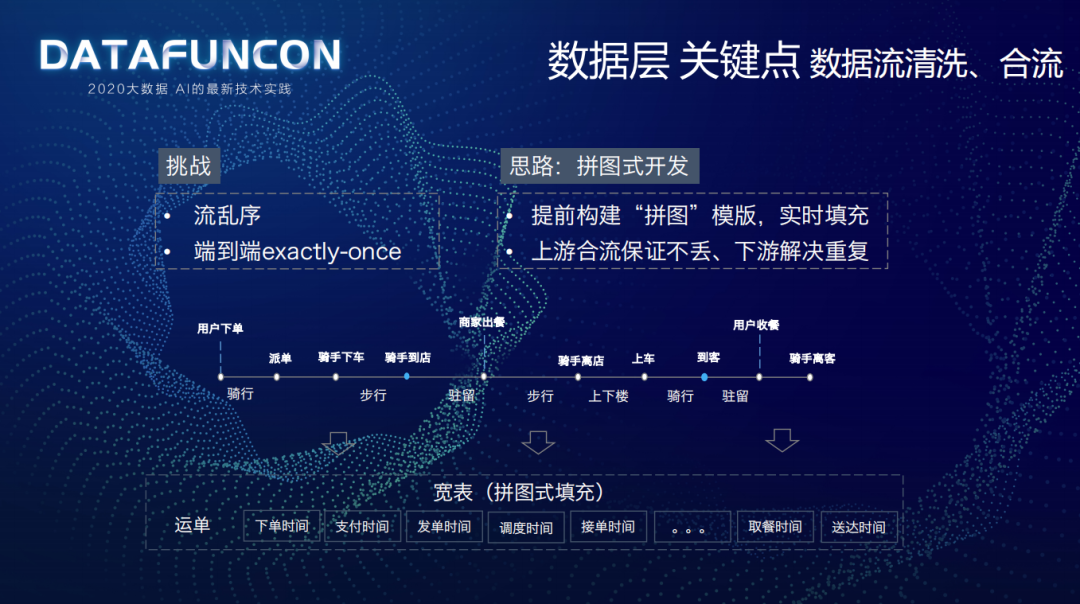
做实时数据系统大都会碰到两个挑战:
流乱序问题
端到端的 Exactly-Once 语义保障
针对以上挑战,结合配送的实际业务场景给出对应的解决思路:
提前构建“拼图”模板,实时填充:结合物理世界的配送履约过程,构建业务宽表,涵盖下单时间、支付时间、发单时间、调度时间、接单时间、取餐时间、送达时间等,根据实时数据流填充模板宽表,避免各数据流填各自的字段,避免乱序问题。
上游合流保证不丢,下游解决重复问题。
④ 计算层关键点
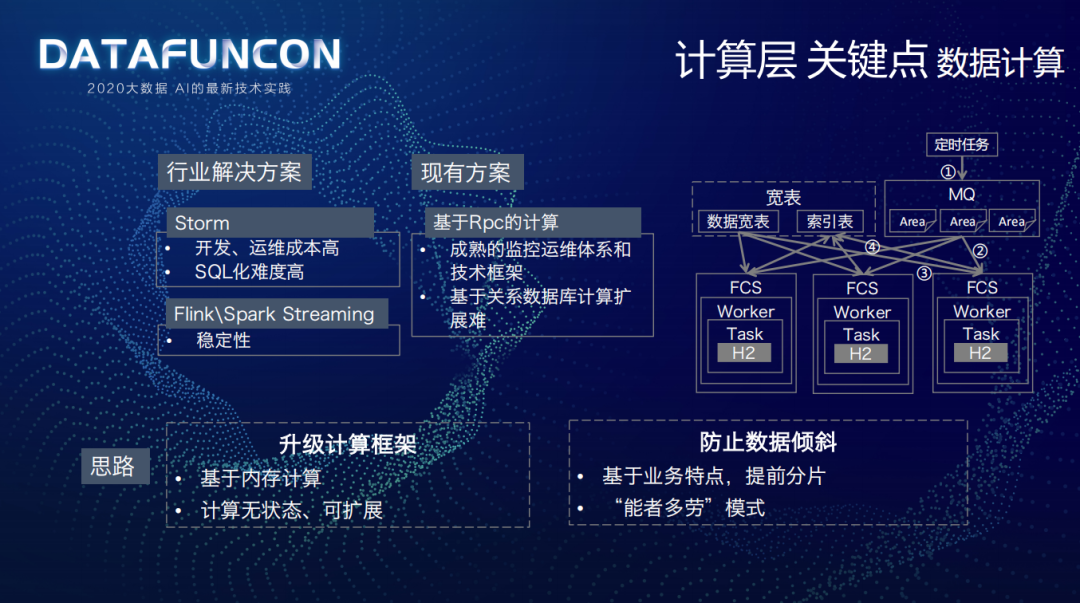
2017 年调研了一些行业解决方案:
Storm 开发运维成本较高、SQL 化难度高。
Flink 没有现在这么火,稳定性无法保障;Spark Streaming 不是公司运维的关键点,对于线上场景的稳定性也是无法保障。
耦合在业务系统内部的基于 Rpc 计算在公司有成熟的监控运维体系和技术框架,但有一个问题是,该场景主要是基于关系型数据库进行计算的,例如 MySQL,是存在单点问题的,扩展较难。
因为对基于 Rpc 的计算是相对有把握的,所以首先升级计算框架,将原有基于关系数据库计算升级为基于内存计算,计算是无状态、可扩展的;为了防止数据倾斜,基于业务特点进行提前按区域分片,采用“能者多劳”模式,计算比较快的节点就多计算一些。
接下来介绍下计算层的核心逻辑:
首先,数据层形成的宽表,主要存储在外存中,例如运单包裹合流信息,那它如何和区域 dim 起来?就是通过索引表,将区域和运单关联起来。
其次,全国有多少区域是确定的,每隔一分钟会通过定时任务将全国的区域放到 MQ 中。
