
深度学习正在改变一切。正如电子和计算机改变了人类所有的经济活动一样,人工智能将重塑零售业、交通运输业、制造业、医药、电信业、重工业……甚至数据科学本身。而且,像 AlphaGo 这种人工智能超越人类的领域及其应用在不断增长。在Schibsted,Manuel Sánchez Hernández 看到了深度学习所提供的机会,他们很高兴为此而出力。
Manuel Sánchez Hernández 在最近的 NIPS 2016(Neural Information Processing Systems,神经信息处理系统)会议上,听取了 Andrew Ng 分享的一些关于深度学习的想法。Manuel Sánchez Hernández 做了一则笔记,经作者授权,InfoQ 翻译并整理本文,以飨读者。
Manuel Sánchez Hernández 是位于伦敦的 Schibsted Product & Technology 的数据科学家。
深度学习的第一大优势是它的规模。Andrew 总结如下图:
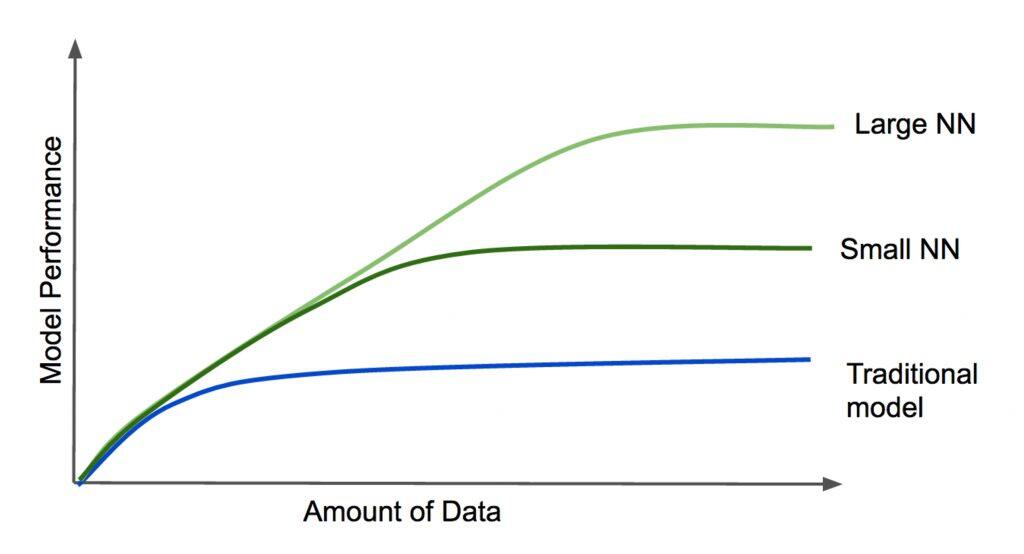
当数据量增加时,深度学习模型表现得更好。不仅如此,神经网络越大,对于更大的数据集,会做得更好。不同于传统的模型,一旦性能达到一定的水平,往模型里增加更多的数据或者改变算法的复杂度,并不能带来性能的提升。
深度学习模型之所以如此强大的另一个原因是它们拥有端到端学习的能力。传统模型通常需要显著的特征工程。例如,一个模型能够转录一个人可能需要做许多中间步骤输入的声音,找到音素,正确链接,为每个链接分配相应单词。
深度学习模型通常不需要这样的特征工程。你通过为模型展示大量实例进行端到端的训练,该技术工作并不是被应用到转换特征,而是进入模型的架构。数据科学家需要决定和尝试他想要的神经元类型、层数以及如何连接它们等等。
构建模型的挑战
