

提供大规模的模型服务只是战斗的一部分。一般来说,你还需要能够解释和预测。Seldon 的团队了解处理许多模型并在生产中提供模型服务的挑战。然而,确保用户理解为什么会做出这些预测则完全是另外一项挑战。
本文最初发布于 Distributed Computing with Ray 博客,经授权由 InfoQ 中文站翻译并分享。
提供大规模的模型服务只是战斗的一部分。一般来说,你还需要能够解释和预测。Seldon的团队了解处理许多模型并在生产中提供模型服务的挑战。然而,确保用户理解为什么会做出这些预测则完全是另外一项挑战。
出于这个原因,Seldon 推出了Alibi库。Alibi是一个用于ML模型观测和解释的开源Python库。它允许用户在他们的数据上运行流行的模型解释算法,如 Kernel SHAP。
不过,尽管 Alibi 有许多算法,但用户往往寻求更好的性能和可扩展性。Seldon 团队开始接触Ray,这是一个开源框架,为构建分布式应用程序提供了一个简单的通用 API,为了寻找扩展 Alibi 的解决方案,我们希望使用Kernel SHAP算法测试下 Ray 的表现。
下面是测试结果预览。简而言之,Seldon 团队能够通过利用Ray Core实现 Kernel SHAPm 的线性扩展,而且只需几百行代码。
本文将回顾这些结果,并讨论团队是如何实现 Distributed Kernel SHAP 的。感兴趣的读者可以从GitHub存储库获取完整的代码和结果。
线性扩展使得有效的计算扩展变得简单!
让我们更深入地探讨下 Alibi、Kernel SHAP、Seldon 如何分发 Kernel SHAP 以及达到的效果。
Alibi 是什么?
Alibi是一个 Python 包,旨在帮助解释机器学习模型的预测结果,并衡量预测的可靠程度。这个库的重点是使用黑箱方法支持最广泛的模型。目前,Alibi提供了8种不同的算法解释模型,包括流行的算法,如 Anchors、Counterfactuals、Integrated Gradients、Kernel SHAP 和 Tree SHAP。
最近,Seldon 团队开展了一个项目,他们需要能够将可解释性计算扩展到大量的 CPU 上。这是必要的,因为黑箱方法对预测函数进行事后建模,而且速度很慢,这使得在单个 CPU 上解释大量实例的任务成本非常高。
Seldon 团队认为,他们可以探索使用更大的机器,但他们的许多客户使用的是分布式环境,因此,需要可持续扩展的解决方案——超出一台机器的范围。
他们联系了 Ray 团队,询问他们会如何扩展这个工作负载。只要一点点工作量,Seldon 团队就能够在短短几天内实现 Kernel SHAP 的扩展。
Kernel SHAP 背景知识
