

许多人不停抱怨 Ruby 运行缓慢。诚然,它的确不如人意,然而这并非致命伤,因为问题的根源在于你的数据库速度缓慢,成为了瓶颈。因此,这个标题也可以改为 “Ruby 虽慢,但对你而言无关紧要”。
在编写一个在现有的 Postgresql 数据库中提供键值存储的 gem,并对其进行基准测试时,我不断地念叨:Ruby 可不慢,数据库才慢。因此,我决定搜集这些基准数据,以支持我的观点。
在业界,这被称为 I/O 密集型(I/O-bound),与 计算密集型(CPU-bound)性能相对立。我所协助解决的大部分 Ruby 性能问题都属于前者。Ruby 的缓慢并未引发任何问题。
Ruby 很慢,但不重要
让我们明确一点:Ruby 很慢。垃圾收集器、JIT 编译器、其高度动态的特性、更改代码运行时的能力等等,所有这些加在一起,都使得 Ruby 显得较为迟缓。
然而,当人们抱怨 “Ruby 很慢” 时,当深入研究时,通常可以细分为以下三类:
Ruby 很慢,这对我们的用例来说是个问题。Ruby 很慢,但实际上对我们来说并不重要。Ruby 应用程序很慢,但实际上它是堆栈,而不仅仅是语言。
我想更深入地研究最后一个问题,但在此之前,我们先解决前两个问题。
Ruby 每年都在提高性能,这受到了大家欢迎,但从更大的角度来看,这可能并不重要:
速度并不是减缓 Ruby 应用的主要因素。大多数使用 Ruby 的人并不要求它更快。他们固然热衷于免费的提升,但并非因速度而避之不及。
——https://www.fastruby.io/blog/ruby/performance/why-wasnt-ruby-3-faster.html
因为性能确实非常依赖于环境:
[……] 你的系统需要多快?它现在的速度又有多快?如果你能测试它目前的性能,并且了解优秀的性能指标,那么你就应该有信心做出改变。有时候,为了获得其他优势而适度放缓某些需要是明智的决策,尤其是如果这种放缓仍在可接受的范围内。
——《构建微服务》(Building Microservices)Sam Newman 著
因此通常情况下,Ruby 的速度缓慢并不重要,因为你的应用场景无需 Ruby 所追求的规模、速度或吞吐量。做好这种权衡是值得的。通常情况下,开发迅速、成本低廉、发布迅速,这些都是值得为应用程序投入额外资源(如服务器、硬件、SAAS)以保持性能可接受的。
虽然并非始终如此,但时常亦是如此。
快速基准测试
