

视频搜索是涉及信息检索、自然语言处理(NLP)、机器学习、计算机视觉(CV)等多领域的综合应用场景,随着深度学习在这些领域的长足进展以及用户对视频生产和消费的广泛需求,视频搜索技术的发展在学术和工业界都取得了飞速的发展。
阿里文娱高级算法专家若仁在 GMIC 2020 分享了视频搜索技术和多模态在视频搜索领域的应用,本文整理自演讲速记,希望能给关注或从事视频搜索方向的算法同学带来启发。
考虑到大家来自不同的业务领域和技术方向,我会先简单介绍优酷视频搜索的业务背景,同时快速介绍搜索的基本评估指标、搜索系统的算法框架以及相关性和排序模型,让大家对视频搜索有一个更全面的认识,后面重点介绍多模态视频搜索相关技术。
阿里文娱搜索现状
搜索团队为整个阿里文娱提供一站式的搜索服务,服务范围包括优酷 Phone 和 OTT 端,还包括大麦、淘票票。涉及的检索内容,从影剧综漫的长视频影视库,到覆盖社会各领域的 UPGC 视频。此外,影人和演出场馆也在搜索服务覆盖范围内。以优酷为例,我们有数亿视频资源,不仅包括平台购买了版权的 OGC 视频,更多是用户上传的 UPGC 视频。 视频的存储、计算以及分发,比文字更具挑战。
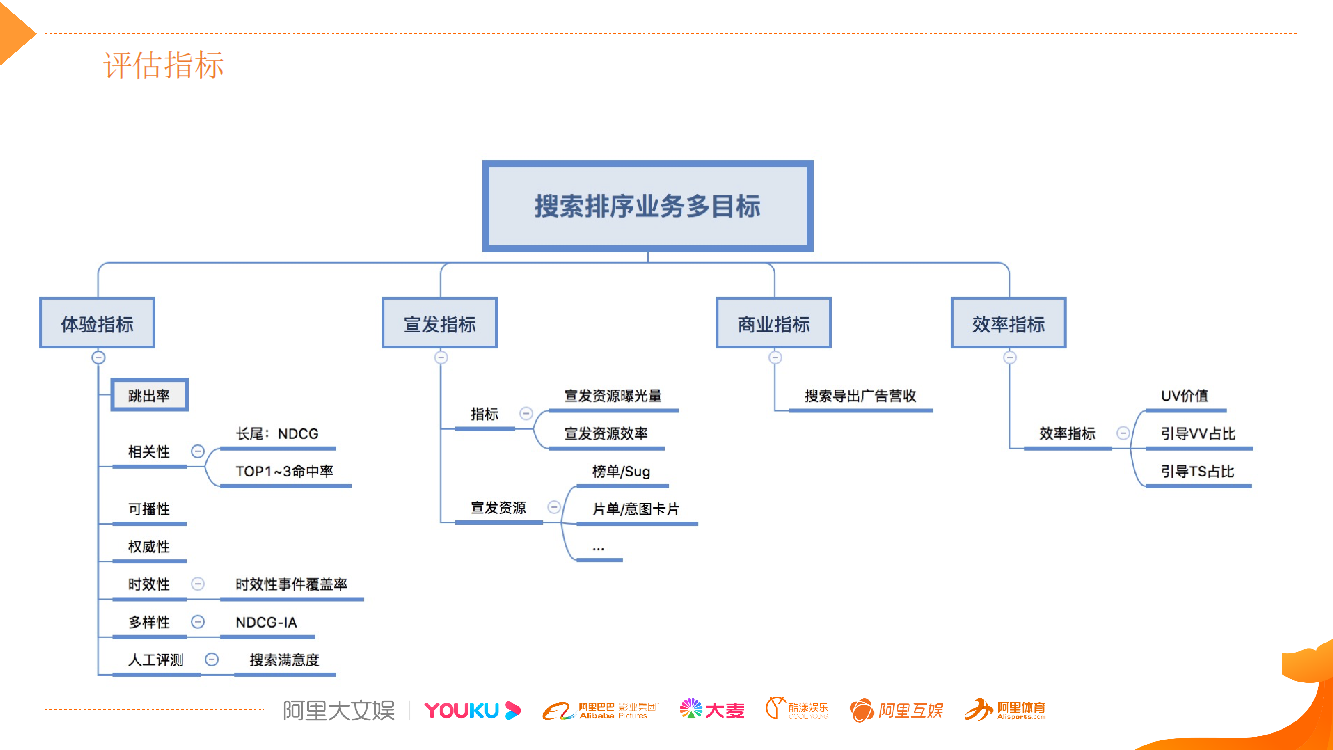
搜索技术的用户价值主要体现在两个维度:
一是工具属性。用户将搜索服务作为寻找内容的工具,目标是“找准,找全”,即“搜的到,搜的准”。从这个维度去评估搜索效果的好坏,需要一系列的体验类指标,比如跳出率、相关性,以及时效性和多样性,这些都是搜索通用的技术指标。所谓可播性指在应用上能播放,这是全网视频搜索特有的,受内容版权和内容监管多方面的原因限制,有一些内容是平台无法播放的。 此外,我们还会定期进行人工评测,做横向和纵向比较。