深度学习模型有他们自己的挑战。许多决策必须在其构建过程中进行。如果采取错误的路径,将浪费大量的时间和金钱,那么数据科学家如何才能做出明智的决定?确定为了改善他们的模型下一步需要做什么?Andrew 向我们展示了他用于开发模型的经典决策框架,但这次他将其扩展到其他有用的案例中。
让我们从基础开始:在一个分类任务(例如,从扫描做诊断),对于来源如下的错误,我们应该有一个好的想法。
- 人类专家
- 训练集
- 交叉验证(CV)集(也称为开发或开发集)
一旦我们有了这些错误,数据科学家可以遵循基本流程去发现模型模型构建中的有效决策。首先问你的训练错误高吗?如果是这样,那么说明该模型不够好;它可能需要更丰富(例如,更大的神经网络)和不同的架构,或者需要更多的训练。重复该过程直到偏差减小。
一旦训练集错误减少,CV 集的低错误率是必要的。否则,分歧高,意味着需要更多的数据,更多的正则化或新的模型架构。重复该过程,直到模型在训练和 CV 集中表现良好。
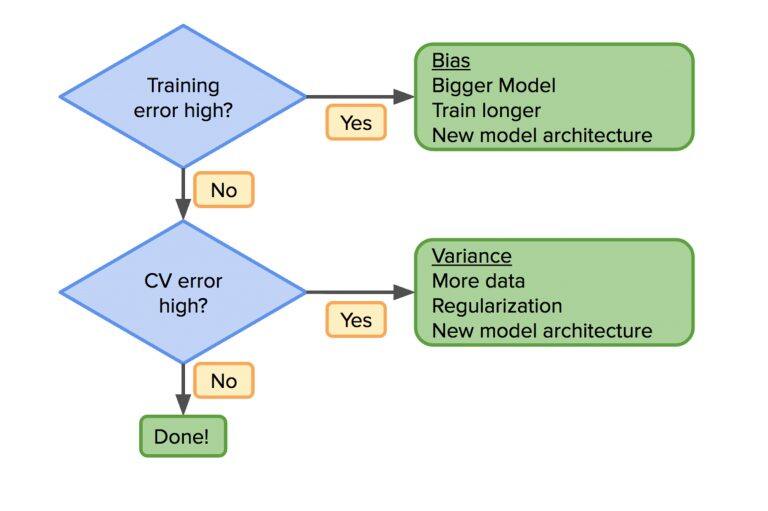
这些过程并没有什么新事物。然而,深度学习已经在改变这个过程。如果你的模型不够好,总有一个“出路”:增加你的数据或使你的模型更大。在传统模型中,正则化用于调整这种权衡,或者产生新的特征——这点看着容易做着难。但是,自从有了深度学习之后,我们有了更好的工具,以减少这两个错误。
改进人工数据集的偏差 / 分歧过程
事实上并没有那么多大量的可用样本,那么还有另一种方法是建立自己的训练数据。一个很好的示例可以是语音识别系统的训练,通过对同一个声音添加噪声可以创建人工训练样本。然而,这并不意味着训练集将具有和实集相同的分布。对于这些情况下的偏差 / 分歧权衡需要不同的框架。
想象一下,对于语音识别模型,我们有 50,000 小时的生成数据,但只有 100 小时的真实数据。在这种情况下,生成的集将是训练集,真正的集应分割成 CV 和测试集。否则,在 CV 和测试集之间将有不同的分布,一旦模型“完成”,将会注意到这些差异。问题由 CV 集指定,因此它应该尽可能接近实集。
