Tech Minds 是又拍云主办的高端技术领导人私享会系列活动,先后在深圳、广州、北京成功举办,凭借私密的分享环境、高质量的对话嘉宾、前沿的行业和技术话题,又拍云 Tech Minds 已经成为技术圈子中非常受欢迎的“思想汇”活动。9 月 22 日,又拍云 Tech Minds 首次进入上海,就“做追求极致用户体验的偏执狂”的交流主题展开了激烈的讨论。
又拍云 CTO 黄慧攀在 Tech Minds No.4 上做了“访问日志的大数据分享应用”的主题分享,介绍了又拍云在访问日志方面的管理和应用方法。
又拍云目前在全球范围内部署了 4000 多台服务器,一天要产生 2000 多亿条日志,在庞大的数据量下,又拍云采取了快捷的日志管理方式,在处理日志数据时,先对日志进行预先合并计算,再存入 ELK,将记录数量压缩了 1000 倍,大大降低了海量日志数据对服务器的压力。
黄慧攀以又拍云日志系统为例,详细介绍了又拍云如何从日志信息中提炼出全网汇总数据、客户使用情况、服务健康信息等关键信息,随时感知客户的变化,快速定位问题。
以下是黄慧攀的分享全文。
大家好!我今天跟大家分享的是访问日志的大数据分析和应用。
其实在座各位都是做了好多年的技术,所以对业务里面日志的价值都会非常熟悉,所以我今天做的这个纯粹是向大家介绍一下我们又拍云是怎样做的,以及我们在这方面能够获得哪些成果,供大家参考一下,可能会从中得到有价值的东西。也请帮助我们发现做得不够好的地方。
下面两图分别是原始的日志,和格式化之后的日志,我们可以看到这一条日志里面有那些数据。在格式化的日志里面,我们注重的主要是把数据里面每一个字段的价值给提炼出来。
日志隐藏的数据价值
在我们刚才看到的那条日志里面,有客户端的访问 IP,但是如果我们只拿一个 IP 的话,其实完全看不出来它是什么东西。
又拍云会通过 IP 解析出来它的归属地和 ISP,才能知道这个用户到底是哪里的,才能准确地分析到我们影响到了哪里。比如说广东或者北京,是电信还是联通。