二是分发属性。让用户消费更多的视频内容,有更多 VV(观看视频数)以及 TS(消费时长)的引导。这些指标对于垂直搜索非常重要,也是对用户满意度最直接的衡量。对于平台来说,搜索还能支持平台的宣发和商业价值,实现广告/会员的商业价值,前提是将用户体验做好。
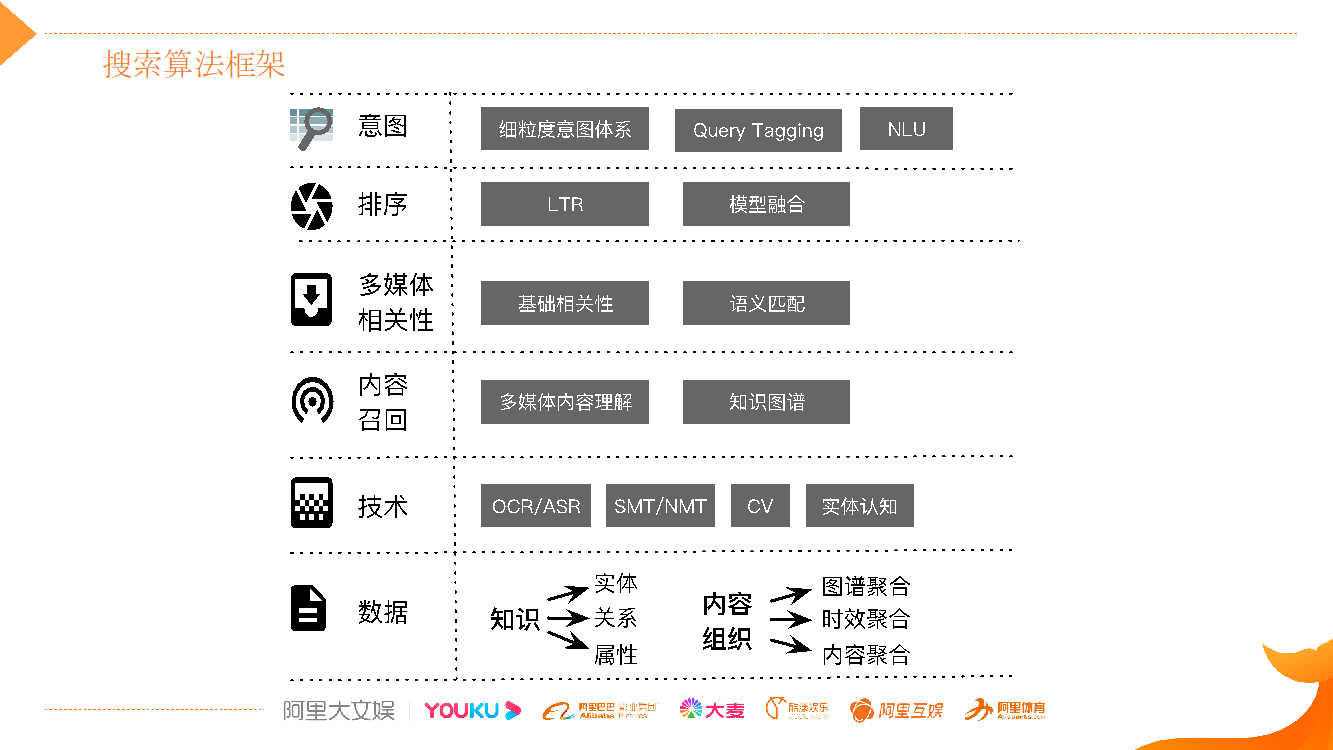
搜索算法框架如上图所示,由下到上依次是数据层、技术层、内容召回、多媒体相关性、排序、意图。
1)数据层:视频内容数据是最基础的,我们从视频内容中抽取出对应的知识,包括实体、实体之间的关系以及属性。通过内容组织的方式,以图谱知识去指导我们做聚合,从时效性的维度做聚合,从多种维度将内容组织起来;
2)技术层:在数据基础之上,利用 CV 和 NLP 技术,支撑上层内容召回和相关性、排序,以及对 Query 的意图理解;
3)召回层:对多媒体内容理解是难点,下文会详细展开讲;
4)相关性:包括基础相关性/语义匹配技术;
5)排序层:按照体验和分发等维度,去提升搜索整体体验。排序利用机器学习排序学习的方式,去提升分发效果,此外还要优化体验类目标,如时效性、多样性等,同时也要实验平台的宣发等目标,是典型的多目标优化场景;
6)意图:对 Query 意图理解,首先要对 Query 做成分分析,标明 Query 各成分是什么,是节目名还是剧集信息。然后要建立细粒度的意图体系,对用户表达的意图去做深层次的意图理解,从而更精准地指导召回、相关性和排序。
多媒体内容理解是视频搜索的重点,视频内容传递的信息是非常丰富的,不可能用标题的短短十几个文字描述全面。用户在检索时,表达需求的差别非常大,这就是天然的语义鸿沟。所以我们不能把视频当作黑盒子,需要利用 NLP 能力、CV 的能力以及其他技术能力对视频内容做全面的分析解构。
视频搜索的相关性和排序模型
1 挑战
相对通用搜索,视频搜索存在特殊的挑战。第一个挑战是内容相关性匹配,下图中前两个 Case 体现出用户表达的 Query 和视频标题不是那么相关,需要通过对内容理解分析,丰富其元信息,建立起内容相关性。