为了再次验证 Ruby 的性能不佳,我进行了一项快速的基准测试,在我近期遇到的一个(简化版)实际工作中,比较了 Ruby 和 Rust 的性能:解析 CSV,从一列中提取一个数字,然后进行桶计数(bucket-count)。这是一个简化版本(而我实际版本使用的 CSV 是这里使用的例子的十倍)。这个例子计算了一部电影的票数,并对这些票数进行分组:0 到 10 票之间,10 到 100 票之间等等。
为了进行对比,我尝试用 Rust 和 Ruby 创建了一个内部尽可能相似的版本。结果令人失望,Ruby 和 Rust 的性能都很差劲,甚至存在一些错误,而且都没有进行性能优化。我确信 Ruby 和 Rust 版本都可以进一步改进(尽管作为 Ruby 专家和 Rust 新手,我已经意识到 Rust 版本比 Ruby 版本更容易进行进一步优化)。所有的基准测试代码都可以在 GitHub repo 中找到。
这并不是一项严谨的科学实验,但它揭示了一个显而易见的事实:Ruby 的确较慢 [1]。
Rust:
Ruby:
Rust 版本的速度大约是 Ruby 版本的十倍,这是一个令人咋舌的差距!然而,在处理更大的数据集时,这种速度差异并非呈线性增长,而是呈现出不规则的变化。其中一部分时间是由启动时间(在这个用例中很难测量)和 JIT 编译器占据的,而另一部分则是 Ruby 中垃圾回收机制的任意启动和停止所有进程所造成的问题。处理大型数据集,使这成为一个真实而恼人的问题。
但两者的绝对差异又如何呢?Ruby 版本仅慢 1.2 秒多一点。这在测试和开发过程中已经足够令人恼火了。当你一遍又一遍地运行此操作时,这一天只需要几分钟的时间:在开发过程中运行大约 20 次的脚本上总共需要 1.2 秒,然后可能每周运行一次。
虽然我只关注 CPU,但内存也是一个重要问题。然而,在现代软件的典型用例中,内存使用并不明显:客户与服务器软件交互时会感到缓慢,但并不会直接体验到内存的使用。然而,不深入探讨这个问题的主要原因是对内存进行基准测试相当复杂。
因此,可以说 Ruby 的确较慢,并且使用较多的资源。它做出了权衡,因此可能包括开发在内的整体成本更低。这取决于具体情况,没有绝对的定论。
让它变慢的是堆栈,而不仅仅是语言
让我们来深入探讨一个不容忽视的问题:Ruby on Rails。虽然有些 Ruby 项目不使用 Rails,但大部分生产中运行的 Ruby 代码都是基于 Rails 开发的。我个人主要使用 Ruby 编写代码,但很少涉及 Rails(因为我不太喜欢它),不过我是个例外。在 Ruby 开发中,几乎总是采用 “用 Rails 进行 Web 开发” 的方式。
