FATE(Federated AI Technology Enabler)是联邦机器学习技术的一个框架,其旨在提供安全的计算框架来支持联邦 AI 生态。FATE 实现了基于同态加密和多方计算(MPC)的安全计算协议,它支持联邦学习架构和各种机器学习算法的安全计算,包括逻辑回归、基于树的算法、深度学习和转移学习。
联邦机器学习又名联邦学习、联合学习与联盟学习,它能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模,消除由于行业竞争、隐私安全与行政手续等问题带来的数据孤岛,让以数据为基础的机器学习顺利进行。
KubeFATE 支持通过 Docker Compose 和 Kubernetes 进行 FATE 部署。我们建议使用 Docker Compose 安装快速开发和学习 FATE 集群,同时使用 Kubernetes 安装生产环境。
深度神经网络(DNN)是在输入和输出层之间具有多层的人工神经网络(ANN)。
本文以经典的神经网络 MNIST 为例子,展示联邦学习版的深度神经网络训练过程。我们使用 KubeFATE 快速进行 FATE 框架的部署。因为模拟联邦学习的双方,我们需要准备两台 Ubuntu 的机器(物理机或虚拟机)。
1、安装 docker 和 docker-compose
Ubuntu 安装 docker:
$ sudo apt-get update$ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -$ sudo apt-get update$ sudo apt-get install docker-ce docker-ce-cli containerd.io
复制代码
安装 docker-compose:
$ sudo curl -L https://github.com/docker/compose/releases/download/1.23.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose$ sudo chmod +x /usr/local/bin/docker-compose
复制代码
2、安装 KubeFATE
学习环境推荐使用 Docker 方式部署。使用 Docker 方式部署分为两步,先根据 parties.conf 配置文件生成 docker-compose 文件。通过 scp 把 docker-compose 文件复制到目标机器上,然后通过 ssh 命令登录到目标机器并运“docker-compose up”。
选择两台机器其中之一作为部署机。
1.在 KubeFATE 的 release 页面下载软件包 kubefate-docker-compose.tar.gz 并解压:
$ wget https://github.com/FederatedAI/KubeFATE/releases/download/v1.3.0-a/kubefate-docker-compose.tar.gz$ tar xzf kubefate-docker-compose.tar.gz
复制代码
2.进入 docker-deploy/ 目录,修改 parties.conf 文件:
$ cd docker-deploy$ vi parties.conf
复制代码
parties.conf:
user=rootdir=/data/projects/fatepartylist=(10000 9999)partyiplist=(10.160.175.20 10.160.162.5)servingiplist=(10.160.175.20 10.160.162.5)exchangeip=
复制代码
说明:
user:两台目标机器的用户 id,建议用户 root 或权限合适的用户。
dir:目标机器上存放 docker-compose 文件的目录。
partylist:FATE 集群的 party 列表。这里是两方,用数字表示。
partyiplist:FATE 训练集群的 IP 地址,与 partylist 对应,例如上例 id 为 10000 的训练集群 ip 地址是 10.160.175.20。注意这里要替换成你准备的两台机器对应的 IP。
servingiplist:FATE 在线推理集群的 IP 地址,与 partylist 对应,可以和训练集群在一台机器上,也可以单独是一台机器。本文里训练集群和在线推理集群使用同一台机器。
