虽然数据科学是一个比较火爆的话题,也受到越来越多重视,但是企业内部数据科学现状却是:不同数据分析人员使用着包括 Python、R、Spark 在内的多种开源产品,并且版本不一;不同开源技术的使用导致数据资产分散存在,形如散沙;最严重的是,当企业内部多位数据分析人员需要协同工作的时候,缺少一个集成多语言、多数据资产、适于统一管理的平台。正因为看到以上挑战,IBM 在去年推出 IBM Data Science Experience (DSX),解决数据科学家协同工作的问题。近日 InfoQ 记者采访了 IBM 分析平台部门资深大数据专家吴敏达,请他详解 DSX。
支持多种语言 DSX 让协作变得更容易
数据分析并不是什么新鲜事物,对于市面上的数据分析产品,其实大家并不陌生。但是因为不同版本、不同开源语言的数据分析工具“群雄割据”,反而使得数据统一管理在企业内部成了一道难题。
据吴敏达介绍,DSX 支持当前几乎所有主流的算法方面的开源语言,比如 R、Python、Scala。在 DSX 平台上,用户可以自由切换使用不同开源语言,只需要打开浏览器输入链接就可以直接使用,它帮助我们免去了安装不同开源平台的烦琐,解决了不同开源平台杂乱无章管理的痛点,这也使得 DSX 可以协助数据科学家在统一平台上进行协作。而无论是 DSX 的公有云版本还是私有云版本,也采用完全一样的底层架构,都以浏览器方式进行使用。
通过 DSX 使用流程 看协作闭环如何实现
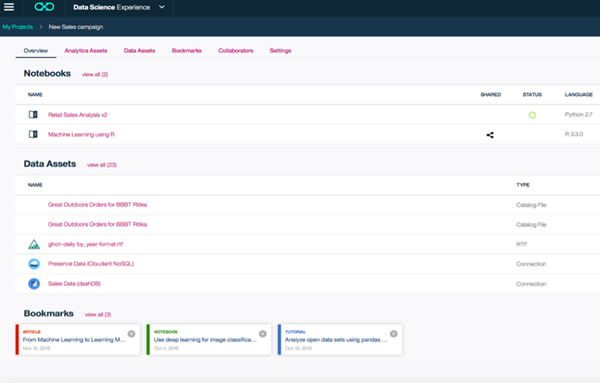
如果说 DSX 的最大优势是什么,吴敏达认为是项目协作概念的引入。项目的资源包括算法模型资产、数据资产、人员、书签,并能够实现任何资产的共享,为团队和个人提供了一个协作的项目空间,大大提高了工作效率。
当然这其中就会涉及到 DSX 在用户中的使用流程了,因为从流程我们能够看到协作如何产生、闭环如何实现。首先是连接数据源;接下来是数据准备和预处理、自动建模、参数优化;然后就是进行模型的发布,其中包括实时,流式传输和批量部署;第四步是模型的应用,比如手持应用、移动应用、网站应用等等;第五步是对模型的管理、持续监控和反馈,可以实现模型的自动学习和自动再训练。可以说 DSX 真正提供了一个端到端的数据科学解决方案。
决策优化、机器学习 DSX 这些功能不容忽视
除对开源算法的支持外,DSX 还配备了决策优化引擎,将机器学习与预测结合在一起,就可以实现从料事如神到运筹帷幄。对此吴敏达列举了某航空公司的例子,通过 DSX 对发动机关键数据和天气、机场等公共数据的收集、存储和利用机器学习的分析,航空公司提前预测发动机故障的可能性。在同一平台 DSX 把前面的预测作为决策优化模型的数据输入,考虑客户服务,成本、维护工程师的可用性和技能,就能为航空公司维护部门提供最优维护计划。
而提到 DSX 就不得不提 SPSS,很多传统金融、电信、制造的客户都对 SPSS 并不陌生并且一直在使用,DSX 未来将支持 SPSS 模型在 DSX 中运行,通过浏览器供用户使用拖拽的方式进行机器学习建模。
对于 DSX,IBM 将其定义为数据科学家日常工作的统一入口。DSX 除具备管理、协作职能之外,DSX 即将支持的 Machine Learning 组件,使更多并不理解底层算法选择、参数优化的数据科学家把精力投向到数据的应用上来,用 DSX 完成数据分析的整个闭环。
基于 Spark 技术 全面拥抱开源
这里值得一提的是 DSX 对 Spark 集群技术的运用。据吴敏达介绍, DSX 采用 Docker 技术布置集群,控制节点实现高可用性,存储节点实现本地数据存储,计算节点实现计算任务。Spark 作为大数据领域当前最热的关键技术,是专为大规模数据处理而设计的快速通用的计算引擎,IBM 对此投入巨大精力,在 Spark 2.x 机器学习领域,IBM 是贡献度第一的厂商,由 IBM 开源的 Apache SystemML 是 Spark 环境下最知名的分布式机器学习项目。

结束语
在企业内部,能够拥有较多数量数据科学家也就意味着企业对数据分析、预测拥有较高需求,而这些需求与业务必然是强关联的,对业务不友好的数据分析管理工具必然不会被广泛使用,而定位于团队协作、致力于成为数据科学家使用入口的 DSX,不仅对开源友好,还拥有决策优化引擎和机器学习平台,要把数据科学家从复杂的数据分析、预测中解放出来让他们真正关心业务,这才是数据科学必然趋势所在。
 吴敏达,IBM 分析平台部门资深大数据专家。有近 20 年信息管理和分析软件相关技术经验,专长是大数据、机器学习和数据分析和可视化等相关领域。他是 IBM developerWorks 的大师级作者,已经发表了 20 余篇技术文章和教程。现从事大数据、机器学习相关技术支持和架构设计工作。
吴敏达,IBM 分析平台部门资深大数据专家。有近 20 年信息管理和分析软件相关技术经验,专长是大数据、机器学习和数据分析和可视化等相关领域。他是 IBM developerWorks 的大师级作者,已经发表了 20 余篇技术文章和教程。现从事大数据、机器学习相关技术支持和架构设计工作。