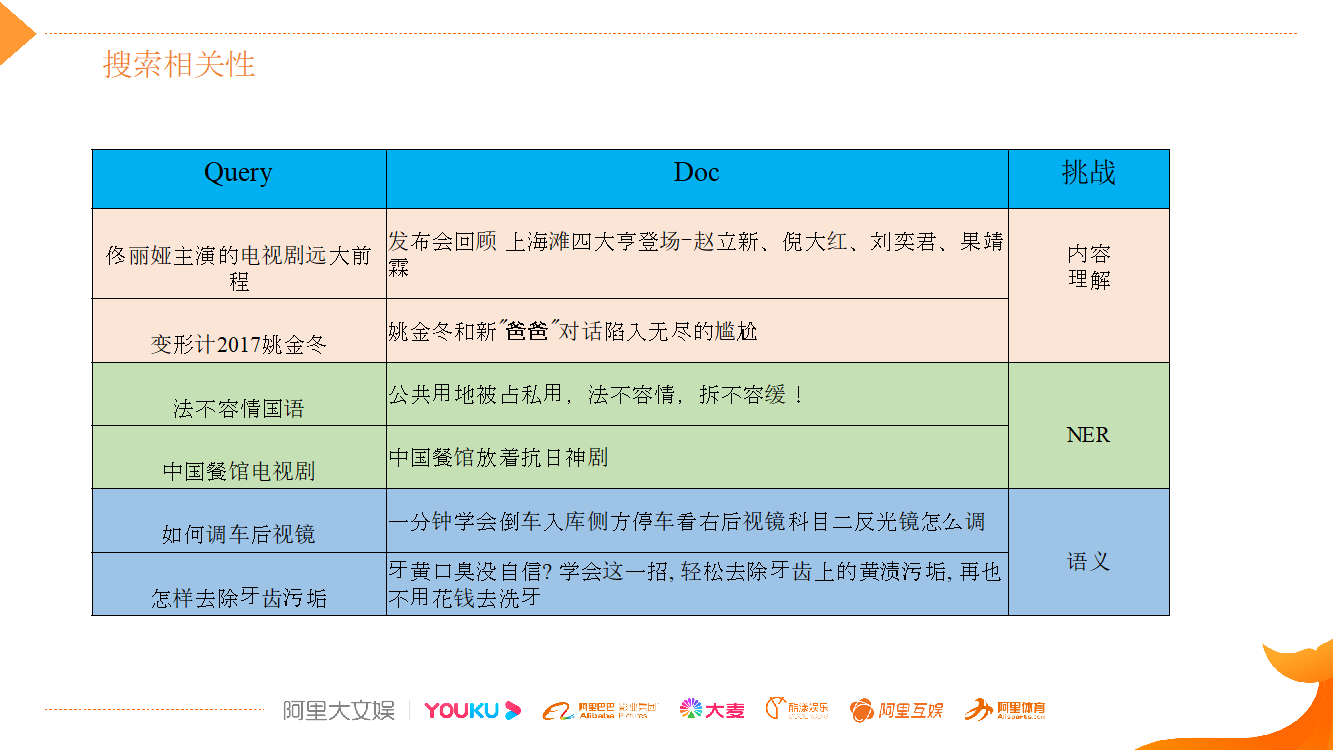
如“变形计 2017 姚金冬”,视频标题中只有“姚金冬”,实际上通过视频内容的理解,可以知道“姚金冬”和“变形计”,并且是 2017 年的。通过内容理解和 IP 指纹,把 IP 周边视频,如切条或二创视频,和 IP 建立起关联关系,能大大丰富视频的元信息,提升内容相关性匹配度。
第二个挑战是实体知识匹配。我们要借助于视频标题的结构化去理解,用 NER 方式抽取出来,同时也需要 CV 的技术去辅助 NER 识别的准确率。比如“法不容情国语”,QP 端理解出“法不容情”是一个节目名,这就是 Query 的成分分析。用户上传的是“公共用地被占私用,法不容情”的社会问题,需要对文档端做结构化的理解,要理解出“法不容情”在上下文中不是节目,而是其他意思,然后在相关性匹配的时候,利用这些先验知识做更好的相关性判断,从而决定相关性匹配度。 此外,“中国餐馆电视剧”这个 Case 也类似,用户找的是《中国餐馆》节目,而不是需要检索出“中国餐馆放着抗日神剧”。
第三个层面的挑战是语义匹配。当然,通用搜索也有语义匹配问题,一些语义类/How to 类的知识匹配,要去做语义和更全面的分析,比如利用内容理解和实体知识的辅助补充等,才能做好语义匹配。
2 解法
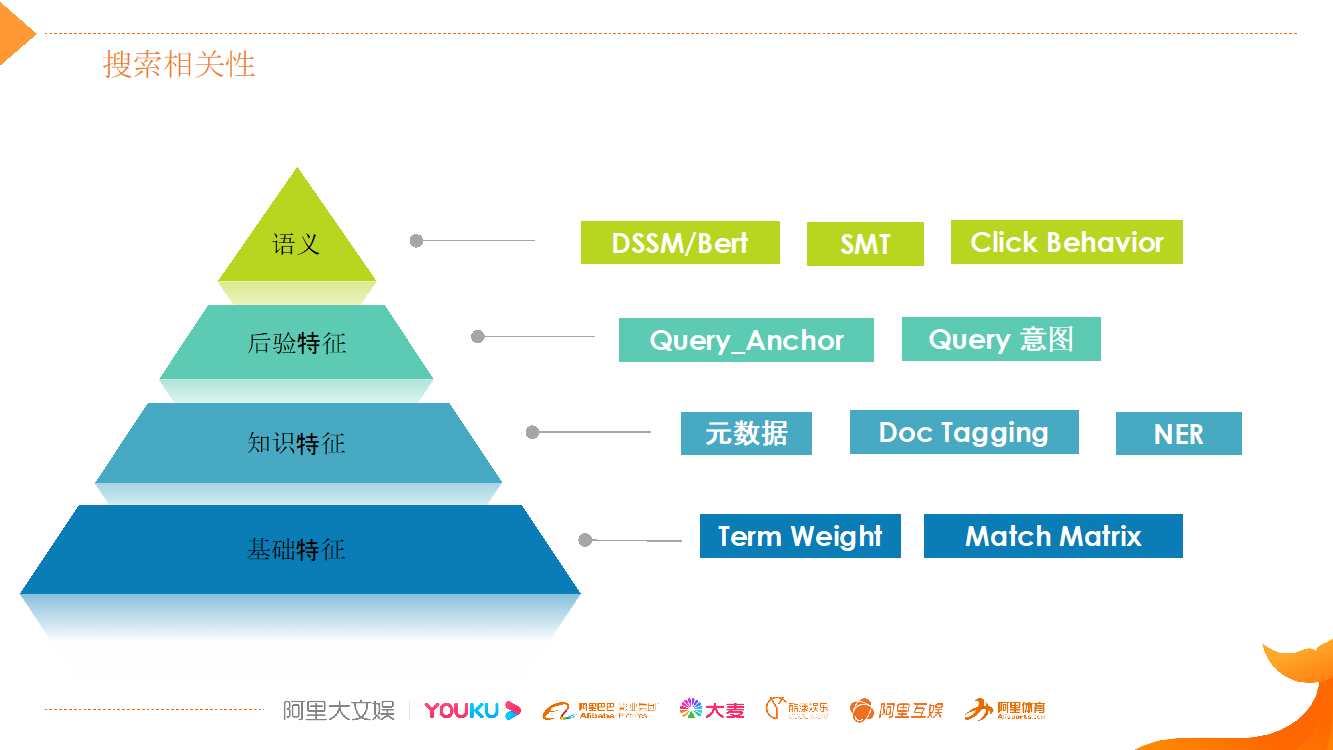
我们整个视频搜索相关性是从四个维度去做:
1)基础特征:基于基础文本的特征匹配,包括 Term Weight、匹配矩阵等;
2)知识特征:通过内容理解以及视频自身所带的元信息,例如视频中的人物所关联的节目相关的元信息,以及针对视频标题所做的结构化理解,比如抽取出哪部分是人物、哪些是 IP 名、哪些是游戏角色等。标题结构化之后,根据 Query 成分的理解,支持在知识层面去做匹配;
