

mesos master 的故障恢复机制
接下来说一下 mesos master 的故障恢复机制。
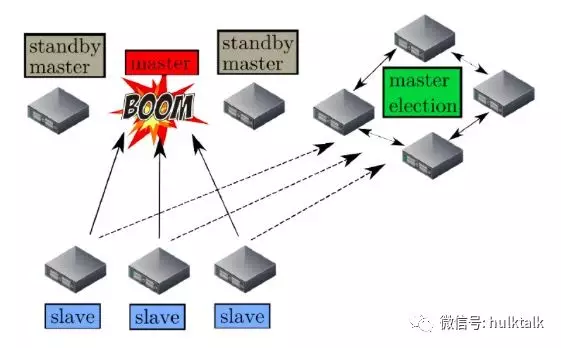
因为 mesos master 只有一个软体状态,只会列出它之上的 framework 以及 mesos-slave 的信息,在 mesos master 需要进行切换的时候,通过 zookeeper 进行 leader 的重新选取,选取好新的 leader 后,只需要所有的 framework 和 mesos-slave 节点重新注册到新的 mesos master 之上,时间就 10 秒钟左右。如有你有上万台机器,可能会同时连 mesos master 会不会造成大量的链接导致 master 服务不可用,官方有这样的设置可以设定链接的比例来进行控制。
mesos 的生态圈有哪些框架
marthon framework
运行长任务。从应用框架字面的意思,任务就像跑长跑一样,这个框架其实就是运行长任务(long running job )的。
服务发现。marathon 还可以实现服务发现,有比较好的 API 接口,比如我有一个 APP id 对应具体机器的 IP 是什么。
健康检测 &事件通知机制。marathon 支持对你所启动的任务进行健康检测,比如端口或者你自定义命令都可以,有事件通知机制,正因为有了事件通知机制才可以在马拉松之上建立一些实时的服务发现,知道哪些服务宕掉了,在哪些新节点启动了,可以保证我们的实时发现服务,重新指向新的服务器。
WebUI。marathon 有自己的 web UI,可以通过界面直接操作,非常方便。
限定条件。你可以设定一大堆的限定条件,比如我之前说的像你选飞机的舱位一样,你设定了网卡必须是万兆的,marathon 会根据你设定的限定条件,帮你选择对应资源。
Labels。labels 标签也是我们常用的,随着资源利用率越来越大,可能有各种应用,大家可以加上各种的标签,方便的查询。
数据持久化。数据持久化也是支持的,可以支持挂载本地卷。
服务的预热。这个功能用得不是特别多,比如你在服务启动的时候会需要启动时间,这个时间健康检测是失败的,你可能需要设定一个预热时间,保证服务启动之后正常的健康检测才生效。
优雅退出。优雅退出这个问题,大家可能都会遇到,比如像 C++不涉及内存自动回收可能需要程序上设计优雅退出的问题,你可以通过 marathon 设置一个退出时间,保证你的服务正常退出之后,才把以前的服务都退掉,新的服务启动。
支持自定义的 containerizer 和 GPU 资源的调度。
Marathon-lb
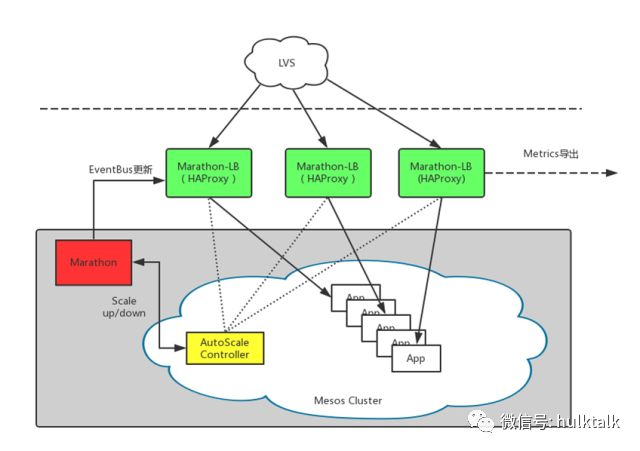
marathon-lb 是我们用的一个实时发现的服务,marathon-lb 是基于 haproxy 和 marathon eventbus 机制设计的。其实除了 mrathon-lb 还有一些其他的服务实时发现,但是都是基于 marathon 的事件通知机制设计的。因为 marathon 有事件总线的实时更新,可以实时的改变服务后端的 IP。如果有宕机或者有服务自动扩缩容的话,marathon-lb 可以实时改变 haproxy 的配置,marathon-lb 主要是通过第四层 IP 加端口的方式进行服务代理,marathon-lb 支持 TCP 或者 HTTP 的代理方式。