其中一个 Rails 的问题是它与数据库的高度耦合(也可以说是一种好处)。Rails 专注于掌控数据库的一切。没有数据库,Rails 将毫无用处,甚至可能阻碍工作进展,而不是提供帮助 [2]。此外,Rails 专注于 Web 开发。虽然你可以在 Rails 中处理非 Web 相关的任务,但这毫无意义。Rails 的目标是处理 HTTP 请求-响应。而且,Rails 的规模相当庞大 [3]。与 Ruby 语言类似,它更侧重于人机工程学(对开发者友好度)而非性能。这是好事!然而,这也导致在 Rails 中性能成为一个问题,甚至比在 Ruby 中更加突出。
因此,“堆栈” 指的是 “使用数据库的 Ruby on Rails”。由于 Rails 专注于 Web 开发,并且只处理 HTTP 请求 - 响应,我们将仅从 Web 服务的角度看待 Ruby。
为了深入分析这个问题,我将会比较一些非 Rails、非 HTTP、纯 Ruby 的脚本。
Ruby 在处理大量数据方面并不擅长,但从本质上讲,这正是 Web 服务所需要的。为了说明相对性能的差异,我们进行了一项实验,比较了在不同源上写入和读取一百万条记录时的表现:内存、内存中的 SQLite 数据库和 Postgresql 数据库。
显然,这并不令人惊讶,内存比其他任何选项都要快得多 [7]。在这里的 Postgresql 是一个 docker 容器,只占用 CPU 资源,而且根本不需要调整配置。这与绝对数值无关,所以具体设置 Postgresql 并不重要。重要的是差异的程度。
数据库写入速度缓慢。即使经过索引和负载状态调优,读取速度依旧无法改善。
然而,这一现象仍需深入探究原因。他们未指明导致缓慢的具体因素。令人意外的是,这也是 ORM 栈的一环。我选择使用 Sequel,因为它相对简单,方便我们剖析问题。
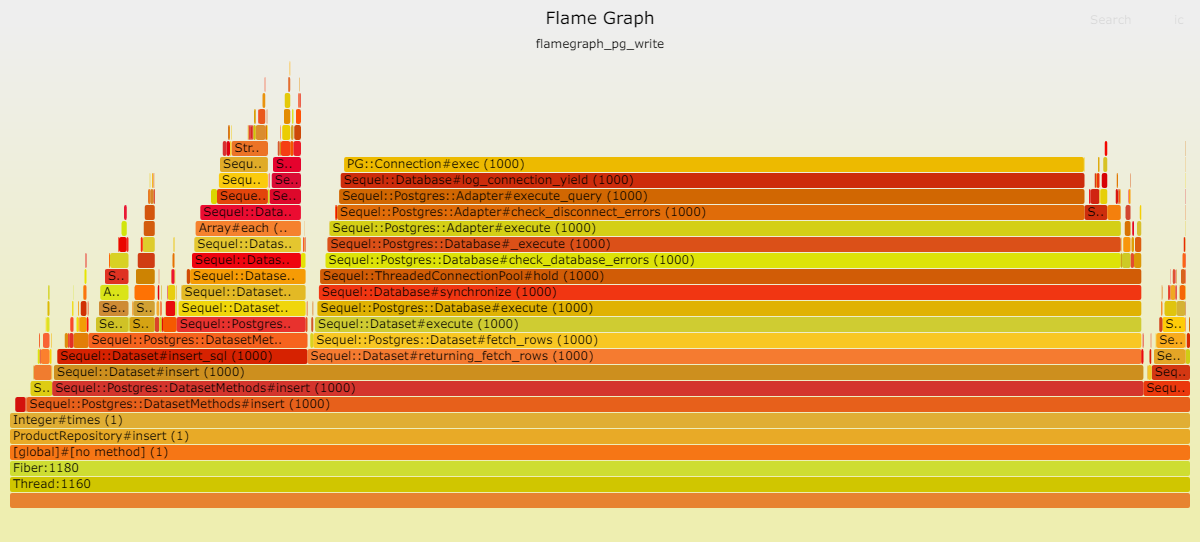
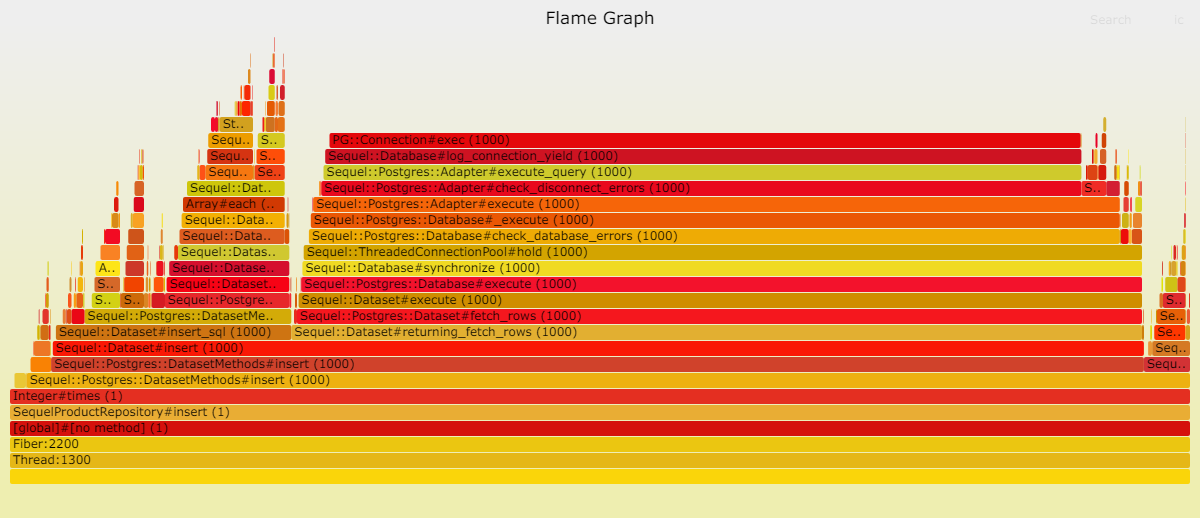
请见以下两幅火焰图,显示在插入数据时,Postgresql 成为瓶颈。这并不奇怪,因为此时数据库需处理大量工作。我们的表只有一项索引,而且是最轻类型的索引。
数据库写入速度之慢令人咋舌,以至于其他时间变得微不足道。
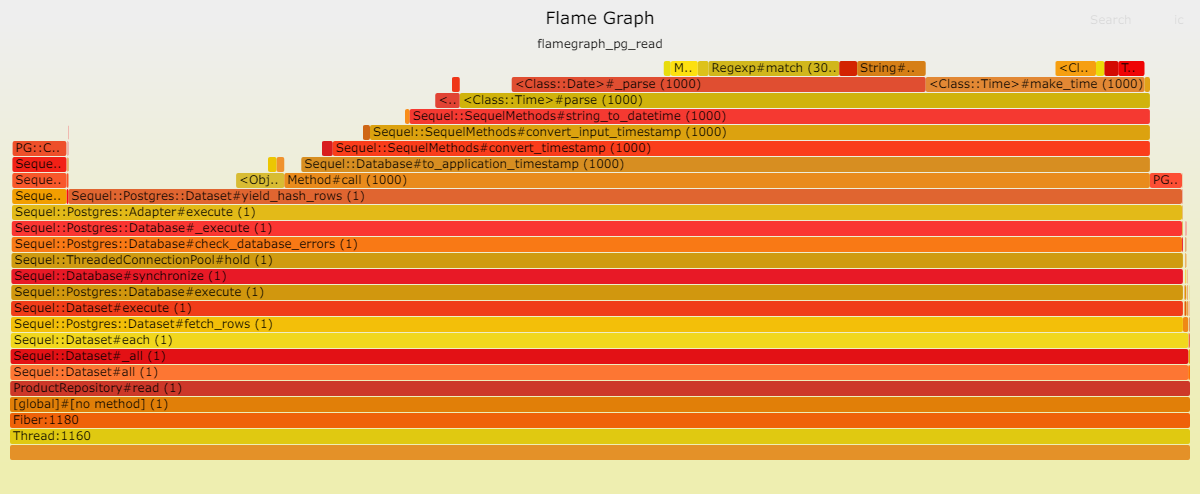
在读取方面,Postgresql 表现卓越。这归功于其简单的查找操作,无需连接,仅使用一个索引,所需数据量也很少等等。然而,解析(处理数据)却耗费了大量时间:DateTime::parse。换言之,DateTime::parse的性能问题相当显著,以至于它在数据库中耗费的时间微乎其微。