exchangeip:多于两方部署的时候推荐使用 exchange 模式。Exchange 是一个集中交换数据的节点,记录了所有 party 的 IP 地址,每个 party 只需要知道 exchange 节点的 IP 地址就可交换数据。本文是两方直连,所有不填写 exchange。
3.生成部署 FATE 的 docker-compose 文件
$ bash generate_config.sh
复制代码
命令会在 outputs 文件夹下面生成对应的压缩包:confs-.tar 和 serving-.tar。
4.部署 FATE
$ bash docker_deploy.sh all
复制代码
因为用到了 scp 和 ssh 命令,所以运行这条命令的时候需要输入密码。为了方便可以在部署机和目标机之间做免密码处理。
两台机器在互联网可用环境下,Docker 会自动下载 FATE 需要的镜像。如果是没有互联网的环境,参考 Github 上使用离线镜像文章。
5.免密处理(可选)
用 10.160.175.20 作为部署机,需要可以免密码登录本机和 10.160.162.5 (目标机)。
生成 ssh key:
一直回车即可,会在~/.ssh/目录下生成一个 id_rsa.pub 文件。分别在两个机器的~/.ssh/目录下新建一个 authorized_keys 文件,并把刚刚生成 id_rsa.pub 的内容填写进去。
6.验证是否部署成功。分别登录两台机器运行以下命令来验证:
$ docker ps
CONTAINER ID IMAGE ...11e86440c02d redis:5 ...16570fa47d36 federatedai/serving-server:1.2.2-release ...b64b251e9515 federatedai/serving-proxy:1.2.2-release ...75603d077a94 federatedai/fateboard:1.3.0-release ...38cb63178b79 federatedai/python:1.3.0-release ...80876768cd35 federatedai/roll:1.3.0-release ...955bab0ae542 federatedai/meta-service:1.3.0-release ...89928bf28b37 federatedai/egg:1.3.0-release ...63e4ae852d0d mysql:8 ...3cc1a4709765 federatedai/proxy:1.3.0-release ...0e1d945b852c federatedai/federation:1.3.0-release ...f51e2e77af88 redis:5 ...
复制代码
3、准备数据集
本文使用 MNIST 数据集,MNIST 是手写数字识别的数据集。从 kaggle 下载 csv 格式的数据集。
FATE 训练时需要数据集有 id,MNIST 数据集里有 6w 条数据,模拟横向 l 联邦学习,把数据集分为两个各有 3w 条记录的数据集。
$ awk -F'\t' -v OFS=',' ' NR == 1 {print "id",$0; next} {print (NR-1),$0}' mnist_train.csv > mnist_train_with_id.csv
复制代码
这句话是在第一行最前面加上 id,第二行开始加序号,并用逗号作为分隔符。
$ sed -i "s/label/y/g" mnist_train_with_id.csv
复制代码
将表头的 label 替换成 y,在 FATE 里 label 的名字通常为 y。
$ split -l 30001 mnist_train_with_id.csv mnist_train_3w.csv
复制代码
将 mnist_train_with_id.csv 分割,每一个文件有 30001 行(一行标题和 30000 行数据)。会生成两个文件:mnist_train_3w.csvaa 和 mnist_train_3w.csvab。将两个文件重命名:
$ mv mnist_train_3w.csvaa mnist_train_3w_a.csv$ mv mnist_train_3w.csvab mnist_train_3w_b.csv$ sed -i "`cat -n mnist_train_3w_a.csv |head -n 1`" mnist_train_3w_b.csv
复制代码
