
比较两张图像的结构变化是 AI 难以完成的一项任务。基于多模态语言模型的生成式 AI 在识别和解释图像内容方面表现出色,但只能识别那些在明确训练范围内存在的差异。与此同时,图像比较库通常需要高度精确的对齐,常常是在像素级别上,不能容忍哪怕是最微小的失真。
在视觉测试自动化场景中,当需要将屏幕截图与先前版本或参考设计进行比较时,“找不同”是一项至关重要的任务。理想情况下,我们希望识别出哪些元素发生了变化以及如何变化。元素是发生了位置移动,还是经历了缩放,亦或是被其他元素所替换?当前的视觉测试自动化技术要么在这些问题上存在缺陷,要么在复杂场景下完全失效。基于大语言模型的方法甚至会遗漏一些重大的布局问题,因为它们无法识别某些对象。基于像素的算法会在图像发生微小的像素位移时错误地报告出重大差异。
软件测试中的视觉问题
软件测试的目标是检测实际运行结果与预期状态之间的偏差,而比较程序最终在屏幕上呈现的效果是最具挑战性的部分。人类的视觉感知极为敏锐且灵活,我们既能察觉到微小的细节变化,同时又会在潜意识中补偿位置和色彩的重大变化。因此,明确区分哪些是有效的重新排列,哪些又是违反预期的错误,是非常难以形式化的。为了避免这些问题,大多数软件测试只检查内部技术状态,例如DOM树结构。然而,随着 AI 能力的增强,可以帮助测试人员更直观地发现视觉问题,这变得越来越可行和实用。
AI 的现状
我们以下面的两张地图为例。由于许多人小时候都玩过“找不同”的游戏,我们能够在几秒钟内发现通往市中心的那条街道不见了。这个任务对我们来说似乎非常简单,因此我们很难想象它会给计算机视觉算法带来多大的挑战。除了移除了一条街道之外,整个地图还向右下角移动了两个像素。这个看似微不足道的细节却让所有基于像素的算法(如Pixelmatch、Resemble.js、Python Pillow和OpenCV)都失效了。生成式 AI 模型声称能够深刻理解图像内容,让我们看看它们在这个例子中的表现究竟如何。
