
引言
经常有人问我这样的问题:“我们在做单元测试,那测试覆盖率要到多少才行?”。而我的答案很简单,“作为指标的测试覆盖率都是没有用处的。”
Martin Fowler(重构那本书的作者)曾经写过一篇博客来讨论这个问题,他指出:把测试覆盖作为质量目标没有任何意义,而我们应该把它作为一种发现未被测试覆盖的代码的手段。
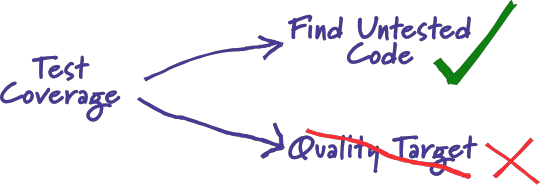
http://martinfowler.com/bliki/TestCoverage.html
Brian Marick(敏捷宣言最早的 17 个签署人之一)也说过,作为一名程序员,我当然期望我的代码有较高的测试覆盖率。但是,当我的经理要求这样的指标时,那就有别的目的了(绩效考核?)。
我认为,高的测试覆盖率应该是每个“认真”写单元测试的程序员得到的必然结果,管理者把一个结果作为指标来衡量,本身就是没有意义的。如果你把“万能”的程序员逼急了,他就会从 “神秘的工具箱”中拿出一两个“法宝”来,“高效”地达成指标。我就见过很多这样的“法宝”,比如在单元测试中连一个“assert”也没有,或者写很多 get 和 set 方法的单元测试(写起来简单啊)来提高整体的覆盖率等等。更何况,测试充分的代码也有可能无法达到 100% 的覆盖率,本文的后面就有这样的例子。
那你大概会问:“那测试覆盖到底有什么用呢?”。我的答案还是很简单,“测试覆盖是一种学习手段”。学习什么呢?学习为什么有些代码没有被覆盖到,以及为什么有些代码变了测试却没有失败。理解“为什么”背后的原因,程序员就可以做相应的改善和提高,相比凭空想象单元测试的有效性和代码的好坏,这会更加有效。
接下来,我会给大家介绍一些传统的测试覆盖方法和一种称为“代码变异测试”(Mutation Test)的方法。大家将会看到这些方法都可以产生什么样的学习点,以及代码变异测试相比传统方法更有价值的地方。如果你是一名程序员(我不会区分你是开发人员还是测试人员,那对我来说都一样),希望你看完这篇文章之后,可以找到一些提高测试和代码质量的方法。如果你是一位管理者,不论你正在用还是想要用“测试覆盖率”来做度量,希望你看完这篇文章之后,可以放弃这个想法,做点更有意义的事情(比如去写点代码)。
传统的测试覆盖方法
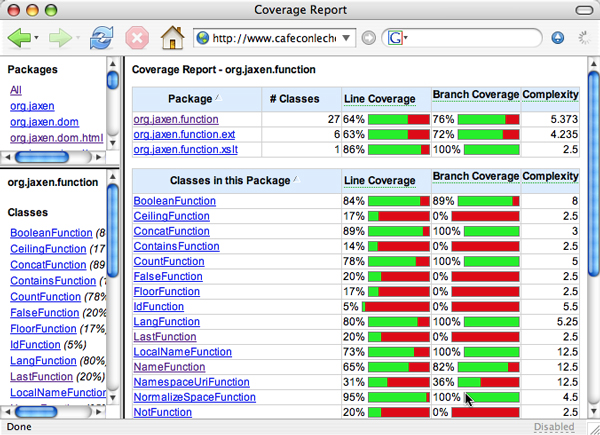
传统的测试覆盖方法常见的有以下几种:
- 函数覆盖(Function Coverage)
- 语句覆盖(Statement Coverage)
- 决策覆盖(Decision Coverage)
- 条件覆盖(Condition Coverage)
还有一些其他覆盖方法,如 Modified Condition/Decision Coverage,就不在这里讨论了。
函数覆盖:顾名思义,就是指这个函数是否被测试代码调用了。以下面的代码为例,对函数 foo 要做到覆盖,只要一个测试——如 assertEquals(2, foo(2, 2))——就可以了。如果连函数覆盖都达不到,那应该想想这个函数是否真的需要了。如果需要的话,那又为什么写不了一个测试呢?
