

本文最初发布于 Canva 工程博客。
在 Canva,我们有意采用了 monorepo 模式,它有好处也有坏处。自 2012 年第一次提交以来,库的规模和流量都与产品一起迅速增长。在过去的 10 年里,代码库已经从几千行增长到 2022 年的将近 6000 万行。数百名工程师在 50 万个文件中工作,每周会产生近百万行的修改(包括生成的文件),数万个提交,数千个拉动请求的合并。
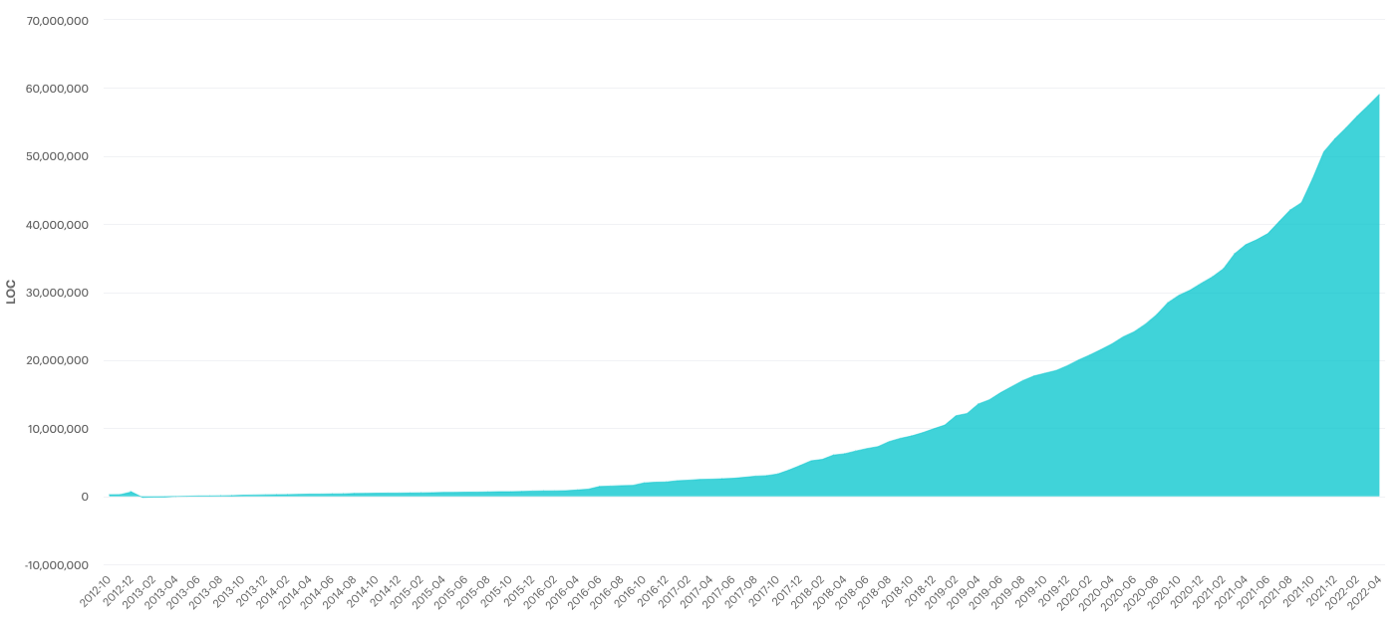
从 2012 年到 2022 年 10 年间代码量的增长
这种增长显著降低了本地 Git 的性能,因为像git status这样的命令运行时间越来越长。在新克隆的一个 monorepo 上,git status平均需要 10 秒,而git fetch可能需要 15 秒到 1 分钟,这取决于工程师合并了多少变更。由于 Git 在工程师的工作流程中非常重要,每天多次运行这些命令会缩短工程师每天的总生产时间。而且,时间太长的话,工程师可能会进行上下文切换,这进一步降低了他们的生产率。
现有解决方案
所幸,并不是只有我们在使用 monorepo 时遇到了这个问题。Github、Dropbox之前的工作以及 Git 近期的改进提供了大量可以用来提高 Git 性能的资源。多年来,多位工程师发表了数篇关于如何“让 Git 更快”的内部博文。这些工作最终形成了一个自动化脚本,建议工程师们将这个脚本作为入职培训流程的一部分。
首先,为了减少 Git 查找变更的开销,我们在 Watchman 中使用了fsmonitor钩子,这样就能在变更发生时捕获它们,而不是在每次运行命令时扫描存储库中的所有文件。我们还启用了feature.manyFiles,而它在后台启用了untracked cache,可以跳过没有变化的目录和文件。
Git 还内置了一个命令(maintenance),用来优化存储库的数据,加速其他命令的执行并减少磁盘占用。它默认是不启用的,所以我们将它注册为每日调度和每小时调度。
我们的 monorepo 有什么独特之处?