将 mnist_train_3w_a.csv 文件的第一行(csv 的表头)插入 mnist_train_3w_b.csv 的最前面。这样我们就得到了两个有表头和 id 的数据集,各有 30000 条数据。
分别将两个文件拷贝到两台机器上的/data/projects/fate/confs-/shared_dir/examples/data 目录里。
Shared_dir 目录是本地文件系统和 docker 容器中文件系统的共享目录,使容器可以访问宿主机的文件。
4、准备 FATE Pipeline
本文在 FATE 里使用 Keras 运行 DNN,参考文章。
1.1 准备 Keras 模型
进入 guest 方(本文选用 9999 作为 guest)的 python 容器:
$ docker exec -it confs-9999_python_1 bash
复制代码
进入 Python 解释器:
构建一个 Keras 模型:
>>>import keras>>>from keras.models import Sequential>>>from keras.layers import Dense, Dropout, Flatten>>>model = Sequential()>>>model.add(Dense(512,activation='relu',input_shape=(784,)))>>>model.add(Dense(256,activation='relu'))>>>model.add(Dense(10,activation='softmax'))
复制代码
得到 json 格式的模型:
>>>json = model.to_json()>>>print(json)
{"class_name": "Sequential", "config": {"name": "sequential_1", "layers": [{"class_name": "Dense", "config": {"name": "dense_1", "trainable": true, "batch_input_shape": [null, 784], "dtype": "float32", "units": 512, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_2", "trainable": true, "units": 256, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_3", "trainable": true, "units": 10, "activation": "softmax", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}]}, "keras_version": "2.2.4", "backend": "tensorflow"}
复制代码
1.2 修改 test_homo_nn_keras_temperate.json
vi examples/federatedml-1.x-examples/homo_nn/test_homo_nn_keras_temperate.json
复制代码
将刚刚输出的 json 格式的模型替换到 algorithm_parameters. homo_nn_0.$nn_define 位置。
将 work_mode 设置为 1,将 guest 设置为 9999,host 和 arbiter 为 10000,将
{ "initiator": { "role": "guest", "party_id": 9999 }, "job_parameters": { "work_mode": 1 }, "role": { "guest": [ 9999 ], "host": [ 10000 ], "arbiter": [ 10000 ] },
复制代码
修改 guest 和 host 数据集的名字和命名空间,role_parameters. guest.args.data. train_data:
"name": "homo_mnist_guest","namespace": "homo_mnist_guest"
复制代码
role_parameters. host.args.data. train_data:
"name": "homo_mnist_host","namespace": "homo_mnist_host"
复制代码
1.3 分别上传 host 方(10000)和 guest 方(9999)数据