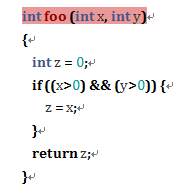
语句覆盖:(也称行覆盖),指的是某一行代码是否被测试覆盖了。同样的代码要达到语句覆盖也只需要一个测试就够了,如 assertEquals(2, foo(2, 2))。但是,如果把测试换成 assertEquals(0, foo(2, -1)),那就无法达到所有行覆盖的效果了。通常这种情况是由于一些分支语句导致的,因为相应的问题就是“那行代码(以及它所对应的分支)需要吗?”,或者“用什么测试可以覆盖那行代码所代表的分支呢?”。

决策覆盖:指的是某一个逻辑分支是否被测试覆盖了。如我上面所说,语句覆盖通常和决策覆盖有关系。还是以上面的代码为例,要达到所有的决策覆盖(即那个 if 语句为真和假的情况至少出现一次),我们需要至少两个测试,如 assertEquals(2, foo(2, 2)) 和 assertEquals(0, foo(-1, 2))。如果有一个逻辑分支没有被覆盖(比如只有测试 assertEquals(2, foo(2, 2))),那么我们应该问和上面“语句覆盖”小节中相似的问题。

条件覆盖: 指的是分支中的每个条件(即与,或,非逻辑运算中的每一个条件判断)是否被测试覆盖了。之前的代码要达到全部的条件覆盖(也就是 x>0 和 y>0 这两个条件为真和假的情况均至少出现一次)需要更多的测试,如 assertEquals(2, foo(2, 2)),assertEquals(2, foo(2, -1)) 和 assertEquals(2, foo(-1, -1))。如果有一个条件分支没有被覆盖(比如缺少测试 assertEquals(2, foo(-1, -1))),那么大家应该想想“那个条件判断是否还需要呢?”,或者“用什么测试可以覆盖那个条件所对应的逻辑呢?”。

通过上面对几种传统的测试覆盖方法的介绍,大家不难发现,这些方法的确可以帮我们找到一些显而易见的代码冗余或者测试遗漏的问题。不过,实践证明,这些传统的方法只能产生非常有限的“学习”代码和测试中问题的机会。很多代码和测试的问题即使在达到 100% 覆盖的情况下也无法发现。然而,我接下来要介绍的“代码变异测试”这种方法则,它可以很好的弥补传统方法的缺点,产生更加有效的“学习”机会。
代码变异测试(Mutation Test)
代码变异测试是通过对代码产生“变异”来帮助我们学习的。“变异”指的是修改一处代码来改变代码行为(当然保证语法的合理性)。简单来说,代码变异测试先试着对代码产生这样的变异,然后运行单元测试,并检查是否有任何测试因为这个代码变异而失败。如果有测试失败,那么说明这个变异被“消灭”了,这是我们期望看到的结果。如果没有测试失败,则说明这个变异“存活”了下来,这种情况下我们就需要去研究一下“为什么”了。
是不是感觉有点绕呢?让我们换个角度来说明一下,可能就容易理解了。测试驱动开发相信大家一定都听说过,它的一个重要观点是,我们应该以最简单的代码来通过测试(刚好够,Just Enough)。基于这个前提,那么几乎所有的代码修改(即“变异”)都应该会改变代码的行为,从而导致测试失败。这样的话,如果有个变异没有导致测试失败,那要么是代码有冗余,要么就是测试不足以发现这个变异。
另一方面,大家可以想一下对于自动化测试(包括单元测试)的期望是什么。我觉得一个很重要的期望就是,自动化测试可以防止“任何”错误的代码修改,以减少代码维护带来的风险。错误的代码修改实际上就是一个代码变异,代码变异测试可以帮我们找到一些无法被当前测试所防止的潜在错误。
举例来说,我们给之前的那段被测代码增加一行,sideEffect(z)。之前的那些可以让传统的测试覆盖方法达到 100% 覆盖率的测试,在新增这行代码之后,依然会全部通过且覆盖率不变。然而,如果我们再删除那行新代码 sideEffect(z),结果有会怎样呢?那些测试还是会全部通过,覆盖率也还是 100%。在这种情况下,原来那些测试可以说没有任何意义。相对的,代码变异测试则可以通过删除那一行,再运行测试,就会发现没有任何测试失败。然后,我们就可以根据这个结果想到其实还需要一个测试来验证 sideEffect(z) 这个行为(如果那行代码不是多余的话)。