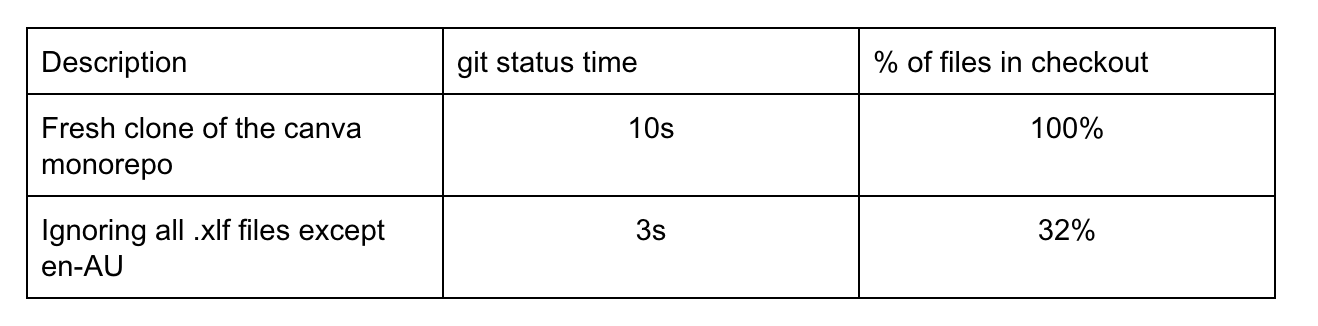
深入研究 monorepo 中的文件类型,我们发现.xlf 文件几乎占文件总数的 70%。这些.xlf文件包含针对每种语言环境翻译好的字符串。即使它们位于一个 monorepo 中,工程师也从来不会手工编辑,因为它们是在字符串翻译时自动生成的。也就是说,Git 在花费资源跟踪工程师永远不会修改的文件。然而,我们不能直接删除或忽略这些文件,因为翻译系统有它们才能顺利运行。次优解决方案是告诉 Git 不要使用稀疏签出(sparse checkout)在工作树中填充它们,局部性地忽略它们,同时仍然通过 monorepo 的其他源头跟踪它们的变化。实际上,为了使构建系统的其他部分可以正常工作,我们必须包含用于 en-AU 语言环境的字符串,但这点差异可以忽略不计。尽管忽略了这些翻译,但我们的本地环境仍然默认使用en-psaccent伪本地化语言环境运行,因此,工程师仍然要注意本地化需求。
我们用一个单独克隆的 monorepo 做了以下实验,使用 Git 的默认设置,没做前面提到的优化。
对于稀疏签出功能的使用,我们可以更进一步。通常,我们的工程师团队都是小团队,只会用到 monorepo 的一个更小的子集。例如,处理编辑器的前端工程师不太可能修改与搜索或计费服务相关的代码。如果一名工程师能告诉我们他们通常在做什么,我们就可以设计一个包含所有必需依赖项的签出模式,让他们可以在本地运行和测试代码,同时保持签出尽可能小。