新建 upload_data_guest.json
$ vi examples/federatedml-1.x-examples/homo_nn/upload_data_guest.json
{ "file": "examples/data/mnist_train_3w_b.csv", "head": 1, "partition": 10, "work_mode": 1, "table_name": "homo_mnist_guest", "namespace": "homo_mnist_guest"}
复制代码
上传数据到 FATE:
$ python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_nn/upload_data_guest.json
复制代码
登陆到 host(10000)机器的 Python 容器,并对应新建 upload_data_host.json
$ docker exec -it confs-10000_python_1 bash$ vi examples/federatedml-1.x-examples/homo_nn/upload_data_host.json
{ "file": "examples/data/mnist_train_3w_a.csv", "head": 1, "partition": 10, "work_mode": 1, "table_name": "homo_mnist_host", "namespace": "homo_mnist_host"}
复制代码
上传数据到 FATE:
$ python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_nn/upload_data_host.json
复制代码
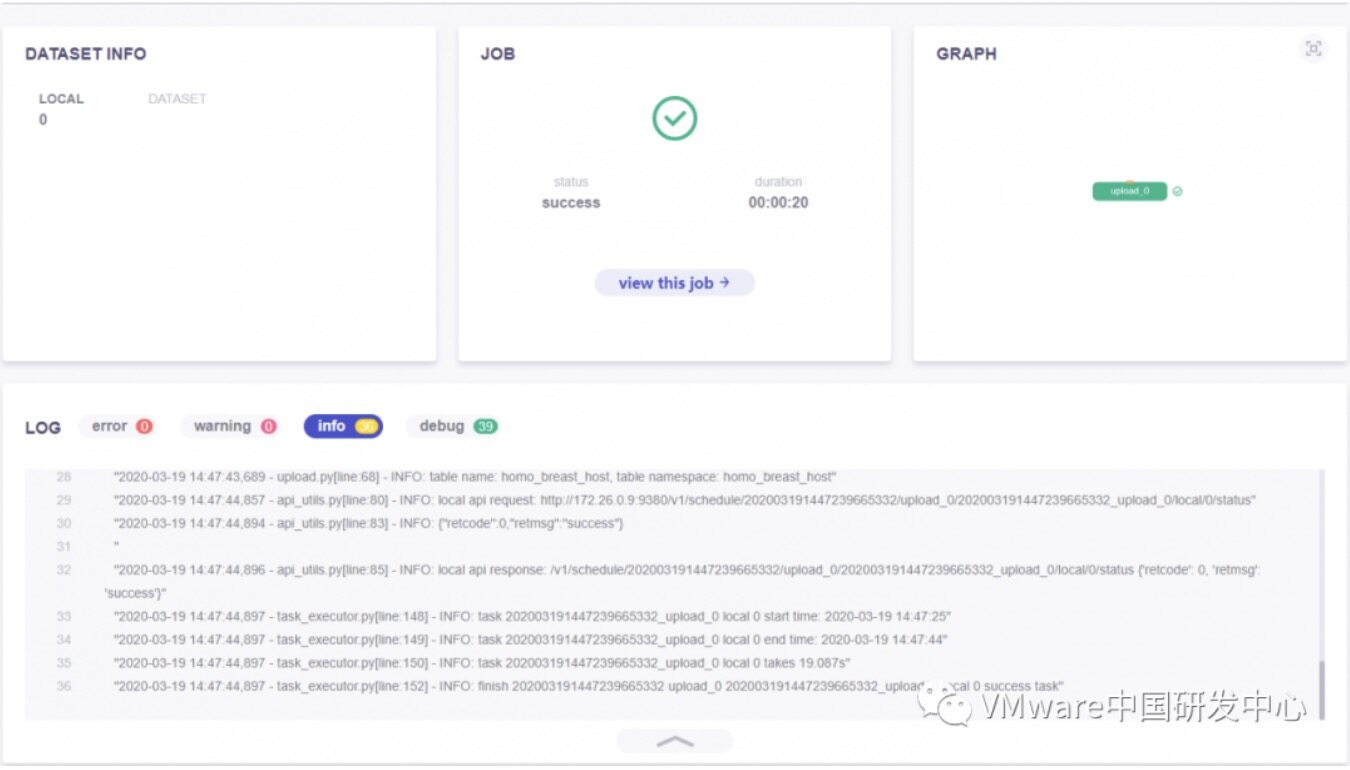
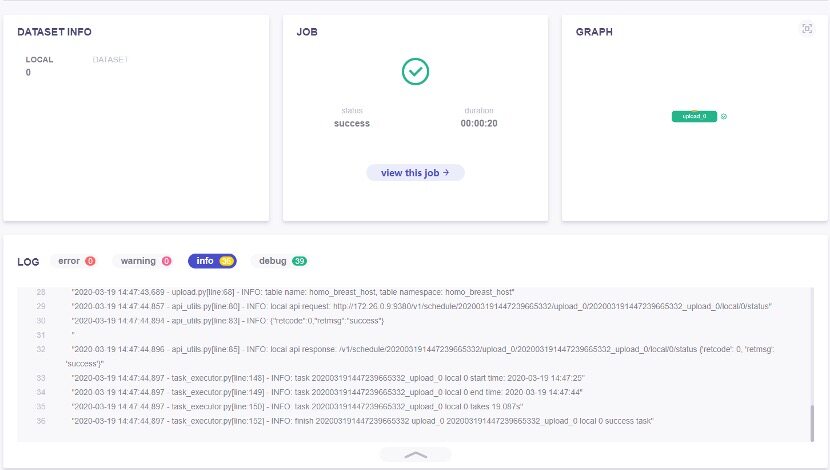
登录到 FateBoard 可以查看上传任务情况,FateBoard 的地址是 http://party-IP:8080,如下图所示为成功:
1.4 用 fate_flow 运行 DNN
FATE 的训练应该由 guest 方发起,所以我们登录到 guest 的 Python 容器:
$ docker exec -it confs-9999_python_1 bash
复制代码
使用 fate_flow 运行 DNN 任务:
$ python fate_flow/fate_flow_client.py -f submit_job -c examples/federatedml-1.x-examples/homo_nn/test_homo_nn_keras_temperate.json -d examples/federatedml-1.x-examples/homo_nn/test_homo_nn_train_then_predict.json
复制代码
得到输出:
{ "data": { "board_url": "http://fateboard:8080/index.html#/dashboard?job_id=202003191510586887818&role=guest&party_id=9999", "job_dsl_path": "/data/projects/fate/python/jobs/202003191510586887818/job_dsl.json", "job_runtime_conf_path": "/data/projects/fate/python/jobs/202003191510586887818/job_runtime_conf.json", "logs_directory": "/data/projects/fate/python/logs/202003191510586887818", "model_info": { "model_id": "arbiter-10000#guest-9999#host-10000#model", "model_version": "202003191510586887818" } }, "jobId": "202003191510586887818", "retcode": 0, "retmsg": "success"}
复制代码
model_id 和 model_version 合起来是确定一个模型的依据,下一步进行预测时候会用到。