正如在文档中提到的,Kernel SHAP 提供了与模型无关的(黑盒)、人类可解释的说明,适合应用于表格数据的回归和分类模型。该方法是可加特征归因方法的一员;特征归因是指结果解释(例如,分类问题中的类别概率)相对于基线(例如,训练集中那个类的平均预测概率)的变化可以归结为不同比例的模型输入特征。
图 1 显示了一个简单的解释过程。我们看到,该图描述了一个模型,它将年龄、BMI 或性别作为输入特征,并输出一个连续的值。我们知道,在我们感兴趣的数据集中,输出的平均值是 0.1。使用 Kernel SHAP 算法,我们将 0.3 的差异归因于输入特征。因为属性值的和等于输出 base rate,所以这个方法是可加的。
例如,我们可以看到,性别特征对预测的作用是消极的,而其他特征对预测的作用是积极的。为了解释这一特定数据点,年龄特征似乎是最重要的。请参阅我们的示例,了解如何使用该算法进行解释,以及使用 SHAP 库来可视化结果(这里,这里和这里)。

图 1:使用 Kernel SHAP 的黑盒解释模型(来自这里)
挑战:利用 Kernel SHAP 进行总体解释
如上所述,Kernel SHAP 是一种解释表格数据的黑盒模型的方法。然而,计算这些解释非常昂贵,所以在一个 CPU 或一台机器上解释许多模型预测以获得模型行为的全局视图非常具有挑战性,因为它需要解释大量的预测。但是,由于预测是独立的,所以可以并行化解释每个预测的计算,在一个高效的分布式计算框架下,这本身就可以节省大量的时间。这就是 Ray 的作用。
Seldon 团队之所以选择Ray,是因为它具有简单的API、支持Kubernetes的分布式集群启动程序以及强大的社区。
在短短几天内,团队就能从概念到原型。
解决方案
Seldon 团队构建的解决方案有两个架构变体。其核心架构很简单,他们创建了一个工作进程池,然后将计算函数传递给它们进行并行化然后执行。但是,这个池的创建有两种方法。
一种方法使用一个 Ray Actor 池,它消费待解释的 2560 个模型预测的小子集。另一种方法使用 Ray Serve 而不是并行池,我们将工作作为批处理任务提交给 Ray Serve。这两种方法的代码都已在GitHub存储库中提供,并且二者的性能结果类似。
单节点结果
实验在 Digital Ocean 上一台经过计算优化的专用机器上运行,该机器有 32 个 vCPU。这也解释了下面的性能增益衰减。
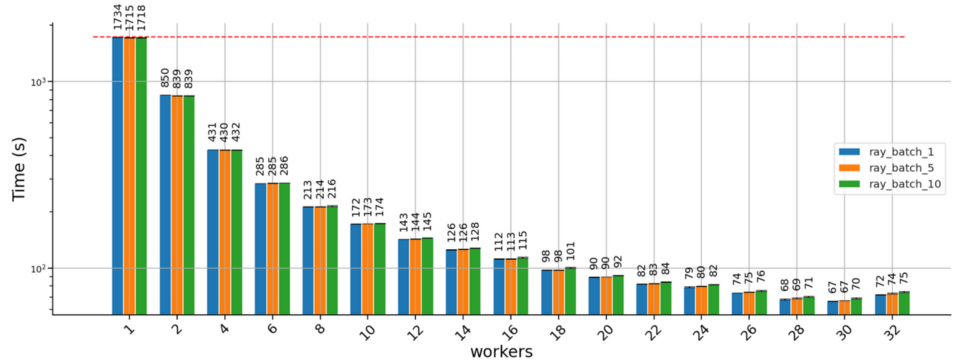
使用 Ray 并行池运行任务得到的结果如下:
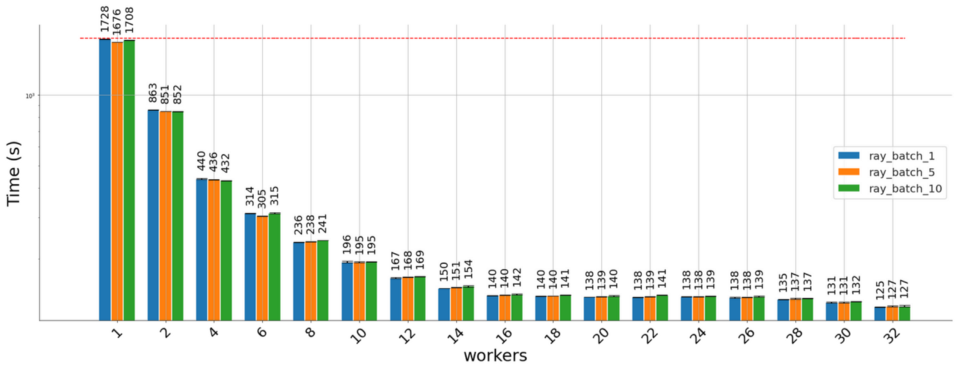
使用Ray Serve分发产生了类似的结果:
分布式结果
Kubernetes 集群
实验在一个集群上运行,该集群由 Digital Ocean 中两台经过计算优化的专用机器组成,每台机器有 32 个 vCPU。这也解释了下面的性能增益衰减。
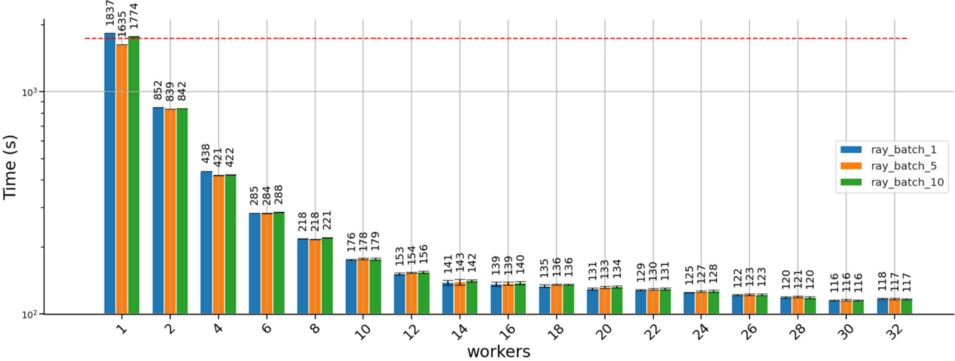
在两节点集群上使用 Ray 并行池运行任务的结果如下所示:
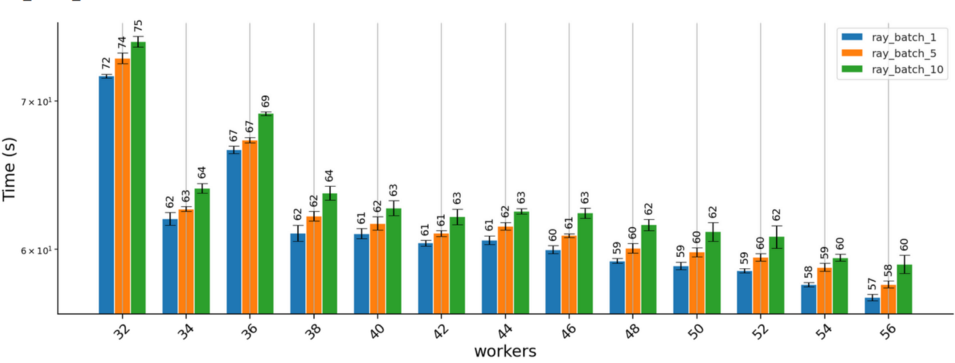
使用Ray Serve分发产生了类似的结果:
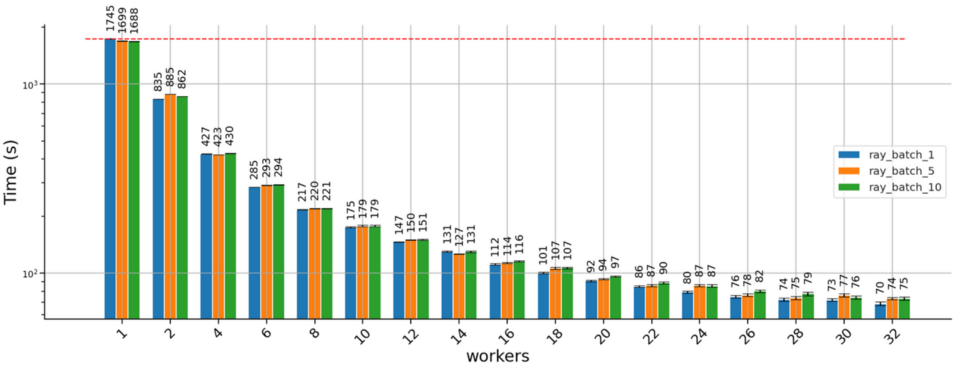
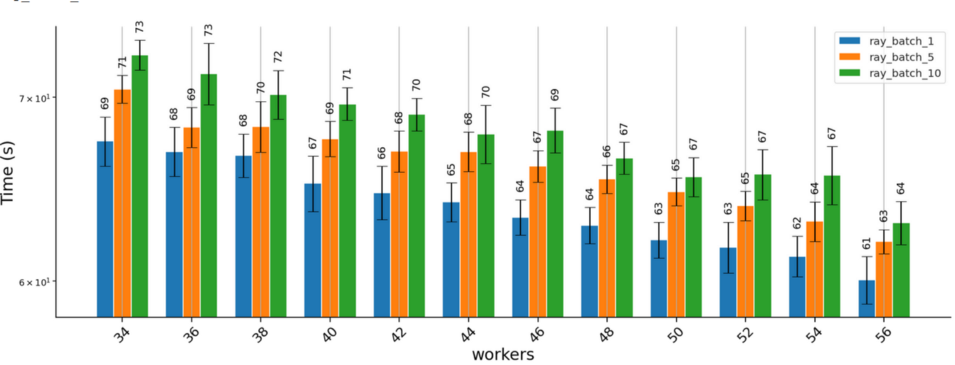
该团队实验了不同的批次大小。批次大小控制同时将多少预测发送给一个工作进程。这样做的主要目的是,确保每个解释任务的运行时间大于分配任务的开销;解释器无法从处理批次中获益,因为每个实例的解释都独立于批次中的其他实例。团队并没有详细分析为什么批次大小较大会导致运行时间略有下降,我们怀疑,分配的解释任务较少,就需要更长的运行时间,可能是因为资源利用效率低(例如,在快结束的时候,有一些任务在运行,但一些工作进程闲置)。
Seldon 和 Ray 未来展望
Seldon 和 Ray 是绝佳的组合。这篇文章展示了在 Ray 上并行化给定的工作负载是多么容易,未来,我们希望可以分享如何将这些工具一起用于从模型训练到提供服务的所有事情。
关于 Ray
Ray 是一个简单、通用的分布式计算框架。Ray 项目最初由加州大学伯克利分校 RISELab 实验室发起并开源。在过去几年中,Ray 项目发展迅速,在蚂蚁集团、Intel、微软、AWS 等公司被应用于构建各种 AI、大数据系统。
Ray 提供了简单、通用的分布式 API(Python/Java),便于快速构建分布式应用程序。在机器学习领域,封装了以下框架,来提升整体研发效率:
Tune:可伸缩的超参数调优框架
RLib:可扩展的强化学习框架
RaySGD:分布式训练器
Ray Serve:可扩展可编程的分布式服务
Ray 官网地址:https://ray.io/
Ray Github 地址:https://github.com/ray-project/ray
Ray 中文官方公众号:微信搜索“Ray 中文社区”或“raycommunity”
英文原文链接:
Scaling Seldon’s Alibi with Ray — Making Model Explainability Easy and Scalable

InfoQ高级编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 1 条评论