

即时通讯的兴起改变了我们的交流方式。与来回的电子邮件相比,我们发送和接收消息的数量和速度都要高得多。在进行即时对话时,我们也希望能够轻松地搜索重要的短语、瞬间或有参考价值的东西。数据交换请求数量的快速增长为消息传递的可伸缩和快速发现带来了许多新的工程挑战。在这篇博文中,我们将讨论如何改进消息搜索体验,基本方法是从头开始改进消息传递后端架构,并引入我们称为 InSearch 的消息搜索后端。
本文最初发布于 LinkedIn 工程博客,经原作者授权由 InfoQ 中文站翻译并分享。
即时通讯的兴起改变了我们的交流方式。与来回的电子邮件相比,我们发送和接收消息的数量和速度都要高得多。在进行即时对话时,我们也希望能够轻松地搜索重要的短语、瞬间或有参考价值的东西。数据交换请求数量的快速增长为消息传递的可伸缩和快速发现带来了许多新的工程挑战。
在这篇博文中,我们将讨论如何改进消息搜索体验,方法是从头开始改进消息传递后端架构,并引入我们称为 InSearch 的消息搜索后端。
挑战
如果我们使用 LinkedIn 的传统搜索基础设施来支持消息搜索,那么构建并提供近线索引服务的成本将会高得令人望而却步。这是因为:
与其他用例相比,要索引的消息数据总量非常大。
考虑到消息交换的增加(每秒数千次写操作),对索引的更新速度要高得多。
这些数据需要进行静态和传输加密,因为消息数据是高度机密的。
此外,我们注意到,搜索查询与正在创建的消息的比率非常低。这使得降低搜索基础设施的成本成为一个重要的问题。我们使用这个和其他对于数据和使用模式的观察来设计了这样一个系统,它满足我们所有的需求,同时又具有成本效益。
整体架构
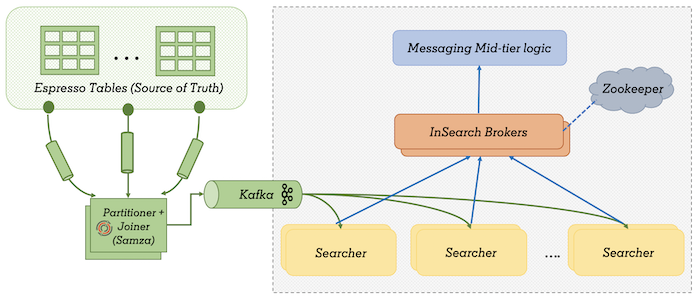
InSearch 的高层架构
搜索器(Searcher)
消息搜索仅限于会员各自的收件箱。你只能在自己的收件箱中进行搜索,因此,只需要针对你的数据在内存中建立索引,从而快速地处理查询。从使用情况来看,我们还知道,使用消息搜索的会员通常是高级用户,这意味着他们经常依赖于我们的搜索功能。比较理想的情况是,按会员索引,并使索引可缓存,这使我们研究了仅在会员执行搜索时生成会员索引,然后缓存索引的想法。
我们的搜索服务内部使用Lucene作为搜索库。处理高度机密数据(如消息)的一个关键要求是确保所有数据都在磁盘上加密。同时,我们还需要能够支持高速率的更新。将索引存储在磁盘上需要一个很长的过程(从磁盘读取加密的索引、解密、更新索引、再次加密并将其持久化),这使得写入操作非常低效——需要注意的是,这是一个写密集型系统。
因此,我们牺牲了创建索引的速度来获得更好的写吞吐量。这是通过将每个原始文档加密存储在一个键-值存储区来实现的,键是 memberId 和 documentId 的组合,而值是加密的文档(即消息)。注意,这是一个简化版本,在生产环境中,它更加复杂,因为我们有不同的文档类型,而参与者不一定是会员。使用这种设计,新消息就是添加到键值存储中的新行,这使得向系统写入数据非常快。我们使用RocksDB作为我们的键值存储,因为它在 LinkedIn 已经被验证是可靠和有效的(参见FollowFeed和Samza的例子)。它也不会伤害到我们,因为我们有大量的内部专家来支持它。
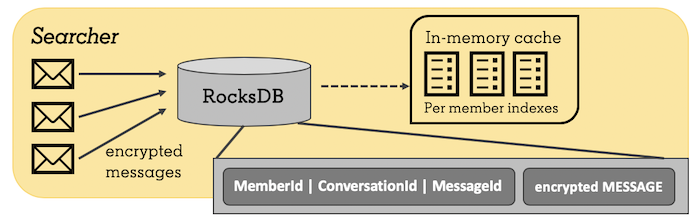
具有 RocksDB 键值结构的高级搜索器流