再举一个例子,还是之前的代码,不做任何修改。我们用 assertEquals(2, foo(2, 2)),assertEquals(2, foo(2, -1)) 和 assertEquals(2, foo(-1, -1)) 这三个测试达到了 100% 的条件覆盖。然而,如果把 y > 0 的条件改成 y >= 0 的话,这三个测试依然会通过。为什么会出现这样的问题呢?那是因为之前的测试对输入参数的选择比较随意,所以让这个代码变异存活了下来。可以看到,在条件覆盖 100% 的情况下,代码变异测试依然可以帮我们发现这种测试写的不严谨的问题(假设 y >= 0 这个代码变异是不合理的),从而使修改后的测试可以防止产生这样的错误代码。
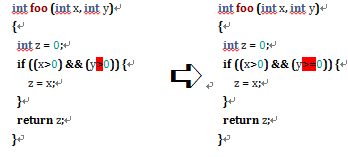
通过上面两个例子,相信大家已经发现代码变异测试可以给我们提供大量的学习代码合理性和测试有效性的机会。实际上,类似的代码变异还有很多种。下面是常见变异的列表,更详细的内容可以参考 http://pitest.org/quickstart/mutators/ 。
- ** 条件边界变异(Conditionals Boundary Mutator)** 对关系运算(<, <=, >, >=)进行变异,上面第二例子就是这种变异
- ** 反向条件变异(Negate Conditionals Mutator)** 对关系运算(==, !=, <, <=, >, >=)进行变异,例如把“==”变成“!=”
- ** 数学运算变异(Math Mutator)** 对数学运算(+, -, *, /, %, &, |, ^, >>, <<, >>>)进行变异,例如把“+”变成“-”
- ** 增量运算变异(Increments Mutator)** 对递增或者递减的运算(++, --)进行变异,例如把“++”变成“–”
- ** 负值翻转变异(Invert Negatives Mutator)** 对负数表示的变量进行变异,例如把“return -i”变成“return i”
- ** 内联常量变异(Inline Constant Mutator)** 对代码中用到的常量数字进行变异,例如把“int i=42”变成“int i=43”
- ** 返回值变异(Return Values Mutator)** 对代码中的返回值进行变异,例如把“return 0”变成“return 1”或者把“return new Object();”变成“new Object(); return null;”
- ** 无返回值方法调用变异(Void Method Calls Mutator)** 对代码中的无返回值方法调用进行变异,也就是把那个方法调用删除掉,上面的第一个例子就是这种变异。
- ** 有返回值方法调用变异(Non Void Method Calls Mutator)** 对代码中的有返回值函数调用进行变异,也就是接收返回值的变量赋值将被替换成为返回值类型的语言默认值,例如把“int i = getSomeIntValue()”变成“int i = 0”
- ** 构造函数调用变异(Constructor Calls Mutator)** 对代码中的构造函数调用进行变异,例如把“Object o = new Object()”变成“Object o == null”
测试驱动开发和代码变异测试

测试驱动开发(TDD)是我推崇和实践的写代码(做设计)方法。我在前面曾经提到,代码变异测试的假设是“实现代码是刚好够通过测试的最简单代码”,而这也是 TDD 中的重要实践之一。大家可能会问,如果做了 TDD,代码变异测试的结果又会如何呢?还会产生学习的机会吗?答案是肯定的,一定会。
让我们通过例子来看一下。我经常会做一些 Kata 来练习编程技巧,PokerHands(如上图)就是其中之一(其实大体就是实现梭哈的五张比较规则 http://codingdojo.org/cgi-bin/wiki.pl?KataPokerHands )。每次我把 Kata 做完之后,都会用运行一下代码变异测试(sonar 中有插件)。Java 的代码变异测试工具有个比较好的叫 pitest。下面是我用这个工具跑出来的结果,代码可以在这里找到 https://github.com/JosephYao/Kata-PokerHands 。
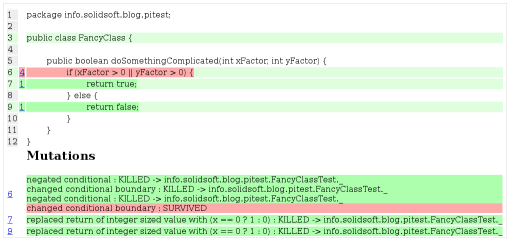
如大家所见,红色那一行中有一个存活下来的代码变异。而这个代码变异是把“index < CARD_COUNT - 1”中的“<”换成“>”。看上去很不可思议吧,因为进行这样的代码变异意味着整个 for 循环都不会被执行了,应该不可能没有一个测试失败吧?
