
本文翻译自: Streaming Messages from Kafka into Redshift in near Real-Time ,原作者为Shahid C.,已获得原网站授权。
这是关于 Yelp 的实时流数据基础设施系列文章的第六篇。这个系列会深度讲解我们如何用“确保只有一次”的方式把 MySQL 数据库中的改动实时地以流的方式传输出去,我们如何自动跟踪表模式变化、如何处理和转换流,以及最终如何把这些数据存储到 Redshift 或 Salesforce 之类的数据仓库中去。
阅读本系列的第一篇:
英文: Billions of Messages a Day - Yelp’s Real-time Data Pipeline
阅读本系列的第二篇:
中文: Yelp 的实时流技术之二:将 MySQL 表数据变更实时流到 Kafka 中
英文: Streaming MySQL tables in real-time to Kafka
阅读本系列的第三篇:
中文: Yelp 的实时流技术之三:不止是模式存储服务的 Schematizer
英文: More Than Just a Schema Store
阅读本系列的第四篇:
中文: Yelp 的实时流技术之四:流处理器 PaaStorm
英文: PaaStorm: A Streaming Processor
阅读本系列的第五篇:
中文: Yelp 的实时流技术之五:数据管道之 Salesforce Connector
英文: Streaming Messages from Kafka into Redshift in near Real-Time
Yelp 的数据管道给了开发者一套工具集,来轻松地把数据在公司内搬来搬去。目前为止我们标出了核心数据管道基础架构的三个主要部分。第一个是 MySQLStreamer ,它把 MySQL 上的操作复制出来并以流的方式发布到基于模式的 Kafka Topic 中。第二个是 Schematizer ,在这里集中化地保存了各个 Kafka Topic 中的真实信息。