3)后验特征:因为用户去搜索 Query 之后,搜索结果之间会产生交互,形成 Query 和 Doc 的交互特征。Query_Anchor 以及通过这些交互特征能够指导 Query 意图的理解,把他们作为这种后验关联的一些特征,能够支持我们这种意图匹配。
4)语义:文本层面的语义匹配,利用 DSSM 语义模型和 Bert 语义模型,做离线和在线的语义匹配模型。除了这种匹配层面之外,还要支持语义召回。通过 SMT 和点击行为分析等技术,进行语义扩展,扩大召回语义内容的范围,利用它们形成的特征做更好的语义匹配。
3 相关性数据集构建和特征体系
全面准确地发现问题是解决问题的基础。构建相关性数据集的目的是给相关性算法提供 Ground Truth,标注是重点。相关性标注数据集的标注规范较复杂,标注样本量比较大,一般会通过外包进行人工标注,需要重点关注的是标注质量和标注成本。根据标注规范不仅要去标注样本的等级,对同等级下的样本还需要标注偏序关系,质量的把控特别关键。对于成本来说,需要有高效的样本挖掘机制和方法。
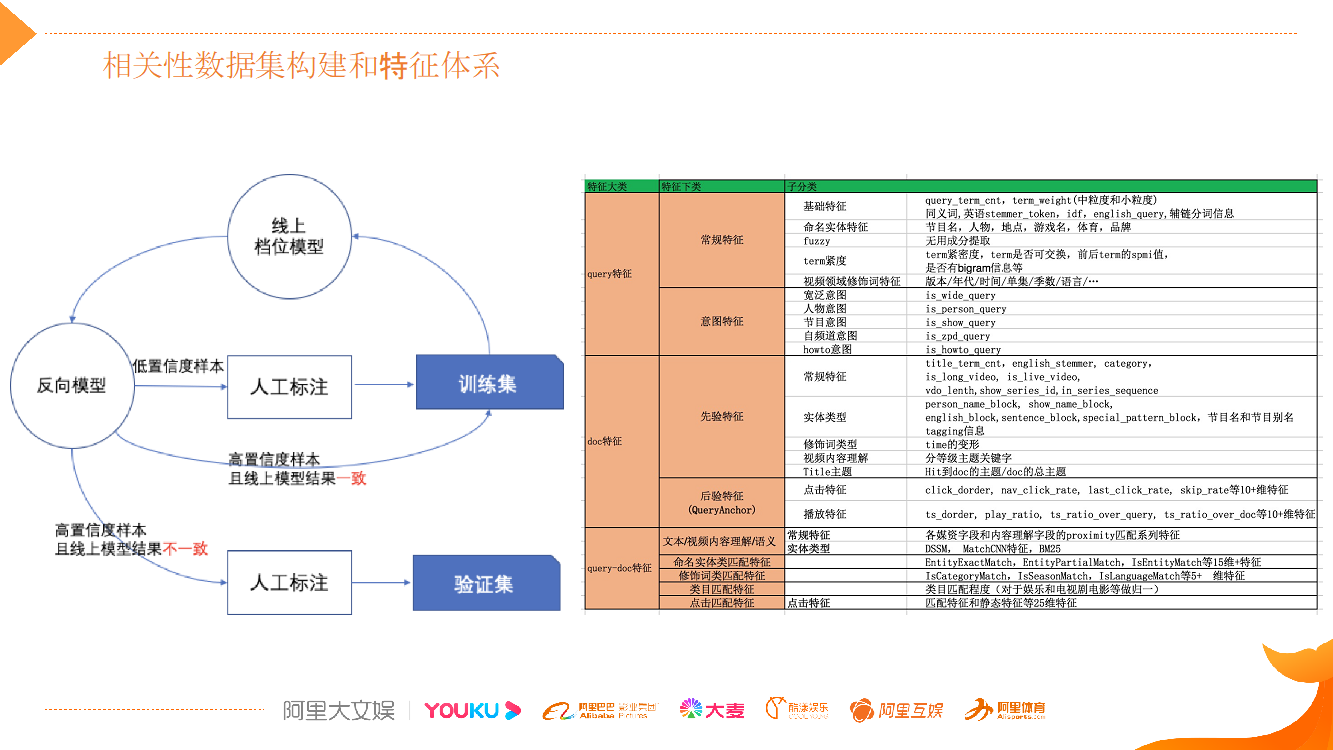
如图中左侧所示,可以通过 Active Learning 的思想来加快标注的效率提升,同时也能提升标注质量。 我们可以基于训练集不断地迭代线上模型,对于线上模型预测不是那么准确的样本,可以提供给外包同学去检测标注,形成一个快速的迭代闭环,提升训练的精度。大家用这种方法去做,能够大大提升整个标注的质量和效率。
右侧是相关性的技术特征,最上层是 Query 相关的特征,有常规类的,非常基础的文本特征;有意图理解输出的特征,比如说人物、节目、宽泛、How to 类意图等;文档端的先验特征包括从文档标题解构出来的特征以及基础文本特征,除了先验特征还会使用前面说的后验特征;最下层是 Query 和 Doc 的匹配类特征,匹配特征也会分基础匹配、意图匹配、语义匹配、知识匹配这几个维度。
