
在数据库和数据分析领域,技术演进常常伴随着范式之争。从传统数仓到数据湖,再到 Lakehouse,不同体系之间的切换不仅是概念上的变化,更是企业架构和成本结构的重新洗牌。
近日,借着 StarRocks Connect 2025 举办之际,InfoQ 与 StarRocks 的 TSC member、镜舟科技 CTO 张友东进行了交流。在演讲和访谈中,他回顾了 StarRocks 的演进路径,并谈到自己对 Lakehouse 架构、实时分析需求的变化,以及 AI Agent 带来的系统性挑战的看法。
在过去几年,Lakehouse 从一个争议性的概念逐渐走向行业共识。张友东回忆道:“去年我们分享讲的是 ‘Lakehouse is ALL you need’,其实我们讲这个东西已经讲好几年了,在国内其实没什么人在提。以前说 Lakehouse 是趋势,大家将信将疑,现在大家对这个的接受度普遍增加了。”
他强调,Lakehouse 的核心价值就是打破“烟囱式”架构。以往企业往往为不同场景搭建不同的系统,带来冗余存储、指标口径不一致和高昂运维成本。“StarRocks 希望成为在分析场景统一的引擎,数据在湖上,不管是实时场景还是离线场景,使用 StarRocks 作为统一的数据分析引擎。”
StarRocks 的演进路径也印证了这一目标:1.0 在 2021 年发布,聚焦高性能分析;2.0 在 2022 年增强实时能力;3.0 在 2023 年完成了从存算一体到存算分离的升级;而即将在 10 月发布的 4.0,则把“Agent Ready”作为核心目标。
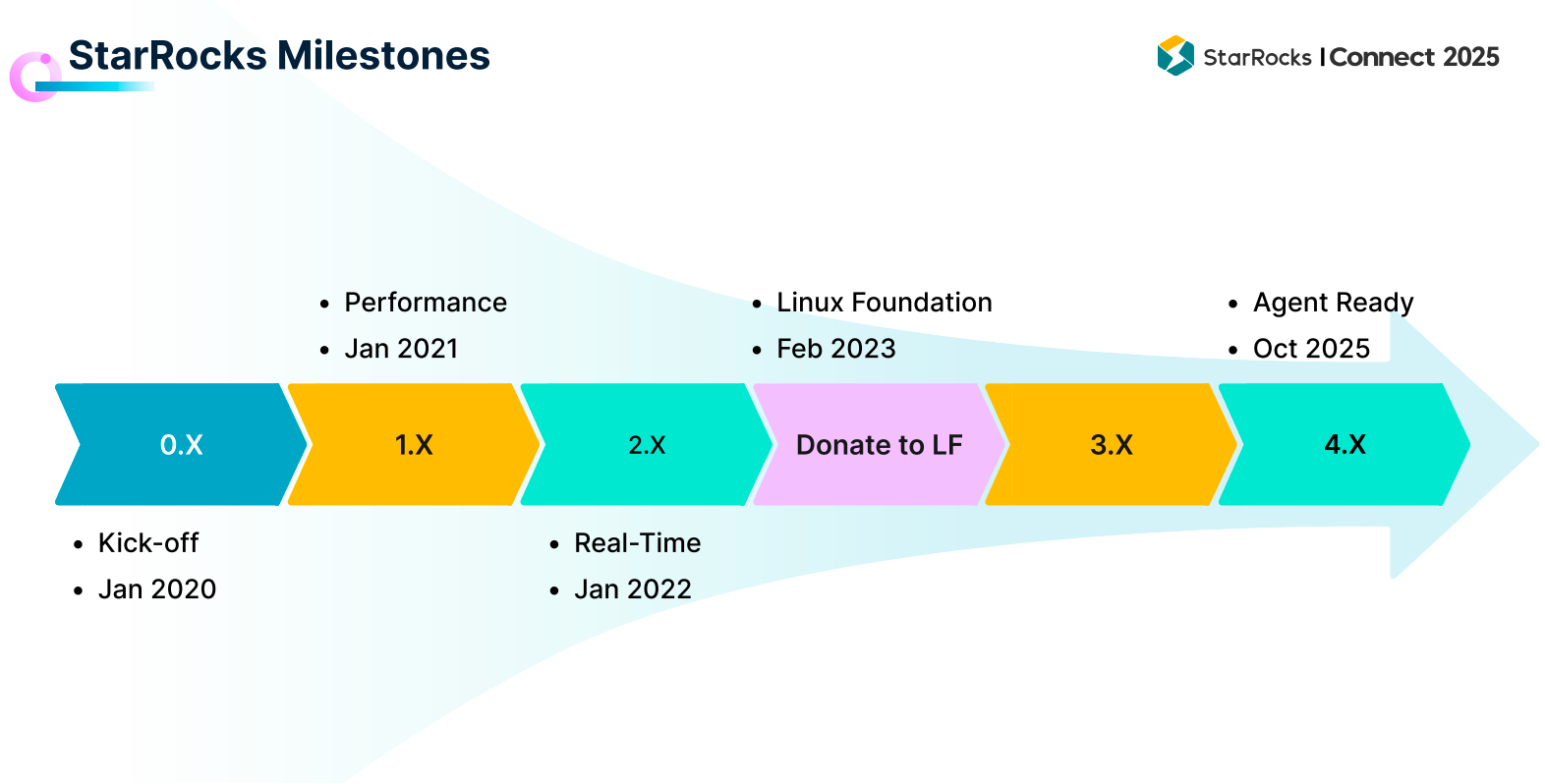
值得一提的是,StarRocks 的社区也在持续壮大:目前 Github 上的 Stars 已突破 11000,超过 500 位开发者为其代码和文档做出过贡献;全球 Slack 社区成员超过 4700,中国本土的用户微信群则早已超过 10000 人。
