【编者的话】Twitter 的监控团队为其内部工程团队提供了全栈的库和多个服务。而其监控技术也为网站发展提供了很好的支持。近日,Twitter 的高级技术经理 Anthony Asta 就在官方博客中发文分享了 Twitter 的监控技术的概况,希望读者可以从中有所收获。
Twitter 的监控工程团队为我们的内部工程团队提供了全栈的库和多个服务,来监控服务的健康状态、遇到问题发出警告、通过提供分布式系统的调用踪迹来支持肯本原因的调查以及通过创建了一个聚合应用 / 系统日志的可搜索索引支持诊断。监控工程团队的主要工作包含四个方面:
- 监视
- 警告 / 可视化
- 分布式系统追踪框架
- 日志聚合 / 分析
我们为运行在我们自己拥有和操作的数据中心以及部署在 Amazon AWS 和 Google Compute 等外部公有云中的所有应有和服务都实现了这些功能。
Twitter 服务每天处理大量的推送。由于负责提供针对支撑 Twitter 的服务的可视化功能,我们的监控服务可称的上是最大规模的内部系统。自从我们在两年前的一篇博客中讨论以后,请求的量以及硬盘中的数据容量都已经大大增加。现在,我们的时间序列量度获取服务每分钟处理超过28 亿的写请求、存储4.5PB 的时间序列数据和处理25000 个查询请求。
本文是系列文章的第一篇。它涵盖了我们的架构、量度获取、时间序列数据库和索引服务。
架构
我们的移动架构一再过去两年中发生了一些变化。以下就是我们现在的系统架构:
(点击放大图像)

量度获取
量度可以通过三种方式进入我们的监控框架。大部分的Twitter 服务都运行一个Python 搜集代理,来将量度放入时间序列数据库和HDFS。监控团队也支持一个普通StatsD 服务器的简单修改版——Statsite,来放松度量到我们的主时间序列度量获取服务Cuckoo-Write 或像Carbon 这样的其他获取服务。最后,在获取的便捷性比性能更重要的地方,监控团队提供了一个HTTP API。通过这些方法,我们能够支持来自运行在Twitter 数据中心的Twitter 服务器或为了利用中心化的监控栈而运行在外部AWS 等数据中心的其他公司的大量客户。
时间序列数据库
所有的Twitter 量度都被发送或存储在Twitter 的时间序列数据库——Cuckoo。它实际上是有Twitter 的分布式键值存储系统 Manhattan 所支持的两个服务——Cuckoo-Read 和 Cuckoo-Write。刚开始,Cuckoo-Read 和 Cuckoo-Write 曾是一个服务。但是,由于读写负载的不同特性,他们被划分为了两个服务,使得每一个服务都只实现特定的任务。
Cuckoo-Write 是量度的获取点,并暴露了一个 API 用于写量度。除了将这些量度存储在 Manhunttan,Cuckoo-Write 还保证这些量度被发送到正确的服务进行索引。最近两周的数据会以分钟的粒度进行存储,而其余的数据以小时的粒度。
时间序列数据库查询引擎 Cuckoo-Read 处理来自我们的警告和仪表盘系统的时间序列数据查询以及用户初始化的特定查询流。查询以 Cuckoo 查询语言 CQL 进行指定。
CQL 查询引擎
给定我们数据集的规模,保证低延迟和高可用性的情况下服务所有的查询是非常具有技术难度的。每天,超过 3600 万个查询是实时执行的,而我们的工程师依靠这些查询和监控系统来满足他们的服务 SLA。
Cuckoo-Read 原本就支持 CQL 查询。查询引擎由三个组件构成:解析器、重写器和执行器。解析器负责将查询字符串解析为内部的抽象语法树(Abstract Syntax Tree,AST);然后,重写器处理 AST 节点,并利用更简单的计算来替换其中一部分节点以改善性能;最后,执行器从下游服务中提取数据并计算结果。