4 排序特征体系
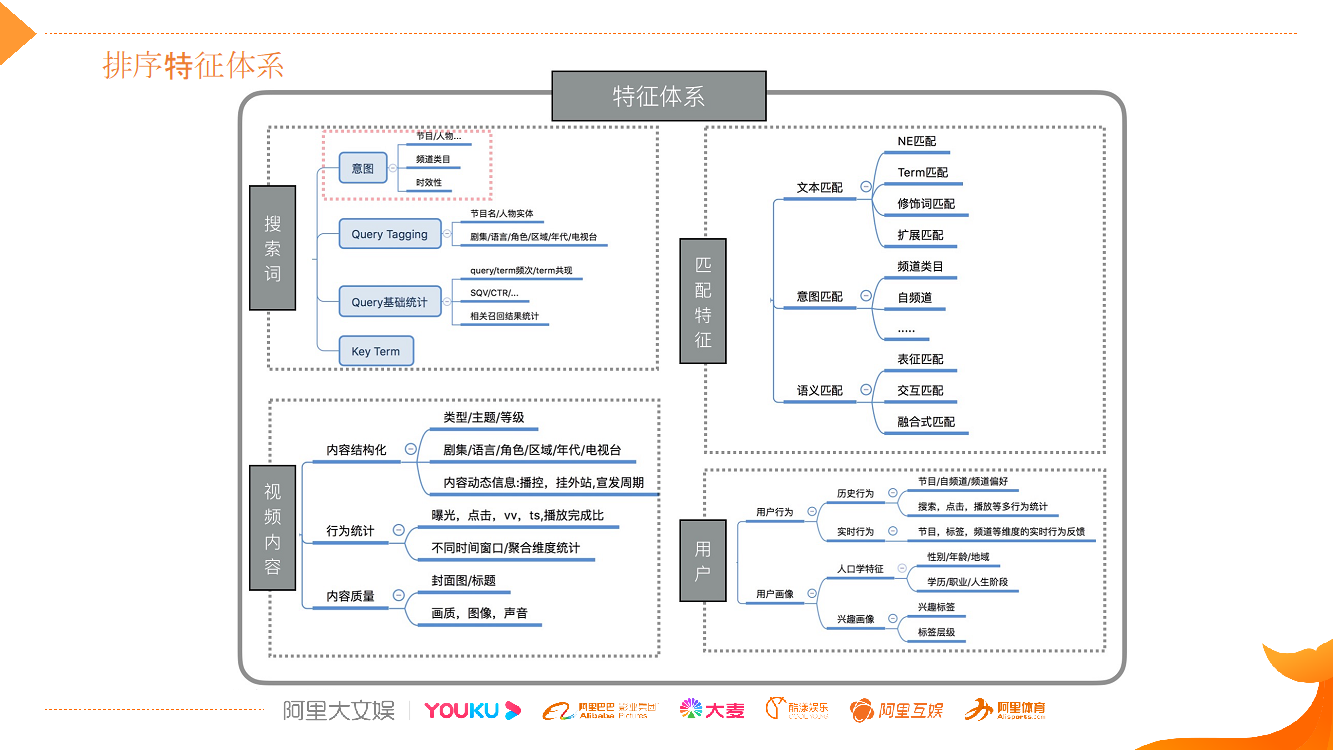
搜索词特征组:搜索词以及匹配特征这些特征类别,是搜索领域通用的;
匹配特征组:有一些特征是平台特有的,比如视频的实时播控、内容宣发特征;
视频内容特征组:内容质量对于我们的平台非常重要,因为每天上传视频量非常大,需要做好内容质量的评估,才能更好地指导冷启动的分发。我们人工智能部有一个 CV 团队,负责为我们提供高质量的特征,从封面图、标题、画质/图像/声音各模态去评估视频质量;
用户特征组:用户行为特征,用户画像及用户行为的表征学习特征主要用在一些宽泛搜索场景。例如频道页的搜索排序、 OTT 宽泛意图排序等。
接下来分享 2017 年,我们和达摩院在搜索上落地的表征学习排序方案。
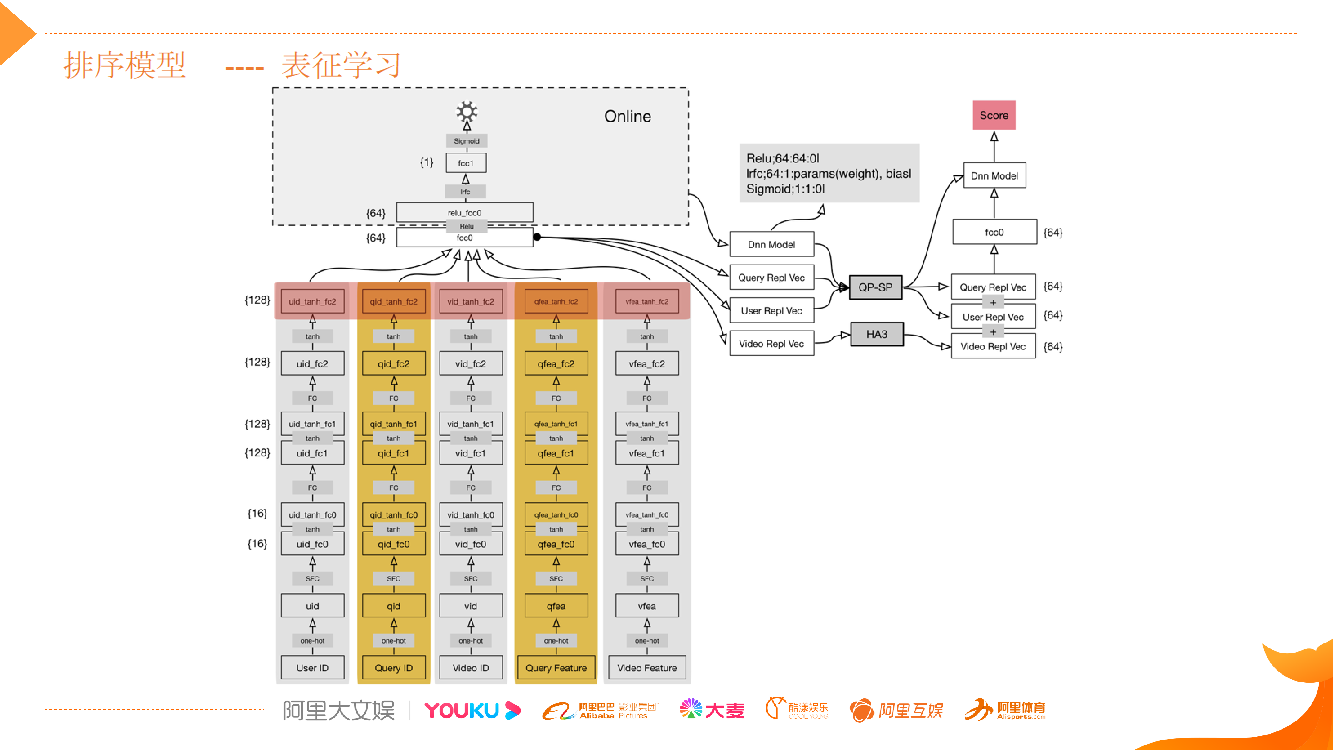
第一层是特征域编码层,按照用户、搜索意图、视频三元素划分。在用户维度,划分了用户 id 域、用户观看视频序列域;搜索意图维度,划分了搜索词 id 域、搜索词视频表达域、文本编码域;视频维度,划分了视频统计特征域、视频文本编码域、视频 i2i 域。
第二层和第三层不同特征域间网络结构相互独立,通过稀疏编码优化的全连接层对第一层的高维特征域进行降维,把高维信息投影至低维的向量空间中。
通过第三层全连接层对域内信息进行二次编码,输出域内特征向量。
通过第四层把 concat 层链接起来,对域间的 id 特征向量、行为特征向量、文本特征向量和观看序列特征向量做多模态的特征向量融合。
之后经过两层的全连接网络实现对给定用户和搜索意图下每个视频的排序分值的预测。这个模型是内容分发的一个排序模型,它同时还会结合相关性模型、时效性,以及视频质量等从多维度做模型融合,来决定最后的排序。
多模态视频搜索实践