Canva 的 monorepo 使用Bazel作为构建系统,我们在其中定义构建目标(主页、搜索服务器、导出按钮等)和它们的依赖项。也就是说,给 Bazel 定一个目标,我们就可以准确地确定哪些文件需要构建、运行和测试,并通过查询 Bazel 依赖关系图排除其他文件。在实践中,这需要更多的启发式逻辑,因为不是所有的东西都连接到了 Bazel 构建图中,需要解析符号链接,但这都是些可以解决的边缘情况。下表展示了一些示例配置以及它们对签出的影响。

后端服务往往模块化程度更高,可以独立运行,前端页面则不那么独立。原因有很多,如 TypeScript 配置,代码分析工具的设置方式,以及在编写工具和网页时没有考虑稀疏签出,而是假设所有文件任何时候都存在。这些针对翻译文件的配置提供了每名工程师都可以使用的增量改进。
稀疏签出也有缺点。首先,现在有跟踪文件没有物理地填充到磁盘上,所以不能搜索或交互。意外变更或错误的合并冲突可能会使这些文件处于错误的状态(例如,如果两个 pull 请求修改了同一个要翻译的字符串并产生冲突,现在就必须手动解决)。工程师在工作过程中必须注意这种情况。
每个 Git 签出命令都有开销用于检查是否应该填充或忽略更新的文件。虽然对于忽略.xlf 文件这样的简单模式来说,这种开销很小,但对于更复杂的模式,这种开销就变得非常明显了。
小结
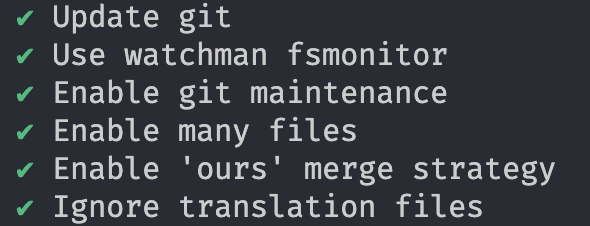
该脚本根据推荐的 Git 配置设置 Canva monorepo。
结合现有的 monorepo Git 配置最佳实践,我们通过缓存将git status的时间缩短到 3 到 2 秒。虽然对于工程师来说,这比什么都不做要好得多,但随着 monorepo 越来越大,工程师越来越多,为了缩小这一数值,我们仍然有很长的路要走。
进行中的工作
