当前股票市场的交易者可以了解丰富的股票交易信息。从金融新闻到传统的报纸和杂志再到博客和社交媒体,汇聚着海量的数据,远比股票交易者想关注的股票信息要大得多,这就需要为股票交易者提供信息的有效过滤。这里将开发一个新闻服务给股票证券投资交易者使用,并为股票交易者提供个性化新闻。
这个新闻服务就叫“自动获取金融新闻”,输入各个数据源的金融新闻,也同时输入用户实时股票交易信息。不管何时,在股票交易者所拥有资产证券中占比较大的公司,它们的新闻一到达,将会显示到股票交易者的仪表板上。随着大量股票交易者进行交易,相应的交易信息会发送过来,所以希望拥有一个大数据系统来存储所有交易者的历史交易信息作为真实数据源,然而,处理海量数据会非常慢以至于不能进行实时的数据更新。为了达到实时跟踪和维持数据结果为最新这两个要求,可以采用Lambda 架构来实现。
Lambda 架构优势
在传统 SQL 系统,更新一个表只是对已存在字段的值进行更改,这在少量的服务器上的数据库工作的很好,可以水平扩展到从库或者备份库。但是当数据库扩展到大量数据服务器上时,硬件崩溃等情况下恢复数据到失败点就比较困难和耗时,而且由于历史不在数据库中,仅仅存在 log 日志,数据崩溃将导致一些不可见的数据错误,即脏数据。
而相对应地,一个分布式、多副本消息队列的大数据系统可以保证数据一旦进入系统就不会丢失,即使在硬件或者网络失败的情况下。存储更新的所有历史可以重建真实的数据源,并能保证每次批处理之后结果正确,然而,为了在实时数据更新后得到最新完整的数据集,需要重新处理整个历史数据集,将会耗费太长的时间。为了解决这个问题,可以在 Lambda 架构中增加一个实时组件,此组件只存储数据更新的当前值,可以保证快速实时得到结果,工作过程类似于传统的 SQL 系统。实时处理层的脏数据将会被后续批处理覆盖掉,这个高可用、最终一致性的系统可以实现准确的结果。当前值的任何错误,实时处理层的报告,硬件或者网络错误,数据崩溃,或者软件 Bug 等将会在下一次批处理时自动修复。
自动获取金融新闻项目的数据管道
整个数据管道流动如图 1:
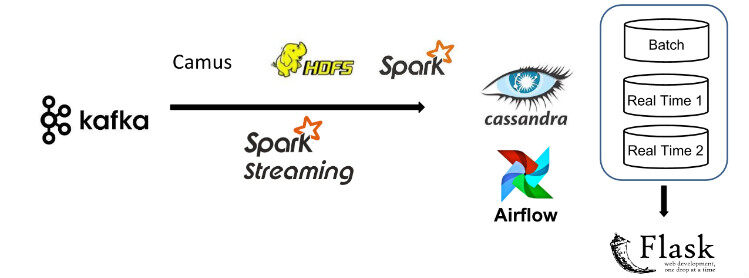
图 1
输入数据格式为 JSON,主要来自综合交易信息和 Twitter 新闻。JSON 格式的消息会 push 到 Kafka,并被批处理层(batch layer)和实时处理层(real-time layer)消费。使用 Kafka 作为数据管道的输入起点,是因为 Kafka 可以保证即使在硬件或者网络失败的情况下,消息也会被传输到整个系统。
在批处理层, Camus (Linkin 开源的项目,现已更名为 Gobblin )消费所有 Kafka 过来的消息并保存到 HDFS 上,然后 Spark 处理所有的交易历史计算每个股票交易者持有的股票准确数量,对应的结果会写入 Cassandra 数据库。
在流式处理层,Spark Streaming 实时消费 Kafka 消息,但并不像 Storm 那样完全实时,Spark Streaming 可以达到 500ms 的 micro-batch 数据流处理。Spark Streaming 可以重用批处理层的 Spark 代码,并且 micro-batch 数据流处理可以得到足够小的延迟。
批处理层和实时处理层的结果都会写入到 Cassandra 数据库,并通过 Flask 提供一个 web 接口服务。随着海量交易数据写入系统,Cassandra 数据库的快速写入能力基本可以满足。