它以持久化存储的方式保存了在某个特定的 Topic 中用于编码数据的 Avro 模式信息、数据的属主、各个字段的文档等。最后,是流处理器 PaaStorm ,它让我们可以更容易地消费数据管道中的数据,做转换、再发布回数据管道。把这些工具一起使用,就可以得到各自关心的数据了。
我们这篇文章关注的焦点是数据管道图的“目标”框。在其中可以看到,在转换后的数据被各后续服务消费之前,需要保存到目标数据库中。
(点击放大图像)

在把尽可能多的数据传输和转换操作抽象到数据管道基础架构中之后,我们仍然要把Kafka Topic 中的数据与服务使用的最终数据库关联起来。每一种数据库都有它自己的特性,所以都需要各自不同的连接器。
Yelp 用来做数据分析处理的工具中有一个非常重要而且应用广泛的就是 Redshift 。它因为具有列存储、易扩展、适用于在几十亿行规模的大表间进行复杂的联合查询操作等特性,让计算和聚合操作都变得非常容易。这就让 Redshift 成了一个分析师、数据科学家和工程师们都要使用的非常棒的数据仓库,要经常交互式地进行各种复杂查询、获得输出。本文主要关注 Redshift 连接器:一个使用 PaaStorm 从 Kafka 中读取数据,并把数据导到 Redshift 集群中的服务。
数据仓库已死!数据仓库永生!
我们旧的 ETL 系统在线服务了很多年,不断地把数据从实时生产数据库搬到数据仓库中。下图显示了这套系统的概要架构。
(点击放大图像)

我们在MySQL 数据库有很多触发器,用于监控各种表上面的数据改动。每当有一条记录发生改变时,我们都会写一条改动日志。一个监控改动日志的工作进程就会生成ETL 任务,把它们发布到我们的工作队列中。然后,有许多个工作进程就会根据各种不同的ETL 逻辑对各行数据做定制化的转换操作。转换操作的输出结果会被写入MySQL,在那里暂时保存,然后再导出到S3,最后 COPY 到 Redshift。