数据分析的范式转变:从战略到运营
张友东认为,现代数据分析正在经历一次重要转型:从 Business Analytics 到 Operational Analytics。前者主要服务战略层面的报表、Dashboard 和分析师查询,而后者直接嵌入运营环节,支撑实时洞察、客户行为分析,乃至未来 Agent 自动化决策。
这种转型带来了新的挑战。“Operational Analytics 对数据新鲜度、延时、并发的要求,都远远超过传统的 Business Analytics。”张友东说。
应对这一挑战,企业往往会为不同业务搭建不同系统,形成所谓的“烟囱式架构”。这种模式不仅带来冗余存储和高昂运维成本,还导致指标口径不一致,难以跨场景复用。张友东强调:“StarRocks 希望成为统一的分析引擎,数据在湖上,不管是实时场景还是离线场景,都能直接使用。”
为此,StarRocks 在 3.0 版本转向存算分离架构,并针对实时链路和数据湖查询做了大量优化。
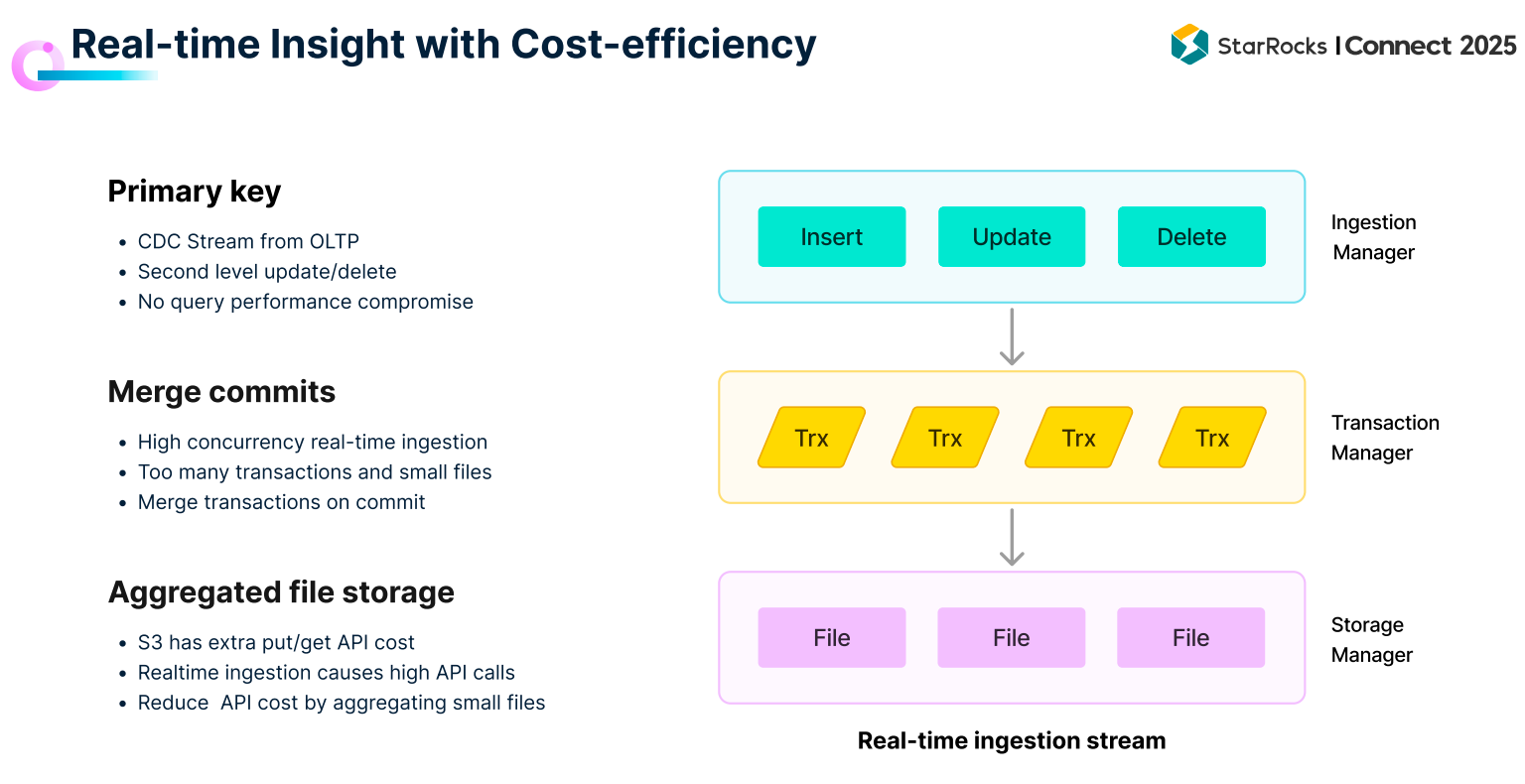
面对企业对实时性和成本的双重要求,StarRocks 已经在多个典型案例中展示了落地成效。张友东在演讲中分享了一些案例:在北美,Pinterest 的广告系统曾长期受限于 Druid 的多表 join 和实时更新能力,依赖复杂 pipeline 构建大宽表,成本高且稳定性差。迁移到 StarRocks 后,“线上 Druid 相对 P90 的延时下降了 50%,同时成本下降了 68%。”
同样在北美,体育电商平台 Fanatics 原本将 Iceberg 数据导入多个数仓,导致数据孤岛和高昂的计算存储成本。StarRocks 帮助其在 Iceberg 上实现统一分析,整体成本降低了 90%。
