
当每次访问 Facebook 时,你会看到从社交图中获得的成百上千的关系信息:不仅仅可以收到你朋友的发帖、图片和私信,也能收到“赞”、评论等。并且,这些信息是不断的变化的、不能事先计算好的,每秒钟都有百万次的写入和亿万次的读取。对于每个人来说,他/她们的交互信息都是实时的。
社交图谱是由顶点和边或者对象和关系组成(这里对象和关系是 Facebook 公司的叫法,其实对象就代表顶点,关系就代表边),带有一系列的属性。典型的图关系查询始于一个顶点,并给出某类限定条件查询出所有的边信息。例如,把你自己作为一个点,查询你所有的朋友信息,并按成为朋友的时间来排序。
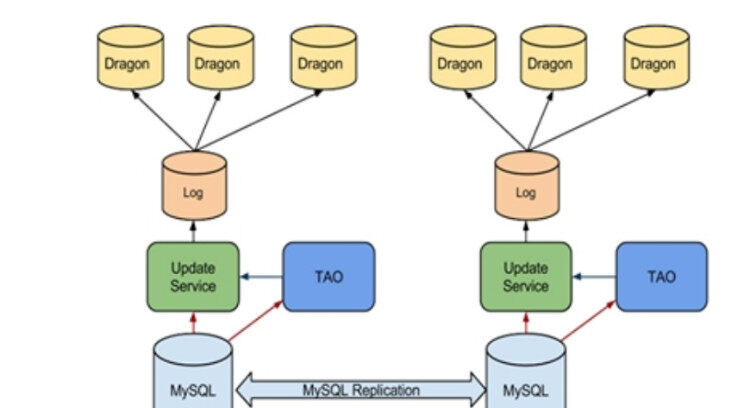
Facebook 查询社交图谱最早是基于 memcached 和 MySQL,后面自己开发了一个分布式数据库TAO (TAO 适合单跳(single hop)大批量查询)。自从Facebook 采用TAO 后,Facebook 的用户量显著的提升,而且许多内容的交互度(engagement)也非常高。Facebook 的发帖有的收到亿万次的点赞,尽管几分钟的直播视频也获得成百上千的评论,评论有各种语言的,这让显示跟每个人的相关信息有了很大的难度。大部分情况TAO 可以解决,但需要新增加对大批量多跳(multi hop)的优化,这时候Dragon 应运而生。
Dragon,一个分布式图谱查询引擎,是支撑 Facebook 巨规模社交图谱的坚固基础,擅长对复杂图的查询。Dragon 可以实时监控社交图谱模型(对象和关系)的更新,并创建索引来提高攫取、过滤和重排序数据的效率。使用 Dragon 可以减少网络数据的传输,低延迟和不抢占其它机器的 CPU。
索引技术
假设 Alice 有上千个 Facebook 好友,她说英语和西班牙语,在 Facebook 上关注夏奇拉(Shakira,著名歌手)。当 Alice 访问夏奇拉的 Facebook 主页,会显示一句话“您的朋友 Bob 和 Charlie,以及其他 1.04 亿人关注这个页面”。如果有一个页面有成百上千的评论,会在顶部显示 Alice 所会语言的评论。
分布式数据库 TAO 能一次攫取成千的关系数据,这对大部分情况下的查询都可以,但对大数据量的查询时会产生延迟。当 Alice 浏览夏奇拉的主页,Facebook 的并发系统会在 RAM 中缓存评论的子集,并以时间戳(ts)排序,过滤上千的评论区找到相关语言的评论并重排序
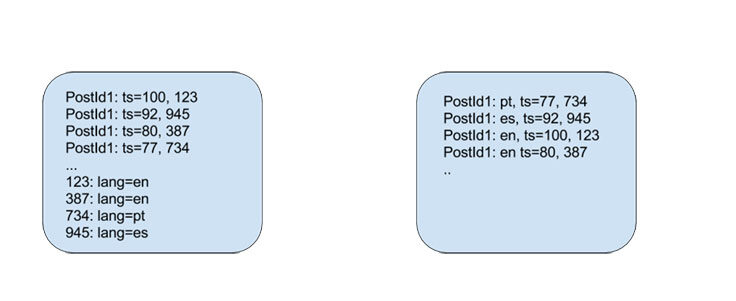
图 1:使用 Dragon 前的评论存储和使用 Dragon 的索引存储