这个系统帮我们把数据从 MySQL 搬到 Redshift 一直工作得很好,不考虑复杂度,在我们日积月累地加上了各种告警和工具集之后它还是挺健壮的。可是,它有一些非常严重的缺点,让它难以扩展。
有个非常大的原因是需要占用开发者非常多的宝贵时间去写定制的 ETL、相关的单元测试、做代码审查、整合到我们的单体代码库等。还有,每当我们关注的源头的表的任何一个字段发生了改变时,我们都要在 MySQL 端和 Redshift 端做模式转换,又要在开发环境做,又要在测试环境做。
最重要的原因是这套系统是只支持一个 Redshift 集群的,也就是说每个团队都得为他们自己关心的数据构建一套系统来把数据导到 Redshift 集群中去。我们已经到了一个临界点,必需要用一套新的系统,以便有更好的扩展能力来适应我们公司规模不断扩张的需要了。
Redshift 连接器: 新的希望
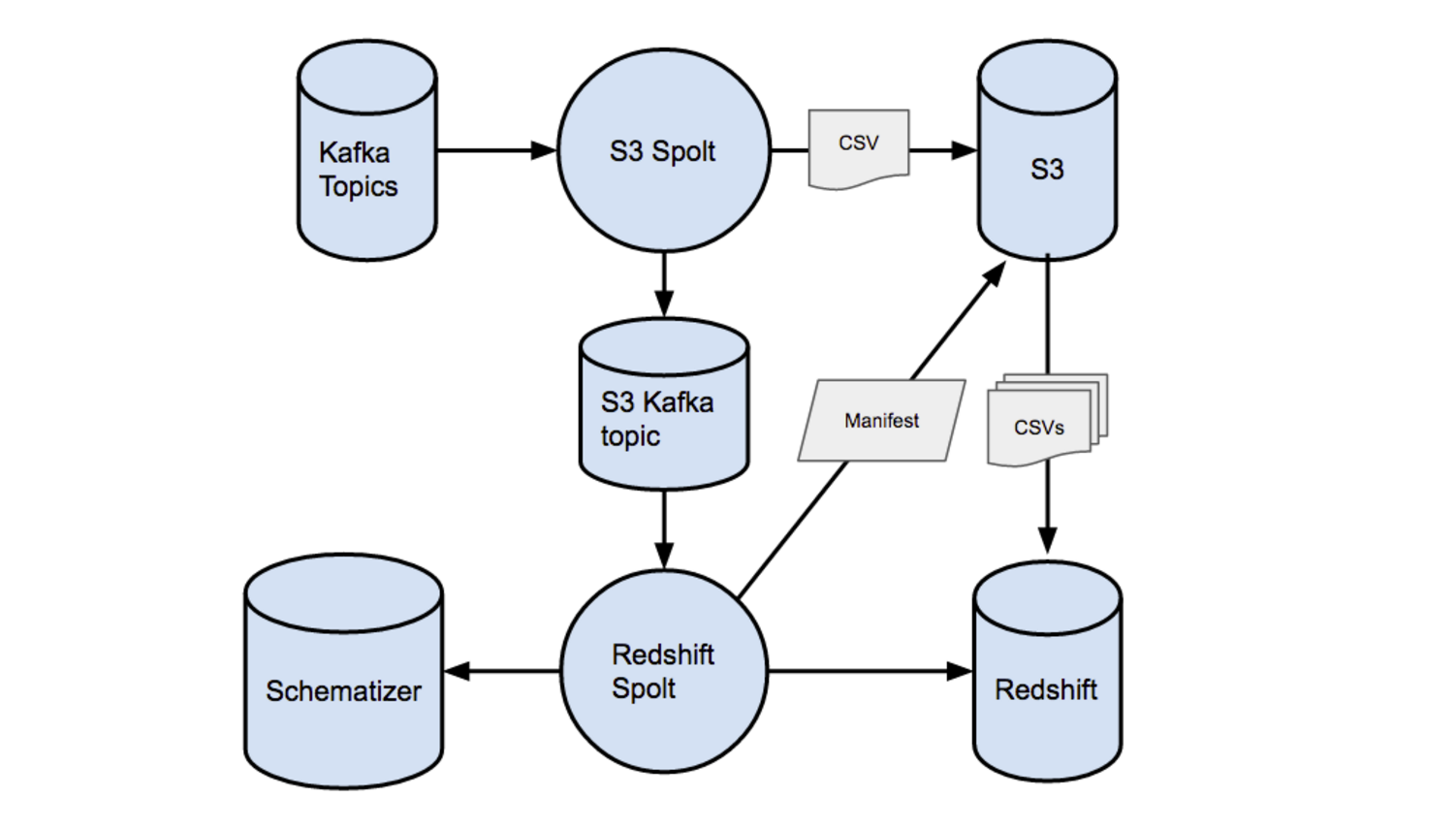
Redshift 连接器概要视图
要解决我们的旧 Redshift 导入系统的问题,新系统必须有以下功能:
- 不需要写定制的 ETL 就可以写入新表
- 自动适应模式转换
- 快速写入
- 可以从失败中优雅地恢复
- 幂等地写操作
- 支持多个 Redshift 集群
根据我们使用旧的 ETL 系统的经验,Redshift 非常适合做从 S3 的 COPY 操作:需求是每天写入几百万行数据,以行为单位的插入操作并不合适。因此,我们需要新的系统来完成两个主要任务:一个要把数据写进 S3,另一个把数据从 S3 读出来,再写入 Redshift。
幸运的是,PaaStorm 的 Spolt 已经提供了必要的抽象,来完成这两个任务。用 Spolt 可以从指定的 Kafka Topic 中读出消息,按某些方式处理过之后,再发往下游进行后续处理。一个 S3 的 Spolt 可以从上游的 Kafka Topic 中读出消息,把它们组成小的批量,再写入 S3。在每次写入 S3 之后,S3 Spolt 可以再向 Kafka 中发送一条消息,记下向 S3 中写入了什么数据。然后,这个下游的 Topic 就可以被当成一个状态记录,记下哪些消息已经被成功的写入 S3 了。