在请求的地址这里面,我们会提炼出来一个域名。又拍云做 CDN 业务,每一个域名要对应到不同的客户,所以这个对于我们来说价值点是非常大的,因为我要知道影响到的是哪一个客户、哪一个域名。对于单个公司来说,可能这个价值并不是特别大。但是通过这一点,可以分析出又拍云到底哪一个子业务出问题了,因为一般开发一个 App 或者网站的时候,我们也会用到多个域名。比如说 Api.huaban.com、Image.huaban.com 这样。当我们去看整体速度的时候,由于它是一个平均速度,所以看不出来到底哪一个业务受了影响,但我有了这个维度之后,我就可以看到 API 这里面是不是平均的、哪个速度出问题了,就可以准确地定位到那个影响面在哪里。
对于状态码,我们最主要是用来分析到底有没有出现什么大面积的故障,像 200、404,这种是比较正常的,那如果是 50X 的这种错误的话,就是我们的业务出现了问题,我们后端的系统就需要排查到底哪一个子系统出了问题。
服务器端吐出的字节数,对于我们网络传输这一块的价值比较大,因为我们可以通过这个去计算出一个平均的下载速度。
Content type 是资源类型,后面的那个是请求号,这也是非常重要的一个点。我的资源吞吐到客户端是多少,跟吞吐的字节数一除,就可以得到速度的数值。
日志存储,not only ELK
我们又拍云有 150 多个结点,4000 多台服务器。平均每台服务器日均产生近 5GB 压缩日志。简单计算一下,我们一天至少要产生 2000 多亿条日志,这是一个非常非常庞大的规模。
我们在处理这么多日志的时候,针对不同的统计需求、分析需求,做了四套分析的系统。
大家接触较多的是第一种类型,第一种就是我们很普通的 ELK 方案,我们用了 50 台这种高性能、大容量存储的服务器去做集群,处理原始的日志。由于刚才说到的那个日志量,量级太大了,这个集群只能存两天的数据。并且这两天的数据,查询起来的时候也比较吃力。这是用来给我们的某一个业务,比如客有一个请求,出现了 50X 的错误,那要去排查的话,需要快速定位,我可以在这一个集群里面通过 Request Id 马上找到这一条日志,它的价值点在这里。我们还会其他需求,比如说客户要下载他的全网访问日志。