我们已经明确了堆栈中的两大性能瓶颈:Postgresql 和 ORM。
需要明确的是:这并不意味着 Sequel 性能低下,或者 DateTime::parse 存在问题 [8]。相反,这表明我们加入堆栈的工具越多,性能就越糟糕。再强调一次:这是显而易见的,并不令人意外。然而,值得重申。
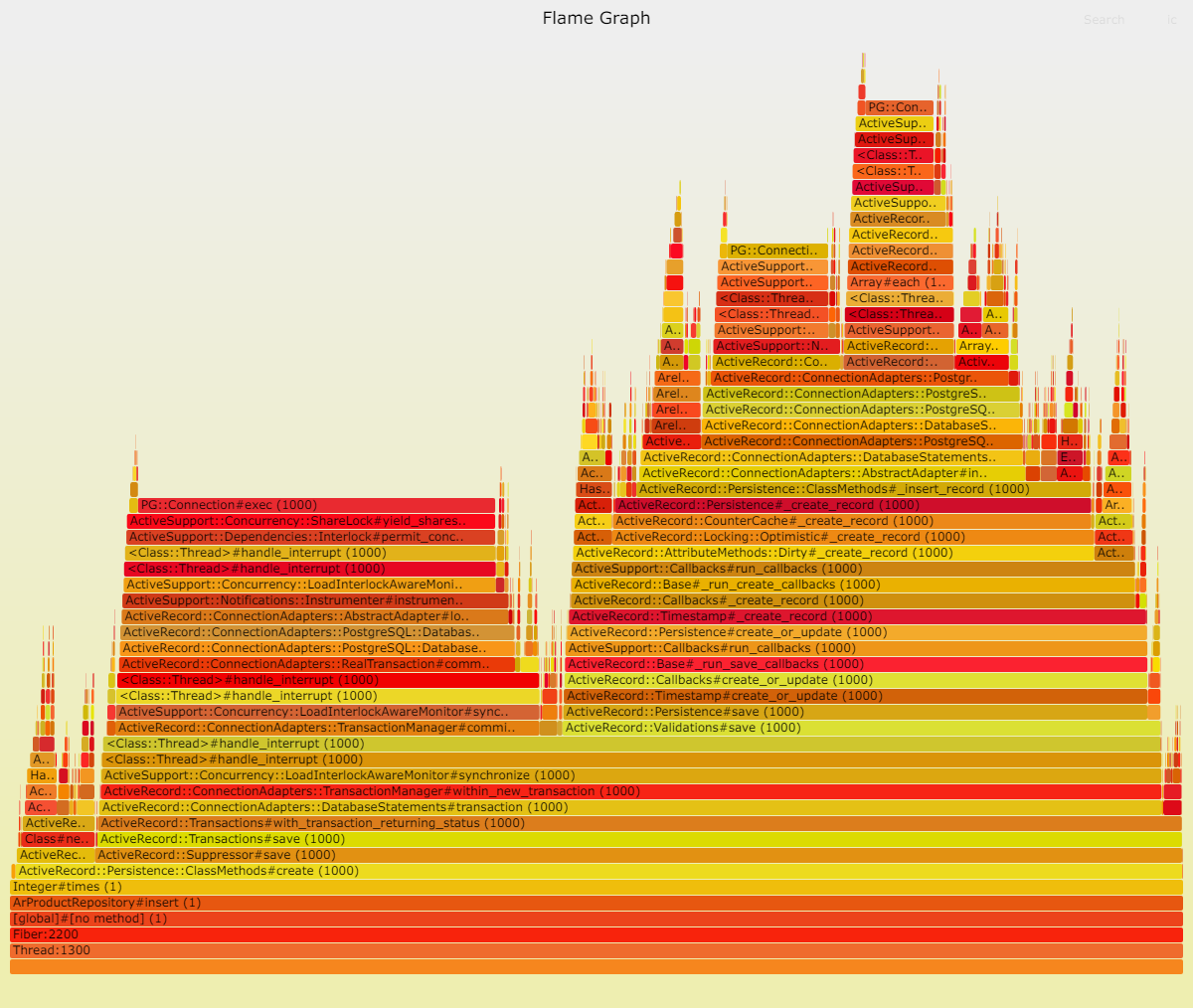
在对整个 Rails 进行全面基准测试之前,我们先来审视一下 Rails 中的 ORM:ActiveRecord。同样地,由于查询操作非常简单,不涉及复杂内容,因此在数据库中所花费的时间非常有限。
通过 ActiveRecord 写入:
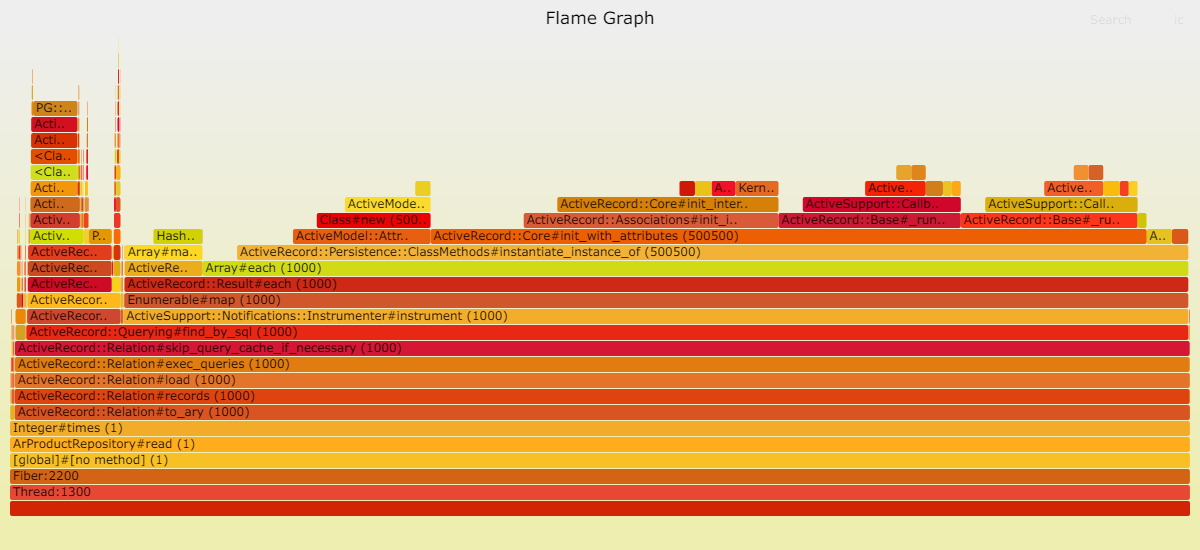
通过 ActiveRecord 读取:
通过 Sequel 读取:
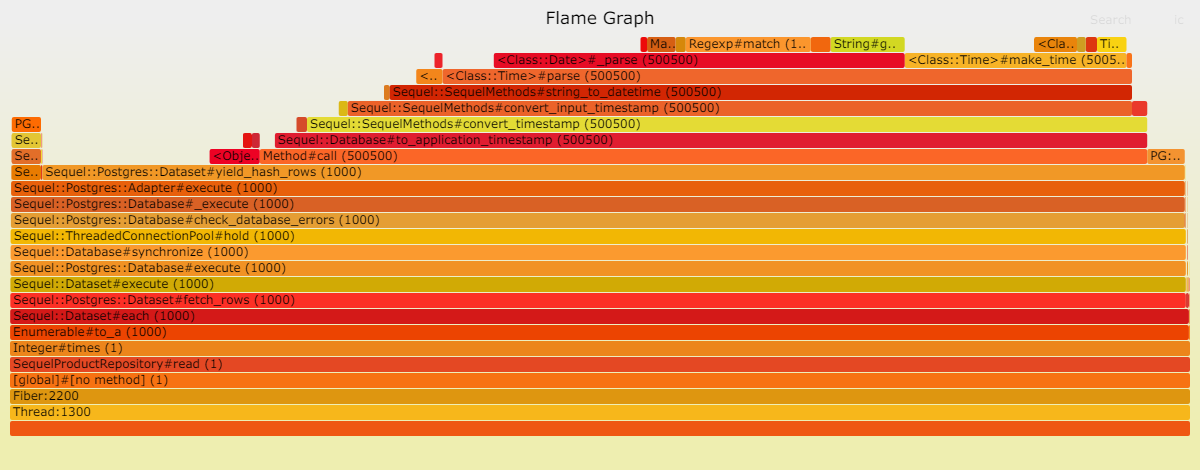
通过 Sequel 写入:
我们可以清楚地看到,Sequel 中的 DateTime::parse 问题依然存在。我推测,ActiveRecord 采用了一种更高效的策略,将 Postgresql 中的日期时间转换为本地 DateTime。
尽管如此,Ruby 的糟糕性能相对来说并不重要。如果最快的数据库查询需要 150 毫秒,那么 Ruby 暂停 15 毫秒进行垃圾回收并没有太大关系。JIT 的开销、Rack 和 Rails 的 HTTP 解析和转发的多层堆栈,除了向数据库插入查询耗时 190ms 之外,对整体性能影响不大。
这个例子展示了从表中获取一条记录的操作,虽然它并非关系型数据库所擅长的领域,但它揭示了 ORM 存在的实际性能问题:缺乏连接、排序、过滤和计算等操作。
因此,即使 ORM 性能较差,数据库仍然是主要的耗时组件。
扩大规模
我们都曾遇到过这样的情况:Ruby/Rails 代码变得错综复杂,设置糟糕透顶,以至于堆栈(或自定义代码)成为瓶颈。问题看似简单解决:只需增加额外服务器。尽管单个请求速度不变,但至少服务器负载不再影响其他用户性能。应用虽未变快,却能容纳更多用户。
起初,这很容易实现,直到数据库再次成为瓶颈。写入关系数据库始终是个难题:只能垂直扩展,即增加更强大的数据库服务器。至于查询(读取)方面,可以通过增加复杂性来解决:读取副本(曾称为 “从属”)。几乎所有常见的关系数据库服务器都支持此方法。虽然并不简单,因为它将“最终一致性”引入了一个设置/框架,这个设置/框架从来没有被设计成最终一致,但这是可行的。写入(创建、插入、更新、删除等)则不然:数据库可能在某个时刻成为瓶颈。除非永远如此:但性能从一开始就并非问题。