Mesos-DNS
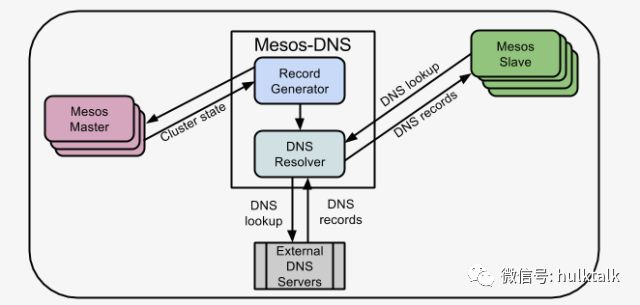
我们还使用了 mesos 官方的 mesos-DNS 服务,用于一些对实时性要求不高的服务,比如我们把 STORM 容器化以后 nimbus 和 supervisor 之间的通信可能就不是那么频繁,如果有 nimbus 宕机的情况,只需要通过 mesos-dns 就可以重新发现 appid 对应的新的 nimbus IP。你可以使用 mesos-DNS 发现 appid 对应的所有后端节点的 IP,可以保证你的服务节点随时都可以访问到你想访问到的 IP。mesos-DNS 有一定的延迟性,我们测试大概有十几秒。
Mesos VS YARN
我说一下在我们做技术选型的时候,我们也做过 mesos 和 yarn 方面的调研。
mesos 主要是能调度各种样的资源,有 CPU,内存、端口、硬盘;yarn 主要是 CPU 和内存。
两者都是两极调度策略但是又有不同。
mesos 本身只做资源的调度,不负责具体任务的调度,把任务调度交给 framework 调度。
yarn 全都是 yarn 本身进行资源调度,一个程序提交给它一个任务都由 yarn 来决定是否接受或者拒绝这个资源,而 mesos 却不同。
mesos 因为是对物理资源进行管理与调度的,yarn 主要基于 hadoop 来做。
根据需要,我们最后还是选择了 mesos 来作我们的分布资源管理框架。
Mesos VS Kubernetes
说起 mesos 可能很多同学觉得使用了 marathon 提供了容器任务的管理能力,可能就需要跟
kubernetes 系统进行比较一下。
本身来讲,mesos 和 kubernetes 是两个东西,mesos 是一个分布式的资源管理框架,被称为分布式系统的内核。假如你有很多物理资源,你想把它整合成一个逻辑资源层面的物理资源池,那么你用 mesos 是最合适不过的了。
mesos 解决问题的核心是如何把资源整合成一个大型的物理资源池,它上面运行什么,怎么跑它并不关注。
kubernetes 主要是一个自动化的容器操作平台,操作主要包括部署、调度还有节点集群间的扩容等等。
kubernetes 解决问题的核心主要是围绕容器来做的,这两个系统本身没有可比性。因为 mesos
支持很多 framework,比如 marathon 可以实现容器的调度,所以大家就会把这两个平台进行比较。
如果你想搭建这样一个容器管理平台或者调度平台,从我个人来讲第一点从任务上来讲,marathon 只支持长任务型的,kubernetes 支持的比较广,比如支持长时间任务(long running job),节点后台支撑型(node-daemon)等等各种各样的任务。
说一下稳定性方面,kubernetes 是谷歌官方推出的,它的更新比较频繁,更新频繁可能带来的就不是特别稳定,大家可能理解我可以多做一些线下测试,但是事实确实是这样的,kubernetes 更新非常频繁。mesos 一般每半年更新一次,一年发布两个版本,会经过充分测试。mesos 产品设计因为是开源的,是 Apache 基金会下面的顶级项目,会在社区跟大家进行投票与沟通,决定未来我们的产品怎么做,我们会增加哪些功能。