然后,再用一个 Redshift 的 Spolt 去把 S3 Spolt 发布到 Kafka 中的消息读出来,也就知道了该向 Redshift 中写入哪些 S3 的数据。这样,把数据写入 S3 的系统和把数据写入 Redshift 的系统就可以相互独立的运行,只是使用 Kafka 来做通信的通用协议而已。
S3 Spolt
S3 Spolt 用于从数据管道上游的 Kafka Topic 中读出数据,并把数据写入 S3 的文件之中。下图简要地展示了 S3 Spolt 的功能。
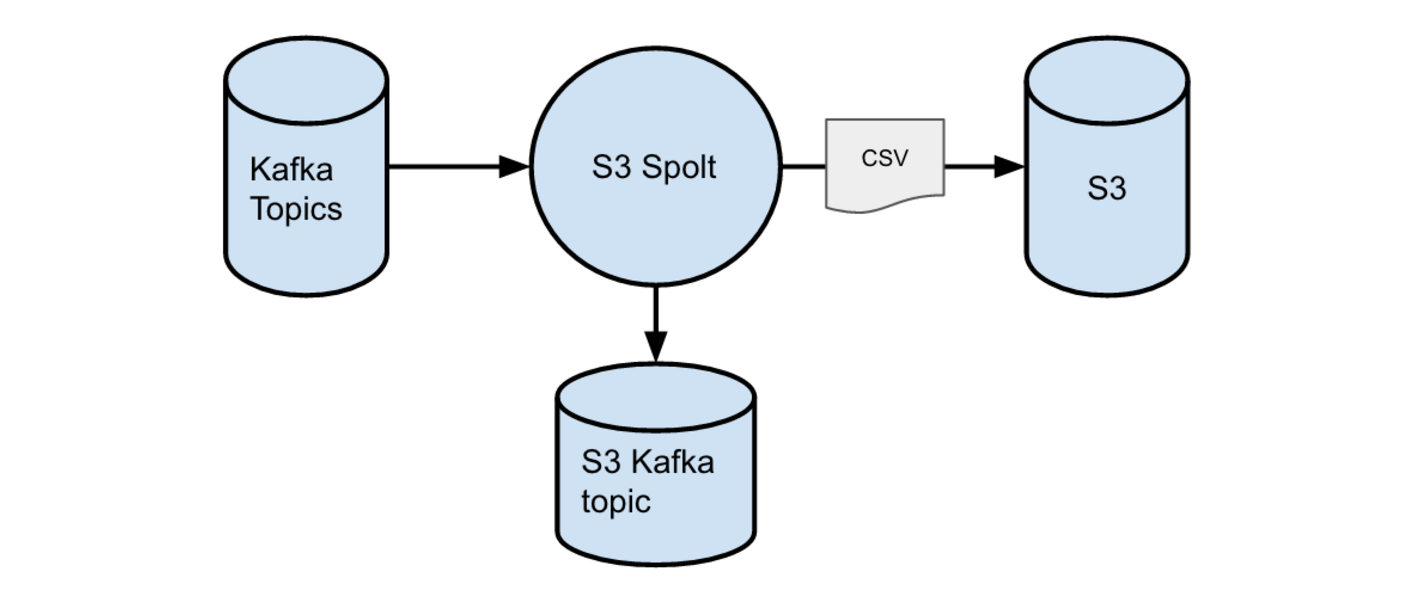
上游的 Kafka Topic 中可能是从 MySQL 表中出来的原始行数据,可能是一个开发者批量写入数据管道的原始消息,也可能是某个中间环节的 Spolt 对这些原始数据做的一系列转换的一个中间结果输出。
批量写入 S3
Redshift 非常适合于从 S3 中批量地把多个文件并行导入Redshift 的场景。为了利用这个特性,S3 Spolt 会把消息分批,把它们以一个CSV 文件的方式写入S3 的一个Key。Key 由Topic、Partition 和这一批消息的第一条在Topic 中的偏移量等信息决定。或者当消息条数达到限制时,或者是时间达到设定值时,或者是上游消息中带了一个新的schema_id 时等,S3 Spolt 就会把一批新消息发布到S3 之中。一批的消息条数上限和时间上限都是可配置的参数。
S3 Spolt 会把它写入 S3 的数据做一些转换。它会为每条消息加一个“消息类型”字段,用于描述这条消息代表了哪一类数据操作(Create、Update、Delete 或者 Refresh)。它也会为每条消息再附加一个字段,值是上游的 Topic 中对应的 Kafka 偏移量。然后,每一批消息都会用一个结构经过了仔细设计的 csv.Dialect 对象打包到一个 CSV 文件中,这样在避免了解析不同格式的同时,也让对输入的 CSV 文件的解析变得更容易。然后数据会被按照对应的 Key 写入 S3。