解决 Ruby 代码中的性能问题轻而易举:只需增加更多服务器。然而,解决数据库性能问题就没那么容易了,因为扩大关系数据库规模困难重重,甚至有时不可能。
因此,为保持代码可扩展性,应尽量在代码中保留逻辑、转换等元素。将业务逻辑、约束、验证和计算推入数据库,等于放弃了最简单、通常也最经济的性能提升手段:“增加更多服务器”。
Rails
正如多次提到的,Rails 的复杂性导致了真正难以解决的性能问题。让我们深入探讨一下。
引用 DHH 在 Rails 的一句话:
“所有花哨的优化都是为了让你更接近于如果你没有使用这么多技术就会得到的性能”☝️
https://macwright.com/2020/05/10/spa-fatigue.html——https://twitter.com/dhh/status/1259644085322670080
Rails 的内部复杂性对性能有两大影响。首先,它包含大量抽象,被批评为 “黑魔法”。其次,在典型的 HTTP 循环中,数据需要经过所有这些层和所有这些复杂性,直到请求响应完成。
由于 Ruby 处理数据相对较慢(参见下文),数据传递的代码越多,结果就越慢。这对所有软件都是如此,但 Ruby 放大了这一点。Rails 的 163500 行 Ruby 代码当然无助于加快速度。
“代码行” 并非性能指标,但它们是一种指示。即使是最小的 Rails 项目也包含数十万行代码,即使你只使用其中一小部分数据。
针对 Rails 的基准测试已经进行了许多次。我现在将获得更多元数据,而不是继续讨论整个堆栈的 “基准” 和火焰图。少谈数字,多谈概念。因为对于 Rails,我确信性能问题是概念性的。如上所述,技术性能问题是由 Ruby 而不是 Rails 引起的。
ActiveRecord(Rails 中的实现,而非模式 per-sé)是对系统(关系数据库)的抽象,需要大量详细知识来保持性能。ActiveRecord (模式)不仅是一个漏洞的抽象,更多地是一个抽象,隐藏了一些不应被隐藏的细节。
更实际的情况是:几年前我为了修复一个 N+1 查询而加入的 User.active.includes(:roles) 动态地选择它认为你需要的内容。它可能会“突然地、神奇地、动态地”开始构建其他连接和查询,从而降低性能。(好吧,不是从一分钟到下一分钟的运行时,而是经过小的更改)。