使用 Dragon,会指定索引并通过感兴趣的属性进行过滤。当一个图谱第一次查询命中,Dragon 会回调 TAO 数据库设置初始值到 RocksDB (一个高效的嵌入式 Key/Value 持久数据库) 持久化存储。Dragon 会存储最近查询的数据或者频繁查询的数据,下推程序到存储层,这样查询到效率会更高。举例,当 Alice 浏览夏奇拉的主页,Facebook 会计算一个 key:并直接寻找感兴趣的发帖;也可以做更复杂的排序并持久化到 RocksDB,以减少查询到时间。
而另外一些 Facebook 上的人并不会出现一篇发帖有大数据量的评论,他 / 她们许多人会上传大量的图片。一个常规的图片上传到 Facebook 会存储 20 条边到 MySQL 里并通过 TAO 缓存到 RAM 中。这些边可能包含一些属性(比如,上传图片的人、上传图片的地点以及图片是否打标签等)信息,大部分情况是读取数据,因此可以在写入的同时进行读操作。边的数据需要持久化存储,并且数据大小六年增长了 20x 倍;大约有一大半的数据是存储边的属性数据,只有一小部分是描述两个实体之间的关系(比如,Alice -> [uploaded] -> PhotoID 和 PhotoID -> [uploaded by] -> Alice)的。
使用 Dragon,只需要写入主要的边关系,然后创建基于方向的索引。索引加速读取,但同时会减缓写入数据,因为在写入数据的同时得创建对应的索引数据,所以 Dragon 只创建有意义的索引。比如,一个只有 10 个评论的发帖不需要创建索引,因为其用分布式数据库 TAO 就很方便的扫描所有数据。结合部分索引技术和丰富的支持过滤、排序操作的查询语言可以索引一个 150x 倍数据量但 90% 的查询会在缓存中命中。
社会化倒排索引
人们一般经常查询朋友的基本信息(比如,姓名和生日);这些数据读的频率远大于写入。复制 Alice 的基本信息到所有主机,当查询朋友的名字时仅仅需要访问一台主机即可,这也得平衡数据的一致性和可用性。索引加速读取,同时也减慢写入。每次写入都得复制到所有的主机上,并且有可能写入失败。
倒排索引在信息检索方面是一个主流的技术。当 Alice 关注 Shakira,Facebook 存储在代表 Alice 的主机有两条边(Alice -> [likes] -> Shakira 和 Shakira -> [liked by] Alice)。我们得到的是一个分布式倒排索引,因为 Shakira 的关注者不限于一台主机。查询一个索引需要访问集群上所有的主机,这显然增加了延迟和查询的代价。
Dragon 的独特实现在于这些索引存储是基于查询模式的深度解析,而不是随机共享
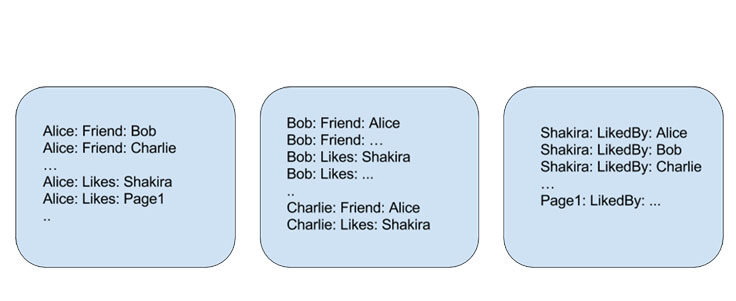
图 2 :朋友关系和主页关注存储在分布式数据库 TAO。每个框代表一台主机

图 3:搜索引擎里常用的倒排索引。每台主机存储一部分对象 IDs,比如[n*100,n + 1 * 100]
如果你看你好友的关系图谱以及他/她们自己的好友的图谱,你会发现一些清晰的规律。对大部分人来说,社交图谱包含对社交圈子包括家庭、合作者或者高中同学。并且那些有相同朋友圈的朋友高度的相似性。如果 Alice、Bob 和 Charlie 在一个公司工作,Bob 和 Charlie 也是朋友,并且有许多成年人朋友,Facebook 公司的算法会试图把他们归到一台主机上。
