

Apache 软件基金会最近发布年度报告,Apache Flink 再次跻身最活跃项目前 5 名。目前,Apache Flink 发布 Apache Flink 1.14.0,这一版本中 Flink 一个主要变化是集成的流媒体和批处理体验,此外,在 SQL API、更多连接器支持、检查点和 PyFlink 等方面也带来了许多新功能和改进。
统一的批处理和流处理体验
检查点和有界流
通过 FLIP-147,Flink 现在支持任务完成后的检查点,并在有界流的末尾获取最终检查点,确保在作业结束之前提交所有接收器数据(类似于 stop-with-savepoint 的行为)。要激活此功能,请将 execution.checkpointing.checkpoints-after-tasks-finish.enabled: true 添加到配置中。
混合数据流和表/SQL 应用程序的批处理执行
在 Flink 1.14 中,有界批处理执行的 SQL/Table 程序可以将中间 Table 转换为 DataStream,应用一些 DataSteam API 操作,并将其转换回 Table。此外,Flink 构建了一个数据流 DAG,将声明式优化的 SQL 执行与批处理执行的 DataStream 逻辑混合在一起。
混合源
现在支持来自多个源的组合流,通过一个接一个地读取这些源,实现从一个源无缝切换到另一个源。比如从分层存储设置中读取流,就好像有一个跨所有层的流。混合源可以将其作为一个连续的逻辑流读取,从 S3 上的历史数据开始,过渡到 Kafka 中更新的数据。
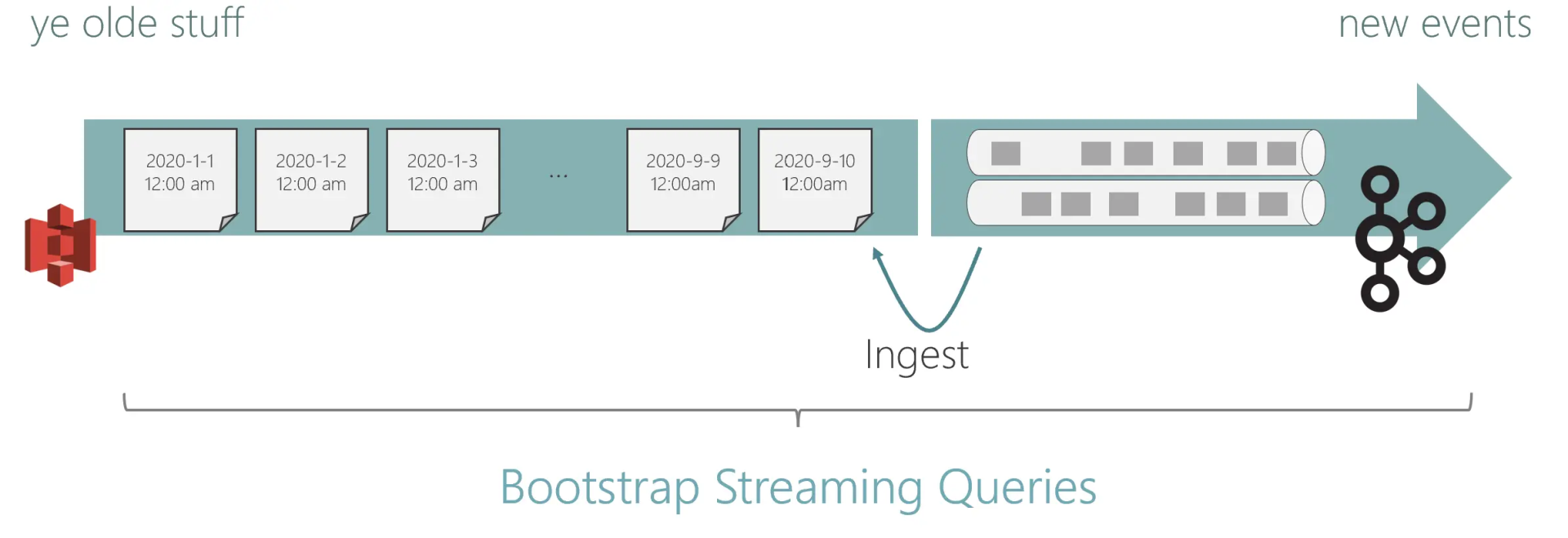
整合源和汇