我曾在一个拥有百万级用户的应用程序中,导致数据库服务器集群崩溃:原因在于一个无关控制器的简单更改,使 Rails 切换到一个外部连接,该连接具有巨大物化视图,本不应以这种方式连接(用于报告)。然而,Rails 的魔力使其从此开始使用这一特性。每次页面加载都会导致大约 2 秒钟的数据库查询,占用数据库服务器上的所有 CPU 和 IO。
当然,这是个愚蠢的错误。我们没有看到这一点,因为在开发和测试中,性能从未下降。但我们应该注意到的是,这种错误在代码库中比比皆是。这些项目之所以继续运行,唯一的原因是 Heroku 服务器的巨大成本(1200 美元 / 月),能为数百访问者提供服务一天。这样的错误不会导致数据库集群崩溃,而是逐渐累积成昂贵且性能糟糕的应用程序。20 毫秒的减速几乎无法衡量,数百个 20 毫秒的速度减慢在几个月内逐渐增加,使响应变得令人无法接受。最糟糕的是,这些 “错误” 被团队贴上了 “以 Rails 方式完成” 的标签。
Rails 里到处都是这样的 footgun(footgun,意即伤自己的脚的枪,Rails 称其为“尖刀”。译注:指在一个产品上添加一个新东西,容易让枪打着自己脚。表明设计不好,促使用户不敢加东西。)。其中大部分本身是无害的。很容易以次优的方式连接表,对未索引的列进行排序或过滤。Active-record 充满了一些工具,可以很容易地滥用数据库,无需警告。我开发的 Rails 应用程序数量惊人,其中包含某种形式的 .sort(params[:sort by]):仅在 2021 年,我就开发了三个独立的 Rails 应用程序,所有这些应用程序都可以通过使用 ?sort=some_unindexed_field 触发请求来处理数据库。虽然这个例子很极端,可能被视为安全问题,但它说明了让应用程序性能变差是多么容易。
sorting-by-un-indexed-field 示例揭示了 Rails 与数据库的耦合如何使其许多性能问题成为数据库问题。
根据我的经验,Rails 中的性能问题总是:
N+1 个查询。易于检测。难以修复(不引入大量耦合问题)。
未优化的连接。添加简单的
has_many太容易了,这使得开发人员可以在数据库中启动过于繁重的查询。一旦通过应用程序引入和传播,这几乎不可能解决。总有一些代码最终运行类似User.with_access_to(project).notifications.last.sent_to的代码。而且它会查询五个连接表并且连接到至少一个索引上,而这个索引并不是为此准备的。导致大约 800 毫秒的查询。在每次页面加载时。未优化的
