
Airbnb 成立于 2008 年 8 月,拥有世界一流的客户服务和日益增长的用户社区。随着 Airbnb 的业务日益复杂,其大数据平台数据量也迎来了爆炸式增长。
本文为 Airbnb 公司工程师 James Mayfield 分析的 Airbnb 大数据平台构架,提供了详尽的思想和实施。
Part 1:大数据架构背后的哲理
Airbnb 公司提倡数据信息化,凡事以数据说话。收集指标,通过实验验证假设、构建机器学习模型和挖掘商业机会使得 Airbnb 公司高速、灵活的成长。
经过多版本迭代之后,大数据架构栈基本稳定、可靠和可扩展的。本文分享了 Airbnb 公司大数据架构经验给社区。后续会给出一系列的文章来讲述分布式架构和使用的相应的组件。James Mayfield 说,“我们每天使用着开源社区提供的优秀的项目,这些项目让大家更好的工作。我们在使用这些有用的项目得到好处之后也得反馈社区。”
下面基于在 Airbnb 公司大数据平台架构构建过程的经验,给出一些有效的观点。
- 多关注开源社区:在开源社区有很多大数据架构方面优秀的资源,需要去采用这些系统。同样,当我们自己开发了有用的项目也最好回馈给社区,这样会良性循环。
- 多采用标准组件和方法:有时候自己造轮子并不如使用已有的更好资源。当凭直觉去开发出一种“与众不同”的方法时,你得考虑维护和修复这些程序的隐性成本。
- 确保大数据平台的可扩展性:当前业务数据已不仅仅是随着业务线性增长了,而是爆发性增长。我们得确保产品能满足这种业务的增长。
- 多倾听同事的反馈来解决问题:倾听公司数据的使用者反馈意见是架构路线图中非常重要的一步。
- 预留多余资源:集群资源的超负荷使用让我们培养了一种探索无限可能的文化。对于架构团队来说,经常沉浸在早期资源充足的兴奋中,但 Airbnb 大数据团队总是假设数据仓库的新业务规模比现有机器资源大。
Part 2:大数据架构预览
这里是大数据平台架构一览图。
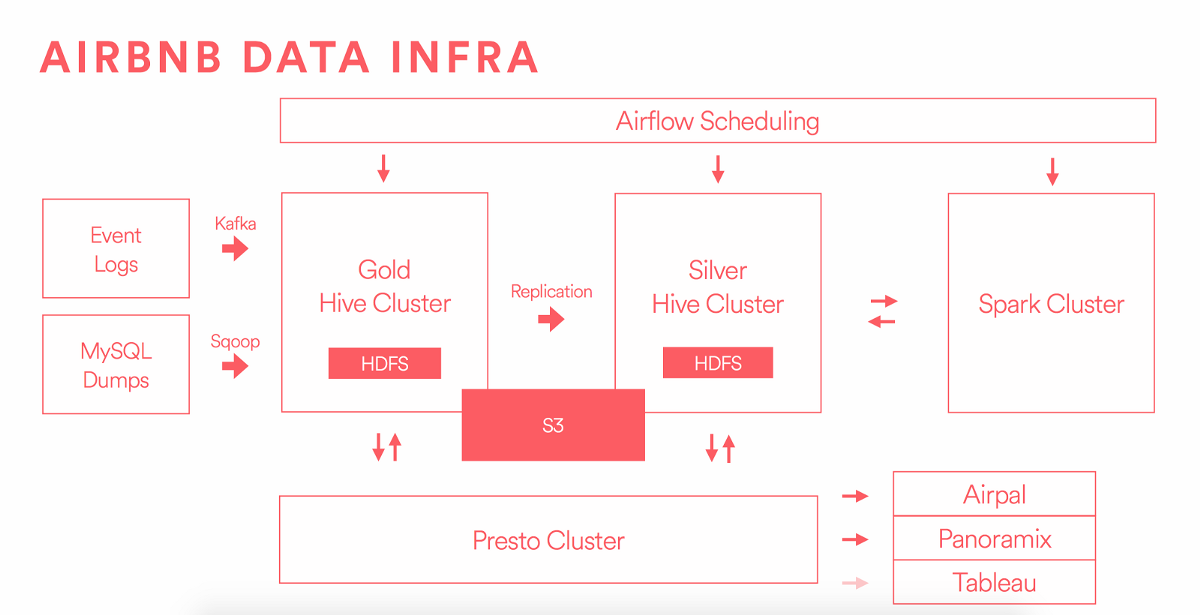
Airbnb 数据源主要来自两方面:数据埋点发送事件日志到 Kafka;MySQL 数据库 dumps 存储在 AWS 的 RDS,通过数据传输组件 Sqoop 传输到 Hive“金”集群(其实就是 Hive 集群,只是 Airbnb 内部有两个 Hive 集群,分别为“金”集群和“银”集群,具体分开两个集群的原因会在文章末尾给出。)。
包含用户行为以及纬度快照的数据发送到 Hive“金”集群存储,并进行数据清洗。这步会做些业务逻辑计算,聚合数据表,并进行数据校验。
在以上架构图中,Hive 集群单独区分“金”集群和“银”集群大面上的原因是为了把数据存储和计算进行分离。这样可以保证灾难性恢复。这个架构中,“金”集群运行着更重要的作业和服务,对资源占用和即席查询可以达到无感知。“银”集群只是作为一个产品环境。
“金”集群存储的是原始数据,然后复制“金”集群上的所有数据到“银”集群。但是在“银”集群上生成的数据不会再复制到“金”集群。你可以认为 “银”集群是所有数据的一个超集。由于 Airbnb 大部分数据分析和报表都出自“银”集群,所以得保证“银”集群能够无延迟的复制数据。更严格的讲,对于“金”集群上已存在的数据进行更新也得迅速的同步到“银”集群。集群间的数据同步优化在开源社区并没有很好的解决方案,Airbnb 自己实现了一个工具,后续文章会详细的讲。
在 HDFS 存储和 Hive 表的管理方面做了不少优化。数据仓库的质量依赖于数据的不变性(Hive 表的分区)。更进一步,Airbnb 不提倡建立不同的数据系统,也不想单独为数据源和终端用户报表维护单独的架构。以以往的经验看,中间数据系统会造成数据的不一致性,增加 ETL 的负担,让回溯数据源到数据指标的演化链变得异常艰难。Airbnb 采用 Presto 来查询 Hive 表,代替 Oracle、 Teradata、 Vertica、 Redshift 等。在未来,希望可以直接用 Presto 连接 Tableau。
另外一个值得注意的几个事情,在架构图中的 Airpal ,一个基于 Presto,web 查询系统,已经开源。Airpal 是 Airbnb 公司用户基于数据仓库的即席 SQL 查询借口,有超过 1/3 的 Airbnb 同事在使用此工具查询。任务调度系统 Airflow ,可以跨平台运行 Hive,Presto,Spark,MySQL 等 Job,并提供调度和监控功能。Spark 集群时工程师和数据分析师偏爱的工具,可以提供机器学习和流处理。S3 作为一个独立的存储,大数据团队从 HDFS 上收回部分数据,这样可以减少存储的成本。并更新 Hive 的表指向 S3 文件,容易访问数据和元数据管理。