向 Redshift Spolt 发信号
当 S3 Spolt 向 S3 的一个 Key 下写了一批消息之后,它就需要一个方法来向 Redshift Spolt 发信号,通知它这个事件。S3 Spolt 会向 Kafka 中写一条消息,包含如下有关 S3 中的数据的信息:
- 上游 Topic 的名字
- 上游 Topic 中的消息对应的起始和终止消息的偏移量
- 用于写数据的 CSV 的格式
- S3 上数据的路径
- 与写入 S3 的数据对应的模式 ID
消息最终会发布到一个 Topic 中,Redshift Spolt 会从中读数据。
检查点与恢复
因为不可避免地会有一些偶尔的停服或网络故障,S3 Spolt 应该在故障恢复后可以立刻恢复工作。我们并不希望 S3 Spolt 每次重启时都从那个 Topic 的最早的偏移量开始恢复工作。我们也不能容忍丢失数据,所以我们需要知道我们上次工作做到哪里了。S3 Spolt 处理这样故障的方式很优雅。重启时,它会起一个轻量级的消费者线程,读读这个 Spolt 的下游 Topic 的最后一条消息。
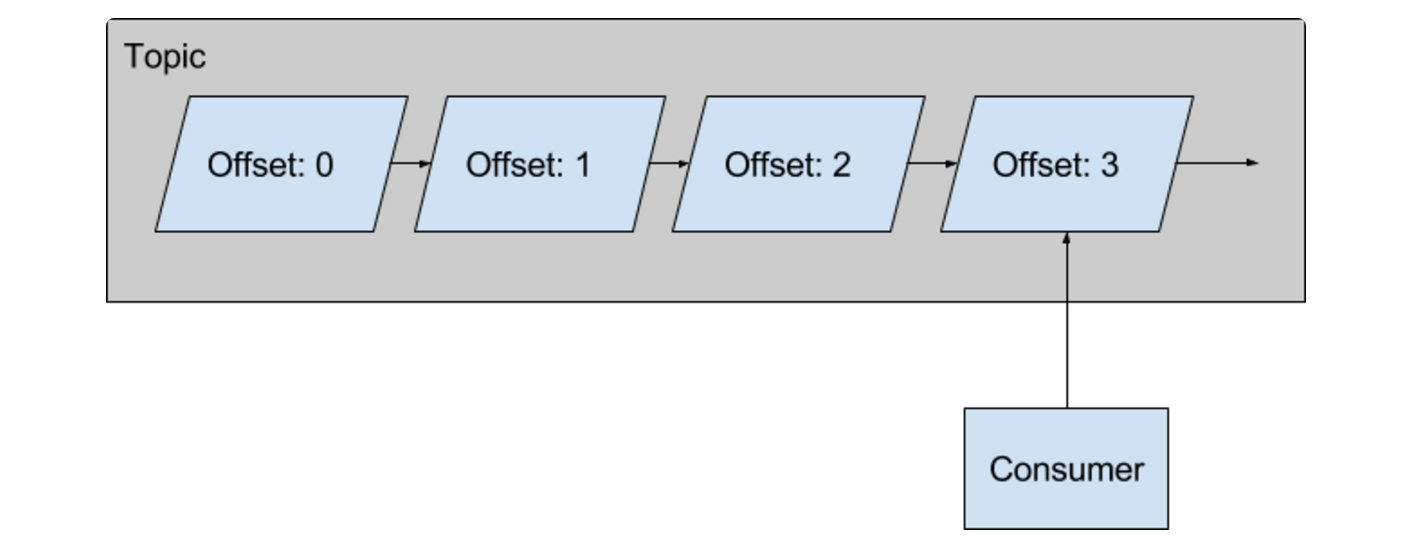
最后一条消息中包含了上游 Topic 的消息以及它最后的偏移量,S3 Spolt 可以用这些信息来在必要时找回它在一个 Kafka Topic 中的位置。而且,写入 S3 的文件是幂等的,所以即使写 Kafka 失败,S3 Spolt 在重启时还会替换这个文件。这就为避免重做工作或者丢消息提供了一个保护机制。
Redshift Spolt
Redshift Spolt 从 S3 Spolt 写消息的 Topic 中读数据,找到 S3 上数据存储的位置,再把这些数据写入 Redshift 集群。每个 Redshift 集群都有特定的 Redshift Spolt。下图显示了 Redshift Spolt 的概要设计。