where、group和order调用。使用难以筛选、分组或排序或优化不佳的列。使用非索引列。我的经验法则是,每个添加或删除的
where、has_many、group或任何此类 active-record 方法都必须伴随着数据库迁移。因为只有当你已经有了以前没有使用过的索引时,才需要为这种新的查询方式优化数据库(这意味着它以前优化得很差)。另一种情况是当你重用现有索引时,在这种情况下,你很可能应该重构以将查询转移到单一责任(例如,命名范围)。
使用 Rails 人性化的 active-record API,很容易忘记你仍然只是在查询一个复杂的关系数据库。它需要微调、调优和调整,以便在合理的时间内为你提供数据。
使用 Rails,很容易累积许多小错误,从而使数据库成为瓶颈。但是,即使所有这些都在你的控制之下,高性能的数据库调用仍然比许多其他调用慢很多。
从内存和代码中填充某个数组,然后从数据库中填充该数组,速度仍然要快一千倍或更多。正如我在第一段中所展示的那样。
所以,该怎么办呢?我采用的一些经验法则是:
在可以避免的情况下,不要使用数据库。这总是比我想象的更频繁。我不需要将世界上 195 个国家存储在数据库中,并在显示国家下拉列表时加入。只需硬编码或在启动时输入配置读取。见鬼,也许你的电子商务网站的整个产品目录可以是一个单独的 YAML 启动时读取?这适用于比我通常认为的更多的对象。
将逻辑与数据库分离,因为数据库是最慢且最难扩展的地方。
谨慎处理
sort()、where()、join()等调用。如果添加(或删除)了索引,它们必须伴随着至少调优索引的迁移。保持所有数据库调用简单。尽可能少的连接,尽可能少的过滤器和排序。一般来说,数据库可以更容易地为此进行优化。这也使应用程序与实际的数据库细节分离。
N+1 个查询并不总是坏事。有时甚至是首选。因为它们使业务逻辑保留在代码中。并将获取内容的逻辑保存在一个地方,从而允许在那里进行性能优化。
保持对实际性能问题的了解。根据性能是 I/O 密集型的还是计算性的,主动扩大规模。并祈祷它是计算性的。
内文注释:
[1] 不过,我要强调的是:作为 Rust 新手,我花了一个多小时编写 Rust 版本,而作为 Ruby 资深用户(10 年以上),我只用了不到 10 分钟。我需要运行两个版本 2000 多次,然后我花在开发 Rust 版本上的额外时间才能在等待它运行的额外时间中得到回报。
[2] 我确信你可以给我展示一个项目,在那里你不用数据库就可以运行 Rails,而且这很有意义。这些案例是存在的。我遇到的一些问题是:“我已经知道 Rails,但不知道 Sinatra”,或者“管理要求我们在类似的代码库上运行一切”。实际上,最后一个理由不成立。大多数都是合理的理由,除了最后一个:这是选择 Rails 的一个可怕的理由。