所以我们做了第二个集群,在这一个集群中,我们服务器的数量明显少了很多,才 4 台,4 台高性能的服务器组成了日志下载的处理集群。这个集群可以做到一小时以内,下载前一个小时的全网日志,并且下载的日志是做了全网排序,按照时间排序。最大的延迟是 8 小时就可以看到昨天一整天的统计分析。
第三个场景是我们需要对网络做一些性能的分析。在这里,我们只用了一台普通的服务器去做,接收所有节点上面二次处理后的数据,并且可以输出到全网的节点质量报告,还可以存一个月的历史数据。历史数据是我们用来做网络调用的。这里面有一个特点,就是我们这台服务器,它压根儿没有做任何数据处理的工作,它只是做存储,还有后面的展现。
第四个,我们有一台普通的服务器。接受所有节点的二次处理的数据之后,并且输入到 ES,在这个 ES 里面,再输出多种维度的分析数据。后面的这两个将会是我们今天分享的重点,就是如何使用最少的资源达到我们需要的那个效果。
我们刚才主要在说怎么能够分析这么大量的日志,并且从这些日志里面提炼出它们的价值来。这里刚才提到了,我们会用到 ELK,但是我们普通的用法可能就只有 ELK 了,就像刚才提的那四个解决方案里面的第一种,这 50 台机器组成的一个大集群,把所有的原始日志都灌进去。但是它有明显的缺点,就是它要存的数据量实在太大,集群规模会非常庞大。我当时在北京做这个分享的时候,京东那边数据分析的朋友跟我们交流,他们是用一百多台高性能大容量的服务器组成了 ELK 的集群,来做这样一件事情。
但是我们要做的这个事情,如果仅局限于 ELK 的话,会付出非常大的成本。所以说我们“not only ELK”,还需要一些我们自己加上去的东西,才能把它管得更好。这个就是我们今天所要讲的重点。
又拍云 ELK 解决方案:1000 倍压缩效果
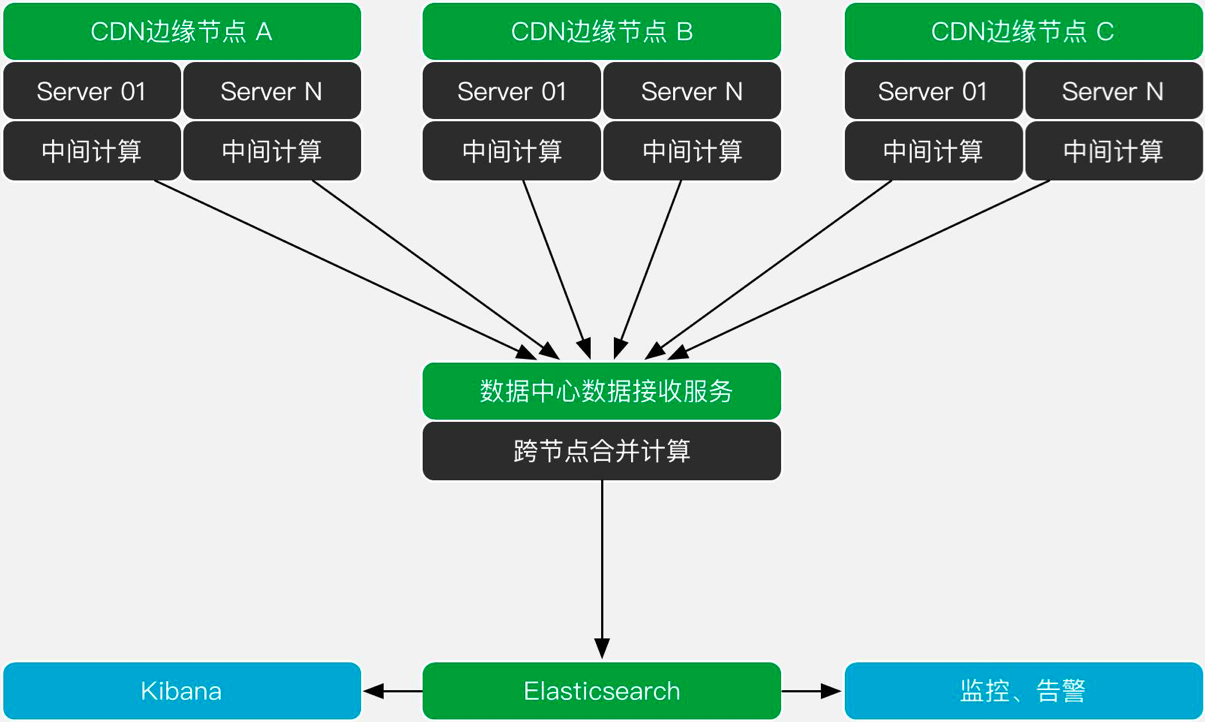
在又拍云 ELK 解决方案里面,ELK 它只不过是一个存储容器、展现数据,并不是我们整个解决方案里面的全部。
