

软件即服务(SaaS)已经成为当今一种非常普遍的软件交付方式。虽然这方便了用户访问,而且消除了用户的运营开销,但这也改变了以前的模式,将实现 SLA 以及现代云原生组织所期望的所有安全和数据隐私要求的责任交给了软件供应商。这也是采用多租户等资源和成本效益架构模式背后的驱动力。
Jit是一个 SaaS 平台,通过自动化的声明式安全计划来构建最小可行的安全措施,其设计和架构可以满足在规模很大的情况下为许多客户和用户提供服务。因此,我们的系统架构其中一个主要的特征是支持多租户。然而,多租户伴有一系列的安全问题。作为一家安全公司,隔离和保护我们的租户从一开始就很重要,我们需要一个强大、安全、可扩展的多租户架构。
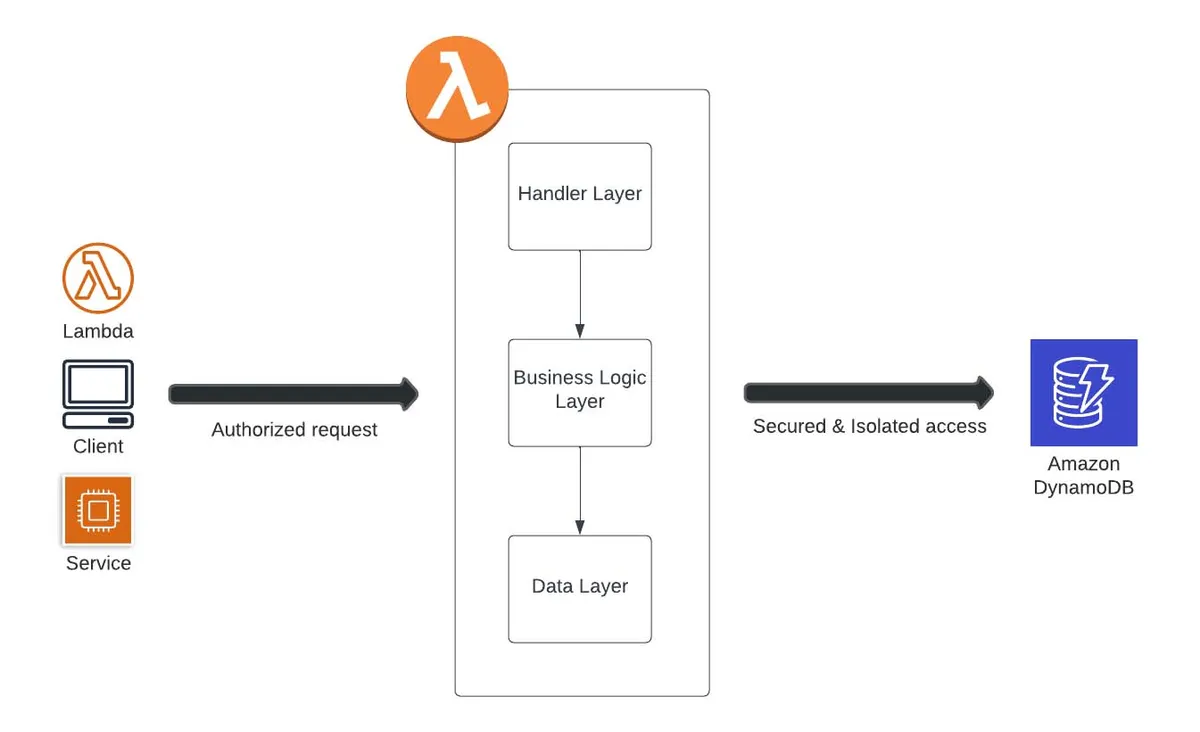
图 1:Jit 多租户架构
虽然网上有很多关于如何构建租户隔离的帖子,但最后一英里终归要具体到你的技术栈。在 Jit,我们的技术栈主要是 Python 和无服务器,以及一个用于读写操作的 DynamoDB 后端。在针对这种架构寻找实现隔离租户的好方法时,我们发现了很多关于 Python+DynamoDB 的优秀的帖子。但是,关于在无服务器架构下向数据层传递凭证的资料相对较少,所以我想分享下,如何为云原生无服务器技术栈设计和实施多租户。
在规模很大的情况下实现多租户面临的挑战
我先从基本情况说起。现如今,为了提高资源利用率,许多 SaaS 产品都选择了多租户架构设计。多租户意味着不同的客户共享基础设施资源,而且基本上是通过一个“租户”系统进行逻辑分割,每个租户被分配给一个客户。然而,像任何基于资源共享的系统一样,这种架构也是既有好处,也有挑战。
多租户系统的主要问题是,如果没有在早期阶段设计好租户之间的数据防泄漏功能,那么长远来看,可能会产生严重的后果。数据泄漏发生的原因很多,可能是代码不够严谨或开发人员的错误,也可能是特定的恶意攻击——攻击者获得了一个被泄漏的令牌,然后利用系统升级权限,获得对其他数据的访问。
在考虑如何缓解这种情况时,我们发现主要有两种方法。一种是 Silo 隔离模型,基本上是完全隔离,它会在系统中为每个租户创建一个完整而独立的栈,没有任何池化或共享的资源。虽然这种解决方案非常安全,但它的可扩展性和资源效率都不高,成本却很高。我们意识到,长期来看,这并不是一个好的系统架构。
另一个选项是池隔离模式,这也是 SaaS 系统通常选择的模式——创建一个资源池(例如一个共享表),并通过特定的 IAM(身份和访问管理)角色来隔离数据,授予每个租户对相关数据的访问权。这意味着,你将把数据保存在一个共享表中来实现数据池化,同时通过一个经过验证的角色来限制数据访问。
为无服务器应用设计租户隔离架构
为了实现数据访问隔离,我们将动态生成访问 DynamoDB 表时使用的凭证。典型的 JWT(JSON Web Token)会包含租户 ID,可以用它来限制访问。

图 2:租户隔离架构