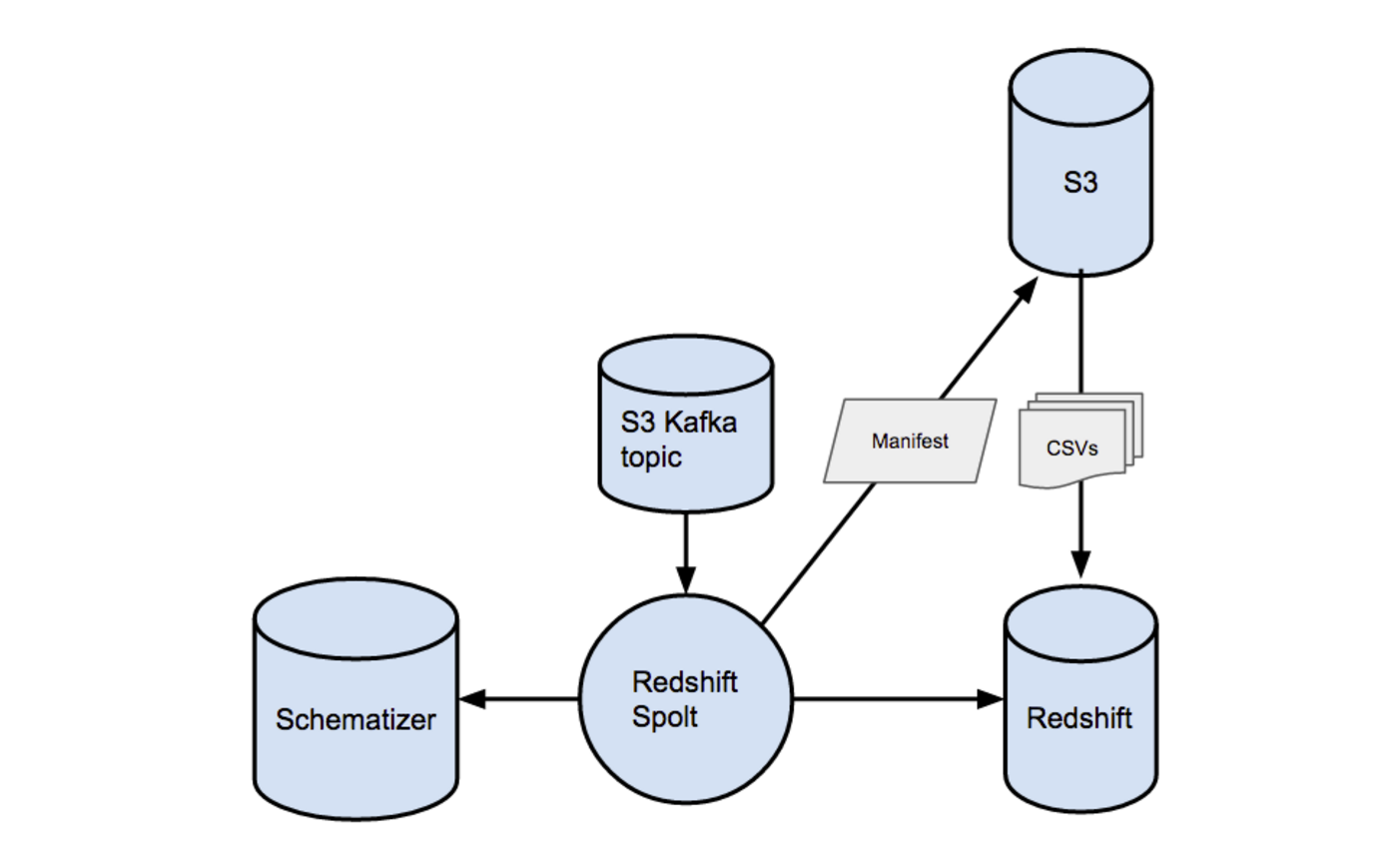
批量创建 S3 清单文件
与 S3 Spolt 写入 S3 时用的批量策略类似,我们也会利用 Redshift 的一次从 S3 中复制多份文件的特性。Redshift Spolt 读的每一条 Kafka 消息中都包括着一批 S3 文件的信息,因此,我们也可以把一定数量的这些文件堆积起来,再通过 S3 清单一次把它们拷过来。比如,Kafka 中的一千条消息代表着 S3 中的一万条记录,让我们可以用一条 COPY 命令就把它们对应的一千万条数据记录拷过来。只要我们用模式 ID 来做数据批量,在同一批的所有文件中的所有记录就都是用完全相同的格式的。我们用它们的模式 ID 缓存消息,在达到了指定的消息数或者达到了在缓存中累积消息的超时时间之后,就把它们刷出去。
在刷出一个缓存中的数据时,我们先提取每条消息对应的 S3 路径,再把它们写到 S3 上的一个唯一的清单文件中。因为S3 在写一致性方面没有list 功能,这个清单文件在我们读取所需文件并拷到Redshift 上时,在保证强一致性方面起着至关重要的作用。然后,Redshift Spolt 就把这个清单文件的位置发给Redshift 写入者。
做模式转换
Schematizer 提供了一系列的功能来把 Avro 模式转换成 Redshift 表的 CREATE 语句。在有一些新文件要拷到 Redshift 上时,Spolt 会检查三种情况:目标表不存在、目标表存在但是模式不同、目标表存在而且模式也相同。
当 Redshift Spolt 开始写入数据时,它会检查一张状态表,其中包含了每张表与它所用的模式 ID 的映射,以此判断我们在 Redshift 中是否已经创建了对应的目标表。如果没有,我们会利用这个模式 ID,让 Schematizer 去生成一个 CREATE TABLE 语句。