[3] 一个快速 grep:超过 9000 个类,超过 33000 个方法;不包括所有神奇的动态方法,比如围绕数据库模型的方法。这还不包括 rails 本身附带的 70 多个依赖项。
[4] 一个常见的 Rails 应用程序将发送电子邮件,可能会生成 pdf,接收 CSV 或导出 CSV,但所有交互通常都通过 HTTP 进行。我知道 Rails 只用于运行 cron 作业、ETL 管道甚至媒体编码的例外情况(我曾研究过),但这些确实是例外情况。
[5] 具有讽刺意味的是,在这种非 http、非 rails 的环境中,性能问题变得不那么明确了,然而在这些情况下,人们通常会因为 ruby 的性能问题而将其作为选项。这也是 Ruby 很少在 Rails(和/或 Web)之外使用的原因之一。
[7] 令人惊讶的是,从内存中的 SQLite 中查找比从数据库中查找要慢。但这说明了另一个重要问题:数据库运行在单独的线程中,甚至可能在单独的硬件上。因此负载是分布式的:在 SQLite 和我们的内存示例中,一个 Ruby 线程完成了所有的过滤、获取和提升。对于外部数据库,这是偏移量。根据你的设置,Ruby 线程甚至可能在数据库进行查找时继续工作。在这种情况下,经过优化以过滤和获取数据的 Postgresql 可以比 SQLite-inside-ruby 更快地完成这项工作。在典型的生产设置中,Postgresql 更适合这一点。
[8] 请注意,虽然 DateTime:parse 很慢,但这个函数是用 C 编写的。之所以慢,并不是因为它是用 Ruby 编写的,而是因为解析如此复杂的文本很慢。对于 Rust 中的功能相当的版本来说,它可能会一样慢。
[9] 有更多的理由说明这是一个更好的主意。最明显的一点是,你永远不能把所有的业务逻辑都放在数据库中,即使你想这样做。因此,你将在多个地方拥有业务逻辑,而不需要任何去往何处的结构。所以把它放在一个地方的显而易见的解决方案是……放在一个地方。唯一可以保存所有内容的地方:你的应用程序。
作者简介:
Bèr Kessels,经验丰富的 Web 开发人员,对技术和开源充满热情。
原文链接:
https://berk.es/2022/08/09/ruby-slow-database-slow/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论