基于标题和描述等文本信息的检索会遇到很多困难。
首先是单模态信息缺失,用户在上传 UGC 视频的时候,标题是比较简单,很难将丰富的视频内容表达清楚,有时这些文字信息还和视频内容是没有关联关系的;
其次是用户搜索意图越来越多元化,即使是版权视频的搜索也不再集中于节目名字的搜索,社交与互动的需求逐渐增长越来越多;
还有 To B 侧的需求,也就是内容二创的用户,需要去找各种各样的视频片段,视频素材,这部分的需求也需要用多模态技术去支撑。
基于多模态技术的搜索,将语言、语音、文字、图像的各种模块集中起来,综合这些信息来理解,能够方便用户更好地找到所需内容,得到更好的搜索体验。目前在工业界和学术界对多模态搜索的研究热度都非常高,学术界有很多方案是基于将 Query 和视频映射到一个中间 Concept 的空间,然后在中间维度做相似度的匹配排序。此外,也有 VQA/GQA 等各类基于视频问答的数据集去推动自然语言和图像的关系推理,最近 Video/Visual Bert 的端到端的解决方案也有了很大的突破。
学术界喜欢这种端到端的解决方案,对于短小视频的理解可能确实是不错的方案。但针对长视频,这些方案很难真正做到准确的理解。因为长视频包含的内容信息更多维、更宽泛。此外,工业界的搜索引擎需要有可解释性和可控性,很少采用单一端到端的解决方案。
优酷的多模态搜索采用的技术方案是:
利用 CV 算法技术,将其他模块的信息降维到文本模态;
通过多模态内容检索的技术实现召回;
再从上层通过内容相关性和排序技术,满足用户对内容各维度的检索需求。
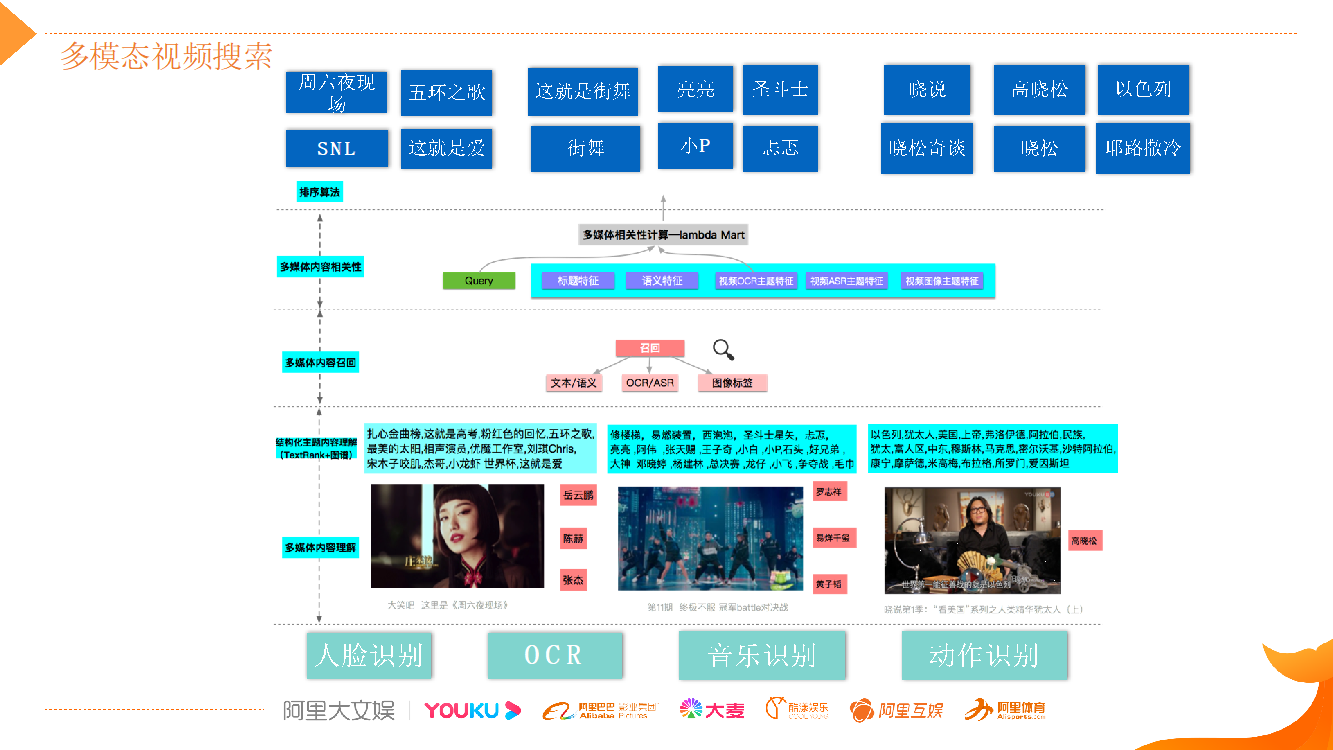
例如,基于人脸识别的技术,识别出视频中出现的明星人物,如《这就是街舞》视频中识别出易烊千玺、黄子韬等;通过 OCR/ASR 技术,识别各视频中的对话内容并转化成文本,然后基于文本去做结构化理解。