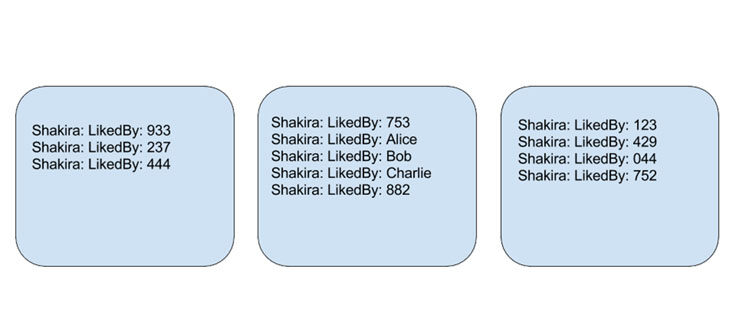
图 4: 社交化倒排索引。Alice 朋友圈在同一台主机上。
Facebook 完成这些算法是针对人,但也同样对图谱中其他类型的对象适用。早期的索引减少读取 30% 的设备块和约 7% 的 CPU 使用,早期版本的 Dragon 未使用倒排索引。
Dragon 主要有两个优点:图谱中一个对象有唯一的索引,并共享存储在类似 MySQL 和 TAO 的数据库;第二个优点是朋友关系边的查询,这步有一个聚合层和更新服务来处理数据重新分布,同时依赖于分布式日志和至少处理一次的语法。
朋友关系、关注和评论是 Facebook 社交图谱中最常见的边。通过离线图谱分解技术来提升数据的本地性,最初的做法主要是通过“ balanced partitioning of the social graph ”基于好友关系边来做离线计算,并且随着扇出优化技术的发展,可以达到低于 3x 的扇出,相对于随机共享服务技术减少了平均延迟,见图 5。
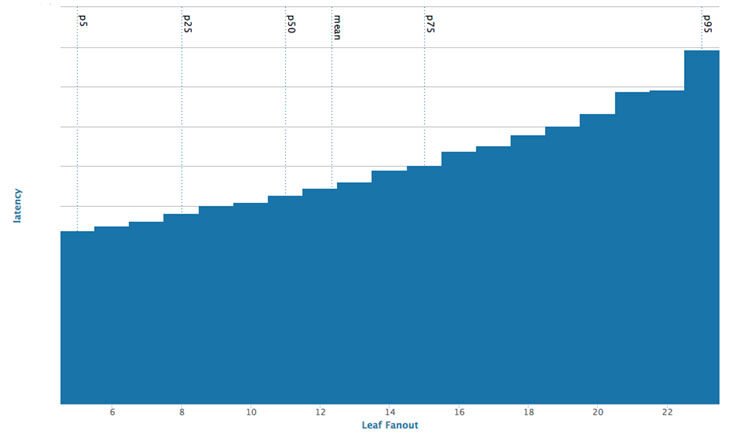
图 5: 延迟和扇出关系图
这个算法机遇和挑战并存,查询时间和好友数并不是线性关系,所以可以高效的查询大批量数据,但查询的总时间遵循“最短木桶”效应,取决于最慢的查询操作,所以如果有某一台机器查询时间超过 100ms,尽管其他机器的查询时间大约 10ms,那也被视为高延迟。通过采用多核机器,尽可能的让 CPU 并行处理查询,这样对大数据量的查询也可以限制在一个合理的延迟范围内。
原生的函数式编程。
Dragon 支持函数式编程,在图谱上过滤/排序某个边。
(->> (friends) (assoc $friends) (filter (> age 20)) (count))列 1: 计算 Alice 朋友的好友年龄大于 20 岁的数量
(->> (groups) (->> (assoc count $offset))
列 2: 计算所有我的关注的组,并按组成员数排序,显示指定的条数。 Dragon 支持使用 Lua/JavaScript 语言编写用户自定义函数(UDF),可实现对复杂的字符串操作和正则的支持。
总结
Dragon 是高吞吐量、Key/Value 存储、实时更新和持久化的社交图谱查询引擎,支持数据一致性和高可用性。它采用多项优化技术存储,提高数据本地性,执行查询时间在 1ms 或者 2ms 左右。
Dragon 可以让你的应用更多的去关注业务逻辑、信息安全、数据质量校验和有深度的数据排序优化,而不是耗费太多的时间在迭代计算图谱数据。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论