

对话系统近来已经成为一种标准的人机交互方式,为了简化人与计算机之间的交互,几乎每个行业都出现了聊天机器人。聊天机器人正在崛起,为了节省大量的劳动力成本,企业正选择将日常任务委托给聊天机器人,而不是人类。与人类不同,聊天机器人能够同时处理多个用户请求,而且总是有求必应。本文中将介绍如何使用 DeepPavlov 开发聊天机器人,以及为什么 TensorFlow 是一个不可或缺的工具。
对话系统近来已经成为一种标准的人机交互方式,为了简化人与计算机之间的交互,几乎每个行业都出现了聊天机器人。它们可以集成到网站、消息平台和设备中。聊天机器人正在崛起,为了节省大量的劳动力成本,企业正选择将日常任务委托给聊天机器人,而不是人类。与人类不同,聊天机器人能够同时处理多个用户请求,而且总是有求必应。
然而,许多公司并不知道从哪里入手机器人开发来满足他们的业务需求。从历史上看,聊天机器人可以分为两大类:基于规则的和数据驱动的。前者依赖于预定义的命令和模板。这些命令中的每一个都应该由聊天机器人开发人员使用正则表达式和文本数据分析来编写。相比之下,数据驱动的聊天机器人依赖于基于对话数据预先训练的机器学习模型。
本文将介绍如何使用DeepPavlov开发聊天机器人,以及为什么TensorFlow是一个不可或缺的工具。DeepPavlov 是由莫斯科物理与技术学院神经网络和深度学习实验室创建和维护的。DeepPavlov 是向#PoweredByTF 2.0挑战赛提交的一个获奖作品。
本文的代码可以在谷歌Colab上找到。
对话系统的架构
简单起见,我们将从对话系统的最基本构成开始介绍。首先,聊天机器人需要理解自然语言中的表达。自然语言理解(NLU)模块将用户查询从自然语言转换为标签语义表示。例如,“请将闹钟设为早上 8 点”这句话将被翻译成机器可理解的形式,如 set_alarm(8 am)。然后机器人必须确定说话者对它的期望是什么。对话管理器(DM)跟踪对话状态并决定如何回答用户。在最后一个阶段,自然语言生成器(NLG)将语义表示转换回人类语言。例如,将 rent_price(Atlanta)=3000 USD 翻译成“亚特兰大的租金价格约为 3000 美元”。下图展示了一个典型的对话系统架构。
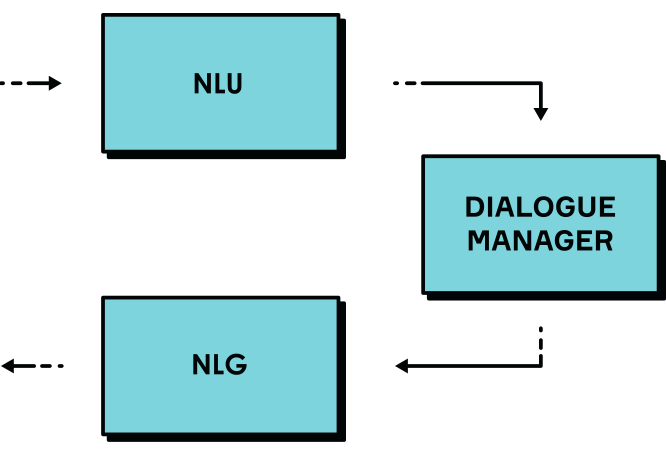
使用 DeepPavlov 构建对话系统
开源对话 AI 框架DeepPavlov为构建对话系统提供了一个免费且易于使用的解决方案。DeepPavlov 附带了几个预定义的组件,用于解决 NLP 相关的问题。你可以使用该框架训练和测试模型,以及微调超参数。它支持 Linux 和 Windows 平台、Python 3.6 和 Python 3.7。你可以运行以下命令安装 DeepPavlov:
DeepPavlov 模型在 config 文件夹下单独的配置文件中定义。配置文件由五个主要部分组成:dataset_reader、dataset_iterator、chainer、train 和 metadata。dataset_reader 定义数据集的位置和格式。加载完成后,根据 dataset_iterator 设置,该数据会被划分为训练集、验证集和测试集。配置文件的 chainer 部分又包含三个子部分。in 和 out 部分定义 chainer 的输入和输出,而 pipe 部分定义与模型交互所需组件的管道。metadata 部分描述了模型需求和模型变量。
你可以通过命令行接口(CLI)与配置文件中定义的模型交互。但是,在使用任何模型之前,都应该使用 install 命令运行它,从而安装它的所有必备软件包。模型的依赖关系在配置文件的需求部分中定义。
其中,<config_path>是所选模型配置文件的路径。
以交互模式通过 CLI 获取模型预测,请执行以下命令:
其中,-d 表示下载所需的数据,如预训练的模型文件和词嵌入。