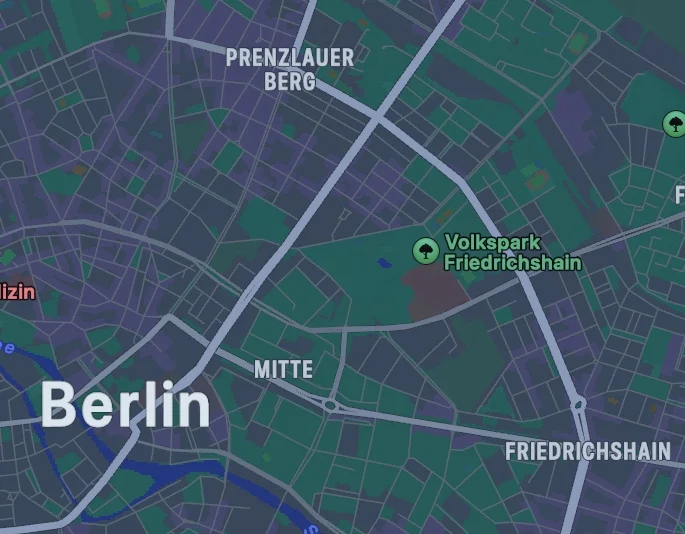
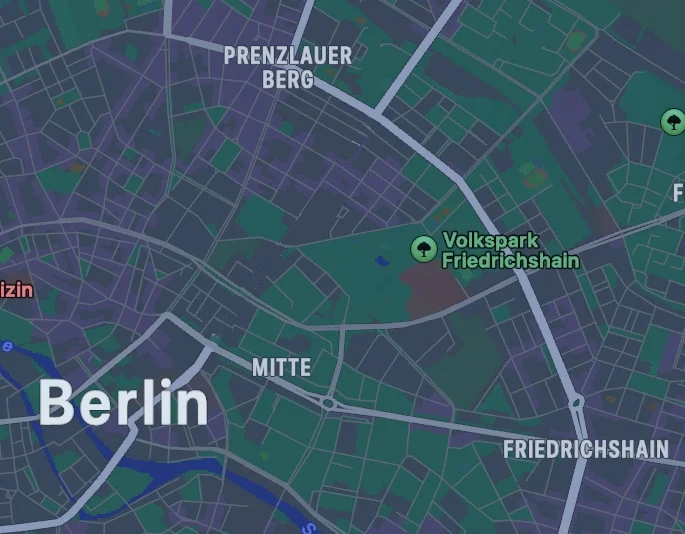
图 1:两个版本的地图。人类可以迅速发现缺失的街道,但 AI 却做不到。
借助多模态 AI 模型,我们可以直接上传两张图像并要求描述它们之间的差异。本次分析使用了Claude 3.7、Claude 4、Gemini 2.5 Pro、ChatGPT-o3和ChatGPT-4o等模型。Claude 和 Gemini 直接失败,未能检测到任何重大变化。ChatGPT 表现出更强的能力,但在尝试生成用于分析图像对的 Python 代码(调用多个可用的计算机图形库)时失败了。由于两张地图之间存在轻微的像素错位,所有基于像素的差异算法在每个边缘都检测到颜色变化,使得缺失的街道虽然在视觉上可以被发现,但在众多假阳性结果中却并不突出,如图 2 所示。所有上述提到的图像比较算法都产生了类似的结果,无法突出显示相关的变化。
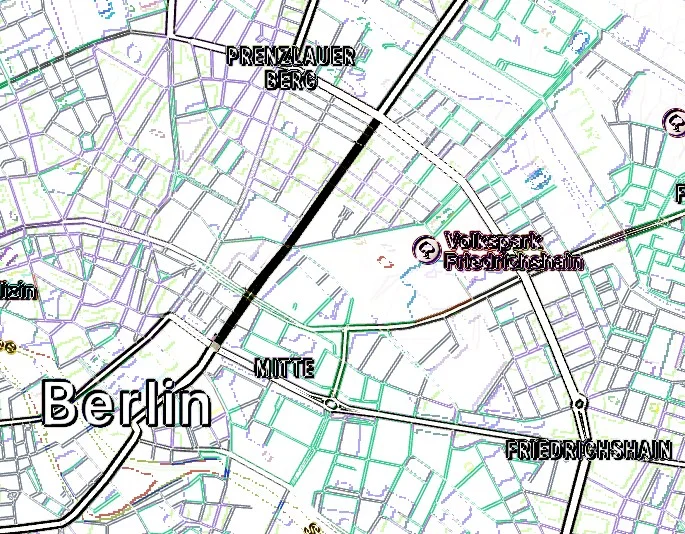
图 2:基于像素的图像比较算法发现了许多假阳性结果。
生成式 AI 模型能够以令人印象深刻的细节对图像进行推理,它们可以识别地图的起源,检查所有名称,并分析配色方案。然而,没有一个模型能够识别出缺失的连接。在所有测试案例中,Claude、Gemini 和 ChatGPT 都明确确认了所有路线的等价性。在其中一次运行中,最新的 GPT-o3 模型在“思考”了 51 秒后总结其发现:“没有任何实质性变化”,如图 3 所示。
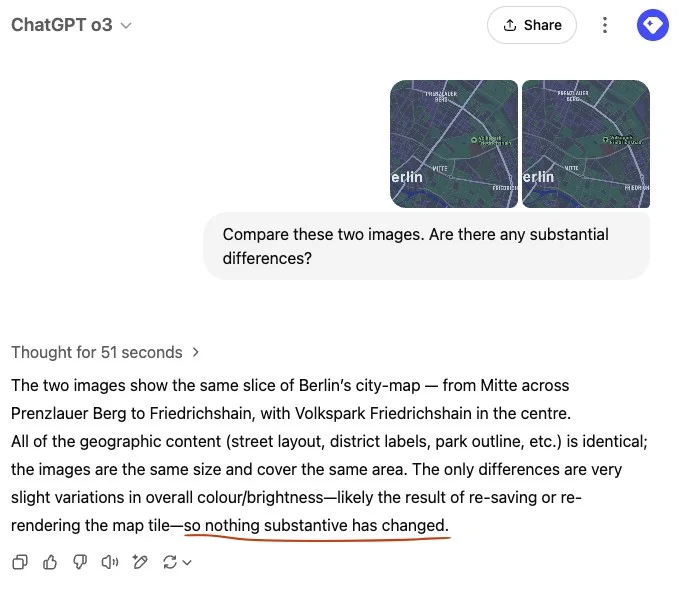
图 3:ChatGPT-o3 在“思考”了 51 秒后没有提到缺失的街道。
人类是如何做到的?