国内的淘宝闪购,则采用 Flink+Paimon+StarRocks 的实时湖仓方案,在海量订单高峰下实现分钟级新鲜度和百级并发,存储成本下降 90%,计算成本下降 50%。
AI Agent:不是追热点,而是做“Agent Ready”
AI 浪潮让所有数据 Infra 厂商都面临同一个问题:如何在新的链条里找到位置?
张友东的回答是:“AI 领域变化太快,今天大家谈 RAG,明天可能就是别的。作为底层数据系统,我们的策略不是去追逐每一个上层应用的热点,而是把 AI 所依赖的最核心、最不变的基础能力做到极致。”
他表示,AI 对数据的需求有三点是确定的:“第一,数据要新鲜,模型需要最新的信息才能做出准确判断;第二,访问要快,AI Agent 不能等几分钟才拿到数据;第三,数据处理要高效,为模型训练准备高质量数据。”
在这个思路下,张友东展示了一个 “StarRocks Agent Demo”。团队发现,用户在数据建模时常常困惑于如何选择分区、分桶和排序键,而这些设计对后续分析性能至关重要。传统方式需要专家经验,因此 StarRocks 尝试通过 Multi-Agent 协作来解决:把整个建表优化流程拆解成多个子任务(数据校验、Profile 分析、建表参数推荐),由不同的 Agent 分工完成,再合并结果输出优化后的建表语句。
“这种方式在多个真实业务场景中验证是有效的。”张友东介绍说。为了提升可靠性,StarRocks 还结合 MCP Server,让 Agent 能直接与数据库交互,并实时获取系统文档和运行状态,保证上下文准确。
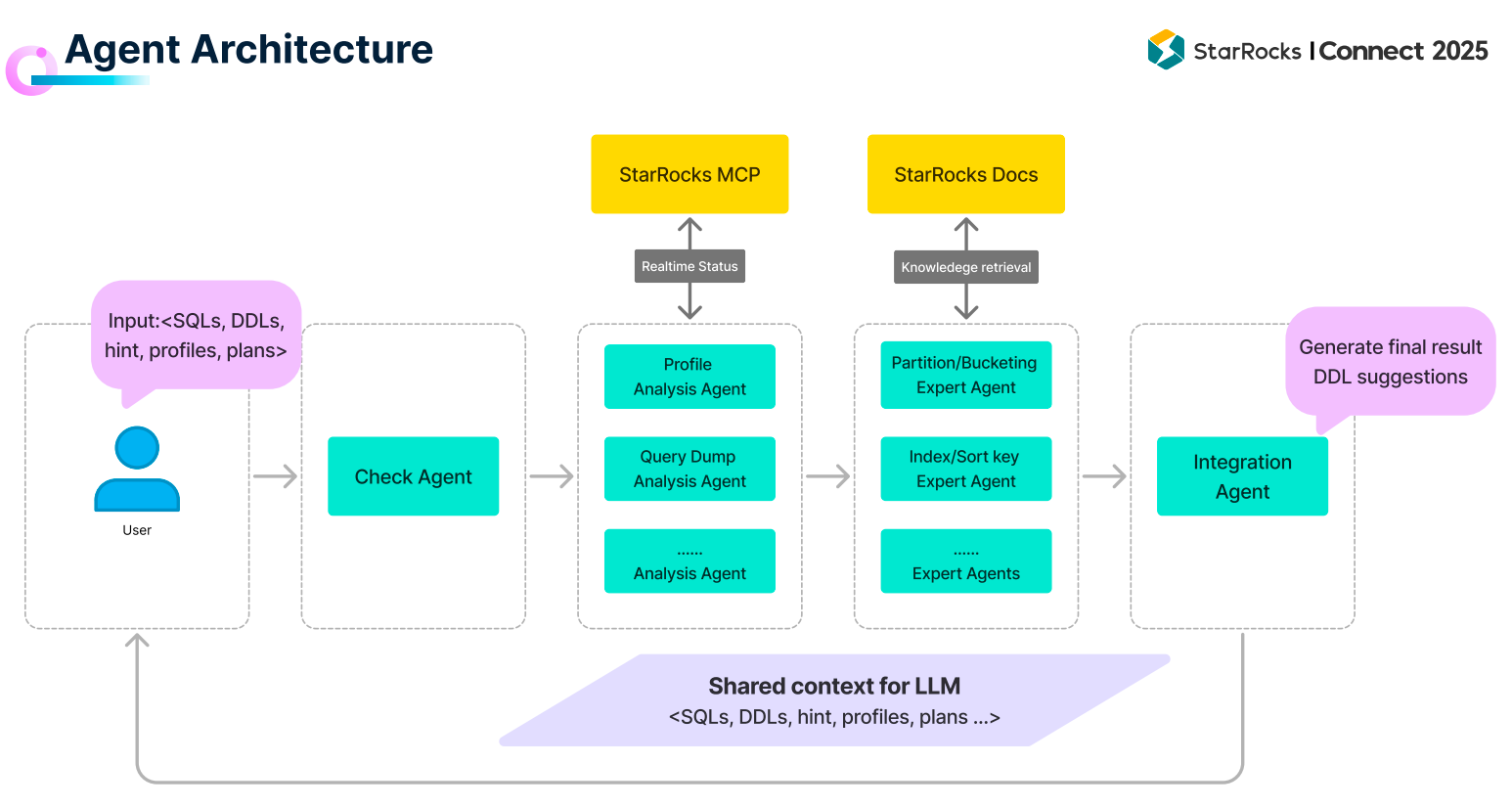
张友东总结,真正的“AI Agent Ready”至少包含四个条件:
自然语言接口:不管是通过 MCP Server,还是 Text-to-SQL,都要能被 Agent 直接调用;
实时上下文:系统运行状态、文档信息必须实时更新;
大规模低延时:Agent 的多轮交互要求极低延时和高并发支撑;