第三种主要是从功能上来讲,kubernetes 是由谷歌做的,所以它的考虑会非常全面,它的生态非常全面,你想要的功能基本都有,包括网络 kubernetes 其实也是有的,其实 kubernetes 本身的网络做得不是特别好,很多用 kubernetes 都是用 calico 实现的。mesos 系统的设计思路则定义了任务调度和功能上整体依赖于调度器的设计,所以可以把 mesos 看成一个大乐高底层的基础板。
对于这两个框架,选择哪一个都没有对与错,只有适合与否,选择一个适合你们的工具才是最重要的。
mesos /container 在 360 的一些应用
我说一下 mesos /container 在 360 的一些应用。

我们从 2015 年开始,就对分布式的调度系统或者容器调度平台进行了调研,最后选择使用 mesos,因为我们想构建一个大型的物理资源池。在 2016 年业务正式上线,包括之后说的一些服务的容器化,2016 年我们也使用了 chronos,可以运行一些物理机上运行的 crontab 任务,长时间支持服务在线运行。2017 年我们已经实现了两个机房各部署了一个大型的资源池,节点达到了单集群最大 1000 个以上,任务达到 5000 个以上,10 个以上的自定义 framework。
解决的问题
部署
现在部署可能你只需要在 marathon 上改变你的镜像(image)地址,或者只需要把 instance 数改大就可以扩容。
故障恢复
故障恢复,如果有一台 mesos-slave 宕掉了,会自动在其他的节点上启动。
服务降级
关于服务降级,我们的资源池服务器是有限的,1000 台服务器如果资源快用满了,有些业务就需要做服务降级,不是所有业务都有动态扩缩容。我们主要处理广告业务,广告业务实时日志流比较多,在资源不够的时候,会让某些业务降级。平时每秒处理 20 万条,降级时让它每秒处理 10 万条或者 5 万条,有一定数据延迟也没有关系,因为数据不会丢只会慢慢处理完。
服务发现
关于服务发现,现在有了 mesos-dns 和 marathon-lb 我们可以做到实时的服务发现,因为是动态资源划分,我们的任务就可能实时变化。
storm 集群的容器化
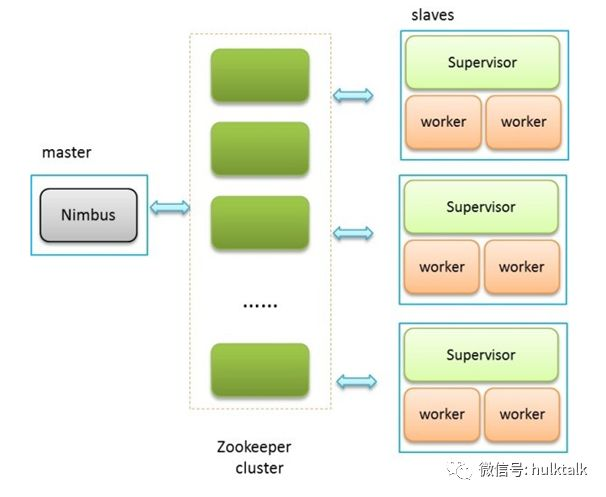
上图是原来通过物理级部署的,所有的 supervisor 节点都是一台台物理机还要单独部署一个 ninmbus,如果 nimbus 节点宕掉非常麻烦,比如有些同学说我可能会用 keepalived 做高可用,这确实是一种方案,但是如果你的集群需要频繁的扩容或者缩容就会非常麻烦,你要是不对资源进行动态管理的话,势必带来的就是资源的浪费,因为不可能一天 24 小时都满负荷运行。
把服务容器化之后,所有的 supervisor 都运行在 container(mesos-slave)中,supervisor 节点会通过 mesos-DNS 发现 ninmbus(master)的 IP。现在集群资源都是动态利用的。
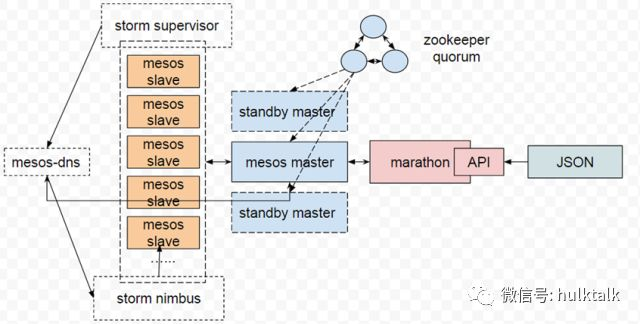
图片服务的容器化
重点说一下图片服务的容器化。
图片服务主要用的 PHP7 来做的,我们也会面临像阿里一样在双十一的时候,因为广告展示与投放量非常大,每秒达到上百万次,因为给用户进行展示与投放的图片会根据用户的习惯去动态的缩放与拼接。如果我放着很多机器专门用来做图片服务,可能也可以达到你的需求,但是在空闲时间段比如夜里资源浪费得非常多,对资源的利用率不是非常好。