最后,就是实时特征计算服务 FCS,每个计算节点有多个 worker,每个 worker 中有 task 会做基于内存数据库 H2 的计算,当收到 MQ 的区域信息后,会拉取对应区域的宽表数据,在 H2 中计算实时特征,计算完成后会继续计算下一批的实时特征。
⑤ 阶段成果

建设系统化的阶段成果主要有:
刻画粒度:维度上主要有商家和区域;粒度上主要有订单、运单、包裹。
效率:特征上线由原来的多天提升到分钟级,收口新特征有 60 多个。
接入量:接入 9 个算法模型、15 个算法版本。
稳定性:通过特征兜底策略避免了 Kafka 集群故障,系统没有 S 级事故。
4. 规模化
① 数据服务挑战 &思路

第二阶段规模化建设的背景就是推动实时特征收口。
在外卖的图中会显示每单的配送时长,看上去这是一个指标,但实际上这个指标从外卖到配送经过的链路是很长的,最少有五六个节点,虽然只是一个 ETA 的预估时间,但是涉及到的特征可能有 60 个左右;另外,商家列表页会几百个商家,还要做排序,这样对实时特征的压力非常大,对实时特征的查询性能有更高的要求,通常 200 毫秒的延迟用户就会感知到。所以实时特征计算就会面临两个问题:
稳定性要求高:交易链路
性能要求高:50ms 响应时间
解决以上问题的主要思路有:
定制度:“135”制度,1 分钟响应问题,3 分钟定位问题,5 分钟恢复计算
保稳定:做全链路的监控和降级
提性能:满足 50ms 的响应时间
② 稳定性建设框架
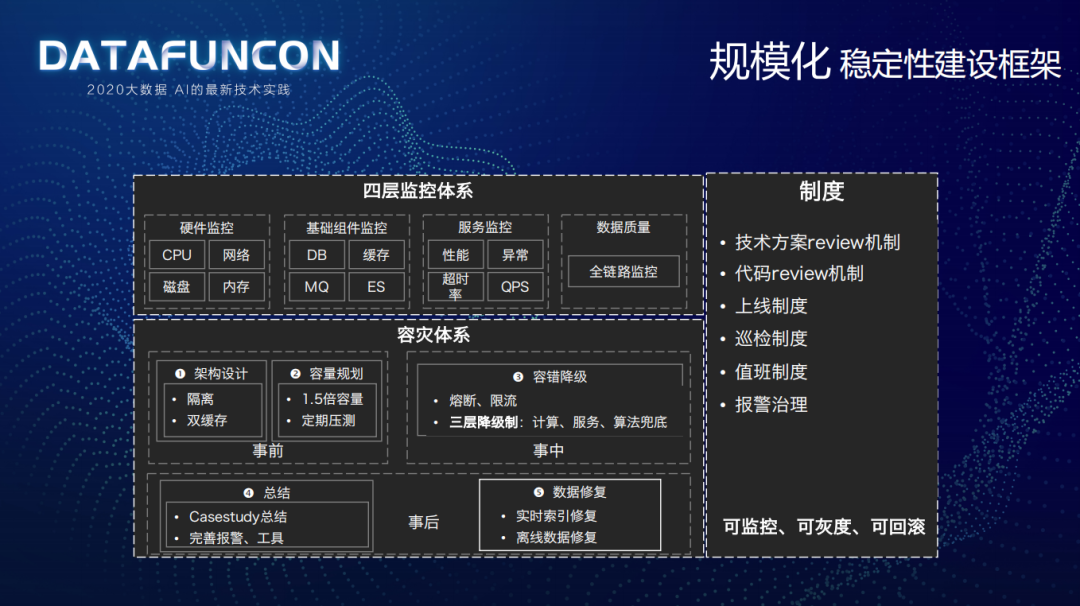
结合实际问题,制定了稳定性建设的框架:
四层监控体系:硬件监控(CPU/网络/磁盘/内存)、基础组件监控(DB/MQ/ES/缓存)、服务监控(性能/异常/超时率/QPS)以及全链路数据质量监控。
容灾体系:事前会做隔离、双缓存的架构设计,1.5 倍容量规划以及定期压测;事中会做熔断、限流,三层降级(计算、服务、算法各层都有各自的降级兜底策略)的容错降级机制;事后主要是做 CaseStudy 的总结以及报警工具的完善,同时还要对实时索引和离线数据进行修复。