为了生成凭证,我们需要创建一个动态策略,通过特定的模式限制对 DynamoDB 表的访问,并在用户请求时用它确定一个角色。在验证用户并创建动态角色时,这会授予 DynamoDB 表的访问和查询权限,前提是表的主键(PK)是按租户组织的。
生成动态策略
我们的主键是按租户组织的,以下是数据库中数据项的例子:

我们希望生成一个策略,让我们可以只对属于特定租户的数据项进行操作。为了做到这一点,我们将利用条件语句“dynamodb:LeadingKeys”,只允许访问键值以给定值开头的数据项。实际的做法如下所示:
在“Action”中,我们应该提供一个数组,其中包含该策略允许的 DynamoDB 操作,可以是“dynamodb:*”(可用于所有 DynamoDB 操作)或任何特定的操作集。
可以看到,在这个例子中,引导键有两个选项。第一个是针对我们这种情况,第二个是针对多属性键(例如“TENANT#<id>#NAME#<name>”)。
使用策略生成会话凭证
下一步,我们将使用生成的策略来确定一个角色,并使用返回的凭证来访问数据库:
重要提示——要达到预期效果,我们必须:
在 AWS 账户中预定义一个要使用的 IAM 角色。这个角色应该有广泛的 DynamoDB 权限,并且与我们的 lambda 角色建立了信任关系。
授权 lambda 承担预定义的角色。如果使用无服务器框架,则可以在
provider.iamRoleStatements下声明。
在 lambda 函数中使用凭证
现在,我们可以使用刚刚创建的凭证初始化一个 DynamoDB 表对象:
在弄清楚我们打算如何保护表中的数据后,下一个问题是如何在我们特定的技术栈中做到这一点,这个过程有其本身的复杂性。
我们知道,在初始化 lambda 函数的执行时,需要生成动态策略,确定角色,并获得查询 DB 时需要使用的凭证。然而事实证明,理论上容易,实际做起来并不简单。
首先,让我们了解一下,为什么要在处理程序的代码开始运行之前在处理程序层中生成凭证(而不是在数据层中)。其中一个原因是,lambda 事件包含一个 JWT 头,其有效载荷最终会包含一个经过验证的租户 ID。我们希望以最安全的方式使用该租户 ID 来生成凭证,还不必将事件对象一直传递到数据层。另一个原因是,数据层是通用代码,不应该包含任何外部逻辑。处理程序层实现这种设置似乎最合适。
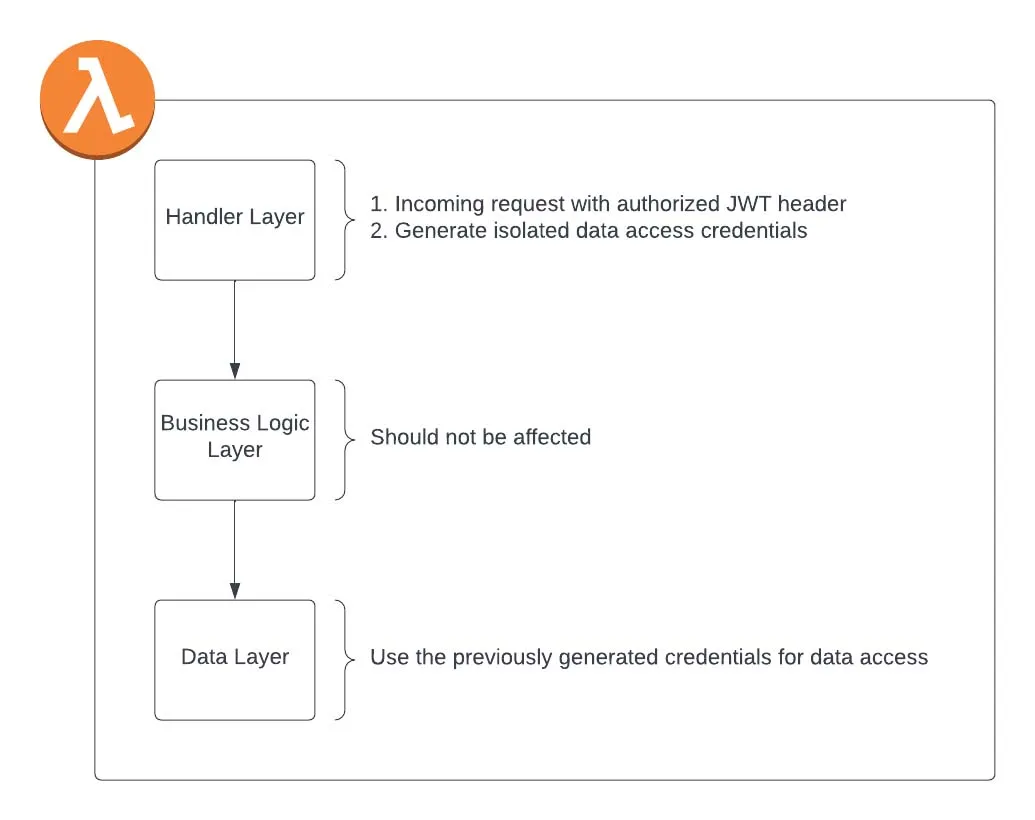
图 3:租户隔离层
第一部分比较简单——我们使用 Python 装饰器实现了动态策略创建。这可以在处理程序之上实现,甚至可以通过中间件实现——然而,在策略方面,最重要的事情是它在 lambda 代码之前运行,从而在处理程序执行之前创建凭证。
将凭证传递给数据层
比较难的是找出在实际中如何将这些凭证一直传递到数据层,我在研究中没有发现多少信息。我们想出了几个解决这个问题的方法,但每个想法都面临不同的挑战。
我们考虑的第一个解决方案是通过请求上下文传递凭证。这样一来,我们就必须把这些数据从函数处理程序,通过业务逻辑层,一直传递到数据层。这就导致了一个问题,即必须通过不需要这些参数的业务逻辑层,这可能会对服务的逻辑层造成干扰或导致冲突。这对我们来说风险太大。
