
在 Qcon London 2016 上,Peter Alvaro 和 Kolton Andrus分享了一项企业与学院合作的成功案例,这次合作最终为 Netflix 找到了一条自动化故障注入测试(failure injection testing)的崭新途径。在这一案例中他们收获了许多宝贵经验,其中主要包括:
- 从已知熟悉的事物出发
通常这有助于缩小解决方案的搜索空间,比如,Netflix 的价值观非常重视用户体验- 求同存异
通过有效的合作,大家制定并朝着共同的目标一起前进,这是非常必要的- 将理论付诸于实践
真实世界往往比实验室复杂得多
主讲人 Alvaro 现任圣克鲁斯大学的助理教授,虽然他个人更乐意被简称为“教授”;而另一位主讲人 Andrus 曾经是 Netflix“混乱(chaos)工程”团队的一员,在离开 Netflix 后创立了 Gremlin Inc。两位主讲人在开始时谈到,企业和学院的合作,往往因为各自目标上的差异而变得困难重重。比如,“教授”Alvaro 十分享受建模以及尝试各种解决方案的过程。他在学院内是否成功,往往体现在其研究成果是否被大量引用(citation impact, h-index ),有没有广泛的应用前景,有时甚至只是一个学院内的评级。而作为“实践者”,Andrus 更热衷于积极寻找可以切实解决的问题,并将其解决方案落地施行。他在企业内是否成功,则具体地体现在提高系统可得性(availability),减少各种事故的数量,以及降低运维成本。
合作的契机出现在 2014 年。当时还在 Netfix 任职的 Andrus,负责在著名的“混乱工程”的基础之上,搭建一套所谓故障即服务(failure as a service)的测试框架。在生产环境上进行故障测试,主要有两个关键的概念:故障范围(failure scope)和注入点(injection points)。故障范围指的是,把一次故障测试可能产生的影响,限制在一个可控的范围内,这个范围可以小到某个特定的用户或者设备,也可以大到所有用户的 1%。而注入点指的是系统内计划会发生故障的组件,比如 RPC 层,缓存层,或者持久层。
故障测试的最终目的,是为了当真的有故障发生时,生产环境不会停止服务,并且整套系统可以在没有人为干预的情况下,非常优雅地通过降级(degrade)将发生故障的部分组件排除出去。Andrus 还描述了一幕,在整套测试框架正确执行的情况下,发生在故障后的场景。
某天,你来到办公室和同事聊天。他们问:“嗨,你知道昨晚什么什么服务跪了么?”你可以回答说:“不知道啊,你接到电话了么?” “没有啊,谁接到了么?” “没有啊……” 这种感觉真的是爽到了!
我喜欢聊各种故障,但是是在事后,是在上班时间,而不是半夜
依照 Netflix 的惯例,故障测试的流程是人工完成的。Andrus 会找各种团队开会,讨论哪些地方发生故障,发生故障的场景是怎么样的,然后手动实现并执行一系列对应的故障测试。直觉告诉 Andrus 应该有更好的办法。在网上大量搜索之后,Andrus 找到了一段 Alvaro 在 RICON Talk 上做的演讲和论文,《路径驱动的故障注入(Lineage-driven fault injection)》。Andrus 相信这就是他苦苦寻找的那种,能够安全地自动化故障注入测试的“更好”的办法。
Andrus 开始和 Alvaro 频繁地交换各种奇思妙想,最终两人决定一起合作,将故障测试领域的最前沿提升到新的高度。合作建立在一种企业和学院都奉行的信条之上,即“在各自明确的职责范围内保有最大程度的自由(freedom and responsibility)”。这次合作的主要目标有以下这些:
- 证明 Alvaro 提出的方法可以应用于真实世界
- 证明这种方法的应用规模可以轻松扩展
- 使用这种方法找到真实系统中存在的真实问题
为了完成这些目标,Andrus 和 Alvaro 决定在暑假的几个月中非常紧密地协作。为此,Alvaro 还以合同工的身份加入了 Netflix,在 Netflix 的办公室中工作。
合作开始之后,他们首先试图回答这样两个问题:“在一套基于微服务(microservice)架构的常规系统中,有多少种可能的故障?”以及“所有这些故障,能组合出多少种故障情景?”。Alvaro 做了个估算,很快给出了大致的结论:假设 Netflix 有 100 种服务,并且每种服务只会发生 1 种故障,那么总共会有种不同的故障场景。换言之,必须执行这么多次故障注入测试之后,Andrus 才能详尽地检查每一种故障场景,然后彻底地找到每个缺陷。从时间上来看,这几乎是不可能的。退而求其次,如果限定同时只会有 1 种故障发生,那么只须要执行 100 次故障注入测试就足够了;如果这个限制放开到 4 种,那么须要执行 300 万次测试;如果进一步放开到 7 种,那将需要 160 亿次。