又拍云有一个天生的优势——在边缘有几千台服务器。每一台服务器它所产生的日志,就是一个数据源。我们可以把一些计算放到这个边缘上面去。每一台服务器我们都会有中间计算的逻辑,把日志以及日志需要提炼的点直接在本机上面做掉。这样可以加快我们数据产生的速度。
这些数据会汇聚到我们的数据中心里面,同时做一个二次的处理。有一些数据维度是针对整个节点的,所以我们在这里有一个中间层,把这些数据收集回来之后还会做一个跨节点的合并计算。这样得到一个二次计算的结果,之后才会存入到我们的 ES 里面。ES 存进去了之后,它其实就可以做出丰富的数据展现,还有做更多的,比如说监控这种事情。
接下来我说一下,我们在边缘里面进行二次处理的逻辑,我们在边缘每 5 分钟会切出一个 NGS 的访问日志文件,切出来的同时,会启动计算逻辑,这个计算逻辑在每一台机器上面都有。在这里主要是有一个合并计算,以及多维度的数据提炼。多维度的数据提炼,比如说 IP 归属地、线路、访问域名、对应客户等。这些业务逻辑都会在前面的边缘节点去完成。根据这一个 5 分钟的日志,它统计了一下之后,会合并生成一份二次处理后的数据,然后再以 JSON 的格式传到在数据中心的这个接收服务器里来,然后它再合并一下,以 JSON 的格式存到 ES 里面去。
纯裸日志数据存到集群的话,性能非常低,并且服务器的资源占用也很高,对于你的公网带宽,还有延时的挑战都很大。但是把日志进行预先的合并计算之后再存到 ELK 里面,记录的数量级别压缩了 1000 倍还不止。具体得看业务产生的原始日志量有多少。因为它不是线性增长的,它的倍率并不随着你的日志量线性增长,它只会随着你平台里面节点的数量增多而增长。在这里面,一台服务器,5 分钟跑 1000 个请求,产生的二次处理是一条。跑 10000 万个请求,出来的二次处理结果还是一条。所以说它不是一个线性的增长,日志数量越大,起到的压缩效果会更强。
日志提炼后的价值
这些数据存到 ELK 里面,读取性能很高,秒级别就可以读取到统计结果。如果使用传统的 50 台机器集群,如果要看前面一个小时的统计数据,估计得等个几十秒,甚至几分钟。
