
GitHub 最近正式发布了 Scientist 1.0,这是一个能够帮助开发者更有信心地重构或重写代码的 Ruby 库,作者是GitHub 的工程师Jesse Toth。在过去几年中,Scientist 已经为GitHub 上的大量项目所用。
按照Toth 的看法,Scientist 对于关键代码的重构尤为实用,在进行这种重构时,开发者对于新的实现的正确性要具备很强的信心。在此之前,一种常见的重构方法是采取 BranchByAbstraction 架构模式,这种模式本身虽然非常实用,但它只是保证了新的组件能够取代旧组件所出现的每一个场合而已。而 Scientist 的目标是提供更好的正确性保障。此外,Scientist 还将尝试绕开测试过程的限制,因为测试过程往往无法做到涵盖所有可能的情况或输入数据的组合。
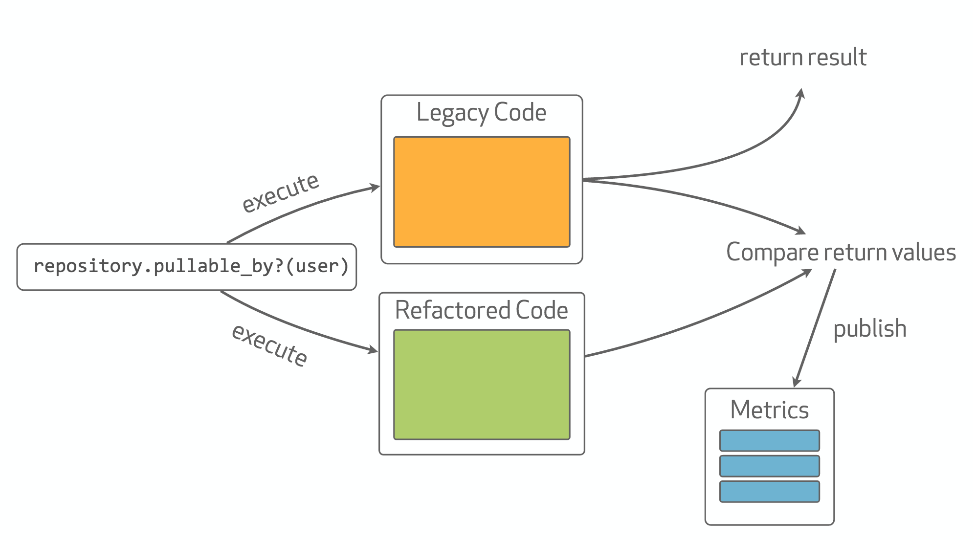
Scientist 的基本思想是建立一种受控试验(experiment),在其中同时运行旧的代码路径与新的代码路径,随后对两者的输出进行比较,并对任何不匹配或异常进行记录。旧的代码路径将保证整个系统在重构的实验阶段仍能够正确地运行,而新的代码路径的正确性也同时得到了验证。
一个 experiment 是一种轻量级的抽象,它包含了两种行为。use 行为表示执行旧的代码路径,而 try 行为则表示执行新的代码路径。
experiment = Scientist::Default.new "my-experiment" experiment.use { <call the old code here, the control> } experiment.try { <call the new code here, the candidate> } experiment.run #... def publish(result) #...
run 方法将始终返回与 use 代码块相同的返回结果,而 publish 方法将在 experiment 的末尾进行调用,以发布所收集到的数据。除了对 try 与 use 代码块的结果进行比较之外,Scientist 还会随机地调整他们的执行顺序,以回避两者之间可能产生的相互关联,它还将评估两种方法的执行时间、管理异常、并发布所收集到结果。
Scientist 提供了大量的方法对它的默认行为进行自定义,举例来说,用户可以定义一个特定的比较方法,以覆盖默认的 == 操作符,这一方法将用于输出的对照比较。此外,用户还可以提供一个上下文对象,可在发布数据时使用。用户还可以控制启动任务、启动或关闭 experiment 的执行等等。Scientist 还提供了一些更高级的控制选项,以允许用户忽略结果、运行多个 try 代码块、或只运行 try 代码块,以涵盖某些特殊的用例。
InfoQ 与 GitHub 的首席工程师 Jesse Toth 进行了一次对话。
能否请你描述一下 Scientist 的诞生过程?
Scientist 的诞生过程是这样的。当时我有一位前同事 Rick Bradley 正在尝试重构一个非常复杂的 API 终结点,该 API 将返回一个长长的 repository 列表。他不确信所改动的代码是否已经得到了足够的测试覆盖,并希望通过某种方式对真实的数据集进行测试。于是他快速地修改了一部分代码以调用重构后的方法,并且每当重构后的方法与原始方法产生不一致行为的时候,就在我们的指标栈中将数据记录下来。这种方法相当有效,于是我们为它编写了一个库,让任何人都可以利用它进行相同的实验。
为了让现有的代码能够通过 Scientist 进行一系列实验,所改动的代码会产生多大的开销?你在 GitHub 中又是怎样在使用 Scientist 时调整它的投入与产出比的呢?
这取决于你希望进行实验的那部分代码有多大开销,以及这部分代码的调用频率。如果候选的重构代码与对照的原始代码具有完全相同的效率,那么运行一个 experiment 就是 2 倍的开销。如果候选代码极大地提升了性能,那么开销就会大大地降低。
如果我们认为运行 Scientist experiment 的代价很高,那么我们就会缓慢地提高运行 experiment 的请求的比例。如果 experiment 的执行能够涵盖 1% 或 5% 的访问量,这就已足够为我们收集大量的性能与不匹配方面的数据了。
你是否希望在 Scientist 中引入更多的特性?
Scientist 已经具备了我们目前所需的所有特性,当然,如果有用户发现了某种使用 Scientist 的其他方式,并希望为支持这一方式而添加相应的特性,我们将非常乐于看到这方面的贡献。
Scientist 所需的运行环境是已安装了 Ruby 1.9 的 Unix 系统,可以从对应的 gem 中进行安装。
查看英文原文: GitHub’s Scientist Aims to Help Refactoring Critical Paths

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论