数据治理:底层数据如果质量不高,Agent 最终输出的效果也会大打折扣。
“我们希望 StarRocks 在未来不仅是 Lakehouse 的统一引擎,也能成为 AI Agent 的底座。”张友东说。
全球化竞争中的差异化路径
在拓展全球市场的过程中,StarRocks 不可避免地被拿来与 Snowflake、Databricks 对比。张友东提到:“过去几年,StarRocks 得到了全世界很多知名企业的采用,我们接触到的至少 500 家以上估值 10 亿美金的公司在使用 StarRocks。”
不过,他并不认为要在巨头的主场硬碰硬。“我们的策略是选择一个还没有被完全覆盖的、细分的潜力市场:当客户的业务对实时分析和查询延时有更高要求时,StarRocks 就是天然的选择。”
他补充说:“先把我们能做的场景做扎实,做到能力的优势比竞品足够强,到这个场景 60%-70% 的公司都默认选我,起码我这个公司的 PMF 就已经实现了,那我再考虑进入更大的市场。”
StarRocks 也在继续坚持开源路线。在本次大会上,张友东宣布 StarRocks 存算分离涉及到的 StarRocks OS Multi-warehouse 企业级能力将会正式开源。这意味着更多企业能够低门槛地构建复杂场景,同时继续在社区和商业版本之间形成良性循环。
“我希望在新的 AI 系统里,不管是加速 AI 构建,还是加速 AI 应用场景落地的系统,尤其是开源的系统,一定能跟 StarRocks 有很好的集成。”张友东说。
写在最后
从 Lakehouse 架构的普及,到实时分析需求的普遍提升,再到 AI Agent 带来的新系统要求,StarRocks 正在不断调整和强化自身定位。
在张友东看来,真正的竞争力不是短期追逐热点,而是在最核心、最确定的需求上做深做透。对 StarRocks 来说,这意味着既要解决当下企业的实时与成本挑战,也要为未来 AI 铺设坚实的基础设施。