我们探索的另一个解决方案是声明一个全局变量,但这本质上会与共享全局状态的 lambda 运行时发生冲突。也就是说,同一个 lambda 的多次执行会冲突,并影响函数的执行。其结果可能是,如果两个不同的租户同时发出多个请求,那么该函数有可能将一个租户的凭证泄露给另一个租户(这正是我们首先要避免的情况)。反过来说,如果收到错误的凭证,那么发出请求的租户在试图查询数据时就会收到错误,因为租户 ID 是错误的,无法验证。
所以这也是不行的。我们继续讨论。
ContextVars
然后我们发现了一个标准的 Python 库,正好可以用于这种情况。它名为“ContextVars ”,适用于 Python 3.7 以上版本(通过开放库对早期版本提供部分支持)。这个库使我们能够在一个特定的运行时上下文中保存全局变量。使用这个库,我们可以为每个传入的请求创建一个新的运行上下文,并将值保存到一个只在该上下文中可用的全局变量上。然后,当在同一个上下文中运行并访问这个全局变量时,就可以得到相关的封装数据。
要了解更多信息,请查阅Contextvars文档。
这解决了环境变量的全局调用问题,并为每个请求提供了特定的上下文调用。
在下面的代码片段中,我们实现了一个装饰器,它创建了一个新的上下文,并在该上下文中运行 lambda 处理程序。这样,对dynamodb_session_keys的任何访问都将绑定该调用上下文,并将一个调用数据从另一个中封装起来。
现在,可以让装饰器创建动态策略和凭证,并将其保存在绑定上下文的全局变量中,最终创建一个输出(export),使得在数据层中接收绑定上下文的凭证成为可能。
从数据层访问凭证的代码如下:
然后在 handler.py 文件中将它们钩连在一起:
这个解决方案为我们基于 Python/lambda 的架构提供了一个扩展性更高的、健壮的租户隔离,而又不会与服务的业务逻辑层发生冲突,也不会在多个请求中泄漏数据。借助 Python 的功能,如装饰器和 contextvars,我们就能够创建一个适合我们特定场景的解决方案。与其他有效的解决方案相比,它与我们现有代码库的冲突几乎可以忽略不计。
我们在这个GitHub库中提供了完整的例子。
作者简介:
Avichay Attlan 是 JIT 的一名全栈工程师。JIT 是面向开发者的最小可行安全平台。Avichay 拥有以色列本古里安大学软件工程学士学位,并在多个领域和技术栈中担任全栈开发人员,从半导体到 VoIP 和商业通信,再到如今的云安全。他曾受雇于英特尔、Vonage(被爱立信收购)等头部组织。现在在 Jit,他专注于在开发工具中构建无摩擦的安全。
原文链接:
Designing Secure Tenant Isolation in Python for Serverless Apps

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论