从某种抽象的学术角度来说,讨论容错性根本是多余的。
理论上,一套拥有容错性的系统,必须在任何可预见的故障发生时,始终能自动找到替代路径来绕开故障,继续正常工作。因此,如果一套系统,可预见的故障场景多达种,那么这套系统就必须在满足业务逻辑的基础上,兼顾每种故障场景下的替代路径。
测试数量的指数级增长,意味着必须有自动化的实施方案,然而这并非易事。一种简单的策略是说,如果无法做到遍历所有故障场景,那可以随机抽取故障场景进行注入测试;但这无异于大海捞针,而且这种策略的耗时依旧太长。既然如此,可以考虑将随机抽样改为人为引导挑选,利用人在业务领域内的专业意见以及直觉,来遴选甄别那些有潜在问题的故障场景;然而这样做就失去了自动化的意义,因为其应用规模受限于人的数量。
使用常规的验证手段时,人们经常思索的是一个很难回答,同时也没有正确答案的问题:怎样才会出故障呢?这个问题对寻找系统缺陷,几乎没有任何帮助。在《路径驱动的故障注入》中提到的重要概念之一,是说人们应该从一套系统的无故障状态出发,然后试图去回答说“系统是如何达到目前这种无故障的状态的?”,以及“整套逻辑链条中,是不是有哪里出错,就能导致系统发生故障?”。逻辑链条中的错误会将链条打破,导致系统无法到达最终的无故障状态,从而发生故障;而从无故障状态推演出的各种逻辑链条,它们组成的图(graph)能帮助人们找到那些最有价值的故障场景。

当图里的每一条逻辑链条上,每一个能出错的环节都被找到之后,整张图就能简化为一个合取范式(conjunctive normal form);其中每个能出错的环节是一个布尔变量,而剩下的环节则被省略。得益于这个简化,“系统出错”这一抽象的概念,就变成了一个具体的问题:“如何让这个合取范式的结果为假(false)?”,而这个问题的答案就是故障注入测试须要检查的那些目标故障场景。再次得益于这个简化,目标故障场景的搜索变得非常高效,因为事实上这是一个布尔满足性问题,数学上已经有很多完备且高效的解法。
Alvaro 在论文中提到了一套名为“Molly”的原型(prototype)系统,这套系统可以通过以下算法来寻找目标故障场景:
- 找到一个被测试系统给出的正确输出
- 从这个正确输出反推,找到并构建支持其正确性的逻辑链条图
- 将图简化为合取范式并求解
- 回到第 1 步继续下一个正确输出,直到遍历完所有正确输出
在算法中的第 3 步中,存在两种可能的结果:一种是 Alvaro 自嘲为“好”的结果,即找到了一些目标故障场景;另一种则是没有找到目标故障场景,那算法将继续寻找。如果逻辑链条图的构建是完备的,那么被测系统在算法找到的每个目标故障场景中,都有很大的几率无法正常工作,或者说存在问题。
在将这套理论应用到 Netflix 故障测试的过程中,第一个遇到的挑战是说,如何定义一次常规用户请求是“正确”的,因为在 Netflix 的服务栈中,一个返回 200 的 HTTP 请求,其结果并不一定是正确的。Andrus 提到,此时一条 Amazon 核心指引(leadership)原则启发了他们,即“一切从用户出发”,因此他们不再纠结于单次请求是否正确,转而试图回答这样的问题:用户有没有看到正确的结果?
在 Netflix 的服务栈中,有一种名为“真实用户监控(real user monitoring,简称RUM)”的服务,可以监控系统特征以及用户体验。RUM 数据以流的形式,不断地从各种客户端异步地发送给Netflix 的后台服务,并在那里与同样来自客户端的用户请求数据联接(join),从中判断用户是否看到了正确的结果。同时,Netflix 还使用一种带故障点标记的分布式追踪系统,这套系统可以判断某个用户当前是否进入了一个,由故障注入测试生成的故障站点,并能追踪到当前测试的目标故障场景中,具体有哪些被注入的故障。
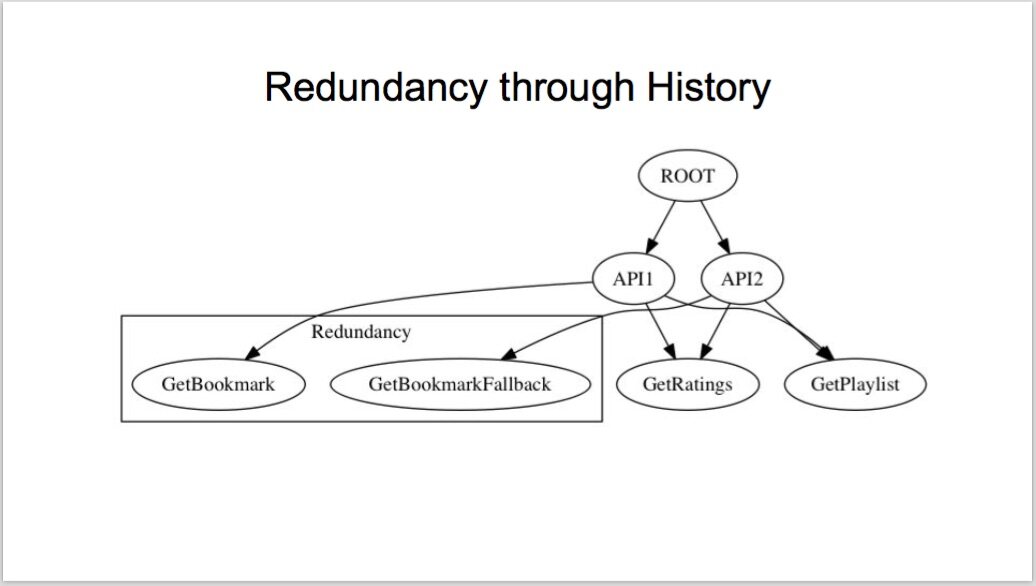