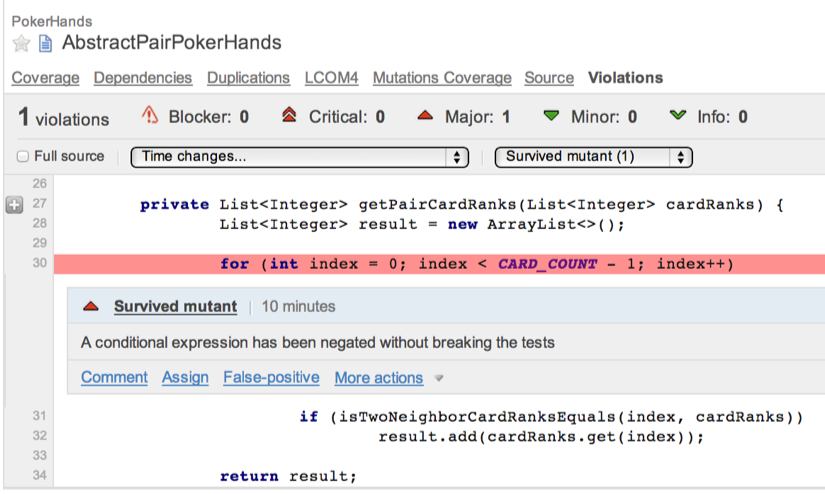
让我们来看一下相关的单元测试。在下面这个测试中有三个 assert,它们都是在验证“一对”之间通过对子的点数来比较大小的情况。大家仔细观察就可以发现,其实这三个 assert 中的牌如果作为 High Card(就是比一对小一点的牌组)来比较的话,也都是成立的。这也就是那个代码变异可以存活下来的原因,因为即使忽略了一对之间的比较,通过 High Card 比较出来的大小关系也是一样的。我从中学到的是,只要把 assertPokerHandsLargerThan**(“2S 3H 5S 8C 8D”,** “2S 3H 5S 7C 7D”) 改为 assertPokerHandsLargerThan**(“2S 3H 5S 8C 8D”, “2S 3H 9S 7C 7D”)** 就可以清除这个代码变异了。

从这个例子中可以看到,即使以 TDD 的方法来写代码,也是无法完全避免出现代码变异存活下来的情况的(当然,存活变异的数量要非常明显的少于不用 TDD 而写出来的代码)。做过 TDD 的人可能都有这样的感觉,就是有时很难抑制自己写出复杂代码的冲动(也就是说代码不是“刚好够”的)。有时,即使实现代码是最简单的,也可能因为代码过于直接,就会很“随意”的写出一个让当前代码失败的测试。上面的例子就是这种情况,这样不太“有效”的测试通常在 TDD 过程中很难意识到,从而给之后的代码维护造成隐患。
除了上面那个有学习意义的代码变异之外,其实工具还帮我找到了一个“没意义”但存活下来的代码变异。
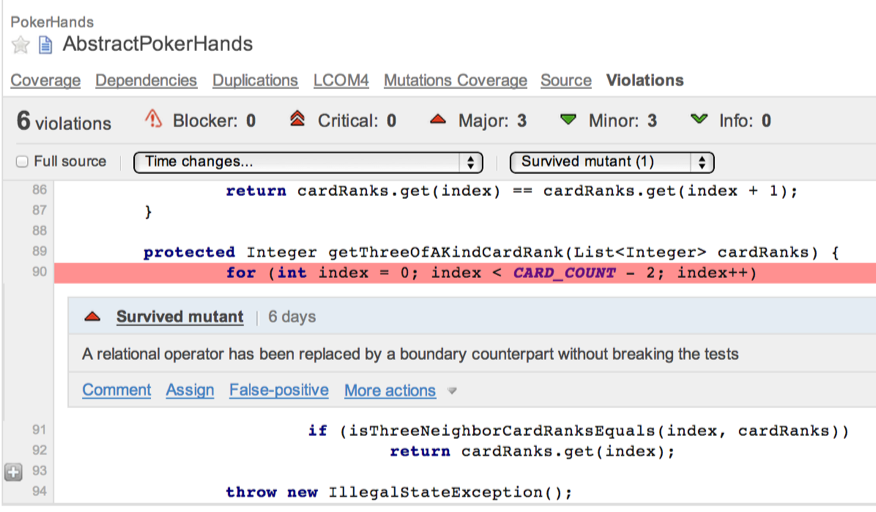
这里存活下来的代码变异是指把“index < CARD_COUNT - 2”中的“<”变成“<=”。之所以说这个代码变异没意义,是因为根据代码上下文,在 for 循环中一定会在 index 等于 CARD_COUNT - 2 之前就找到那个三张的点数。因为工具无法理解上下文,所以产生了这个没意义的代码变异(也叫做 Equivalent Mutation)。之所以举这个例子,只是想提醒大家不要迷信代码变异测试工具。对于他产生的结果一定去分析和学习,不然很容易走上考核指标的那条不归路。
小结