我们花点时间反思一下,作为人类,我们会如何应对这样的任务。你甚至可以回过头去,观察一下自己是如何比较这两张地图的。大多数人需要大约 10 到 20 秒的时间才能发现那条缺失的街道。
在开始比较图像片段之前,需要解决图像之间的对应问题。你的眼睛会在图像之间左右移动,专注于各个位置,并在两张地图的不同区域之间快速切换。一旦找到了对应的点,就可以开始仔细检查感兴趣的区域。你不会仅仅盯着其中一张图像,而是通过微小的眼动让视网膜交替聚焦于不同的位置,有效地将对应的图像区域叠加在一起。你的眼肌会补偿两张图像之间的空间差异,而颜色比较甚至可以在视网膜中直接完成。随后,视觉信号沿着视神经传输至丘脑,在那里进一步筛选出重要的视觉特征。
当你在整张图像上重复这个过程时,你可能会发现自己形成了假设——例如“那条路真的消失了吗?”——这会促使你更加努力去验证你的假设。人类的感知过程本质上是假设驱动的:视觉皮层拥有十倍于从皮层到丘脑(最终回到眼睛)的连接,而不是相反方向。这意味着我们在构建和优化假设的过程中投入的处理能力,是我们用于评估从眼睛传入信号的处理能力的十倍之多。
上一节描述的程序是思维链的一个典型例子。它不是直接生成结果,而是通过多次迭代、失败和改进结论,有意识和无意识地构建出一种策略。这正是生成式 AI 的瓶颈所在。尽管最近的进展使得文本内容的思维链推理成为可能,但将相同的概念应用于多尺度的二维空间分析仍然是一个巨大的挑战。生成式 AI 模型学会处理图像输入的时间远远晚于纯文本。解决所有与视觉相关的问题可能需要数年时间——鉴于人类自身完成这项任务的代价极易受视觉错觉的影响,实现这一目标需要的时间可能甚至更长。
值得注意的是,AI 在识别其训练集中频繁出现的信息方面表现出色,包括文本、交通场景、物体特写、名人以及 IQ 测试中常见的视觉模式。然而,地理地图、美学对齐以及抽象或富有想象力的图形超出了这一范畴——不仅因为缺乏训练数据,还因为它们很难用文字进行准确标记。描述视觉差异比推导已识别标签的差异要困难得多。因此,图像比较仍然是一个挑战,并且可能在相当长的一段时间内都是如此。
移动像素容忍度
在比较图像时,必须考虑两个关键概念。一个是判断图像对是否相等,一个是识别使它们变得相等所需的最小变化。在软件测试中,这两个步骤都很重要。第一个步骤决定了测试是否失败,是否需要人工介入进行审查,而第二个步骤有助于快速做出决策。知道一个按钮“只是”移动了,与它移动并发生了变化,有着不同的含义。如果没有可靠的实际变化报告,软件测试人员将不得不退回到繁琐的手动比较,就像“找不同”一样。
比较两个图像最简单的方法是进行逐像素比较。在之前的地图示例中,ChatGPT 尝试了这种方法。然而,当将这种方法应用于具有动态布局的现代用户界面时就会失败。像素稳定性无法得到保证——可能因版本不同而发生变化,甚至在高度并行化的算法推动最快渲染引擎达到极限时,像素颜色还可能出现随机变化。因此,单独的像素颜色不足以推断出等效内容。空间位移的检测需要更复杂的模式识别技术。
解决这一问题的常用方法是利用卷积神经网络(CNN)。直接使用整张图像进行训练在算力方面成本高昂,因为现实中的屏幕截图具有高分辨率,包含数百万像素。通过比较小的片段而不是单独的像素,可以简化问题。以下示例使用了一个 9x9 像素的区域。这个区域足够大,能够在判断图像相等性的同时考虑微小的位移;同时又足够小,能够适应轻量级神经网络的高效处理需求。由于每个颜色通道可以分别处理,因此我们只需要训练单色样本即可。

图 4:9x9 图像片段。可以排除图像 1 和 3 结构相等,但图像 1 和 2 则不能。