实时处理层和批处理层的调度
当最新的消息进入大数据系统,web 接口提供的结果服务总能保持最新,综合批处理层和实时层的处理结果。用一个列子来展示如何简单的使用批处理结果和实时处理结果。
从下图 2 看到,有三个数据库表:一个存储批处理结果(图 2 中 Batch 表);一个存储自上次批处理完成时间点到当前时间的实时交易数据,即增量数据(图 2 中 Real Time 2 表);另外一个存储最新数据,即状态表(图 2 中高亮的 Real Time 1 表)。
任何软件、硬件或者网络问题引起批处理结果异常,都通过单独一个数据库表记录数据增量,并在批处理成功后更新为对应的批处理结果数来保证最终数据一致性。
在这个列子中,假设第一轮批处理起始时间点为 t0,一个交易者做了一笔交易后获得了 3M 公司的 5000 股股票。

图 2
在 t0 时间点,批处理开始,处理完之后最新结果存储在 Real Time 1 表,当前值为 5000 股。

图 3
在批处理过程中,交易者卖掉 3M 公司 1000 股股票,Real Time 1 表更新数据值为 4000 股,同时 Real Time 2 表存储从 t0 到当前的增量 -1000 股,如图 4 所示。
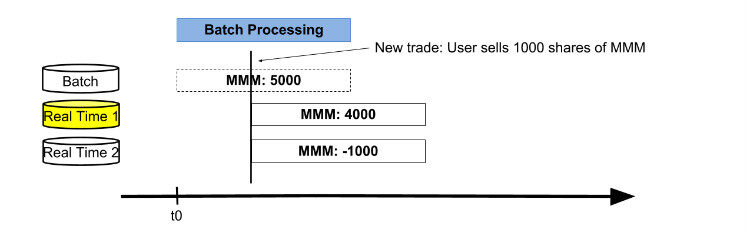
图 4
当批处理结束,三个表的值分别为 5000,4000,-1000。这时,交换 active 数据库表为 Real Time 2 表,进行合并批处理结果和实时结果获得最新结果值。然后重置 Real Time 1 表为 0,后续用来存储从 t1 时间点开始的增量数据。接下来新的一轮以存储最新数据的 Real Time 2 表为起点,循环前面的过程。
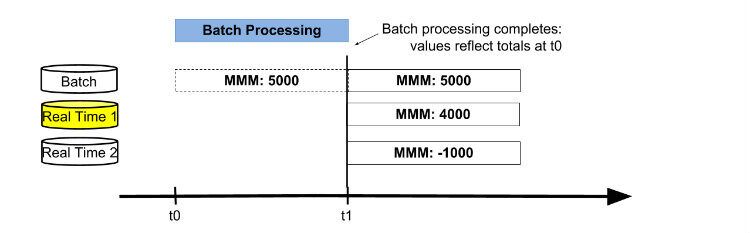
图 5
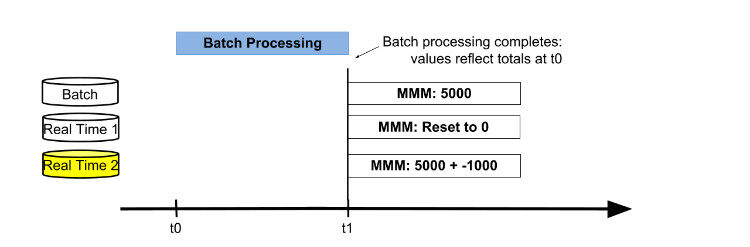
图 6
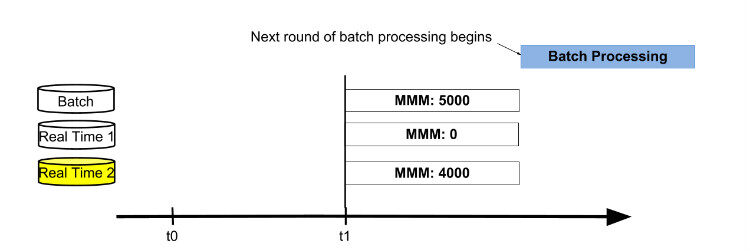
图 7
以上每步处理过程完全成功并写入数据库,可以保证展示给交易者的数据准确性。数据集 处理时间取决于数据集大小,处理任务的计划按序处理而不是按自然天时间。在一个系统中需要工作流支持复杂处理、多任务依赖和资源共享。这里采用 Airbnb 的项目 Airflow ,可以调度程序和监控工作流。Airflow 把 task 和上游各种依赖构建成一个有向无环图(DAG),基于 Python 实现,可以把多个任务写成 Bash 脚本,Bash 命令能直接调用任何模块,并且 Bash 脚本可以被 Airflow 使用,这样使得 Airflow 易操作。Airflow 编程接口比基于 XML 配置的调度系统 Oozie 简单;Airflow 的 Bash 脚本编码量比 Luigi 要少很多,Luigi 的每个 job 都是一个 python 工程。每步合并实时和批量数据的 job 运行都是前一步成功完成退出后。
最后简单总结一下,Lambda 架构涉及批量处理层和实时处理层处理历史数据以及实时更新的数据。 为了 Lambda 架构的实现切实可行,数据处理要设计成批处理层和实时处理层结合。本项目中,有一个“备用”数据库表仅仅存储输入的总数,而不从批处理层读取数据,并允许对批处理层和实时处理层的结果进行简单的聚合。以上就是用 Lambda 架构实现的一个高可用、数据最终一致性的系统。




