

基于用户画像进行广告投放,是优化投放效果、实现精准营销的基础;而人口属性中的性别、年龄等标签,又是用户画像中的基础信息。那该如何尽量准确的为数据打上这些标签?
这时候机器学习就派上用场了。 本文将以性别标签为例,介绍人口属性标签预测的机器学习模型构建与优化。
性别标签预测流程
通常情况下,无监督学习不仅很难学习到有用信息,而且对于学习到的效果较难评估。所以,如果可以,我们会尽可能地把问题转化成有监督学习。
对于性别标签也是如此,我们可以使用可信的性别样本数据,加上从 TalkingData 收集的原始数据中提取出来的有用信息,将性别标签的生产任务转化成有监督机器学习任务。更具体来说,男/女分别作为 1/0 标签(Label,也就是常说的 Y 值,为了方便表达,我们标记男/女分别为 1/0 标签),这样性别标签的任务就转化成了二分类任务。
性别标签的生产流程图如下:
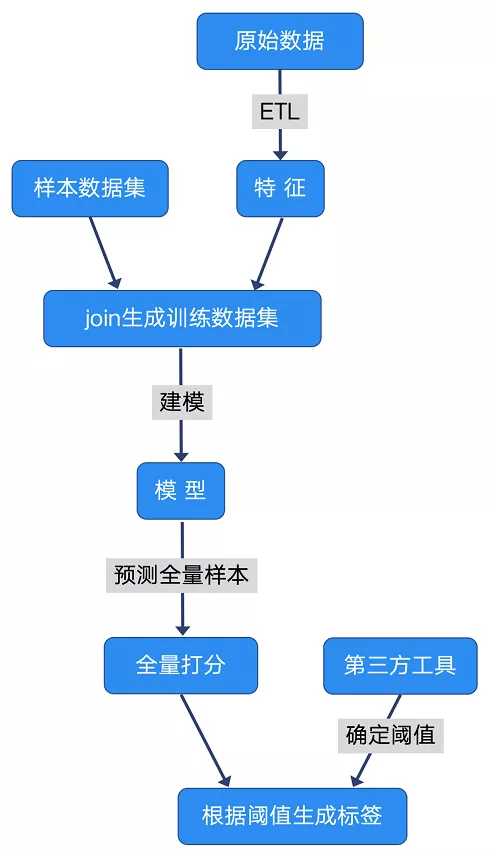
简单来说,输入为具有可信性别信息的样本数据,以及从近期活跃的原始数据中提取出有用特征;
将两者 join 之后,得到可以直接用于建模的数据集;
基于该数据集进行建模,学习出性别预测模型;
再用该模型对全部样本进行预测,从而得到所有样本的性别打分。至此,模型部分的工作基本完成;
最后一步是确定阈值,输出男/女标签。这里我们不依赖模型确定阈值,而是借助比较可信的第三方工具,保证在期望准确度(precision)下,召回尽可能多的样本。
另外,面对 TalkingData 十几亿的数据体量,在标签生产的过程中,为了加速运算,除了必须用单机的情况下,我们都会优先采用 Spark 分布式来加速运算。
特征与模型方法的版本迭代
为了优化模型的效果,我们又对该性别标签预测模型进行了多次迭代。
01 性别预测模型 V1
模型最初使用的特征包括 4 个维度: 设备应用信息、嵌入 SDK 的应用包名、嵌入 SDK 的应用内自定义事件日志以及设备机型信息。
模型采用 Xgboost (版本为 0.5),基于每个维度的特征分别训练模型,得到 4 个子模型。每个子模型会输出基于该特征维度的设备男/女倾向的打分,分值区间从 0 到 1,分值高代表设备为男性倾向,反之则为女性倾向。模型代码示例如下:
缺点及优化方向:
模型为四个子模型的融合,结构较复杂,运行效率较低,考虑改为使用单一模型;
嵌入 SDK 的应用内自定义事件日志特征覆盖率低,且 ETL 处理资源消耗大,需重新评估该字段对模型的贡献程度;
发现设备名称字段看上去有男/女区分度——部分用户群体会以名字或者昵称命名设备名(例如带有“哥”“军”等字段的倾向为男性,带有“妹”“兰” 等字段的倾向为女性),验证效果并考虑是否加入该字段。
02 性别预测模型 V2
对模型使用特征的 4 个维度进行了调整 ,改为:嵌入 SDK 的应用包名、嵌入 SDK 的应用 AppKey、设备机型信息以及设备名称。
其中,对嵌入 SDK 的应用包名和设备名称做分词处理。再使用 CountVectorizer 将以上 4 类特征处理成稀疏向量(Vector),同时用 ChiSqSelector 进行特征筛选。
模型采用 LR (Logistic Regression),代码示例如下:
优点及提升效果:
采用单一的模型,能够用常见的模型评估指标(比如 ROC-AUC, Precision-Recall 等)衡量模型,并在后续的版本迭代中作为 baseline,方便从模型角度进行版本提升的比较。
缺点及优化方向:
LR 模型较简单,学习能力有限,后续还是替换成更强大的模型,比如 Xgboost 模型。
03 性别预测模型 V3
模型所使用的特征,除了上个版本包括的 4 个维度:嵌入 SDK 的应用包名、嵌入 SDK 的应用 AppKey、设备机型信息以及设备名称, 又增加了近期的聚合后的设备应用信息 ,处理方式与上个版本类似,不再赘述。