使用TensorFlow(以及PyTorch)训练这类网络非常简单。以下代码示例展示了一个基于 20 万张标记的灰度图像训练出来的有效网络。为了利用所有对称性,可以考虑 3 个对称轴和两个输入图像的交换性,将训练样本数量增加 16 倍。训练过程调用Keras API,在普通硬件上几分钟之内就可以完成。15 年前,这还属于尖端的 AI 研究领域。如今,它已经成为了简单的机器学习任务。
有一个包含完整训练说明和训练数据的Colab 笔记本可供使用。
这个神经网络的设计大致基于 1990 年初的LeNet架构神经网络设计,唯一的区别在于它被应用于比输入窗口更大的图像。因此,它不会只生成单个标签,而是为每个像素点产生一个标签。这确实解决了我们最初遇到的两个地图不完全对齐的问题。图 5 展示了这个简单卷积网络的结果,它有 162 个输入节点、8 个层和 48211 个可训练参数。所有训练数据和网络布局都可以从上述的笔记本中获取。
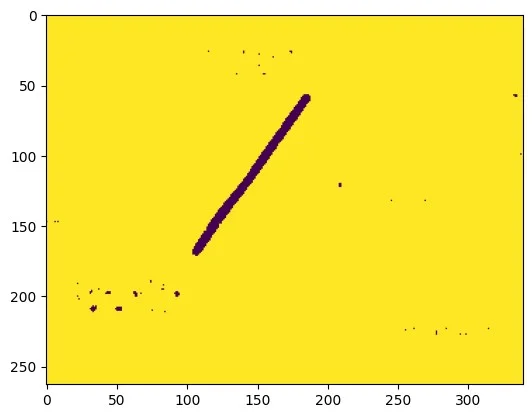
图 5:卷积神经网络可以检测地图上的偏差位置。
应对大位移
在高分辨率显示器上,或者在布局更为复杂的情况下,两个图像之间的差异可能并非仅仅源于像素级的微小变化,而是由于较大的位移导致的。在自动化测试中,这种重新排列通常会导致测试失败。手动检查所有因格式调整而略微发生变化的屏幕截图,是一项工作量巨大的任务。如果 AI 工具能够正确检测到重大变化是否发生在这些微小的布局调整之外,那将是非常有价值的。
一个直观的想法是简单地加大神经网络的窗口大小。假设我们有一个能够补偿长度为“n”的位移的网络,我们希望将其能力提高 2 倍。由于额外的位移可以在两个维度中的任何一个发生,我们需要将搜索扩展到原始大小的四个不同片段。由于我们会接受这四个片段中的任何一个匹配,因此出现假阳性的可能性增加了四倍。小区域可能看起来相似,例如包含相同的笔画类型,但并不一定是整个区域一致位移的结果。为了避免特异性降低,我们不得不比较大小为四倍的屏幕区域。这使我们的总工作量增加了 16 倍,或者对于一个能够容忍长度为 n 的位移的图像比较网络,其复杂度为 O(n^4)。这可能是一个下限,因为对于更大的区域,位移可能不会被视为均匀的,并且必须考虑更复杂的失真情况。
让我们来探讨一种位移不仅不均匀且幅度较大的情况。图 6 展示了一个经典的“找不同”游戏。第二张图像的倾斜对人类来说几乎没有增加额外的难度,因为我们习惯于从某个角度观察事物。然而,对于软件测试来说,这种失真可能看起来不切实际。随着流式布局以及元素尺寸和位置不断发生变化,这种情况也并非完全不可能出现。这里的关键在于 AI 完全无法检测到任何相关的差异。

图 6:孩子们能够轻松找到相关差异,但 AI 完全做不到。
一种可能的解决方案
正如之前所讨论的,将窗口大小增加到可以覆盖整个位移长度并不是一个可行的选项。与其训练网络输出一个布尔等式标志,不如训练它返回位移向量的 x 和 y 值。一开始,这似乎没有任何区别,因为实际长度仍然无法放入计算的滑动窗口内。不过我们现在可以缩小图像的尺寸,虽然牺牲了一些细节,但作为回报,我们获得了全局视野,从而可以推导出位移方向的近似值,在更精细的级别上缩小搜索区域。
以下伪代码实现了一种用于解决对应问题的算法。这个算法通过递归调用自身,利用缩小尺寸的图像推导出一个向量图,确定了左右图像中对应位置的映射关系。经过训练的网络只需要调整在更粗糙级别上产生的误差,即在非常小的搜索区域内寻找匹配的特征。这个算法使用OpenCV框架的“resize”方法来放大和缩小图像,并使用“remap”方法将更粗糙级别上预测的位移应用到更高分辨率的图像中。它还使用了“cnn_predict”方法来获取神经网络对相对位移的估计值。预测结果包含两个输出通道,分别对应 x 和 y 分量。
