

作者 Caleb Kaiser 此前曾撰写过《为何我们用 Go 而非 Python 编写机器学习基础设施平台?》,InfoQ 中文站曾经翻译并分享。今天,我们带来了作者的新作《为何我们用 Go 而非 Python 来部署机器学习模型》,在这篇文章中,Cortex Labs 介绍了团队为何用 Go 而非 Python 部署机器学习模型。
本文最初发表在 Towards Data Science,经原作者 Caleb Kaiser 授权,InfoQ 中文站翻译并分享。
Python 是当下最流行的机器学习语言,对这一点大家应该没有什么异议。不过很多机器学习框架进行实际计算使用的是 CUDA C/C++ 等语言,只是它们都提供了 Python 接口。因此,大多数机器学习从业者都是直接使用 Python 工作的。
我们的机器学习基础设施 Cortex 也是如此,它 88.3% 的代码是由 Go 语言编写的。
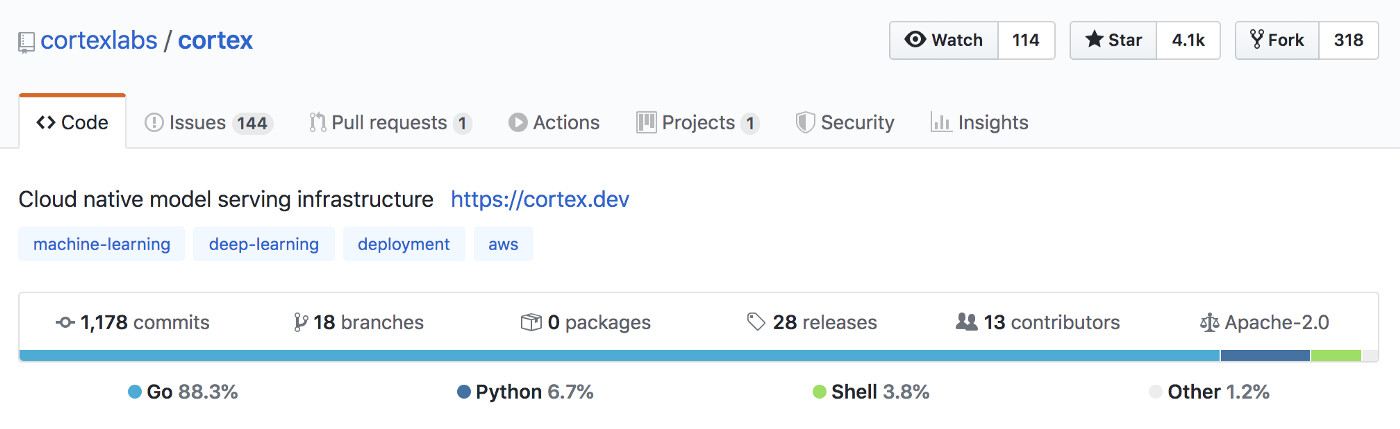
来源:Cortex GitHub
大规模部署模型不同于编写调用 PyTorch 和 TensorFlow 函数的 Python 脚本。要实际大规模地运行一个生产机器学习 API,我们需要基础设施来做如下事情:
自动伸缩:这样流量波动发生时就不会中断我们的 API(且我们的 AWS 仍然保持可控)。
API 管理:处理多个部署。
滚动更新:这样我们就可以在更新模型的同时还可以为请求提供服务。
我们构建了 Cortex 来提供这一功能。我们之所以决定用 Go 语言来编写,是出于以下几个原因:
1.Go 语言已为基础设施社区所接受
就背景而言,我们是软件工程师,而不是数据科学家。我们进入机器学习领域是因为我们想构建像 Gmail 的 Smart Compose 这样的功能,而不是因为我们对反向传播着迷(尽管它确实很酷)。我们想要这样的一个简单工具,它将采用经过训练的模型,并自动实现所需的所有基础设施功能,如可复制的部署、可扩展的请求处理、自动监控等,以便将其部署为 API。
虽然这种从模型到微服务的一体化平台还不存在,但我们之前已经在普通软件中实现了这些功能。我们知道什么样的工具适合这项工作,并且还知道它们是用什么语言编写的。
构建 Kubernetes、Docker 和 Terraform 等工具的团队使用 Go 语言是有原因的。Go 语言的速度很快,能很好地处理并发,可以编译成单一的二进制文件。这样一来,选择 Go 语言对我们来说,风险相对较低。其他团队已经用 Go 语言解决了类似的挑战。
此外,对于基础设施工程师来说,使用 Go 语言编写更容易做出贡献,因为他们可能已经熟悉了这门语言。
2. Go 语言解决了与并发性和调度相关的问题
管理一个部署需要许多服务同时运行,并按照精确的时间表进行。值得庆幸的是,Gorountine、channel(通道)和 Go 内置的 timer 和 ticker 为并发性和调度提供了一个优雅的解决方案。
在较高的级别上,Goroutine 是指 Go 语言通过在一个虚拟独立线程上执行一个原本正常的函数,使其并发运行。一个操作系统线程可以容纳多个 Goroutine。channel 允许 Goroutine 共享数据,而 timer 和 ticker 允许我们调度 Goroutine。
我们在需要的时候使用 Goroutine 来实现并发性,比如 Cortex 需要将多个文件上传到 S3,并行运行这些文件可以节省时间;或者是为了保持一个潜在的、长期运行的功能,比如 CloudWatch 的流日志,以免阻塞主线程。
此外,我们在 Goroutine 中使用 timer 和 ticker 来运行 Cortex 的 autoscaler。我已经写过一份关于如何在 Cortex 中实现副本级自动扩展的的完整版报告,该报告的中心思想是,Cortex 计算排队和进行中的请求数量,计算每个副本应该处理多少并发请求,并进行适当的扩展。
为了做到这一点,Cortex 的监控功能需要以一致的时间间隔执行。Go 的调度器确保在应该进行监视的时候进行监视,而 Goroutine 允许每个监视函数并发地、独立地执行每个 API。
要在 Python 中实现所有这些功能,也许可以使用 asyncio 这样的工具来实现,但 Go 让它变得如此简单,这对我们来说不啻为一个福音。
3. 在 Go 中构建跨平台 CLI 更容易
我们的 CLI 部署模型并管理 API:

来源:Cortex GitHub
我们希望 CLI 在 Linux 和 Mac 上都可以用。最初,我们尝试用 Python 语言来编写 CLI,但用户一直很难让它在不同的环境中使用。当我们在 Go 中重新构建 CLI 时,能够将它编译成单一的二进制文件,这样一来,我们就可以跨平台分发 CLI,而不需要做太多额外的工程计划。
编译后的 Go 二进制代码与解释性编程语言相比,性能上的优势也很明显。根据计算机基准测试的结果来看,Go 的速度明显比 Python 要快得多。
无独有偶,许多其他基础设施的 CLI,如 eksctl、kops 和 Helm 客户端等,都是用 Go 语言编写的。
4. Go 有助于构建可靠的基础设施
最后一点,Go 有助于 Cortex 最重要的特性:可靠性。
在所有软件中,可靠性显然很重要,但对于推理基础设施来说,可靠性绝对是最关键的。Cortex 中的一个 bug 可能会让推理费用严重增加。如果存在严重的 bug,那么很有可能在编译过程中被发现。对于一个小团队来说,这是非常有用的。
与 Python 相比,Go 的高冷性质可能会使得它上手变得更痛苦一些,但这些内部的“防护栏”为我们提供了第一道防线,帮助我们避免犯下愚蠢的类型错误。
小结:Python 用于脚本,Go 用于基础设施
我们仍然喜欢 Python,它在 Cortex 中占有一席之地,特别是在模型推理方面。
Cortex 支持 Python 作为模型服务脚本。我们编写 Python,将模型加载到内存中,进行推理前后处理,并为请求提供服务。然而,即使是 Python 代码也被打包到 Docker 容器中,这些容器也是由 Go 语言编写的代码进行编排的。
对于数据科学和机器学习工程来说,Python 将(并且应该)仍然是最流行的语言。但是,当涉及到机器学习基础设施时,我们对 Go 很满意。
作者介绍:
Caleb Kaiser,Cortex Lab 创始团队成员,曾在 AngelList 工作,最初在 Cadillac 供职。
原文链接:
https://towardsdatascience.com/why-we-deploy-machine-learning-models-with-go-not-python-a4e35ec16deb

InfoQ 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论