
URL 从没打算过实现现在的这种用途:让用户以一种近乎神秘的方式确认网站身份。然而我们没能让 URN 成为标准,也就没法使用这种更实用的命名系统。认为目前的 URL 系统已经够用了,这种想法就类似于赞美 DOS 命令行,并认为大部分人都需要学习命令行语法。我们使用窗口化系统的原因在于想要让计算机更易用,被更广泛的用户接受。出于类似原因,也许需要用一种更完善的方式定位网络上的网站。
— Dale Dougherty, 1996 年
“互联网”可以通过多种方式来理解。方式之一将其想象成通过网络连接在一起的计算机所组成的系统。对于互联网的这种认识早在 1969 年创建 ARPANET 时就已存在。其实在 HTTP、HTML,或“网页浏览器”诞生前,人们已经可以通过网络进行邮件、文件、聊天等活动了。
1992 年,Tim Berners-Lee(TBL)发明了三个东西:HTTP 协议、HTML,以及 URL,它们塑造出今天我们所熟悉的互联网。他的目标是让“超文本”(Hypertext)更为实用。简单理解的话,超文本实际上是一种在不同文档之间相互建立连接的技术。当时这种技术看起来更像是科幻小说里的万灵药,并催生出了超媒体(Hypermedia)以及其他很多以“超(Hyper)”打头的词汇。
超文本的核心要求在于要能在不同文档之间相互连接。TBL 当时认为,这些文档可以用多种格式承载,可通过诸如 Gopher 以及 FTP 等协议访问。但他希望能通过一种一致的方式引用使用各种协议编码,托管在互联网上,存在于某台主机里的文件。
在 1992 年 3 月举行的首届万维网发布会上,TBL 将这种技术称之为“通用文档标识符(UDI,Universal Document Identifier)”。当时为这种标识符考虑过很多不同格式:
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README PR=aftp; H=xx.yy.edu; PA=/pub/doc/README; PR:aftp/xx.yy.edu/pub/doc/README /aftp/xx.yy.edu/pub/doc/README)
这篇文档也解释了为什么要对 URL 中的空格进行编码(%20):
UDI 中应避免使用空白字符(White space character):空格不是合法字符。这样做是因为频繁使用无关的空白字符会导致邮件等系统需要折行,或不可避免地缩短列宽,此外还要在转换字符编码方式的过程中,以及在应用程序之间传输文本的过程中对不同形式的空白字符互相转换。
更重要的是,从本质上来说,URL 只是一种对结构(Scheme)、域名、端口、凭据,以及路径等内容组合产物进行缩略的方法,而以往在不同通信系统中需要结合上下文情境加以理解。
URL 最初于 1994 年通过 RFC 正式确立。
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
这种系统使得我们能够在超文本中引用不同的系统,但发展到今天,几乎所有内容都是通过 HTTP 方式提供的,因此可能已经不再那么重要。早在 1996 年,浏览器就已经可以帮助用户自动插入 http:// 和 www.(这也让当时在广告中的网址里依然包含这些字段的做法显得十分愚蠢)。
路径
我觉得问题并不在于人们能否了解 URL 的含意,我只是认为迫使爷爷奶奶辈的用户必须理解 UNIX 文件系统的各种约定到底是什么,在道义上这是一种很可恶的做法。
— Israel del Rio, 1996 年
过去 50 年里用过任何类型计算机的任何用户,对于用来分隔 URL 中路径部分的斜杠应该已经很熟悉了。这种具备层次结构的文件系统是由 MULTICS 系统发明的,该系统的创造者将这种做法归功于他在 1952 年与爱因斯坦进行过一次两小时谈话的结果。
MULTICS 使用大于号(>)分隔文件路径的不同组件,例如:
>usr>bin>local>awk
这种做法在逻辑上很完美,但不幸的是发明 Unix 的那帮人决定使用 > 代表重定向,并使用正斜杠(/)分隔路径。
最高法院,阅后即焚
错了。现在我觉得你我之间存在明显的分歧。
…
作为个体,我保留为不同用途使用不同标准的权力。我希望这些名称能够更通用,可用于任何具体的解释,也可用于任何具体版本。我希望实现比你的提议更加丰富多彩的世界。我不想受到你那种由“文档”和“变体”组成的两级系统的束缚。
— Tim Berners-Lee, 1993 年
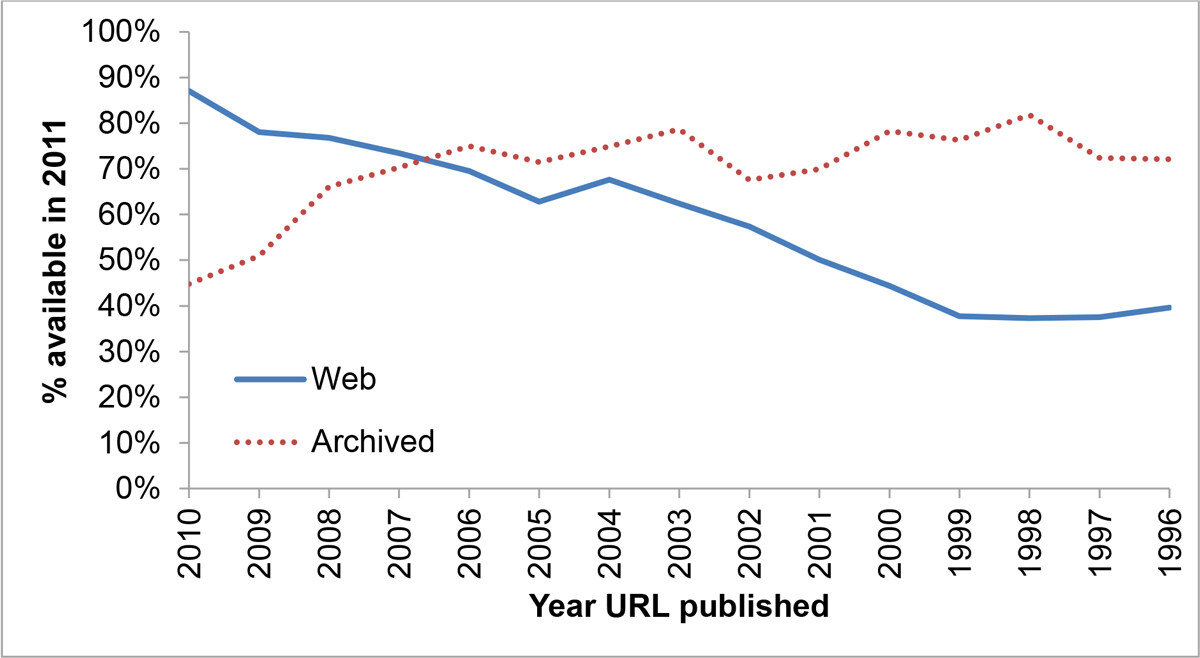
美国最高法院意见里使用 URL 指向的页面中,一半页面已经不复存在。如果你在2011 年阅读一篇2001 年写就的学术论文,你肯定会发现很多已经失效了的 URL。