Part 3:Hadoop 集群演化
Airbnb 公司在今年迁移集群到“金和银”集群。为了后续的可扩展,两年前迁移 Amazon EMR 到 EC2 实例上运行 HDFS,存储有 300 TB 数据。现在,Airbnb 公司有两个独立的 HDFS 集群,存储的数据量达 11PB。S3 上也存储了几 PB 数据。
下面是遇到的主要问题和解决方案:
A) 基于 Mesos 运行 Hadoop
早期 Airbnb 工程师发现 Mesos 计算框架可以跨服务发布。在 AWS c3.8xlarge 机器上搭建集群,在 EBS 上存储 3TB 的数据。在 Mesos 上运行所有 Hadoop、 Hive、Presto、 Chronos 和 Marathon。
基于 Mesos 的 Hadoop 集群遇到的问题:
- Job 运行和产生的日志不可见
- Hadoop 集群健康状态不可见
- Mesos 只支持 MR1
- task tracker 连接导致性能问题
- 系统的高负载,并很难定位
- 不兼容 Hadoop 安全认证 Kerberos
解决方法:不自己造轮子,直接采用其它大公司的解决方案。
B) 远程读数据和写数据
所有的 HDFS 数据都存储在持久性数据块级存储卷(EBS),当查询时都是通过网络访问 Amazon EC2。Hadoop 设计在节点本地读写速度会更快,而现在的部署跟这相悖。
Hadoop 集群数据分成三部分存储在 AWS 一个分区三个节点上,每个节点都在不同的机架上。所以三个不同的副本就存储在不同的机架上,导致一直在远程的读数据和写入数据。这个问题导致在数据移动或者远程复制的过程出现丢失或者崩溃。
解决方法:使用本地存储的实例,并运行在单个节点上。
C) 在同构机器上混布任务
纵观所有的任务,发现整体的架构中有两种完全不同的需求配置。Hive/Hadoop/HDFS 是存储密集型,基本不耗内存和 CPU。而 Presto 和 Spark 是耗内存和 CPU 型,并不怎么需要存储。在 AWS c3.8xlarge 机器上持久性数据块级存储卷(EBS)里存储 3 TB 是非常昂贵的。
解决方法:迁移到 Mesos 计算框架后,可以选择不同类型的机器运行不同的集群。比如,选择 AWS c3.8xlarge 实例运行 Spark。AWS 后来发布了“D 系列”实例。从 AWS c3.8xlarge 实例每节点远程的 3 TB 存储迁移数据到 AWS d2.8xlarge 4 TB 本地存储,这给 Airbnb 公司未来三年节约了上亿美元。
D) HDFS Federation
早期 Airbnb 公司使用 Pinky 和 Brain 两个集群联合,数据存储共享,但 mappers 和 reducers 是在每个集群上逻辑独立的。这导致用户访问数据需要在 Pinky 和 Brain 两个集群都查询一遍。并且这种集群联合不能广泛被支持,运行也不稳定。
解决方法:迁移数据到各 HDFS 节点,达到机器水平的隔离性,这样更容易容灾。
E) 繁重的系统监控
个性化系统架构的严重问题之一是需要自己开发独立的监控和报警系统。Hadoop、Hive 和 HDFS 都是复杂的系统,经常出现各种 bug。试图跟踪所有失败的状态,并能设置合适的阈值是一项非常具有挑战性的工作。
解决方法:通过和大数据公司 Cloudera 签订协议获得专家在架构和运维这些大系统的支持。减少公司维护的负担。Cloudera 提供的 Manager 工具减少了监控和报警的工作。
最后陈述
在评估老系统的问题和低效率后进行了系统的修复。无感知的迁移 PB 级数据和成百上千的 Jobs 是一个长期的过程。作者提出后面会单独写相关的文章,并开源对于的工具给开源社区。 大数据平台的演化给公司减少大量成本,并且优化集群的性能,下面是一些统计数据:
- 磁盘读写数据的速度从 70 – 150 MB / sec 到 400 + MB / sec。
- Hive 任务提高了两倍的 CPU 时间
- 读吞吐量提高了三倍
- 写吞吐量提高了两倍
- 成本减少百分之七十
查看英文原文: Data Infrastructure at Airbnb
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论