如果目标表已经存在,但我们用来创建它的模式 ID 与当前的写入进程用的不同,这就表明模式已经改变了,这时我们就该生成一系列的操作,来把数据从旧表迁移到新表去。
最后,如果状态表中的模式 ID 与当前的写入进程用的模式 ID 相同,我们就什么都不用做,因为目标表的模式正是我们希望的。
分阶段将数据迁移入目标表
当目标表已经存在并且模式也是我们想要的时,我们就需要有方法来把各条记录写或更新进去。我们先用当前任务使用的模式 ID 来创建一张临时的阶段表。然后,用 S3 清单文件来让 Redshift 批量把文件拷到这张临时表中。这样我们就有了一张包含着几百万条(可能是)记录的表,我们要把它合并到目标表中去。
队表中的每一条记录都代表着一个行事件,也就是上游数据源中的 Create、Update、Delete 或 Refresh 事件。我们不能简单地把每条记录都直接写到目标表中,因为我们要处理类似 Update 和 Delete 这种特殊事件。这样,我们就会做一个合并的策略,策略与 Redshift 文档中建议的相似,并有少量的修改。这个就增加了唯一主键的约束,而这个在 Redshift 中并不是原生支持的。
首先,我们只保留每个主键的最大的偏移量的那一行。这样,如果在上游发生了有一系列关于同一行数据的操作我们就只会保留那行记录的最新的值。
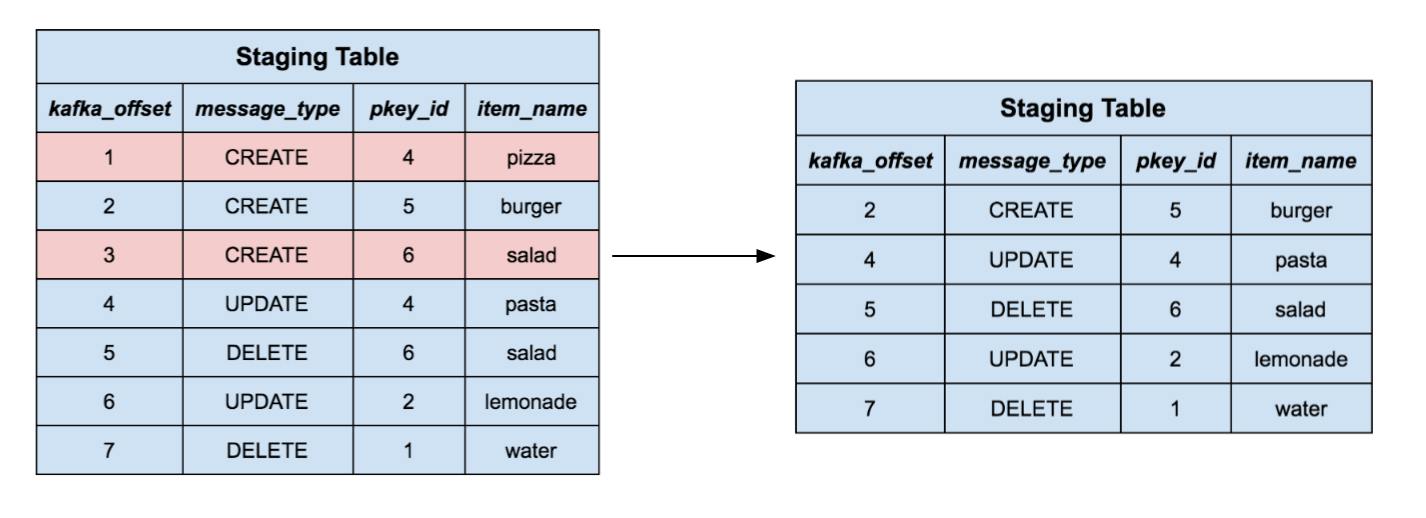
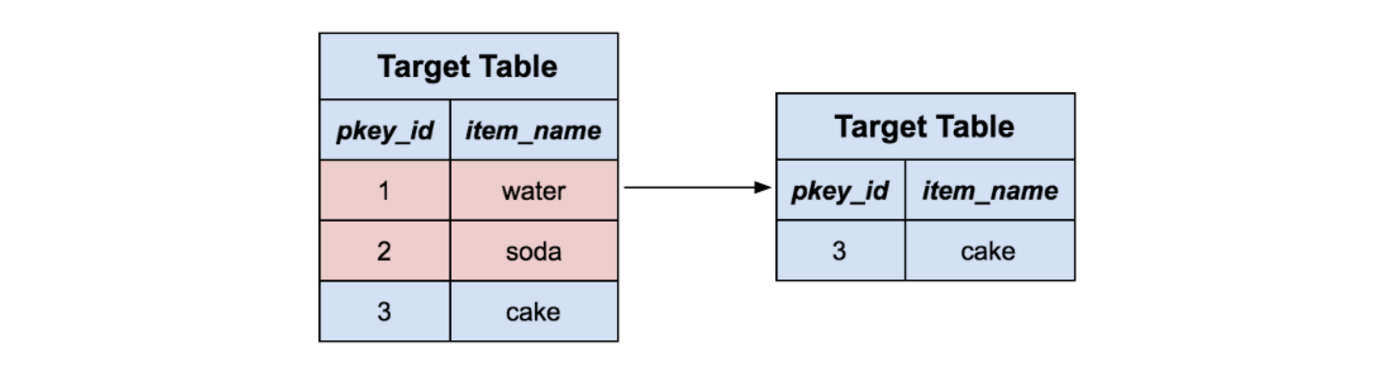
对阶段表中剩下的记录来说,我们把目标表中有相同主键的记录全删掉。从直观上来看,我们就在从目标表中删除那些我们想用新内容替换的记录。请注意这也会处理 Delete 消息,因为那些记录会被简单地删除掉,而没有新东西去替换它们。
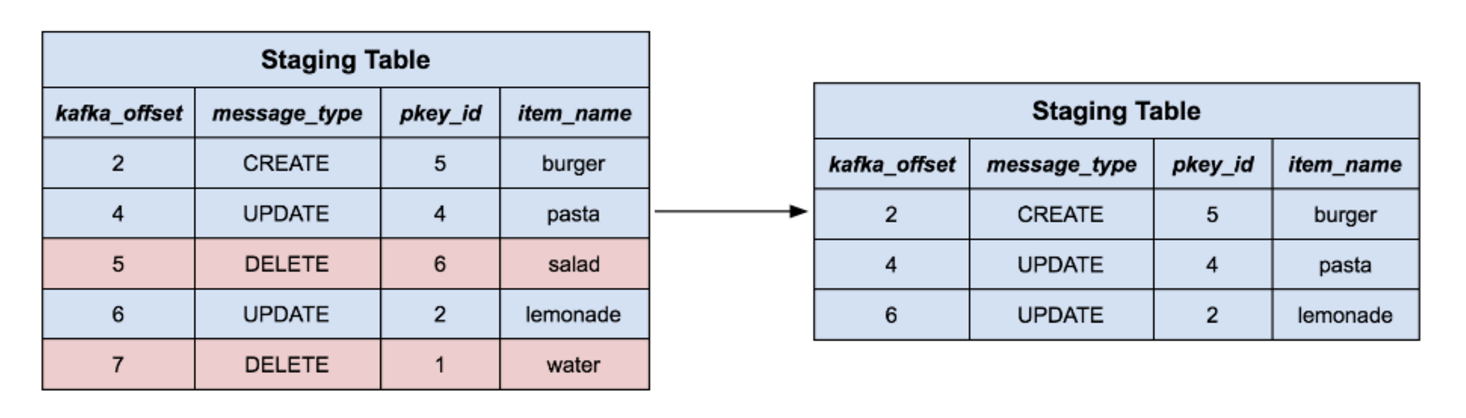
接下来,我们把阶段表中与 Delete 事件对应的消息全删掉,正如从目标表中删除它们一样。
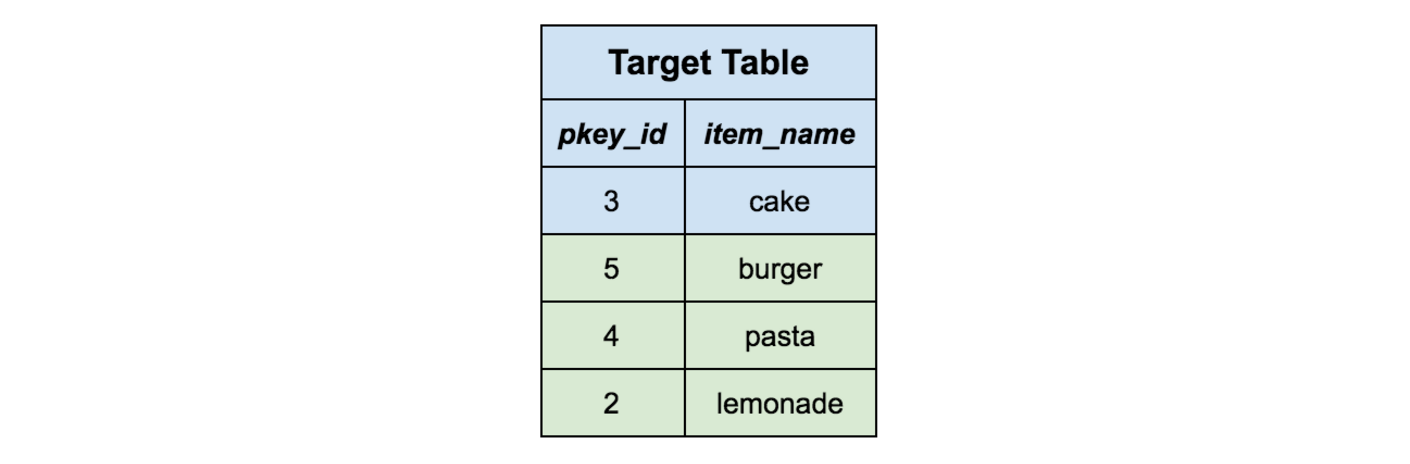