总而言之,测试覆盖这种方法是一种不错的学习手段,可以帮助我们提高代码和测试质量。代码变异测试则比传统的测试覆盖方法可以更加有效的发现代码和测试中潜在的问题,提供更多的学习机会。在这里,我要郑重警告那些妄图把代码变异测试变成一种新的考核指标的管理者们,这样做只会迫使程序员从他的神秘工具箱中找出新的法宝来对付你(比如,修改编译器等等)。
代码变异测试的概念其实早在 30 年前就被提出了。之所以到目前为止还没有被业界广泛接纳,一个重要原因是由于需要对每个代码变异反复运行测试。如果不是单元测试(运行速度慢),代码变异测试工具执行时将消耗大量的时间。正因如此,单元测试可能是唯一符合代码变异测试要求的一种测试了。如果你对代码变异测试的历史和发展过程感兴趣的话,你可以参考这篇研究报告 http://crestweb.cs.ucl.ac.uk/resources/mutation_testing_repository/TR-09-06.pdf 。
关于姚若舟
姚若舟是 Odd-e 的一名敏捷教练,为团队提供敏捷实践的教导和培训。他在软件业有超过十三年的开发和项目管理经验,熟悉互联网,移动和桌面软件的开发。他是中国敏捷社区的积极参与者和组织者。作为一名追求软件工艺的程序员,他从 2011 年开始坚持每天通过 Coding Kata 来不断提高自己的编程技巧。同时,他还在不少公司,社区沙龙和会议中组织过许多次代码道场(Coding Dojo)和 Coderetreat 的活动。
他有非常丰富的 Scrum 经验,曾长期担任 ScrumMaster,服务于多个开发团队和 Product Owner。他擅于在各种 Scrum 会议和日常工作中通过提问来引导和帮助团队成员发现潜在的问题和改善机会,从而真正实现团队的敏捷转型。
他对软件工艺的各类实践(如编写高可读性代码,单元测试,重构,遗留代码隔离,测试驱动开发(TDD)等)有着深入的了解和丰富的实战经验。同时擅于通过 Coding Dojo 这种编程练习的方式来帮助开发人员提高编程能力和代码质量。他精通 Java 语言,熟悉基于 Java 的 Web 开发中的常用协议,开源软件和工具。
Kata 视频: http://tudou.com/home/yaoruozhou
新浪微博: http://weibo.com/yaoruozhou
Github: https://github.com/JosephYao
感谢侯伯薇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论