1993 年,很多人认为 URL 会消失,人们会转为使用“URN”。统一资源名称(Uniform Resource Name)是对特定内容的一种永久引用,与 URL 不同,URN 永远不会改动或失效。Tim Berners-Lee 早在 1991 年就首先评论了这一“迫切需求”。
创建 URN 最简单的办法可能是对页面内容使用算法创建哈希,例如 urn:791f0de3cfffc6ec7a0aacda2b147839。但这种方法无法满足网络社区的某些要求,因为无法真正确定向谁提出申请才能将这串哈希转换为实际内容。此外这种方式也没能充分考虑文件经常可能进行的格式变化(例如压缩和解压缩),尽管格式再怎么变内容都是一样的。
1996 年,Keith Shafer 和其他几人针对 URL 失效问题提议了一个解决方案,介绍该解决方案的链接现已失效。Roy Fielding 于 1995 年 7 月公布了一套实施建议,该链接也已失效。
不过我们可以通过谷歌找到这些页面,而谷歌在这其中的作用已经类似于今天的 URN。URN 格式最终于 1997 年正式确定,但在那之后基本没人使用。这种格式本身的实现也很有趣。每个 URN 包含两个组件:负责对特定类型 URN 进行解析的 authority,以及 authority 可以理解的,任何格式文档的 ID。例如 urn:isbn:0131103628 代表一本书,本地 isbn 解析程序(有可能)可从中提取出代表图书 URL 的永久链接。
考虑到搜索引擎的强大威力,目前最好用的 URN 格式也许就是直接以文件形式指向早前的 URL。我们可以让搜索引擎索引这些信息,然后提供相应的链接:
<!-- On http://zack.is/history --> <link rel="past-url" href="http://zackbloom.com/history.html"> <link rel="past-url" href="http://zack.is/history.html">
查询参数
application/x-www-form-urlencoded 格式在很多方面都是一种反常的畸形,多年来在实施过程中遇到的意外和妥协产生了对互操作性的一系列必备要求,但这些要求无论如何也不能代表好的设计实践。
— WhatWG URL 规范
如果对网络有所了解,你肯定已经熟悉查询参数了。这些参数会显示在 URL 中路径组件之后,并包含了类似?name=zack&state=mi 这样的选项。你可能会觉得奇怪查询为什么要像 HTML 对特殊字符进行编码那样使用连接符号(&)。实际上如果熟悉 HTML,你可能曾对 URL 中的连接符号进行编码,将 http://host/?x=1&y=2 变成 http://host/?x=1&y=2 或 http://host?x=1&y=2(这种特殊的混用情况始终存在)。
你可能还注意到Cookie 使用了类似但略有不同的格式:x=1;y=2,但这种格式与HTML 的字符编码完全不会冲突。这种做法并非W3C 疏忽所致,他们其实早在 1995 年就鼓励大家在查询参数中支持使用 ; 和 &。
最初 URL 的这部分内容被限制只能用于搜索“索引”。最早发明互联网是为了向高能物理学家提供一种协作方法(也正是出于这一目的才能获得最初的资金)。这并不是说 Tim Berners-Lee 不知道自己实际上将发明出一种常规用途的通信工具。多年来他一直没有支持在网页中使用表格,尽管物理学家有这样的需求。
总之这些“物理学家们”需要通过某种方式对信息进行编码和链接,并通过某种方式搜索这些信息。为了实现这些目标,Tim Berners-Lee 发明了标签。如果某个页面出现
这种查询使用了用加号(+)分隔的多个关键字这种格式:
http://cernvm/FIND/?sgml+cms
随着互联网逐渐流行,这个标签很快被滥用来做各种事,例如对输入的数值计算平方根。当时很快有人提议也许这种做法过于具体了,我们真的需要一种通用用途的标签。
该提议最终开始使用加号分隔不同组件,使其看起来更像是一种现代化的 GET 查询:
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzz
这个提议远远超出了“广受欢迎”的程度。有人认为我们需要通过某种方式宣告链接另一端的内容是可以搜索的:
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Tim Berners-Lee认为我们应该通过某种方式定义强类型查询:
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
我可以有些自信地说:现在回想起来,幸亏当时那种更为通用的解决方案未被采用。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论