原始日志只有基础的信息,需要二次提炼才能把价值给提炼出来的。针对于又拍云的业务来说,需要提炼 IP 归属地、服务节点信息、服务状态、缓存命中率、路由状态等,其他业务或许会需要慢日志等信息。日志里能提炼很多有价值的信息,比如说 slow 是在哪一张表里、集中在哪一个字段里。这种我们都可以把它分析出来放到 ELK 里面,然后可以很直观地看到业务性能的瓶颈在哪里。
这里还有一种更简单的办法——用 APM。但是我们做技术的可能都会想,这个 APM 可能跟我们业务的吻合度不高,用 APM 这些系统去定制一些逻辑会比较困难。如果我们是自己去做原始日志的价值提炼,才能最清楚应该提炼哪些东西,也就可以很方便的做到这种操控。
用又拍云非常简单的一条 Nginx 日志举例说明一下,经过二次处理和价值提炼之后,我们得到了哪些有价值的信息。
全网汇总信息
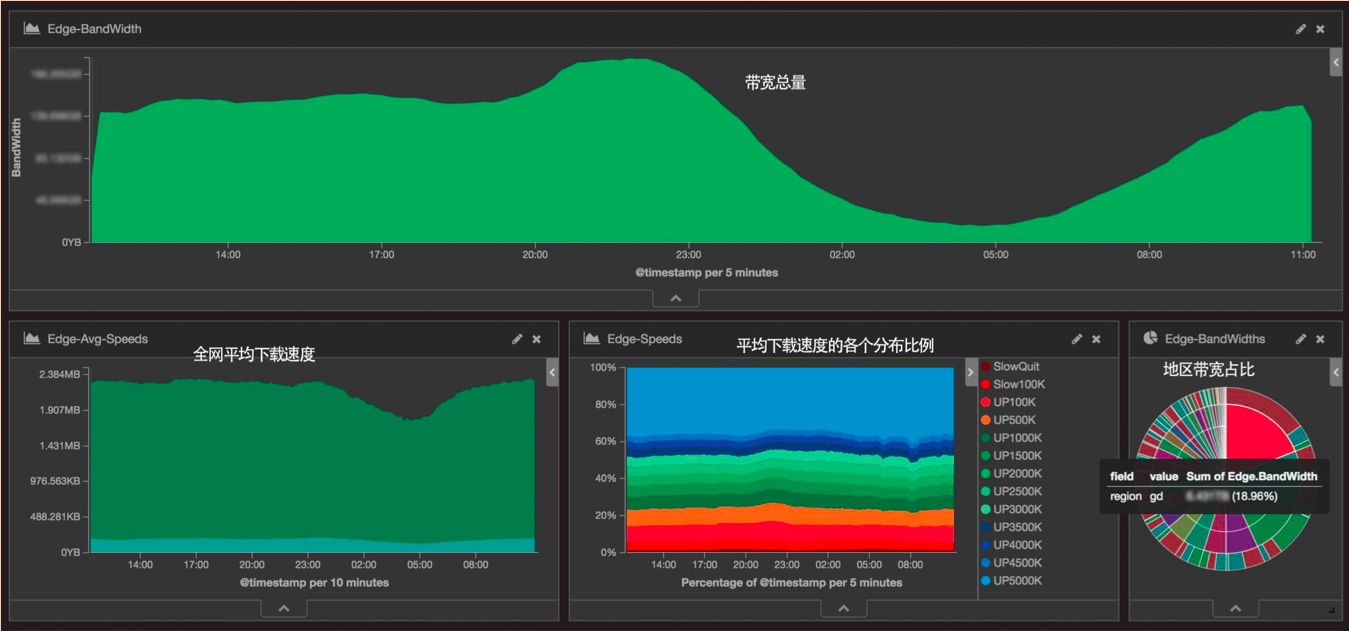
这个是我们全网的汇总信息。在这里我们可以看到全网的总带宽情况、全网平均下载速度、全网下载速度各个区间的比例。我们把区间分成 100K 到 500K,1M,到 2M、3M、4M 这样,每一个下载区间的比例都可以很方便地看出来。右边会有一个地区的带宽占比,哪一个地区的带宽使用量是最大的,一目了然。
客户使用情况
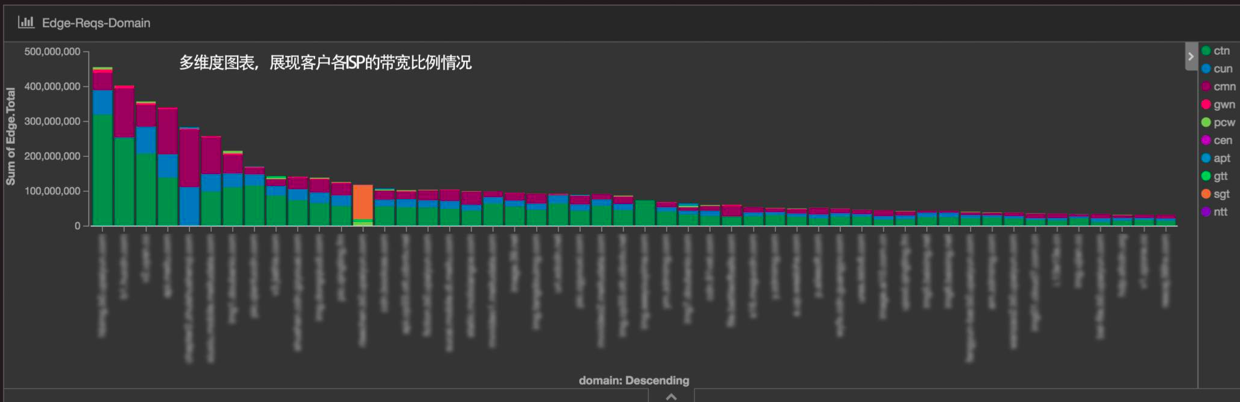
我们可以实时地看到又拍云平台里面大客户的分布情况。具体某个客户使用的网络覆盖信息,也可以在这里面得到非常有效的展示。如果突然之间有一个大客户要加入又拍云平台,这个系统可以马上感知到,因为这个图表是每分钟刷新的。
服务健康监控
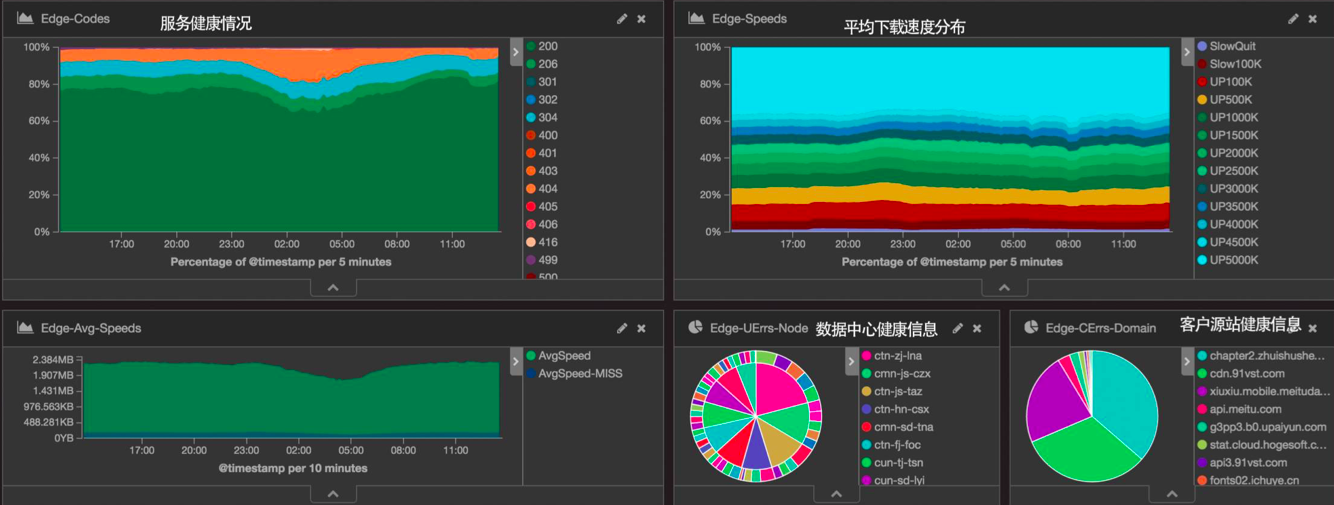
又拍云服务的健康检查,可以针对到某一个域名上面,可以看到它的全网状态,吞吐到底是 200 OK 为主,还是说出现了 50X 的错误。在这一个页面能够比较快速地查看到各类问题。
又拍云有两类客户,一种是有用到又拍云存储的,还有一种是自主源站的。