你可以在执行命令时使用 train 参数来训练模型。模型训练将使用配置文件的 dataset_reader 部分定义的数据集。
DeepPavlov 框架允许你在自己的数据上测试所有可用的模型,然后选出效果最好的一个。要测试模型,请在配置文件的 dataset_iterator 部分指定数据集划分以及划分字段。
此外,你可以在执行 DeepPavlov 时使用 riseapi 命令启动一个允许通过 API 访问模型的服务器:
要了解更多运行操作,请查阅文档。
一个不可或缺的工具
TensorFlow是一个端到端的开源机器学习平台。TensorFlow 是开发 DeepPavlov 时不可或缺的工具。
从 TensorFlow 1.4.0 开始,Keras 一直是核心 API[https://github.com/tensorflow/tensorflow/releases/tag/v1.4.0]的一部分。Keras 是一个高级 API,它降低了入手深度学习的门槛。Keras 在 TensorFlow 之上提供了一个高级抽象层,因此我们可以更多地关注问题和超参数调优。DeepPavlov 的大多数文本分类模型都是通过 Keras 抽象实现的。Keras 为我们提供了快速原型技术,让我们可以快速尝试各种神经网络架构及调优超参数。
此外,TensorFlow 的灵活性使我们可以构建出任何我们能想到的神经网络架构,包括但不限于序列标记和问答系统。具体来说,我们使用 TensorFlow 与基于 BERT 的模型进行无缝集成。我们已经针对文本分类、命名实体识别和问答系统实现了基于 BERT 的英语和多语言模型(更多信息将在接下来的部分中介绍)。此外,TensorFlow 的灵活性使我们能够基于我们的数据构建 BERT;这就是我们使用会话数据训练 BERT 从而在社交网络输入上获得更好性能的方法。
TensorFlow 的另一个优势是 TensorBoard。你可以使用 TensorBoard 来可视化你的 TensorFlow 图,绘制数据记录,并显示额外的数据。TensorBoard 允许我们在调试模型时检查模型并做出适当的更改。这有助于我们更好地理解机器学习模型。
DeepPavlov 显成效
DeepPavlov提供了几个预定义的组件。这些组件基于 TensorFlow 和 Keras,用于解决 NLP 相关问题,包括文本分类、命名实体识别、问答系统等。目前,许多任务都是通过应用基于 BERT 的模型得到了最高水准的结果。BERT(Bidirectional Encoder Representations from Transformers)[研究论文]的发布使 2018 年成为自然语言处理社区的转折点。BERT 是一种基于转换器的预训练语言表示技术。我们将 BERT 集成到三个下游任务中:文本分类、命名实体识别(通常是序列标记)和回答系统。因此,我们在所有这些任务中都取得了实质性的进展。在接下来的部分中,我将详细描述如何使用基于 BERT 的 DeepPavlov 模型。代码可以在谷歌Colab上找到。
文本分类 BERT
我们将使用侮辱检测问题来演示基于DeepPavlov的文本分类 BERT 模型。它涉及到预测在公开讨论中发表的评论是否被认为是对其中某个参与者的侮辱。这是一个只有两个类别的二元分类问题:侮辱和非侮辱。
任何预训练的模型都可以通过命令行接口(CLI)和 Python 用于推理。在使用该模型前,请务必使用以下命令安装所有必要的软件包:
你可以通过 Python 代码与模型交互。
你可以在自己的数据上训练基于 BERT 的文本分类模型。为此,你需要修改配置文件 dataset_reader 部分中的 data_path 参数。
然后在 CLI 中训练模型:
或通过 Python:
要了解更多关于文本分类 BERT 模型的信息,请点击这里,你也可以在我们的演示程序中测试它们。
命名实体识别 BERT
