
整理 | Tina
1 月 2 日,OneFlow 创始人袁进辉(老师木)有了新动向,其创立的新公司“硅基流动”正式进入公众视野,这是一家关注 AI 基础设施层的公司。
袁进辉是 AI 架构界的资深人才,他于 2017 年创立了一流科技 OneFlow。去年大模型爆火后,光年之外收购了 OneFlow,此后美团又收购了光年之外。
实际不久前,袁进辉就已经在朋友圈宣布了 OneFlow 团队近期重新创业的消息。
袁进辉表示,重新创业的计划目标是瞄准大模型推理成本问题。
“计划第一个推出的产品是大模型推理和部署系统,解决 AIGC 和 LLM 行业推理部署成本太高的痛点,我们判断这是大模型时代最好的商业机会之一。”
提高大模型推理和部署的效率已成为大模型时代提供基础设施服务的重要课题。在依赖数据、算法和算力的支持下,大模型的能力才能得以充分展现。数据显示,在过去的 4 年里,大模型的参数量以年均 400%的复合增长,而 AI 算力需求增长超过 15 万倍。传统以 CPU 为中心的计算基础设施已经无法满足大模型和生成式 AI 的新需求。由此引发的成本不断膨胀,成为大模型企业负担沉重的账单。因此,一些领先的厂商正寻求降低成本的方法。
硅基流动提供的方案,跟云厂商之间“本质一样,取决于谁做的更好。而实际上我们的确做得也更好。现在 AI 算力很分散,公有云只占其中的一小部分,还有就是跨云和多云。”袁进辉回复 AI 前线询问时表示。
“Stable Diffusion 进行了公开评测,反馈很好。在大模型产品初次推出时,我们进行了内部测试,并与国内外产品进行了比较,结果显示我们的产品具有明显的优势。我们在海外获得了一批付费客户,其中包括 stability.ai,也覆盖东南亚、巴基斯坦、中东等地。”
“海外市场主要比拼的还是产品力,”袁进辉表示道,“目前我们正在做大模型推理方案,并且很快会推出极具竞争力的产品,性能上比市面上现有方案会有数量级的提升。”
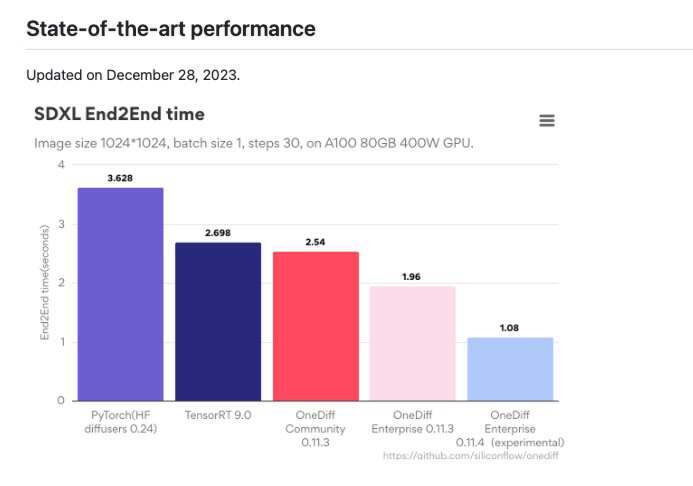
截图来源:https://github.com/siliconflow/onediff
袁进辉因读书时成绩优异,保送清华大学直博生,师从人工智能领域张钹院士。期间多篇论文在国际顶级会议上发表,在竞争激烈的国际技术评测(TRECVID)中连续多年名列第一。2013 年,加入微软亚洲研究院(MSRA),在 MSRA 期间,专注于研发大规模机器学习平台,以出色的科研和工程综合能力,发明了世界上最快主题模型算法 LightLDA 及分布式训练系统:只用几十台服务器就能完成之前需要数千服务器才能完成的训练任务。之后创业并打造了分布式学习框架 oneflow。
对于这次创业,不少技术圈人士给予了高度评价:“从 LightLDA 到 siliconflow,袁老师教了我们太多,这次 siliconflow,我相信还能教我们不少技术,支持就对了!”“分布式系统软件研发难度大,做好技术创新和工程开发还不够,还要懂应用负载、生态系统、商业模式等等。”
而且,袁进辉一直关注的领域都相当前沿和准确。用他自己的话说,在深度学习开始火爆之前几年,他就已经涉足神经网络领域(2008 年开始研究计算神经科学)。在大模型成为热点之前几年,他就开始构思面向大模型的深度学习系统(2015 年从 MSRA 开始,并于 2016 年创业,一直贯彻这个理念)。
AI 前线早于 2017 年就曾跟他探讨过算力对 AI 的重要性,如今到了生成式 AI 时代,算力利用问题愈加凸显。我们正好可以借此机会重温一下他的观点:
InfoQ:为什么计算力会成为深度学习的一个突破方向?
老师木:首先,计算力是极其关键的一项支撑技术。最近发生的人工智能革命通常被认为是三驾马车驱动,数据,算法和计算力。与上世纪九十年代相比,深度学习在算法原理上并无二致,在数据和计算力方面进步更大,各行各业积累了大量的优质数据,GPU 作为新的计算手段引爆了此次深度学习的热潮。
其次,计算力方面还有现成的红利可吃,相同的算法,如果能用上更多的数据,或者用更大规模的模型,通常能带来效果的显著提升,能不能做的更大取决于计算力的水平。
再次,算法和原理的研究进展依赖于计算能力,好的计算力平台可以提高算法和原理研究的迭代速度,一天能实验一个新想法就比一星期才能实验一个新想法快的多。有些理论问题本身是一个大规模计算问题,譬如神经网络结构的自动学习等价于在一个超大规模假设空间的搜索问题,没有强大计算力的支持就只能停留在玩具数据上。深度学习是受生物神经网络启发而设计出来的,现在人工神经网络的规模还远远小于人脑神经网络的规模,人脑有上千亿神经元细胞,每个神经元平均有成千上万的连接。
最后,如何在低功耗约束下完成高通量的计算也是制约了深度学习在更多终端上应用的一大因素。
InfoQ:计算力具有什么样的商业价值?