模型从 LR 更换成 Xgboost (版本为 0.82),代码示例如下:
优点及提升效果:
相比上个版本, AUC 提升了 6.5%,在最终的性别标签生产中召回率提升了 26% 。考虑到 TalkingData 的十几亿的数据体量,这个数值还是很可观的。
04 性别预测模型 V4
除了上个版本包括的 5 个特征维度,还 添加了 TalkingData 自有的三个广告类别维度的特征 ,虽然广告类别特征覆盖率仅占 20%,但对最终标签的召回率的提升也有着很大的影响。
模型由 Xgboost 替换成 DNN ,设置最大训练轮数(Epoch)为 40,同时设置了 early stopping 参数。考虑到神经网络能工作是基于大数据的,因此我们将用于训练的样本量扩充了一倍,保证神经网络的学习。
DNN 的结构如下:
优点及提升效果:
与上个版本对比, AUC 仅提升了 1.5%,但在最终性别标签生产中的召回率提升了 13% ,考虑数据体量以及现有的标签体量,这个提升还是不错的。
由此可以看出,在验证版本迭代效果的时候,我们 不应该仅仅从模型的 AUC 这单一指标来衡量 ,因为这对版本迭代的效果提升程度衡量不够准确。我们应该验证最终的、真正的指标提升情况——在性别标签预测中, 是期望准确度(precision)下召回的样本数量 。但我们仍然可以在版本优化时使用 AUC 等模型相关指标,来快速验证控制变量的实验效果,毕竟这些指标容易计算。
模型探索小建议
从原始日志当中抽取字段聚合成信息,需要经过很多步 ETL,也会涉及很多优化方式,这部分有专门的 ETL 团队负责,在这里不做过多介绍。
模型团队可以直接使用按时间聚合之后的字段进行建模任务,尽管如此,ETL 和特征生成所花费的时间,也占据了模型优化和迭代的大部分时间。
下面总结两个优化方面的坑和解决经验,希望能给大家一些参考。
01
对于性别标签预测,输入的特征大部分为 Array 类型,比如近期采集到的设备应用信息。对于这种类型的字段,在训练模型之前,我们一般会调用 CountVectorizer 将 Array 转成 Vector,然后再作为模型的输入,但是 CountVectorizer 这一步非常耗时,这导致我们在版本迭代时不能快速实验。
针对该问题,我们 可以事先完成这一步转换,然后将生成的 Vector 列也存储下来 ,这样在每次实验时,就可以节省 CountVectorizer 消耗的时间。
在实际生产中,因为有很多标签的生产都会用到同样的字段,事先将 Array 转成 Vector 存储下来,后续不同任务即可直接调用 Vector 列,节省了很多时间。
02
虽然第一条能够节省不少时间,但 Spark 还是更多用于生产。其实在模型前期的探索当中,我们也 可以先用 Spark 生成训练集 ——因为真实样本通常不会很多,生成的训练集往往不是很大,这时我们就可以用单机来进行快速实验了。
在单机上,我们可以使用 Python 更方便的画图来更直观的认识数据,更快的进行特征筛选,更快的验证想法。在对数据、对模型有了深入的了解之后,我们就可以把实验所得的结论快速应用到生产当中。
作者介绍:
张小艳,TalkingData 数据科学家,目前负责企业级用户画像平台的搭建以及高效营销投放算法的研发,长期关注互联网广告、用户画像、欺诈检测等领域。
本文转载自公众号 TalkingData(ID:Talkingdata)。
原文链接:
https://mp.weixin.qq.com/s/-6FEBPsVyAhnPThbQsSK2g

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论