登录 fateboard 查看任务,下图为完成训练:
5、使用模型预测
我们用之前训练的 MNIST 数据集来做预测,所以就不用再上传数据了。
$ awk -F'\t' -v OFS=',' ' NR == 1 {print "id",$0; next} {print (NR-1),$0}' mnist_test.csv > mnist_test_with_id.csv$ sed -i "s/label/y/g" mnist_test_with_id.csv
复制代码
1.1 定义预测 pipeline
预测也是由 guest(9999)方发起,新建 test_predict_conf.json
$ vi examples/federatedml-1.x-examples/homo_nn/test_predict_conf.json
{ "initiator": { "role": "guest", "party_id": 9999 }, "job_parameters": { "work_mode": 1, "job_type": "predict", "model_id": "arbiter-10000#guest-9999#host-10000#model", "model_version": "202003191510586887818" }, "role": { "guest": [9999], "host": [10000], "arbiter": [10000] }, "role_parameters": { "guest": { "args": { "data": { "eval_data": [{"name": "homo_mnist_guest", "namespace": "homo_mnist_guest"}] } } }, "host": { "args": { "data": { "eval_data": [{"name": "homo_mnist_host", "namespace": "homo_mnist_host"}] } } } }}
复制代码
job_parameters 里面的 model_id 和 model_version 就是刚刚训练时输出里面的,guest 和 host 的数据的名字和命名空间都和训练时一致。
1.2 进行预测
$ python fate_flow/fate_flow_client.py -f submit_job -c examples/federatedml-1.x-examples/homo_nn/test_predict_conf.json
复制代码
登录 Fateboard 查看是否完成预测。
1.3 下载预测结果
$ python fate_flow/fate_flow_client.py -f component_output_data -j 2020032001133193102117 -p 9999 -r guest -cpn homo_nn_1 -o examples/federatedml-1.x-examples/homo_nn
复制代码
f:fate_flow 的任务种类,component_output_data 是获取模块输出用的。
j:jobID,在刚刚预测时候输出里。
p:partyID,guest 方是 9999。
r:角色,guest。
cpn:模块名称,是训练模型时 pipeline(examples/federatedml-1.x-examples/homo_nn/test_homo_nn_train_then_predict.json)定义的,本次是 homo_nn_1。
o 是下载结果的输出路径。
运行完这条命令之后,会发现 examples/federatedml-1.x-examples/homo_nn/目录下多了一个 job_2020032001133193102117_homo_nn_1_guest_9999_output_data 目录。
查看一下这个目录里面的内容:
ls job_2020032001133193102117_homo_nn_1_guest_9999_output_dataoutput_data.csv output_data_meta.json
复制代码
output_data.csv:预测的结果集。
output_data_meta.json:结果集的元数据,就是结果集表头。
作者介绍:
彭路,VMware 云原生实验室工程师,FATE/KubeFATE 项目贡献者。
















评论 2 条评论