制度:有完善的技术方案 review 机制、代码 reiview 机制、上线制度、巡检制度、值班制度以及报警治理等制度,最终形成一套可监控、可灰度、可回滚的技术体系。
③ 稳定性建设:拆分、隔离

在规模化稳定性建设的拆分和隔离上,主要做法如下:
服务链路:遵循按照业务场景垂直拆分、一套代码部署隔离的服务/存储拆分原则,将实时特征服务拆分为 ETA、调度、定价、爆单四个服务,在物理环境上进行隔离,但是使用的是同一套代码。
计算链路:通过双机房(rz、gh)热备、三种场景集群(监控、运营、履约)对 Storm 集群进行拆分;使用美团自研的多机房 Mafka 集群做了 MQ 容灾,替换了单机房 Kafka 集群;对于数据收集的 canal 做了隔离,离线、实时、zk 隔离,并做了多机房的容灾。
④ 数据质量
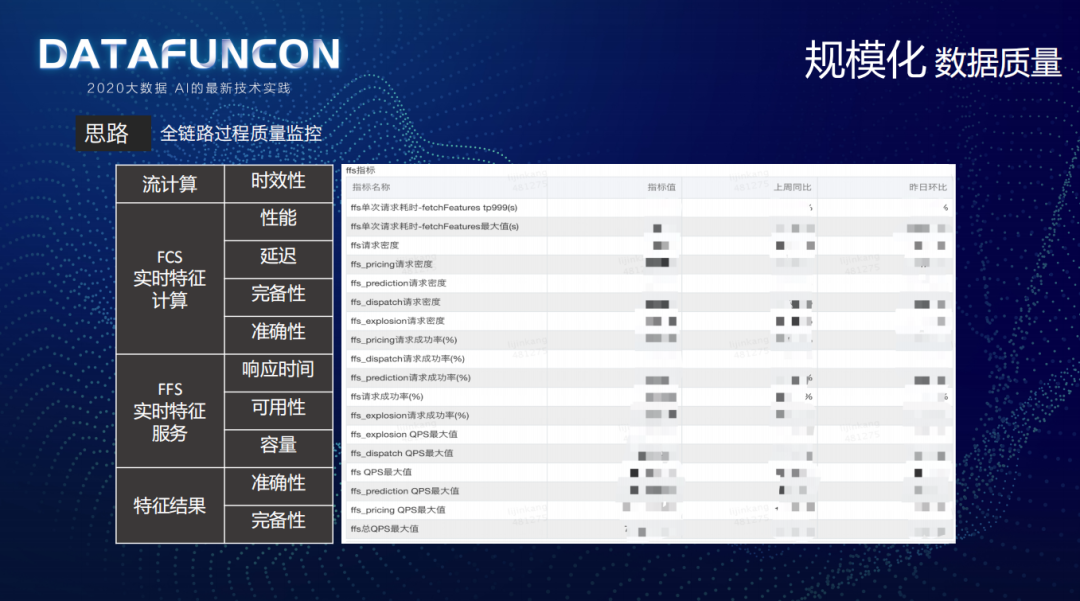
在数据质量上做了全链路过程质量的监控:
流计算:监控时效性;
FCS 实时特征计算:监控性能、延迟、完备性、准确性;
FFS 实时特征服务:监控响应时间、可用性、容量;
特征结果:监控准确性、完备性。
例如:数据清洗中会关注消息处理耗时;FCS 服务会关注 event 流入总量、sql 流入总量、内存表记录数、空值特征比例、单批次计算耗时;宽表会关注宽表记录数、未填充字段占比、不合理记录占比;特征质量会关注骑手平均负载最大值发生的时间、区域特征个数 95 分位数、商家平均特征个数、骑手负载中位数、众数等;FFS 服务会关注每次请求耗时、请求密度、请求成功率和 QPS 等。
⑤ 查询服务性能优化
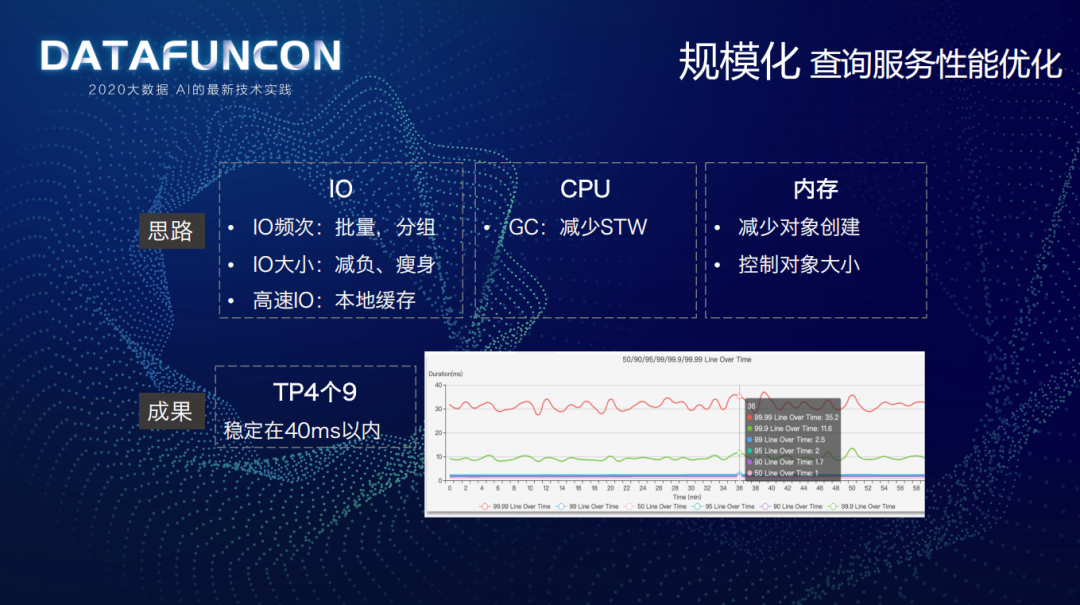