本次对齐了 DataStream 和 SQL/Table API 之间的连接器,首先是用于 DataStream API 的 Kafka 和 文件源和接收器。
操作改进
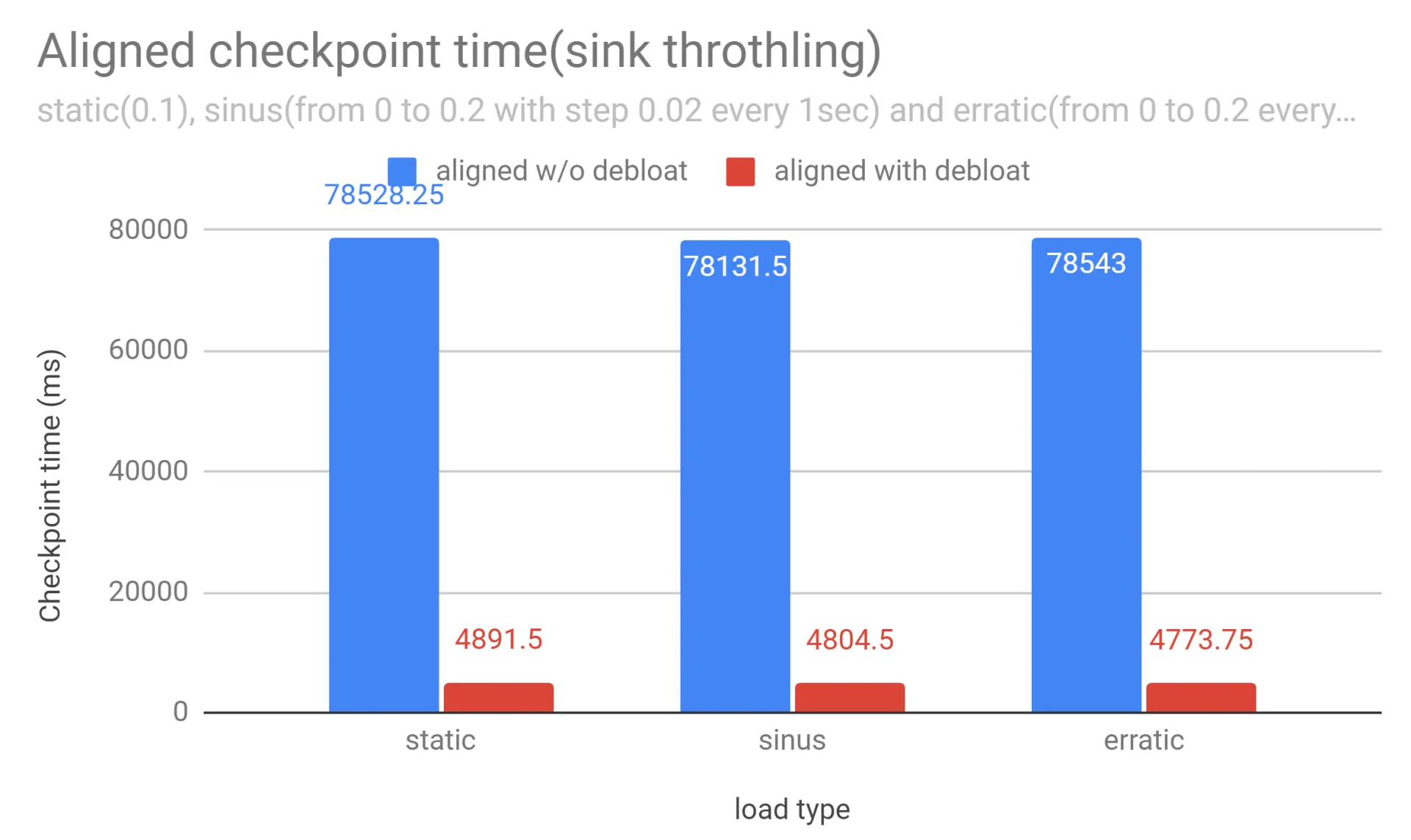
缓冲区的去浮动化
Buffer Debloating 是 Flink 中的一项新技术,可以最大限度地减少检查点延迟和成本。它通过自动调整网络内存的使用来确保高吞吐量,同时最大限度地减少传输中的数据量。因此,Flink 现在可以为背压下的对齐检查点提供稳定且可预测的对齐时间,并且可以大大减少背压下未对齐检查点中存储的动态数据量。
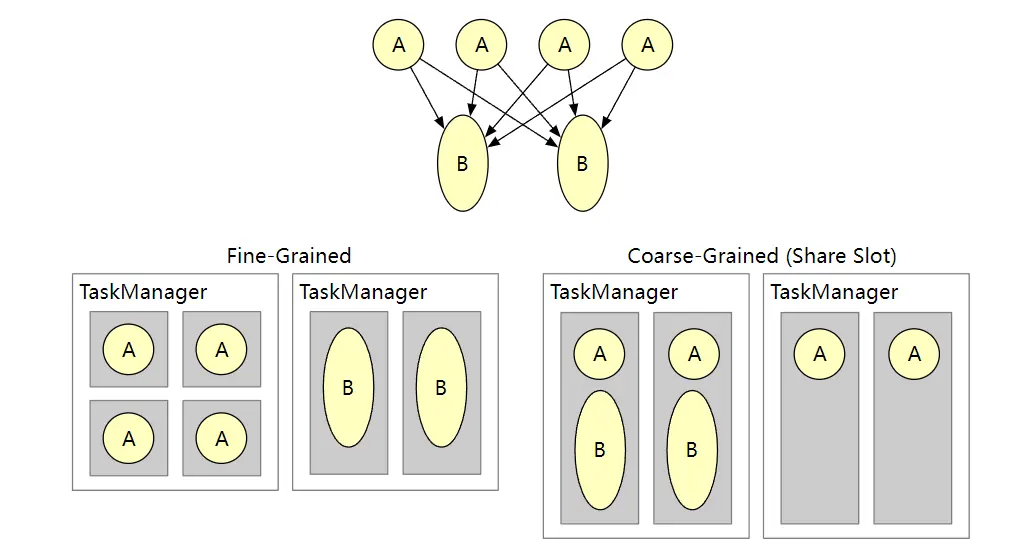
细粒度资源管理
细粒度资源管理是一项高级新功能,可提高大型共享集群的资源利用率。通过细粒度的资源管理,TaskManager 插槽现在可以动态调整大小。转换和操作符可以指定资源配置文件(CPU 大小、内存池、磁盘空间),并由 Flink 的资源管理器和任务管理器将任务管理器总资源的特定部分切掉。
连接器
连接器指标
此版本中已对连接器的度量标准进行了标准化。社区将逐渐通过所有连接器提取指标然后在下一个版本中将它们重新设计到新的统一 API 上。
脉冲式连接器
在这个版本中,Flink 添加了 Apache Pulsar 连接器。Pulsar 连接器从 Pulsar 主题读取数据,并支持流和批处理两种执行模式。在事务功能的支持下(在 Pulsar 2.8.0 中引入),Pulsar 连接器提供了一次性传递语义,以确保消息只传递给消费者一次,即使生产者重试发送消息。该连接器当前支持 DataStream API,表 API/SQL 绑定预计将在未来版本中提供。