结构化的文本需要有系统性的理解和组织,可以利用关键词抽取技术把它理解好并形成我们的内容主题;同时我们还会利用音乐识别、动作识别、场景识别、情绪识别等 CV 技术,不断丰富解构内容,进而做到用户做各种组合搜索的时候,我们都能够召回,还能排的比较好。
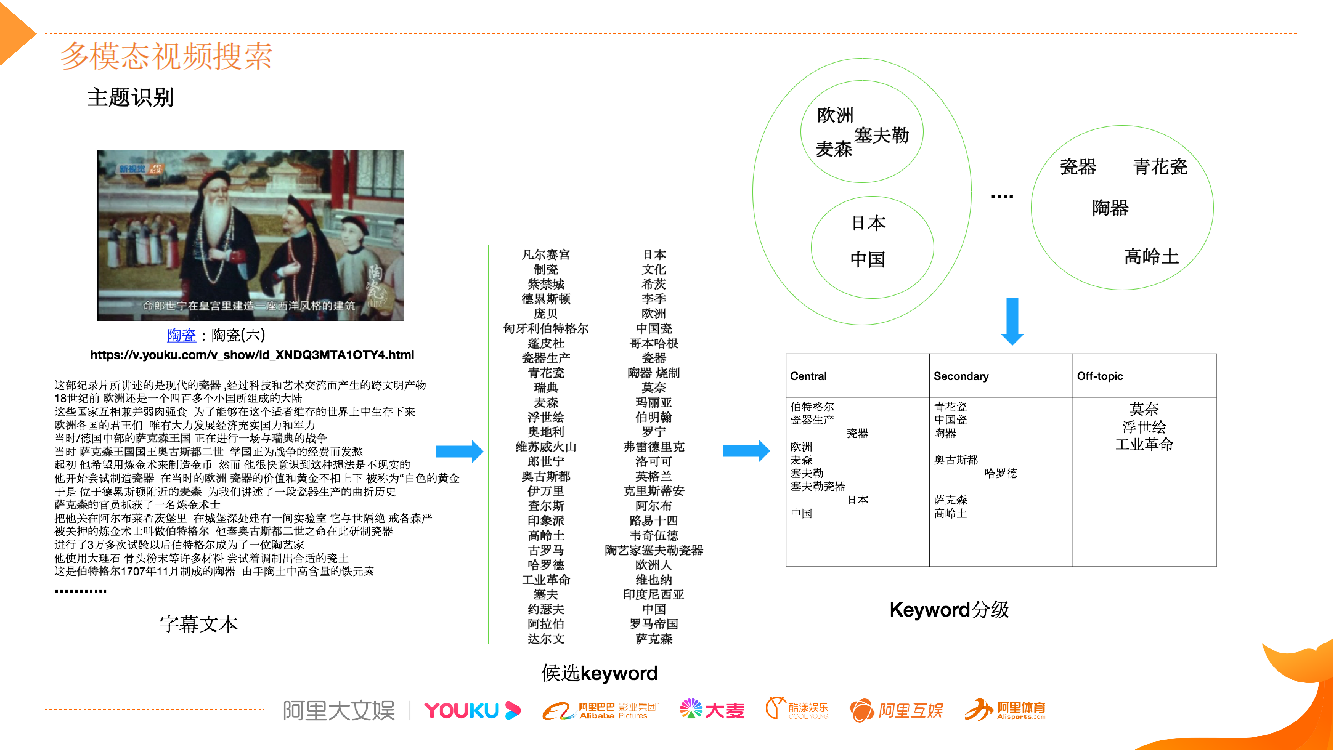
上图是用一个案例来介绍我们在多模态视频搜索时,如何更好地组织内容关键词,视频内容降维成文本之后,怎么做好这些文本内容的组织理解。
首先,这个案例中,内容关键词的词库是非常非常大的,此外内容和关键词属于多对多的关系。我们要通过各种关键词抽取技术来抽取候选的内容关键词,并且要扩大候选词来源的多样性。比如基于“NER”的方法能确保抽取的内容关键词是百科类实体名称,有较广泛的知识内涵; “新词发现”方法会综合 Ngram 以及语言模型(LM)等多种基础能力扩大对未知知识领域的挖掘。
候选关键词是不断扩充的,随着我们在视频内容理解的维度扩大,候选关键词的来源会越来越丰富。在丰富的内容候选关键词基础上,根据内容候选关键词和视频内容相关程度构建分类模型预测不同的等级,最相关的是核心内容关键词,其次是相关内容关键词以及提及内容关键词。然后关键词分级的核心特征除了文本特征之外,还会采用音频/视频表征网络生成的一些多模态特征来共同训练,进而提升预测关键词相关度的准确率,把关键词和内容表达的关联度预测得更精准。
这么做存在一些问题,以图中视频为例,该视频主要是讲欧洲瓷器的发展史,但是该视频文本标题是“陶瓷:陶瓷(六)”,非常简短的描述,对它做内容理解降维成文本后,我们能够利用上面讲到的技术抽取内容关键词“塞夫勒”、“麦森”,但是如何把“塞夫勒”、“麦森”和“欧洲”关联起来,知道这个视频讲的是欧洲瓷器发展史,而不是中国或者日本?此外对于瓷器领域知识实体,“陶器”、“青花瓷”、“高岭土”,怎么把它们和“瓷器”概念关联起来?