如果是用我们云存储服务的,那在左一的饼图里面,我可以看到到底哪一个节点出现的错误数据比较多,可以非常快速地定位到全网里面是不是有一个节点出现了故障。
通过右边的饼图,又拍云可以很迅速地定位到客户的哪个源站出了问题。监控部门的同事看到客户的状态异常,马上主动联系到我们的客户,告知他们的源站出了问题。
业务数据分析、合理调度资源
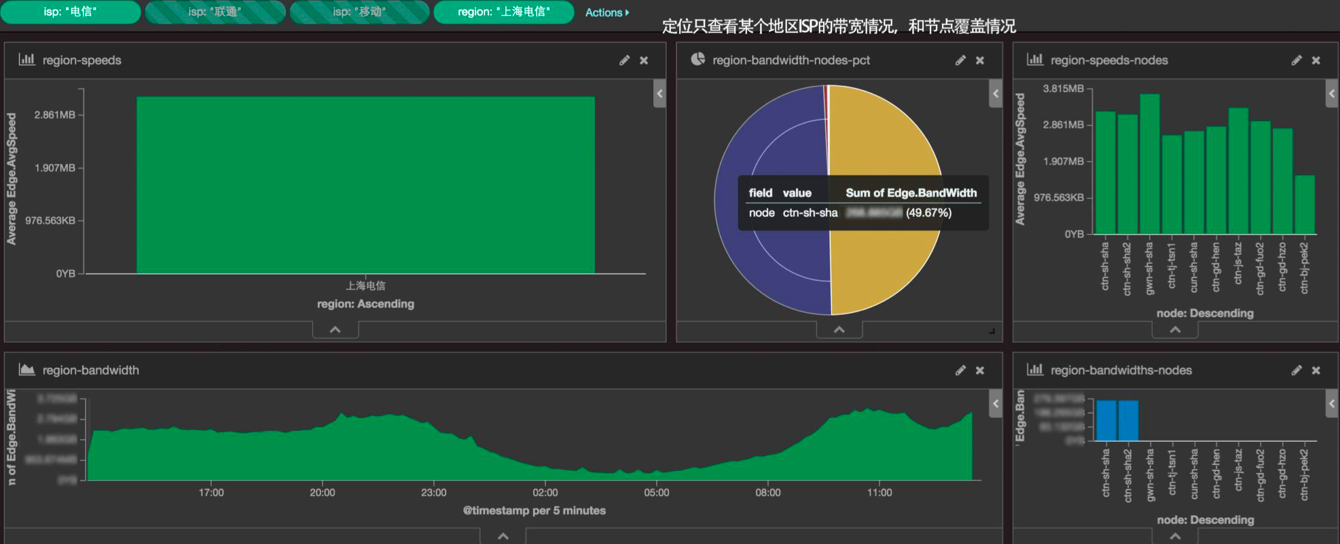
通过提炼日志数据,我们还可以进行业务数据分析。比如根据客户端地域、ISP 去查看 CDN 的服务情况。我们现在比较关注的是有没有做跨节点的覆盖,在这张图里就可以定位准确定位到,就是说我要看一下上海电信到底用了哪些节点去覆盖。在这个饼图里面,可以很准确地看到其实只用了两个节点,并且两个都是上海电信的节点。饼图里有非常细的紫色区域,如果这个紫色区域的比例比较大的话,就是一个异常的情况,说明我们的 DNS 解析准确度不高,或者说调度策略出问题了,把外面的那些节点弄给上海电信的用户去访问了。
这些数据信息是我们资源调度的一个依据。比如说我们现在要覆盖新疆,但是又不知道新疆的用户有多少,他们需要多少带宽。放在以前,只能盲目地提需求——我要覆盖新疆电信,你去找个节点。找个节点,是多少带宽呢?不同的带宽,采购的成本是不一样的。有了这个数据之后,我们就可以做出很准确的决定。根据全网的日志统计,新疆电信会用到 2 到 3 个 G 的带宽,并且这个是准确的数据。我可以提供准确的需求给我们采购的同事,说我要 3 个 G 的带宽,你按照这个需求确定一下采购量。
遇到的难点
以上就是我们又拍云从日志里面提炼出来的一些价值点。而我们在做这个事情的过程中,也遇到了有很多难点,或者说我们踩过的坑,这里可以分享一下。
- 第一个是性能的问题。边缘有 4000 多台服务器,但不可能说所有的 CPU 计算资源都可以给你去做日志处理。其实每台服务器可能给到日志处理的资源的只有 1~2%。这样的话就对于二次处理的程序的性能要求就会非常高,所以我们采用了在内存中直接做流式的计算。这个对于开发难度的要求是比较高的,但它的性能很高,并且很稳定。