在实践中,Andrew 建议将人工数据分为两部分:训练集及其一小部分,我们称之为“训练 /CV 集”。这样,我们将估量以下错误:
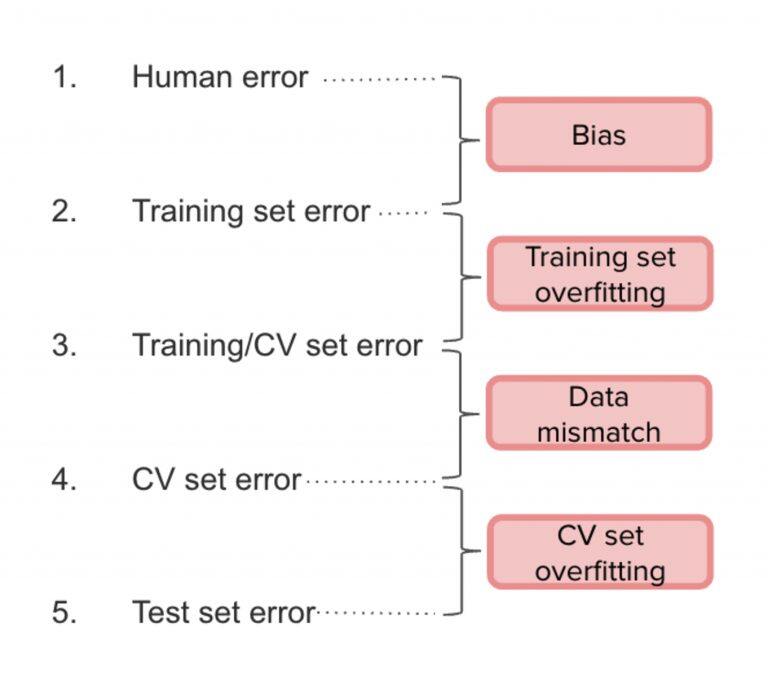
因此,(1)和(2)之间的区别是 _ 偏差 _,(2)和(3)之间的区别是分歧,(3)和(4)之间的区别是由于分布不匹配,(4)和(5)之间的区别是因为过度拟合。
考虑到以前的工作流程应该像这样修改:
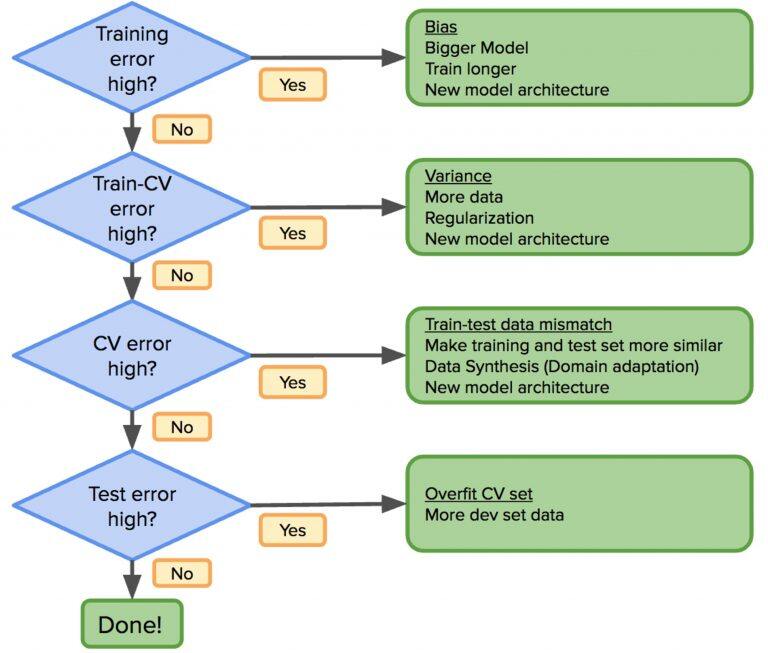
如果分布误差高,修改训练数据分布,使其尽可能类似于测试数据。对偏差 / 分歧的正确理解,能提高机器学习的效率。
人类水平的表现
了解人类的表现水平非常重要,因为这将指导决策。事实证明,一旦一个模型超越人类的表现,通常是很难改善的。因为我们越来越接近“完美的模型”,即没有模型可以做得更好(“贝叶斯率”)。这不是传统模型原有的问题——它的表现已经超越人类水平,但在深度学习领域这个问题变得越来越普遍了。
因此,当构建一个模型时,以人类专家组的表现误差为参考将是“贝叶斯率”的代表。例如,如果一组医生比一位专家医生做得更好,则使用医生组测量的误差。
怎样才能成为更好的数据科学家?
阅读许多论文和复现别人的结果是成为一个更好的数据科学家的最佳和最可靠的路径。这是 Andrew 已经从他的学生身上看到的模式,我对此也十分认同。
即使几乎你做的全都是“苦活”:清洁数据、调整参数、调试、优化数据库等,不要停止阅读论文和验证模型,在验证别人模型的过程中,你将得到启发。
阅读英文原文: How is Deep Learning Changing Data Science Paradigms?
感谢魏星对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论