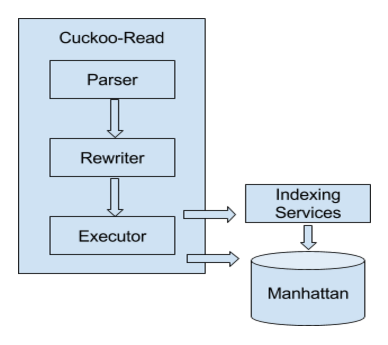
在 CQL,时间学习通过一个包含服务、源和量度的数组进行唯一标识。该结构不仅直接映射了服务的组织方式,也使得我们可以简化存储中的数据划分。
基于时间的聚合
我们的时间序列数据库基于服务所在的组或以小时和天的粒度支持数据聚合。过去,我们使用 Manhattan 计数器来完成基于时间的聚合。我们观察到了两个在每小时和每天数据中的通用的访问模式,从而帮助我们重新设计我们的聚合流水线。这两个访问模式就为:
- 数据访问通常发生在小时 / 天边界的回滚之后(例如,由于数据收集发生在晚上 9 点到 10 点,大部分的每小时数据读访问都发生在晚上 10 点以后)。
- 每小时数据的延迟要求比每分钟数据的要求要低很多。用户通常对每小时数据拥有更高的延迟容忍度。
在这些观察的基础上,我们针对新的聚合流水线,做出以下选择:
- 将相对昂贵的基于 Manhattan 计数器的聚合替换为低消耗、高延迟的 Hadoop 批处理流水线
- 针对聚合结果采用高密度存储(磁盘 vs SSD)
- 在来自 Hadoop 流水线的数据可用之前,对于不经常出现的新进请求从每分钟数据中同步每小时 / 每天的数据
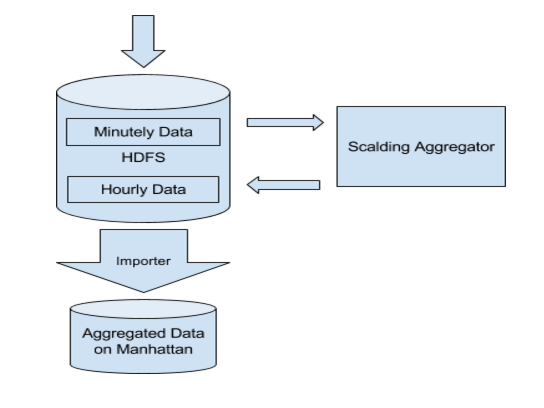
利用这一新的流水线,我们以更低的硬件代价取得了重大的效率提升。而且,我们还通过减少时间序列数据库中的负载,改善了系统的可靠性。
时间集索引服务
时间集索引服务 Nuthatch 保留着量度元数据的踪迹,并维护一个量度键到成员集的映射(例如,从宿主组到每个宿主的映射)和时间戳。下面的浏览工具显示了一个数据的用例。工程师可以快速导航这些服务、源以及服务中可用的量度。
(点击放大图像)

更重要的是,Nuthatch 提供了成员关系解析和CQL 查询引擎的单个查询支持,使得工程师能够针对给定的键查询成员关系,然后利用sum() 和avg() 等函数将所有的时间序列聚合在一起。在下面的查询例子中,Nuthatch 负责识别所有的nuthatch.router 服务以及在“/update/request/”范围内的源,并提供CQL 查询引擎的数据以提取存储中特定时间序列的数据集。
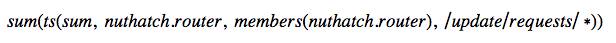
Nuthatch 服务的挑战来自即将被索引的流入量度集和来自 CQL 查询引擎的成员请求的巨大的数据量。一个通用的索引或缓冲引擎在这种情况下并不适用——时间集数据拥有以下特性:
- 时间序列数据的写会引起大量成员集的更新。请求的量如此之大,以至于 Manhattan 存储系统不能有效的进行处理。
- 几乎所有的时间集都会经常被更新,使得基于最近更新的缓冲不再高效。
- 在一个成员集内的大部分成员,即使一些成员非常高频率的加入或离开,仍然保持相对稳定。
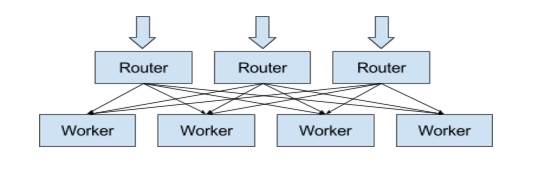
Nuthatch 使用一个中间缓存来减少存储操作的数量,以改善性能和降低开销。在该设计中,一个无状态的路由器服务负责接收进行的请求,并决定请求应该被转发到哪些 worker 碎片以使用兼容的随机。一个带有自身 in-memory 缓存的 worker 碎片的集合通过从缓存或 Manhattan 存储中读取数据来处理请求。
编后语
《他山之石》是 InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到 editors@cn.infoq.com。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