这样,所有剩下的记录所对应的数据在目标表中都不会有相应的数据了,那我们就可以简单地把它们全插入到目标表中,然后再删掉阶段表。这样所有数据就都从阶段表中合并到目标表了。
检查点与恢复
每一次更新插入任务都可能会涉及数百万条记录的改动,耗时数分钟。与 S3 Spolt 相似,在 Redshift 由于网络故障发生重启,或者 Redshift Spolt 失去了与 Redshift 的连接时,Redshift Spolt 都要表现得很健壮,这样我们才不必重复做过的事情。我们用了一张 Redshift 中的状态表来建立每个 Topic 和分区到偏移量的映射关系。当 Redshift Spolt 完成了一次更新插入任务之后,它就会把 Redshift 状态表中与 Topic 和分区对应的偏移量设置成这批消息对应的最大偏移量。这整个更新插入操作和做检查点的操作都发生在一个事务中,所以每次做的任务都是要么全部成功,要么全部不成功,绝不会让 Redshift 处于某种不一致的状态。这样每当 Spolt 重启时,它先检查这张状态表,找到它所处理的 Kafka Topic 的最后位置。
展望未来
Yelp 的数据管道已经极大地改变了我们考虑数据的方法。我们处理数据的方式已经从批量移动数据和定时调度任务,转变成了接入数据块的流,以此来构建更实时的系统。事实证明,数据管道底层架构提供的抽象在构建到诸如 Redshift 和 Salesforce 等各种目标数据库的连接器时极为有用。到目前为止,数据管道所展示出来的潜能是令人极其兴奋的,我们很高兴地看到在将来,我们可以如何利用这些工具来让 Yelp 的数据更容易为大家所用。
鸣谢
非常感谢 Redshift 连接器的合作者 Matt K., 以及 Chia-Chi L. 和 Justin C.,他们自始至终不断地为这个项目提供着反馈和指导。也对整个业务分析组和指标组至以最大的敬意,他们构建了整个数据管道架构,才让我们的项目成为可能。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论