做查询服务性能优化主要有三个思路:
IO:使用批量、分组方式降低 IO 频次;使用 PB 格式替换原 JSON 格式、去除无用字段等减负瘦身方式来降低 IO 大小;使用高速的本地缓存。
CPU:减少 Stop The World 时间,使用 G1 替换了原来的 CMS。
内存:减少对象创建,控制对象大小。
最终成果是 TP4 个 9 的耗时稳定在 40 毫秒以内。
⑥ 建设成果

规模化的建设成果主要有:
接入量:接入 100+算法版本,200+实时特征全部收口,调度、ETA、定价、爆单策略 21 个核心服务全部接入。
性能:60w+QPS 下,4 个 9 的响应时间在 50 毫秒以内;每分钟生产 1000w+特征,计算耗时小于 40 秒;计算、服务、存储都支持水平扩展。
稳定性:应对了 GH 机房断电故障,且没有 S 级事故。
5. 平台化
① 背景 &策略

平台化的建设背景是需要满足更多粒度的特征需求,第一类是降雨、降雪等天气等级等的区域维度以及骑手轨迹等的骑手维度;第二类是通过算法实时加工的特征,如预计出餐时长和预计进单量。
针对以上背景,有两大策略来解决:
开放策略:事件驱动,开放履约事件,让业务平台可以根据开放平台自己计算一些特征。
集成策略:建设数据收集通道,汇总第三方特征,业务通过收集通道将自己计算的特征上报汇总起来;将类似于骑手轨迹这种动态维度,屏蔽了计算引擎,引入了 Flink 进行动态维度计算。
② 架构升级
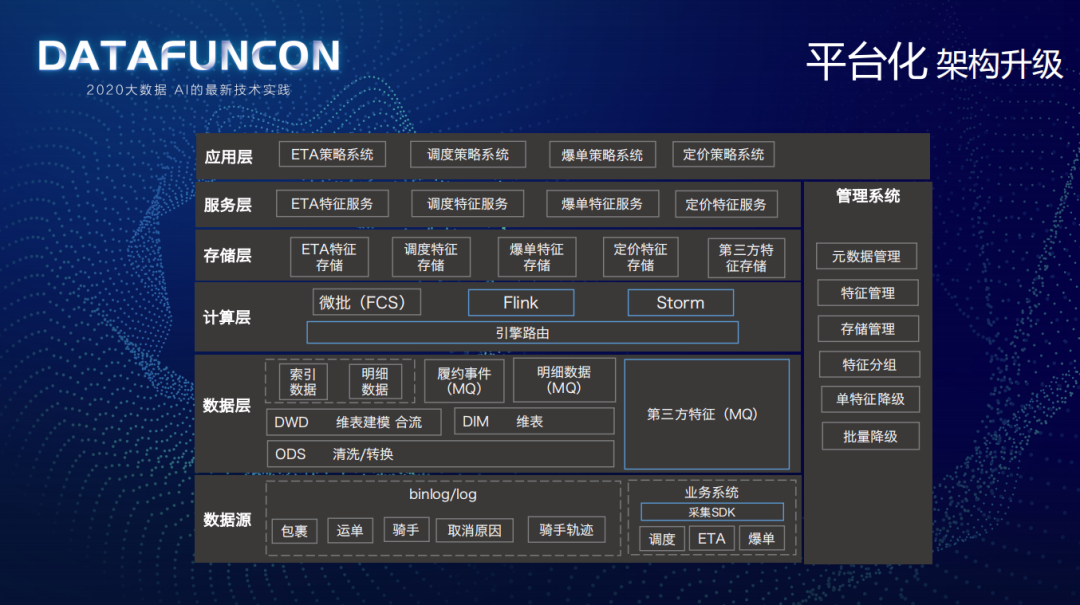
上图是在平台化建设过程中升级后的架构,蓝色部分是新增的:
数据源层新增了采集 SDK:业务平台可以将自己算的特征通过 SDK 上报到 MQ 里面,然后通过计算引擎落到第三方特征存储,通过服务层提供给需求方。
计算层引入了 Flink 和 Storm,建设了一层引擎路由,屏蔽掉了底层的计算引擎,让用户使用无感知。