这些优化为配置大型存储库设定了一条基线。但是,为了量化 Git 性能对工程师生产力的影响,并进一步分析问题和优化,我们需要能够收集 Git 操作的遥测数据。
Git 通过trace2格式输出跟踪信息,我们可以捕获这些信息并将其发送到中央存储进行分析。为此,我们团队一直在开发一个名为 Olly 的内部工具,用于捕获操作时间、失败及其原因,跟踪新分支的创建,等等。这有助于我们在整个组织中监控 Git 的性能,将来可以在 Git 配置发生变化时通知我们,这是量化工程师开发周期的第一步。
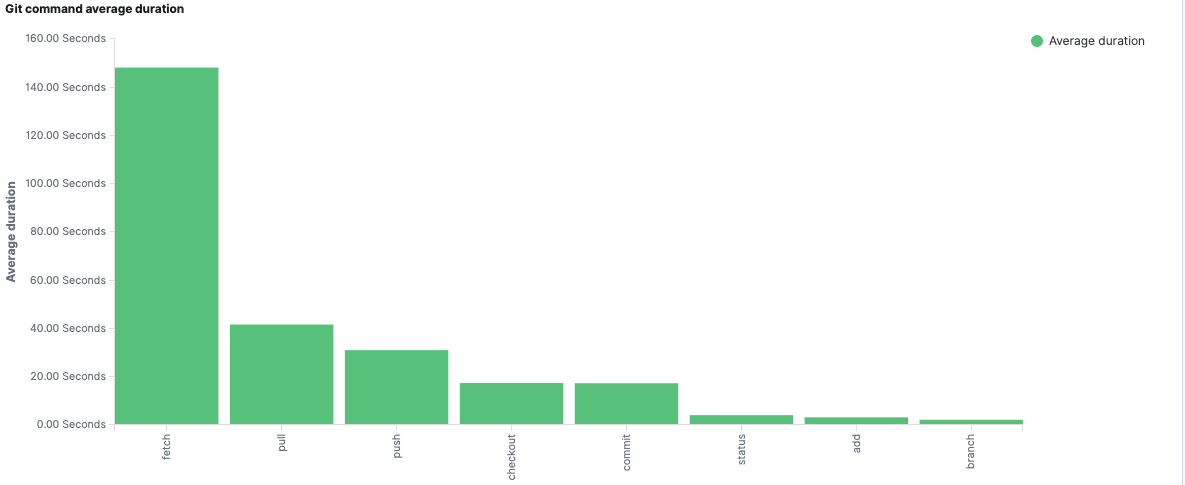
常见 Git 操作的平均时长
有了这些遥测信息,我们现在可以具体地量化 Git 性能对工程师的影响,关注痛点(上图中的 git fetch),并进一步深入分析每个操作。
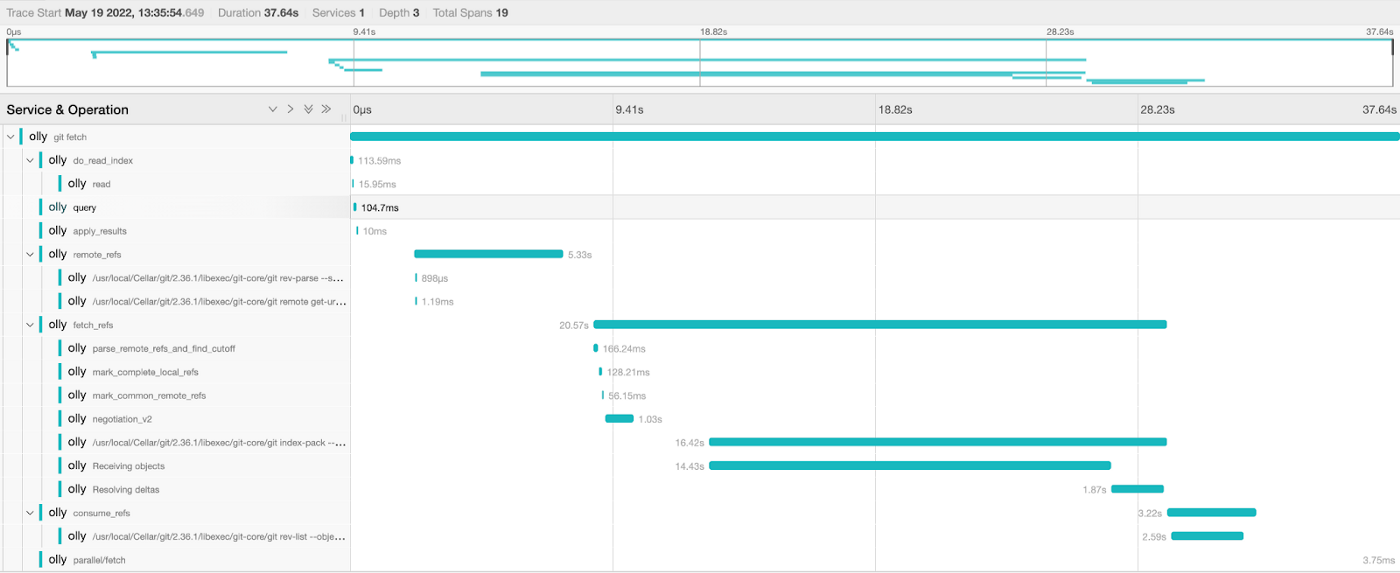
git fetch 跟踪信息
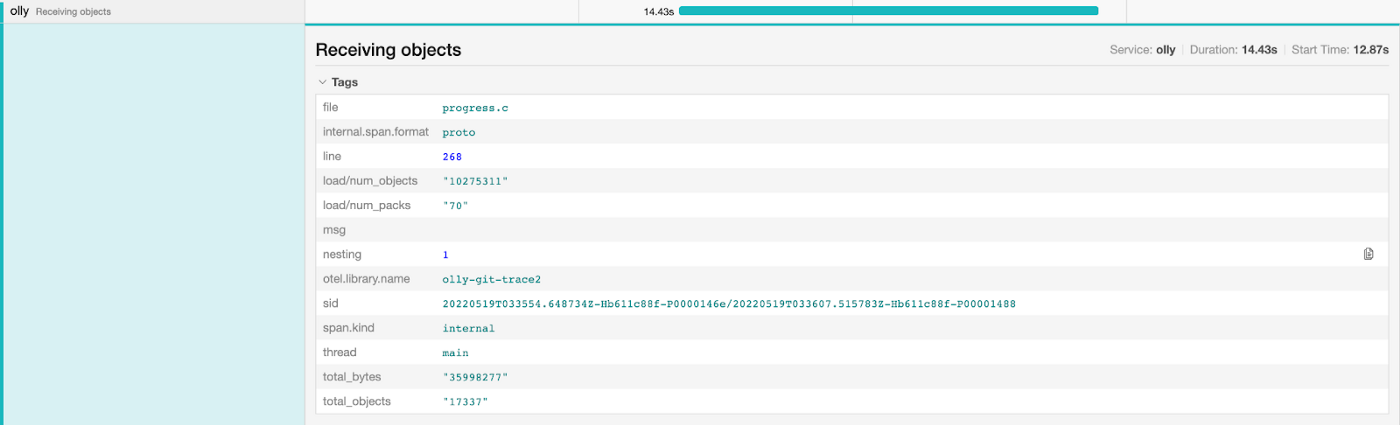
深入研究 index-pack 操作,我们可以得到正在传输的包、对象和字节的数量。
此外,鉴于 Git最近暴出的漏洞,我们正致力于向所有工程师提供一个明确的 Git 版本,默认提供正确的配置,确保每个人都能获得最新的安全补丁和性能改进。
原文链接:
We Put Half a Million files in One git Repository, Here’s What We Learned

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论