我们就制定了这样一套方案,首先把 PHP 服务容器化,之后我们根据亚马逊 AWS 的策略,做了自己的方案,跑一个 long running job,根据 marathon 的 API 获取你的图片服务具体是哪台机器,由于所有机器上的监控都用了二次开发,通过 API 接口能获取负载、CPU,内存等等信息。当图片服务器的负载上升了肯定是压力最大的时候,这样我们只需要设定一个阈值。
比如系统负载大于 10 超过 10 次,就进行一次扩容,扩容的倍数是 1.5 倍,原来我有 10 台机器,现在要扩容到 15 台。大家可能会问你这个最大能扩到多少?我一定要设定一个最大值不能无限的扩。比如我们设定一个 36,最大扩到 36 台,在 5 分钟内可能判断 10 次,如果这个负载水平一直很高,就不进行缩容。
我肯定还会设定一个最低值,比如最低值是 6 台,可能到了夜里直接减为 6 台,每次都需要通过 marathon 的 API 实时发现后端所有机器计算出一个平均值。服务的监控,我们对每台 mesos slave 都有监控,具体的 container 我们做了异步,通过异步把日志写到 graylog 中,监控日志传输通过 UDP 协议。如果发生网络中断的情况也不会有太大影响,因为 UDP 是可丢的不可靠的。
其他
我们还有其他服务的一些容器化,有 Web service 相关的,aerospike 服务,通过组播实现集群之间的通信部署起来比较方便,marathon-lb 也是完全的 Docker 化的,毕竟是代理层像 lvs 一样,可能会有服务瓶颈。kafka mirrormaker 我们用来进行多机房之间的数据传输,原来直接部署在物理机上,这样虽然不会有太大问题,如果宕掉之后数据不能在多个集群当中进行同步,对实时性不能要求那么高。如果做了容器化之后是可调度的,都是可高可用的,我们会保证服务的可靠性。redis 也有做容器化,支持数据的落地和持久化,因为我们有 cephfs 还有更多的一些无状态的服务也运行在 mesos 之上。
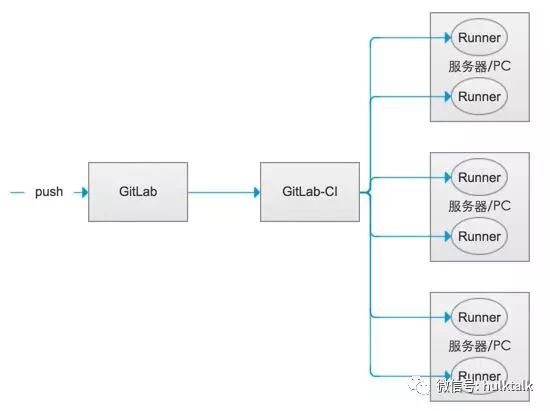
最后我要说一下我们的服务 ci/cd 是怎么做的,ci/cd 主要是通过 GitLab runner。我们会定义一个 Gitlab-CI,可以直接把你提交的代码进行 Docker build,把镜像自动提交到对应的仓库,通过 API 修改 marathon 上面对应的地址,最后实现上线自动化。
未来计划
未来我们想做的,因为 cephfs 的量不是很大,cephfs 之后想上一些写入量比较大的业务,看看效果如何。我们不是做公有云的对于 calico 的需求不是那么急切,之前一直没有上这个服务。之后我们可能会做一些 calico 相关的,比如一些爬虫的应用,如果用公司的 Nat 代理的话,可能遇到一些 IP 被封,导致整个代理 IP 都不能访问对应的网站就有一些问题了。
还有一些实时的机器学习,现在机器学习主要都基于离线业务来做,实时学习比较少,marathon 和 mesos 本身是支持的。
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/GX4rJRJs7TP5lpEjqBEDqA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论