PyFlink
通过链接提高性能
PyFlink 现在链接了 Python 函数。在 PyFlink 的情况下,链接不仅消除了序列化开销,还减少了 Java 和 Python 进程之间的 RPC 往返。
用于调试的环回模式
PyFlink 1.14 引入了环回模式,默认情况下为本地部署激活。在这种模式下,用户自定义的 Python 函数将在客户端的 Python 进程中执行,该进程是启动 PyFlink 程序的入口点进程,包含构建数据流 DAG 的 DataStream API 和 Table API 代码。
其他改进
PyFlink 还有许多其他改进,例如支持在 YARN 应用程序模式下执行作业以及支持将压缩的 tgz 文件作为 Python 存档。
关于 Apache Flink
Apache Flink 是 Apache 软件基金会内的 Apache Flink 社区基于 Apache 许可证 2.0 开发的开源流处理框架,该项目已有超过 100 位代码提交者和超过 460 贡献者。
它的核心是用 Java 和 Scala 编写的分布式流数据流引擎。Flink 以数据并行和流水线方式执行任意流数据程序,Flink 的流水线运行时系统可以执行批处理和流处理程序。此外,Flink 的运行时本身也支持迭代算法的执行。
更多详细内容,点击1.14.0 发布公告
GitHub 地址:https://github.com/apache/flink
参考链接:https://flink.apache.org/news/2021/09/29/release-1.14.0.html

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论