这些都需要有知识图谱(KG)支撑,这就需要 KG 实体知识库涵盖广泛的领域,需要有全行业的丰富实体,才能帮助我们提取核心内容主题。另外像抽取的内容关键词“伯特格尔”是个人名,但是要用什么技术才能使它和内容主题相关程度识别准确?知识库不一定能收录,单纯通过频次也不一定能理解准确,但是“伯特格尔” 被“他”指代提及多次,算法需要有这种指代推理能力,才能把这样的关系理解出来。有了这些关系的理解,才能基于内容关键词去理解整个内容事件、内容主题,以及内容故事线等不同层级的抽象,才能够更全面地理解视频,然后更好地支撑上层的召回匹配和排序。
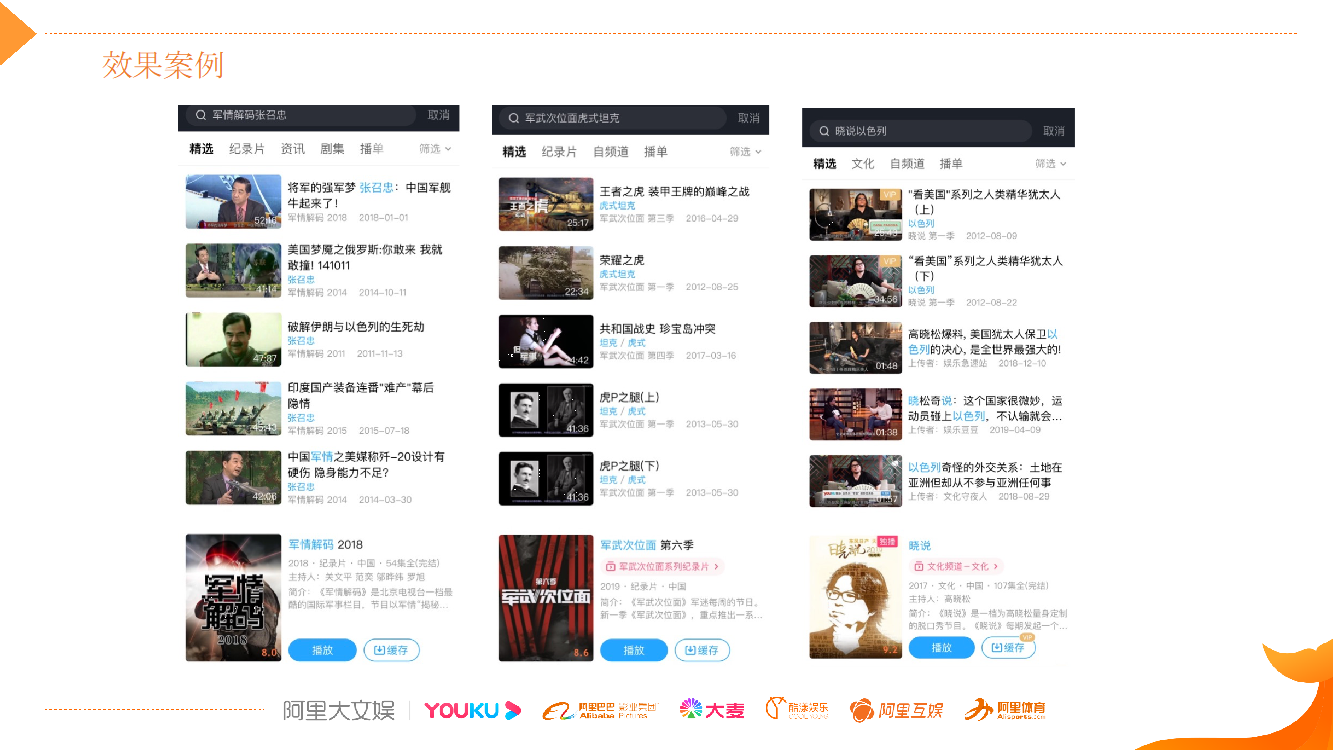
目前,我们做的这些探索都已经在优酷上线了,在线上能看到效果。当用户搜索“军情解码张召忠”时,排前面的这几个视频内容都是“张召忠”主讲的,但是在标题文本里面其实没有“张召忠”这个名字,我们的算法通过内容理解的方式把它抽取出来了;像“军武次位面虎式坦克”,“虎式坦克”是用户是要找的,但是在视频标题中都是“荣耀之虎”、“虎 P 之腿”,这些视频里面针对“虎式坦克”有详细的内容介绍,通过内容理解能够将用户的需求和内容关联起来,做比较好的召回和排序;最右边的是高晓松老师的“晓说以色列”,也是同类型。
作者介绍:阿里文娱高级算法专家 若仁

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论