除了文本分类模型,DeepPavlov 还包含用于命名实体识别(NER)的 BERT 模型。这是 NLP 中最常见的任务之一,可以这样表述:给定一个符号序列(单词,可能还有标点符号),为序列中的每个符号提供一个来自预定义标签集的标签。NER 具有多种业务应用。例如,它可以从简历中提取重要信息,方便人力资源专员对其进行评估。此外,NER 还可以用于识别客户请求中的相关实体,如产品规格、公司名称或公司分支机构的详细信息。
我们使用 OntoNotes 英语语料库训练了 NER 模型,该语料库有 19 种标记模式,包括 PER (person)、LOC(location)、ORG(organization)等。为了与模型交互,首先安装它的必备软件包。
此外,你还可以通过 Python 代码与模型交互。
多语言 BERT(M-BERT)模型支持语言之间的零距离转换,这意味着你可以使用非英语句子测试该模型,即使它是使用英语语料库 OntoNotes 训练的:
你可以从我们的[演示程序]获取 NER 模型:
https://demo.deeppavlov.ai/#/mu/ner?utm_source=medium&utm_medium=article&utm_campaign=tf
问答系统 BERT
基于上下文的问答系统是在给定的上下文中(例如,Wikipedia 中的一个段落)找到问题的答案,其中每个问题的答案都是上下文的一部分。例如,下面的上下文、问题和答案就构成了一个基于上下文的问答任务的三元组。
上下文:
*在气象学中,降水是大气中的水蒸气在重力作用下凝结而成的。降水的主要形式有小雨、大雨、雨夹雪、雪、霰和冰雹。当较小的水滴在云中与其他雨滴或冰晶碰撞而结合时,就形成了降水。地点分散的短时强降雨称为“阵雨”。
问题:
*水滴在哪里与冰晶碰撞形成降水?
答案:
*在云中。
问答系统可以使你业务中的许多流程自动化。例如,它可以帮助你的雇主根据公司内部文件得到答案。此外,在辅导学生时,它可以帮助你检查学生的阅读理解能力。近年来,基于上下文的问答任务引起了学术界的广泛关注。该领域的一个重要里程碑是斯坦福问答数据集(SQuAD)的发布。这是一个新的阅读理解数据集,其中包含众包工作者针对维基百科上的一系列文章提出的问题。SQuAD 数据集为解决问答问题提供了无数的方法。其中最成功的是基于 BERT 的问答模型。该模型的性能优于其他所有模型,并且目前的效果已接近于人类的水平。
要在 DeepPavlov 中使用基于 BERT 的 QA 模型,首先要安装必备软件包:
然后可以像下面这样与模型交互:
此外,你还可以在 Python 代码中使用模型:
多语言 BERT 模型仅在英语 SQuAD 数据集上进行训练就可以构建多语言 QA 系统。多语言 QA 支持用于训练 M-BERT 的104种语言。你可以这样使用它:
如你所见,我们在调用模型时提供了成批的上下文和成批的问题,作为输出,该模型将批量返回从上下文中提取的用起始位置表示的结果。这段代码演示了多语言 QA 模型,虽然只在英语数据集上进行了训练,但它能够从法语上下文中提取答案,即使问题是用另一种语言提出的。
关于多语言 QA 模型的跨语言可转换性(transferability )的详细比较,这里有一篇专门的[文章]:
小 结
我们希望本文对你有所帮助,并将 DeepPavlov 用于你自己的自然语言用例。要了解更多关于我们的信息,请访问我们的官方博客:https://medium.com/deeppavlov
另外,你可以随意使用我们的演示程序测试我们基于 BERT 的模型。不要忘了,DeepPavlov 有一个专门的论坛,那里欢迎关于框架和模型的任何问题:https://forum.deeppavlov.ai/
原文链接:

暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论 1 条评论