- 第二个是在接收服务端的合并处理的方案上。又拍云的日志量级非常巨大,不能用一般的方案去做合并统计,比如说用 redis。redis 可能大家都认为是非常快的一个解决方案,它的性能已经非常高效了。但是在又拍云的日志场景里面,完全不能用 redis。我们主要是用共享内存去做数据统计,直接在程序里面使用内存跟使用 redis 去做计算,它们的性能差距是千倍万倍以上的——因为我们没有任何网络 IO 的产生。我用 redis 的话,起码要产生 1、2 个网络 IO,1 个网络 IO 最快都要 1、2 毫秒;但是在内存里面是纳秒,两者完全不在一个级别。
- 第三就是程序化的自动清理历史数据,这个是我踩坑最多的地方。现在我写了一个自动化的程序去自动做历史数据的清理,在整个集群里面,数据是落到每一块磁盘上面的,每一块磁盘都会按照我的节奏,比如说今天落到 A 盘,第二天落到 B 盘。但是在清理逻辑里面,要有一个自动化的过程,就是说 A 盘的容量已经超过 90% 了,就要自动的在 A 盘里面删掉某一天的数据,把这个阈值永远控制在 90% 以内。有了自动化清理之后,就不会出现这个磁盘爆了而影响到整个集群服务的情况。一块磁盘爆了,会导致整个查看、统计出现问题,这里要强调一下,自动化的历史数据的清理的重要性。
刚才说的,在内存里做流式计算是我们整个体系里面最重要的一个环节。如果我们用开源的那些解决方案,比如说 redis,其实它的性能是非常低的,完全不用去考虑。如果它是用 java 去写的,那也不用考虑了,因为它完全没有达到这种量级的要求。
只有我们做到原生的,对日志文件不需要做解压,就能去分析、统计里面的数据,这样才能达到高的性能。这个方案对于磁盘的要求还不高,因为完全是流式处理,不会说把一个压缩日志文件解压到磁盘里面,然后再从磁盘里面读出来,然后再去统计分析。像 Hadoop 这样的方案,都是面临这个问题的,就是说这个日志文件必须是解压一下,放到集群里面,然后再做统计的分析,所以 Hadoop 的性能没办法提高到这种级别。