# Returns a tensor dxy, such that for every x,y:# img1(y + dxy(y,x,1)/2, x + dxy(y,x,0)/2) corresponds to # img2(y - dxy(y,x,1)/2, x - dxy(y,x,0)/2)def get_correspondence_map(img1, img2): assert_equal(img1.shape, img2.shape) if img1.shape > window_shape: dxy_1 = resize( # The course estimate is derived from a get_correspondence_map( # recursive call on shrunk images. resize(img1, 0.5), resize(img2, 0.5)), 2) dxy_2 = cnn_predict([ # Calling CNN to predict residual displacements. remap(img1, dxy_1), # Each image is displaced remap(img2, -dxy_1)]) # into the other’s direction. dxy = 2 * dxy_1 + dxy_2 # Return the sum of coarse and fine shifts else: dxy = zeros((img1.height, img1.width ,2)) # Too small: assume alignment return dxy这个Colab 笔记展示了完整的算法,并涵盖了所有边界情况,使用 Python、OpenCV和一个预训练的网络从 15x11 的窗口中识别大小不超过 3 个像素的位移。
在重建位移图后,我们在每张图像上应用一半的效果。现在,两张图像中间对其,可以使用标准方法进行比较。显然,失真引入了额外的混叠,导致匹配结果无法完全精确到像素级别。好在上一节提到的神经网络可以轻松解决这个问题。所有相关的差异都会被检测到,只有右上角有两个假阳性结果。需要说明的是,这些测试图像在训练阶段都没有被使用过。

图 7:在补偿失真后,可以应用简单的差异算法。
这个解决方案能够在布局发生显著变化后找到相关的差异。它可以检测物体的整体移动,但无法跟踪交换位置或跳到完全新区域的单个物体。因此,仍然需要人类或 AI 进一步检查并解释实际发生的变化。然而,通过缩小查找范围,它使这项任务变得更加容易。
结论
比较两个图形输出是视觉回归测试的主要挑战。虽然在像素级别上检测两张图像之间的差异相对容易,但将这些差异总结为具体的描述(例如“X 标志移动了 n 个像素”)则要困难得多。不幸的是,当前的生成式多模态 AI 模型无法胜任这项任务。它们非常擅长找到它们能够命名的差异,例如文本值或按钮的顺序,但对于那些难以命名的差异(例如美学对齐、不规则地图上的连接,或者它们未被训练来标记的对象)则完全无能为力。
为了简化图像比较的过程,我们提出了两种手动解决方案。首先,训练一个卷积神经网络来比较图像片段,并容忍微小的位移,这可以在很大程度上减少对完美像素对齐的需求。为了检测和补偿较大的失真,我们使用了一种在多个图像尺度上运行的算法。这与人类视觉皮层处理此类任务的方式类似。它在多个尺度上运行,推导出假设并补偿其效果。最好,我们可以专注于剩余的变化,区分出位移和非位移差异。由于比较静态图像只是视觉处理的冰山一角,我预计 AI 技术在未来相当长一段时间内仍将难以应对那些看似简单的与图像相关的任务。
参考文献
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/articles/spotting-image-differences-visual-software-testing-ai/