老师木:一方面,计算力的商业价值体现在它是数据驱动型公司的大部头营业支出(硬件采购,人力成本等)。数据驱动型业务的完整链条包括数据收集,预处理,深度分析和在线预测,无论是私有部署还是上公有云,建设高扩展性的基础设施等支撑技术,都是一笔不可忽视的开销。另一方面,计算力也是数据驱动型公司获得竞争优势的关键,人工智能可提高公司业务效率,而计算力又可提高人工智能的效率。目前,围绕着计算力已经出现了诸多成功的商业模式,譬如公有云,面向私有部署的商业技术服务,深度学习加速器(GPU,DPU)等。
InfoQ:计算力在技术上有哪些瓶颈?
老师木:从硬件看,我们现在使用的都是冯诺依曼结构的计算机,它的主要特点是计算单元和存储单元分离,主要瓶颈表现在摩尔定律(Moore’s law)的失效和内存墙(Memory wall)问题上。克服摩尔定律的主要途径是增加中央处理器上集成的核心(core)数量,从单核,多核发展到现在众核架构(GPU, Intel Xeon Phi),但芯片的面积及功耗限制了人们不可能在一个处理器上集成无穷无尽个核心。内存墙的问题是指内存性能的提升速度还赶不上 CPU 性能的提升速度,访存带宽常常限制了 CPU 性能的发挥。纯从硬件角度解决这些瓶颈问题,一方面要靠硬件制造工艺本身的发展,另一方面可能要靠新型的计算机体系结构来解决,譬如计算和存储一体化的非冯诺依曼结构计算机。除了高通量的计算,在电池技术没有大的突破的前提下,终端应用场景(物联网,边缘计算)里低功耗也是计算力的一项重要指标。当前,深度学习专用硬件创业如火如荼,有可能会被忽视的一点是:对突破计算力瓶颈,软件至少和硬件一样关键。
InfoQ:为什么软件会成为计算力突破的关键?
老师木:计算力的基础设施要满足上层用户对易用性,高效率,扩展性的综合需求,仅有硬件是不够的。一方面,数据科学家和算法研究员不像系统研发工程师那样深刻立刻硬件的工作机理,不擅长开发释放硬件计算潜能的软件,对数据科学家最友好的界面是声明式编程,他们只需要告诉计算力平台他们想做什么,具体怎样算的快要由软件工具链来解决。另一方面,尽管单个众核架构的协处理设备(如 GPU)吞吐率已远超 CPU,但出于芯片面积 / 功耗等物理限制,任何一个单独的设备都无法足够大到处理工业级规模的数据和模型,仍需由多个高速互联的设备协同才能完成大规模任务。出于灵活性需求,设备之间的依赖必定由软件定义和管理,软件怎样协调硬件才能提高硬件利用率和释放硬件潜能极具挑战,至关重要。在相关领域,软件定义硬件已是大势所趋:上层软件决定底层硬件的发展方向,底层硬件要取得成功离不开完善的上层软件生态。
InfoQ:长江后浪推前浪,这样一个先进的技术架构生命力会有多久?
老师木:首先,我们可以探讨一下深度学习的范式还有多久生命力,毕竟技术架构应需求而生。可以从这几方面看:从数据流计算模型是生物体采用的信息处理机制,是人工智能的效仿对象;人工神经网络已经在多个领域取得成功,而且深度学习本质上还是统计学习理论,利用算法在数据种挖掘统计规律性,这种学习机制的本质不会变化;深度学习算法便于利用并行硬件的威力,算法和硬件的天作之合,还看不出取代它的必要。其次,从计算机体系结构及硬件演化方向上看,软硬件结合的数据流计算机代表着突破摩尔定律和内存墙限制的方向。
InfoQ:是不是只有大公司才需要这样的基础设施?
老师木:并不是。目力所及,这样的基础设施已经不是大公司的独享的专利,拥有数十台服务器的中小企业,大学研究院所比比皆是。数据驱动是一种先进的生产力,所有行业最终都会变成数据驱动,每个行业的每个公司的数据都在积累,每个公司对数据分析的需求都在进化,从浅层的分析到深度分析,这个大趋势呼之欲出不可逆转。十年前,会有多少公司需要 Hadoop,现今几乎所有的公司都要用到 Hadoop。历史一再证明,无论计算能力发展到多强大,应用总能把它用满。多年以前,有人还觉得 640K 内存对于任何人来说都足够了,今天 64G 的内存都开始捉襟见肘,一辆自动驾驶测试车每天收集的数据达数 TB 之多。从来不是强大的计算力有没有用的问题,而是计算力够不够用的问题。
更多阅读:
微博技术大 V 老师木:软件平台是深度学习计算力突破的关键(https://www.infoq.cn/article/software-platform-deep-learning-compute-capability)
让 AI 简单且强大:深度学习引擎 OneFlow 技术实践(https://www.infoq.cn/article/vwLNsabkqDpr*oRDdgN5)