数据粒度:新增了 GeoHash、AOI 的维度;新增了天气、轨迹、预测类特征的粒度。
接入量:实现了 200+第三方特征自助化上报,履约事件校友对接了 ADS、ETA 等服务。
稳定性:无 S 级事故。
③ 建设成果

实时特征平台的建设成果有:
业务效果:计算 400+实时特征,覆盖了 ETA、爆单、调度、动态定价等配送线上策略;实时特征成为配送履约的一环,对算法策略的效果提升显著。
效率提升:开发周期从多天降低到分钟级别。
性能和稳定性:每分钟处理上亿条数据;在 70W+的 QPS 场景下,实时特征服务 4 个 9 响应时间在 50 毫秒;没有 S 级故障。
未来规划

配送数据方向的未来规划有:
数据治理:除了实时特征外,还有活动类、运营类的实时数据,因此未来考虑实时特征以及其他场景的数据与实时数仓进行融合;虽然目前做了一些端到端的监控,但大都是单节点的监控,未来会做从数据源到最终提供服务的全链路的数据质量建设。
降低研发成本:可以看到目前架构中使用的计算引擎开发运维成本有点高,有 FCS 微批处理、Storm、Flink,未来会考虑将计算引擎整合,降低开发运维成本。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
李金康,美团高级技术专家。2013 年加入美团,现任美团配送数据组数据应用组的负责人,长期负责配送数据架构的系统开发与架构升级,主导配送实时数据建设、配送 BI 系统建设、实时特征平台建设,为全国海量骑手及各级管理团队和算法团队提供信息化支持。拥有多年互联网研发及技术管理经验,在大数据、高并发、高可用架构设计等领域积累了丰富的经验。
本文转载自:DataFunTalk(ID:datafuntalk)
原文链接:美团配送实时特征平台建设实践