例如,如果一套Netflix 的服务被部署到多个区域的不同可得带(availability zone)中,那么这套服务必须拥有冗余性。当某个可得带中的一项服务不再工作时,Netflix 的 Hystrix 组件,会从代码层面上自动向其他可得带的同一服务重播请求,从而做到了时间上的冗余(redundancy through history),即多次请求返回一次正确结果。这种冗余性因其应用普遍,在 Netflix 服务的逻辑链条图中,占到了相当大的份额。
Alvaro 表示,唯有通过企业和学院的紧密合作,大家在共同目标的指引下求同存异,才有可能发现这样创新的途径。Andrus 也强调说,只有一起协同工作,频繁的讨论以及在白板上交流想法,这样才是有效的合作。
这就是并肩工作的优点。我们能够讨论各种各样的问题,通过在白板上作图解来提高沟通质量。这是写 email 或者打电话无法做到的,只能依靠经常性的肩并肩工作。
随着故障注入点和逻辑链条图的确定,接下来的步骤是实现这套算法。作为学术派的 Alvro 决定证明一下自己的软件研发功力,而他实现的算法现在已经被部署到 Netflix 生产环境下运行。
Alvaro:我自豪地宣布,我提交的代码现在正跑在 Netflix 上!
Andrus:严格来说,是你提交的刨去这些 println 之后的代码…
Alvaro:呃,抱歉我忘了删了…
算法实现之后,整个项目到了最终的执行阶段。每当有一个用户请求进入系统,并且在处理过程中没有引发任何故障,那么这个请求就会成为系统的一次“正确输出”,并被故障注入测试系统在各种故障场景下重播。但是,在 Netflix 的分布式系统中,并不是每一种服务都具有等幂性(idempotent),因此有在确认不会造成意外后果之前,故障注入测试系统并不能简单地重播所有能产生“正确输出”的用户请求。
解决这一问题的方法,并不是让所有服务都拥有等幂性,而是将产生“正确输出”的用户请求进行分类;故障注入测试并不是重播所有能产生“正确输出”的用户请求,而是从每一类用户请求中重播一个,从而将由等幂性缺失造成的意外后果降到最低。如果两个用户请求在系统中的处理路径是相同的,或者出错的路径是相同的,那么从故障注入测试的角度来说,这两个请求就是相同的,在故障注入测试时可归为一类。然而,一个用户请求在系统中的路径,只有处理完才能知道,但两个用户请求是否属于同一类必须在开始处理他们之前就决定,否则故障注入测试无法恰当地引导用户请求进入故障场景。本质上,我们须要建立一种映射,将用户请求映射到 Netflix 系统内的某条路径上。
这种映射可能可以用机器学习来找,但从时间上来看这个方法并不可取。最终两人找到一种替代方案,使用一套被称作 Falcor 的框架(一套由 Netflix 开源,用来提高数据传输效率的 JavaScript 库)来确定,某个用户请求将会涉及到哪些后台服务,从而近似地找到从用户请求到系统内路径的映射。虽然并不完美,Avlaro 表示这一近似确实帮助他们将理论应用于现实,并有效地推进了整个项目的进行。在这套方案上线运行几周之后,Alvaro 和 Andrus 确认说,这条崭新的故障注入测试的自动化方法是非常成功的。
在最后,两位主讲人还展示了一个名为“Netflix AppBoot”的用例分析。在这个用例中,最新的自动化故障注入测试被应用于一个在 Netflix app 启动时所发出的用户请求上,而这个用户请求的故障搜索空间大约是 100 个服务。虽然彻底检查整个故障搜索空间需要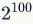 次测试,自动化故障注入测试筛选并最终只针对 200 个故障场景进行了测试,其测试结果帮助开发人员找到并修复了 6 个比较严重的问题。
次测试,自动化故障注入测试筛选并最终只针对 200 个故障场景进行了测试,其测试结果帮助开发人员找到并修复了 6 个比较严重的问题。
从学院的角度来看,Alvaro 后续可能会研究故障搜索的优先级,尝试更复杂的逻辑链条,以及探索故障之间的时间交错(temporal interleavings);而从企业的角度,Andrus 日后会更专注于丰富设备的指标,寻求更有效的办法来对用户请求进行分类,以及优化测试选择的策略。
Peter Alvaro 和 Kolton Andrus 在 QCon London 演讲的视频可以在InfoQ 上找到。
查看英文原文:“Monkeys in Labs Coats”: Applied Failure Testing Research at Netflix
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论