当一名会员执行他或她的第一个消息搜索时,我们从 RocksDB 运行一个键的前缀扫描(前缀是会员 ID)。这将为我们提供该会员的所有文档用于构造索引。在第一次搜索之后,索引被缓存在内存中。结果呢?我们观察到的缓存命中率约为 90%,而总第 99 百分位延迟约为 150 毫秒。
对于写操作,我们将加密的数据插入到 RocksDB 中。如果索引被缓存,那么缓存的索引也会通过再次从数据库读取更新后的文档来更新。我们还持久化缓存的会员 ID,以便在启动时将它们的索引重新加载到缓存中。这使缓存即使在部署之后也能保持温度。
分区、复制和备份
与大多数分布式系统一样,我们通过复制和分区来处理可伸缩性和可用性。数据按会员 ID 和文档 ID 的组合进行分区。一名会员的数据可以分布在多个分区上,这有助于我们针对具有大型收件箱的会员进行水平扩展,因为索引创建负载可以由多个分区分担。
对于每个搜索器分区,我们有三个活动副本和一个备份副本。每个副本独立地使用来自 Kafka 流的索引事件。我们在适当的地方进行了监控,以确保没有一个副本比它的对等副本延迟高。备份副本定期将数据库快照上传到我们的内部 HDFS 集群。和备份副本一起,我们还会备份 Kafka 偏移量。这些偏移量用于确保在服务从备份数据集启动之前,我们能够完全捕获 Kafka 丢失的数据。
摄入
消息数据的真实来源是Espresso表。我们使用Brooklin以流的方式将来自这些表的更新传递给一个Samza作业,然后将这些更改日志转换为搜索器索引所需要的格式。流处理作业将这个流与其他数据集连接,从而使用要使用的实际数据装饰 ID(例如,用姓名装饰会员 ID)。它还负责对搜索器所需的数据进行分区。现在,每个搜索器主机只需使用它所承载的特定 Kafka 分区的数据。
代理
代理服务是搜索查询的入口点,它负责:
查询重写:它根据查询用例将原始查询(例如:“apple banana”)重写为 InSearch 格式(例如:TITLE:(apple AND banana) OR BODY:(apple AND banana))。不同的搜索查询可能使用不同的评分参数对某些字段进行优先级排序。
分发收集操作:它将请求分发给搜索器主机,整理从搜索器那里返回的结果。
重试:如果出现可重试的失败,或者一个特定的搜索器耗时太长,那么代理将在一个不同的搜索器副本上重试请求。
重新排序:对所有搜索器主机的结果进行重新排序,得到最终的结果集,并根据分页参数进行精简。
代理使用我们的内部D2 zookeeper 服务(它维护每个分区的搜索器主机列表)来发现每个分区的搜索器主机,以便选择扇出主机。我们还确保在这些主机上进行严格的路由,这样,给定会员的请求就会转到相同的搜索器副本,进而就不会在多个副本上重建索引,并且提供了一致的搜索体验。
小结
到目前为止,所有来自 LinkedIn 旗舰应用的消息搜索请求都由 InSearch 提供,我们能够以低于 150 毫秒的延迟服务于 99%的搜索请求。
目前,我们正在将几个企业用例迁移到新系统中,并评估其他应用。此外,我们现在开始利用新的消息搜索系统来加速改进 LinkedIn 的消息传递体验。
原文链接:
InSearch: LinkedIn’s new message search platform

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论